目次
リクルートテクノロジーズの大杉です。
Apache Solr の新しい入門書が出版されました。
私はその中で「検索改善」の章を手厚く書きました。その中でも A/B テストについては、概念から統計手法やら実務的なFAQまでかなり手厚く書きました。
Solr 本の中での A/B テストについての記述を「これくらいで十分だろう」と当時の自分は考えていたのですが、改めて読み返すとA/Bテストのそもそもの思想の部分をもっと書いておけばよかったなと反省したので、その部分を当ブログで書きます。ついでにA/Bテストの先の思想についても少し書きます。今回ちょっと長めです。
A/B テストとはそもそも何のためにあるのか
A/B テストとは、無作為抽出とよばれる実験計画法のテクニックを用いた科学的な実証方法のことで、Web業界での呼び名です。A/B テストは「変更によってサービスが進歩するかについての知識獲得」のために行われます。極論をいえば、A/Bテスト自体はサービス成長のために行われるものではありません。A/Bテストで得られた知識こそがサービス成長のために使われます。例えば、A/Bテストでは新しいボタン配置が旧来のものと比べて使いやすいかどうかを知るために用いられます。そのさいに「使いやすさ」そのものは直接測定できないため、「ユーザーの離脱率」といったような指標を使って推定を行います。A/Bテストの結果、「新しいボタン配置の方が統計的にユーザーの離脱率が低い」ことがわかったとします。A/Bテストの役割はここまでです。サービス成長のためにこの知識がどのように活用されるかはA/Bテストの外側の話です。どちらの方が良いものなのかについての知識獲得がA/Bテストの目的です。
「どちらのほうがサービスにとって良いのか」についての知識は非常に重要です。この知識を獲得できない状態で新しいことを試そうとすると、「試したところで、その意義がわからない」→「わざわざコストとリスクをとって変更する必要はない」→「サービス進歩の停止」、あるいは「とりあえず作ってみた」→「どの開発がサービスにとって本当に有益だったかわからない」→「サービス迷走」といった、ろくでもないことになりがちです。A/Bテスト以外でも、関連する知識獲得は可能ですが、やはりA/Bテストは極めて強力な実験手法なので、使われなくなることはないでしょう。本ブログでは、A/Bテストの限界とその先についても簡単にふれます。
まず、本ブログで頻出する「知識」という言葉について考えます。
知識とは
かつてあったことは、これからもあり
かつて起こったことは、これからも起こる。
太陽の下、新しいものは何ひとつない。
日本聖書協会『聖書 新共同訳』 コヘレトの言葉1編9節
知識というものは、今でこそインターネットに凄まじい量の知識が保存され閲覧できるようになりましたが、近代以前にとっては
- 知識をどのように獲得するか
- 正しい知識をどのように蓄積させるか
- 蓄積された知識をもとに知識をどのように深めていけるのか
は難しいことでした。そこで冒頭のコヘレトの言葉のような憂いも、太陽が東から昇って西から沈むことと同じくらいに自然なことだったのかもしれません1。一方、21世紀に生きる我々は、科学技術が日進月歩に進歩し、少し前には存在しなかった再生医療やら深層学習やらが発展し、人類がどんどん可能なことを増やしていく世の中に生きています。
この違いはどこから生まれているのかといえば、知識獲得の方法論を人類が手にし、知識を共有できる世界になったこと、つまり科学と科学を支える社会システム2ができあがったことです。
A/Bテストとは、この知識獲得の方法の中で最も優れている科学の考え方に基づいています。
