目次
![]()
皆様はじめまして.リクルートテクノロジーズでエンジニアをしている相野谷と申します.
先週開催された第3回Elasticsearch勉強会で「Elasticsearch+DynamoDB+Node.jsで作る全社基盤」というタイトルで,独自開発したシステムでのElasticsearchの利用例を紹介させていただきました.
発表スライド自体は既にupされていますが,それだけでは初見の人に分かりづらいと思いますので,解説記事を上げさせていただきます.
スマホアプリのためのプッシュ通知基盤
今回開発したシステムは,「リクルートグループが開発するスマホ用のアプリでプッシュ通知を送るための基盤」です.このプッシュ通知基盤が提供する条件指定プッシュという機能のために,Elasticsearchを使用しています.
システム構成
本システムはリクルートで開発される全アプリから利用されることを想定しているため,大規模な利用でシステムが高負荷な状況になっても安定して動作するよう,スケーラビリティに念頭を置いた構成にしています.技術要素を列挙すると次のようになります.
インフラ:AWS
スケーラブルな仕組みを構築するためにAWSの各種サービスを活用しています.デプロイにはElastic Beanstalkを利用している他,Cloudformationも併用して運用を最大限省力化しています.
開発言語: Node.js
サーバサイドアプリケーションは全てNode.jsで実装しています.Node.js採用の理由はAPI通信を非同期かつ高速に
処理する必要があったためです.なお,プロジェクト開始時点では開発メンバーのほとんどがNode.js未経験でしたが,全員がシステム開発可能なスキルに到達するまでさほど時間はかかりませんでした.
DB: DynamoDB
システムが持つ端末情報のデータ構造がKVSで扱いやすいものだったため,DynamoDBを採用しました.DynamoDBを採用した理由は,主に以下の3つによるものです.
– システムで必要となるデータ構造がKVSで表現しやすかった
- 並列scanにより高速な全件抽出が可能なこと
- 高信頼性.各テーブルにつき複数のAZでレプリカを持つなど高可用性のための仕組みが備わっていること
検索: Elasticsearch
DynamoDB(KVS)が苦手としているデータの検索を補完するための検索エンジンとしてElasticsearchを採用しました.
Elasticsearchを選んだ理由は,「条件指定プッシュ配信機能」の項目で後述します.
システムの使われ方
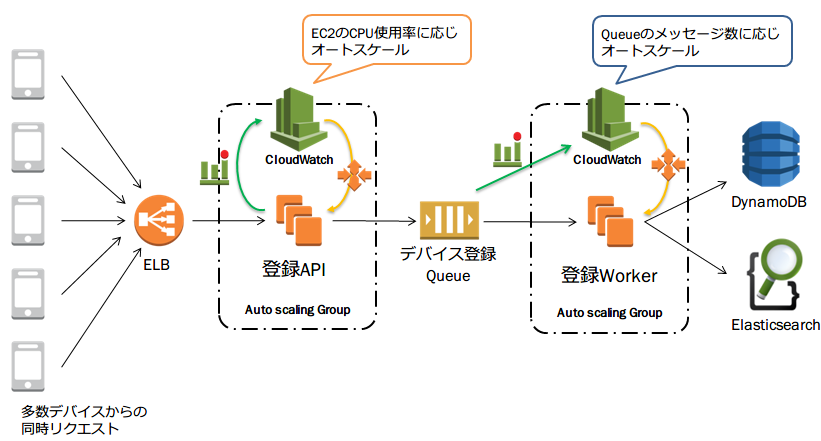
プッシュ配信基盤では登録されたデバイス情報を元に,アプリ運営者によりキックされたプッシュ配信を実行します.全体の動作の流れについて,「デバイス登録」と「プッシュ配信」の2つに分けてアーキテクチャの動作を見ながら説明します.
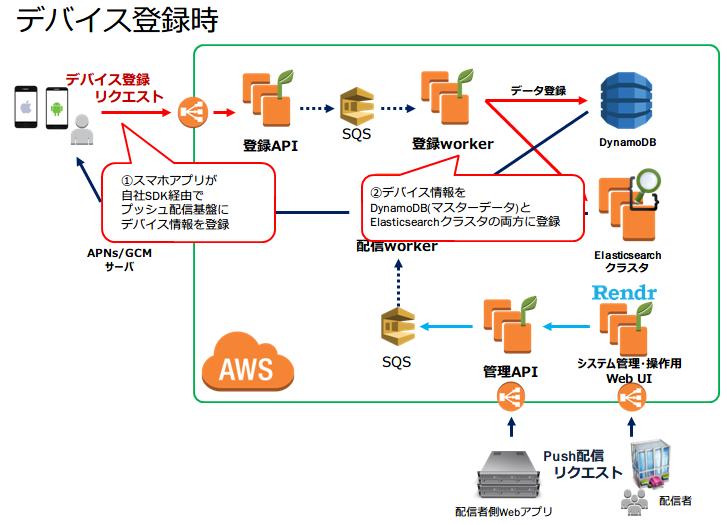
デバイス登録
リクルートのクライアントアプリは,自社SDK経由でシステムに自身のデバイス情報の登録リクエストを送信します.デバイス情報は,登録リクエスト時にDynamoDBとElasticsearch両方に書き込まれます.
プッシュ配信
プッシュ配信は,配信者あるいは配信者側のWebサーバからの配信リクエストにより実行されます.
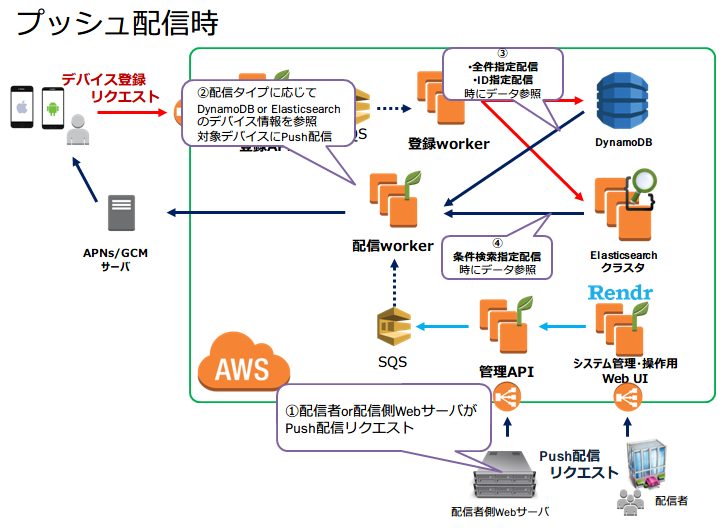
プッシュ配信時,システムはプッシュ配信リクエストの配信種別に応じてデバイス情報の参照先を切り替えています.DynamoDBは全デバイス配信やデバイスIDを指定した配信時に,Elasticsearchは条件指定プッシュ配信時に参照されます.
条件指定プッシュ配信機能の実現
先述の条件指定プッシュ配信とは,アプリごとに指定されたタグで対象となるデバイスを絞込検索してプッシュ配信できる機能のことです.
アプリはシステムへのデバイス登録時にタグを付加することが可能になっており,配信時にはそのタグを検索条件にして,条件にマッチするデバイスのみにプッシュ通知を送ることができます.
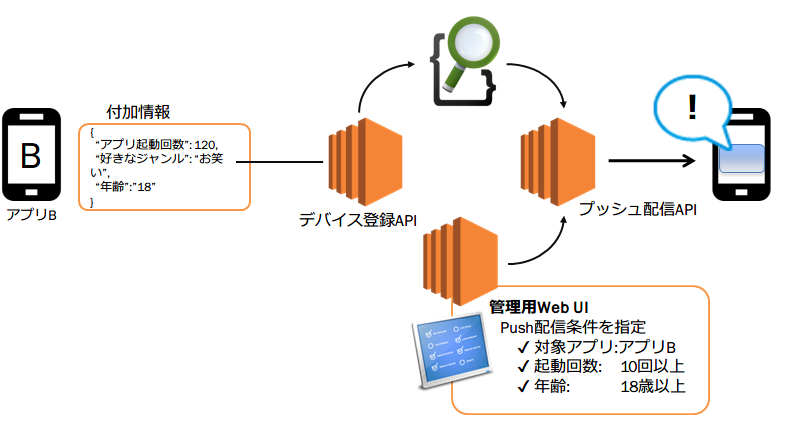
簡単な利用例を図とともに示します.例えばアプリBへのプッシュ配信時,タグに登録された起動回数や年齢を配信条件として配信管理のWeb UIから絞り込むことで,起動回数が10回以上で,ユーザの年齢が18歳以上の端末にPush配信を送るといったような細かいターゲティングができます.
Elasticsearchの採用理由
条件検索プッシュ配信機能の実装に際し,デバイス情報を保持するDynamoDBはKVSで検索が苦手なため,
別途検索エンジンを用意する必要がありました.さらに,そこで用意すべき検索エンジンに求められる条件として
- 多数アプリからの大規模な利用に耐えるスケーラビリティ
- 大量のリアルタイム更新に耐える性能
- アプリごとに自由なタグを扱えるようにするためのスキーマレスな検索インデックス
があり,これらの条件を全て満たすものとして,Elasticsearchが適任だったというのが主な採用理由です.
Elasticsearchの使い方
次に,Elasticsearchの利用の実際について紹介します.
クラスタ構成
AWS上でのクラスタリングには,ec2プラグインを使うのが一般的です.このプラグインを使うと,シンプルなconfigで簡単にクラスタを構築することができます.