知識獲得に有用な考え方とはなにか
万物の根源は水
古代ギリシア7賢人ターレスが考えたとされること
古代ギリシアの哲学者たちは、現代の我々からすると、ひどく適当なことを言っているように見えます。しかし、人類の知性が古代ギリシア人と比べて向上したとも思えませんし、冒頭のターレスも残された逸話から非常に賢い人だったことが伝わってきます。この違いは現代の我々が古代ギリシア人よりも、実証、つまり「実際に試してみる」ことや「ちゃんと観測すること」に重きを置くようになったからだと考えられます。
実証的な考え方では、「実際に試してみること」といったことの他に、「実際に得られた結果から考えを改めること」といったことが非常に重要です。実際に得られた結果から考えを改めることは難しいことのようです。
例えば、天文学では、神話に基づく仮説やら宗教上の権威の他にも、真円こそが美しいといったような「かくあるべし論」3による説明で地球と太陽の関係性が論じられていたようです。かの有名なガリレオ裁判の逸話からもプラトンのイデア論からも、「実際に得られた結果」を重視することが軽視されていたことがわかります。
我々は、古代の宇宙観が、観測やそれに基づく理論によって覆され、その後の物理学の誕生から科学技術の急速な発展の歴史を知ってます。そこから実証的な考え方は知識獲得に極めて重要であることを知っています。
A/B テストも「実際に試してみよう!」という実証的な考え方が根底にあります。実際に検証・実験・テストをせずに語る内容は「万物の根源が水である」くらいの信頼度だと私は思っています。古代ギリシア7賢人よりも賢い人の考えだったとしても、です。
一方、実証的な考え方にも大きな弱点はあります。たとえば、その時点での技術では測定が不可能であったり測定自体のコストが高すぎたりすることが往々にしてよくあります。この弱点は農学や医学や心理学といった複雑な事象4を扱う場合に、非常に大きな問題になります。この問題の解決には20世紀の統計学の実験計画法が大きく寄与しています。中でも無作為抽出といった技法は「測定できない要因」や「考慮しきれていない要因」5の影響をテスト条件間で取り除けます。
無作為抽出とは
無作為抽出とは英語で書くと random sampling です。英語のままの方がわかりやすいほどに、古めの統計用語の訳語はわかりにくいものが多いのですが、統計の文脈でしか使われない用語のため混乱が少ないといった利点もあります6。
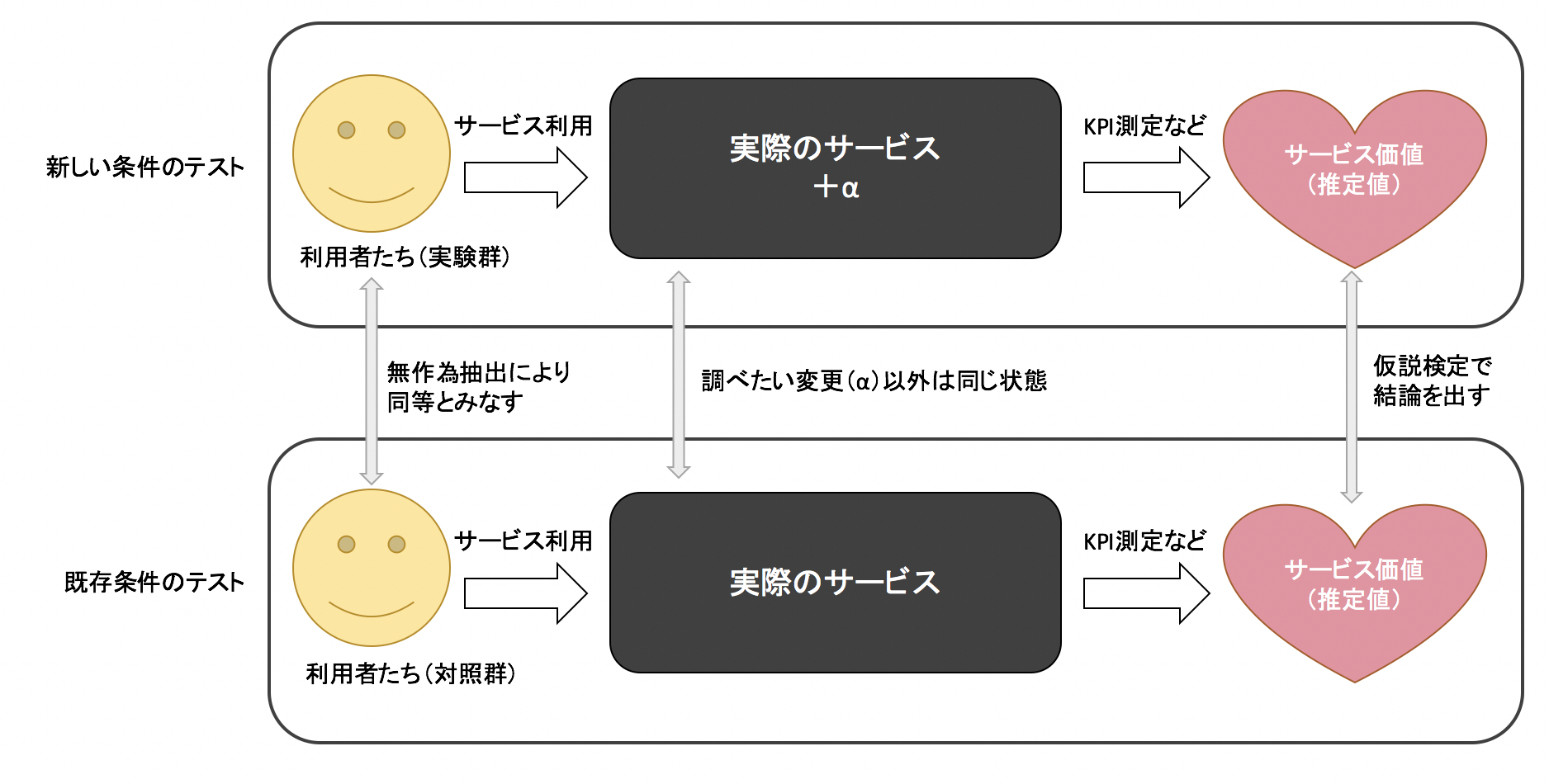
この無作為抽出の使い方を、新しい治療法(新薬とか)が有用かどうかの調査を例にして説明します。人体という複雑怪奇なものを相手にした実験なので、どの要因がどう効くのかについてすべてを理解することは不可能です。例えば、年齢や性別といった要因にその治療法が大きく影響すると考えられるのなら、年齢や性別を聞けばいいだけなので、簡単です。喫煙や飲酒の習慣も質問紙で聞けます。しかし、血中のとある成分の割合が〜となると血液検査をし、特定の遺伝子が〜となると遺伝子検査を、といった具合にキリがないです。仮に関連しそうな要因をすべて測定できたとしても、それらを、実験群(新しい方法を試す方)と対照群(新しい方法を試さない方)にバランス良くどのように割り振れば良いのかといった問題が出てきます。この割り振りの問題を解決したのが無作為抽出です。
無作為抽出により、測定できないが結果に影響を与える要因があったとしても実験群・対照群でその要因が同じ割合で配分されるので、実験群間ではその要因由来の差は生じません。A/Bテストを十分な期間で、サイト訪問者全員を対象に実験した場合、実験群・対照群に含まれる各種要因の含まれ具合は、実際のサイト訪問者と同じになるはずなので、さらに信頼できる結果が得られます。更に詳しい、A/B テストのハウツーは例のSolr本に色々と書いた7ので、そちらをご参照ください。
ここまでのまとめ
A/Bテストの思想をまとめると
- どちらのほうが良いものなのかについての知識の獲得が目的
- 実際に試した結果によって判定を行う
- 無作為抽出化により、複雑な要因については考えないで済むようにする
となります。全容を図にするとこんな感じです。
この図は最も単純な場合で、テスト条件が複数になったり、複数のA/Bテストを同時に実施したり8、と応用パターンはありますが、A/Bテストの基本形はこれです。複雑怪奇な利用者や実際のサービスについてはブラックボックスのまま扱える点が非常に強力です。
A/B テストの限界とその先
A/B テストを用いることで、「どちらのほうが良いものか」について判断できるようになりました。しかし、「なぜ良いのか」については依然わかりません。A/B テストをひたすら繰り返すだけだと、ブラックボックスを部分的に操作した場合の出力を記録し続けるだけです。テレビで例えると、リモコンのボタン操作とテレビの画面や音の対応関係を延々と調べているようなものです。これではテレビの仕組みについては永遠にわかりません。
「なぜ良いのか」についての仮説があれば、A/Bテストで得られた結果を汎化して実験前の事象について予測することができます。これは自然科学では「法則」とよばれるものに対応します。法則というと物理学のように高精度で予測できる信頼度が高いものに聞こえるので、心理学などではよく「モデル」という表現をします。心理学でのモデルは数式で表現される場合もありますが、そうでない場合もあります。数式でないモデルの代表例は記憶のモデルで、記憶を短期記憶とか長期記憶とかに分類したものです。(機械学習の分野でも「モデル」という言い方をしますが、こちらは数式のことをさします。)
この「なぜ良いのか」についての高精度なモデルが獲得できれば、「なにをどうしたらサービスはどのくらい良くなるのか」が検証前から正確に予測できるようになるということなので、当面の機能改善はだいたい終わったようなもの9です。
この高精度なモデルをどのように獲得できるかは、まだ人類が取り組み途中の課題かと思いますが、私は以下のようなアプローチが有効だと考えています。
といった行動心理学・認知科学的なやりかたで、考慮すべき要因をある程度しぼった上で、機械学習で効率的な探索13をし、その結果を再び、A/Bテストのような実証実験によって検証を行う、をひたすら繰り返し、結果を蓄積しつづけモデルの精度を上げ続ける14。自分のバッググラウンドである認知科学の方法論の影響が強い気がしますが、現状このアプローチが「なぜ良いのか」についての知識を獲得するのにベストだと考えています。
宣伝
リクルートテクノロジーズではリクルートグループの様々なドメインのWebサービスに関わるチャンスがあります。あちこちのサービスでA/Bテストをし易い状況と、データ分析環境も整備されつつあります。Webエンジニアはもちろん、知識獲得に興味がある科学者のような方とも一緒に働きたいです!15
個人的なオススメ本
本ブログを最後まで読み、このような話題が好きな奇特な人向けに
- 悪霊にさいなまれる世界(カール・セーガンの科学啓蒙本。翻訳ごとにタイトルがぜんぜん違う)
- 科学の発見(日本語訳は2016年。実証的なものの考え方の起こりとか)
- 病の皇帝「がん」に挑む(皇帝が「がん」に挑むのでなく、人類が病の皇帝である「がん」に挑む話。下巻の実証実験と統計学のくだりとか)