また,Auto scaling Groupでクラスタの台数をキープする設定にしていて,MultiAZなクラスタ配置になるようにしています.MultiAZ配置にするにあたっては,AZ障害を考慮して1つのAZがまるごと落ちても復旧できるようなReplica数を設定しています.これにより,仮にAZが落ちた際にはAuto scaling Groupの機構により,元のクラスタの台数までインスタンスが上がってきて自動復旧するようになっています.発表後の質問で自動復旧の不安定さについて指摘がありましたが,クラスタの挙動がまだ読みきれない点は否めないので,クラスタ数やステータスをCloudwatchで監視しつつ安定した運用が可能な設定を模索しているところです.
性能面での工夫
search_type=scanの利用
このシステムで使っている検索の特徴として,条件指定配信において大量の検索結果を取得しつつ配信するために,ページングである程度結果をまとめて取得する処理を行っています.この検索には,通常の検索ではなくsearch_type=scanを活用しています.
scanを使うメリットとして,以下が挙げられます.
- 通常の検索と違い検索結果セットのソートを行わないので,深いページングをしても性能が劣化しない
- それに付随してページングの際のデータ抜けも防げる
scanを使って実際に検索を行う場合は,まず最初にsearch_typeにscanを指定してsearchリクエストを行います.これによりscroll objectのidが返ってくるので,scroll_idを指定してscrollリクエストを送ると,イテレータのようにリクエストごとにsize分の件数の検索結果が返るので,scrollリクエストを繰り返してページングを行います.
詳細な使い方についてはElasticsearch公式の紹介ページをご参照ください.
Node.jsとの組み合わせ
今回のシステムではelastical-clientというnpmモジュールを独自のWrapperから利用しています.このWrapperには,システムで利用するindexのフィールドの型をJSの型にマッピングする処理が入っていて,実際の利用時には検索結果のオブジェクトを型付きの状態でそのまま利用できるようになっています.これにより,使う側は煩雑な型定義に気を使うことがないようにしています.
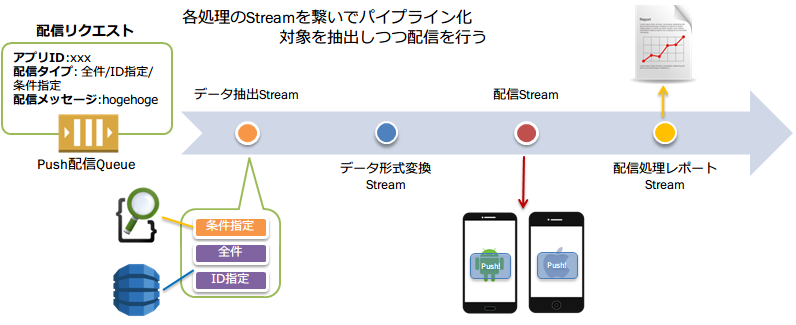
実際の検索から配信までの処理は,処理の一連の流れをStreamを使って非同期I/Oで実装しています.
このStream実装のイメージとしては、デバイスデータを検索して、Push配信するまでの各処理をそれぞれStreamとして実装しておき、それらをパイプで繋いでパイプライン化して一連の処理をする流れになります.このStreamによる実装によってelasticsearchから検索結果を抽出しながら配信を行う処理を非同期で行うことができ,高い処理性能を実現しています.
データ更新時の負荷平滑化
システムの特性上,プッシュ大量配信後,通知開封のために同時に大量のデバイス登録リクエストが走るようなケースが多々あります.このような急激な負荷増加が発生した場合,Elasticsearch側ではindex更新が追いつかない状態になることが予想されます.これを防ぐために,APIとインデキシングの間にキューを挟むことでelasticsearchにかかる負荷を平滑化しています.
さらに,CPU使用率やQueueをトリガーにしたオートスケールを設定することで,インスタンスの処理能力がネックとなる場合の負荷分散を図っています.
DynamoDBからのリストア
Elasticsearchクラスタの信頼性はDynamoDBに比べて低いため,マスターデータはあくまでDynamoDBが持つという前提で運用を行っています.
Elasticsearchのindexデータがいつ破損しても大丈夫なように,DynamoDBからindexを復旧するツールを用意しています.(幸いまだ使う事態には陥っていませんが…)
まとめ
勉強会では,Elasticsearchの活用例としてプッシュ配信システムを作った話を中心に発表してきました.今回の例ではElasticsearchをDynamoDB(KVS)の機能の補完として利用しましたが,このようにElasticsearchは普通の全文検索エンジン以外の用途にも活用できる事例があると考えています.
また,scanによるdeep scrollingなど,solrは苦手でもelasticsearchには得意な機能要件もあるので,検索エンジン選択の際の一つの参考になればと思います.
さらに今回のシステムでは,Node.jsからElasticsearchを利用しましたが,検索結果のJSONオブジェクトをそのまま扱え,Streamで検索結果を非同期に処理する実装を簡単に書けるので,相性良く組み合わせて使えるのではないかなと思っています.
最後に
本システム以外にも,リクルートグループの主要Webサービスでの検索にElasticsearchを本格運用する準備をしています.今後もelasticsearch周りのノウハウについて継続的に共有していければと思います.