- エンサイクロペディア 心理学研究方法論(2013年に改訂版がでたため入手が少し簡単に。私は実験計画についてこれで勉強しました。)
- バイオサイエンスの統計学(バイオサイエンスだけでなく、統計勉強したい人向け全員にオススメ。最近、やっとp値絶対主義者の立場があやしくなってきましたが、なんだかんだ仮説検定は重要です。)
- [改訂第3版]Apache Solr入門
- コヘレトの言葉は地質学スケールの時間の流れことを指しているのかもしれないので、昨今の科学技術の進歩を引き合いに出すのは不正確かもしれませんが、コヘレトの言葉は個人的に好きなので引用しました。 ↩
- 科学者を支える金銭的支援とか、論文を公表することで評価される仕組みとか。科学はちゃんと社会で支援しないと持続できないです。 ↩
- 地球は太陽の周りを楕円軌道でまわってますが、この楕円という箇所が受け入れがたかったようです。 ↩
- Webサービスも複雑怪奇です。 ↩
- 私はこれを未知の交絡変数と呼んでますが、分野によって微妙に呼び方が違うみたいです。この辺の独立変数と従属変数の周辺は、従属変数ひとつとっても束縛変数とか応答変数とか目的変数とか様々な言い方するので面倒くさいです。 ↩
- とはいえ母数(パラメータ)のように誤用が多発するようですと、混乱が生じるので、わかりにくすぎる訳語は良くないかもしれません。 ↩
- 9章です。Solrの本ですが検索精度改善のためにA/Bテストは非常に重要なので、仮説検定のやり方まで書いたりFAQだけでほぼ3ページ書いたりと頑張りました。 ↩
- 以前にブログで書いた内容です。https://recruit-tech.co.jp/blog/2015/08/14/multi-variable-testing/ ↩
- もう勝ったも同然と言いたいところですが、そのサービスの需要がなくなったりビジネスモデルが古くなったりなどの外部要因によって負けるので、あくまでサービス内での比較の話です。 ↩
- 理学部や工学部出身の方よりも文学部などで心理学、特に動物行動をやっている人が強い印象があります。学科の演習とかで結構真面目にやらされますし。 ↩
- この辺は一般的なエンジニアリングの領分です。どんな情報が計測できて、どういう状態で保存するのかといったデータエンジニアリングだけでなく、そもそも実験を実施するための開発・リリース・運用とか当然ないと話になりません。 ↩
- 実験結果の分析も複雑なモデルの改善という文脈ですと、単に図を作ったり基礎集計したりするだけでは済まなくなってきます。例えば、統計処理を仮説検定しか行っていない場合は「どのくらい良いのか」についてもわかりません。「どのくらい良いのか」は、結局いくら儲かるの?という問いの答えにつながるので、ビジネスを行っていく上で一番重要なことです。仮説検定で帰無仮説を棄却しただけですと「これらのものは同じであるとは考えにくい」という結論しか得られません。最近では帰無仮説を棄却するだけだと結果として弱すぎる、といった主張も強くなっているようです。例えば、http://www.nature.com/news/psychology-journal-bans-p-values-1.17001。また帰無仮説を棄却する考え方だと、「これらのものは同じであるとは考えにくい」という結論の価値を担保するために、実験条件を複雑になると、検定方法も複雑になります。またWebではかなりの数に利用者で実験ができる場合があるため、ほんの少しの違いでも有意差が検出されてしまうといった問題もあります。この辺の話もSolr本に少し書きました。ですので、古典的な仮説検定以外の方法も使える必要があります。 ↩
- 2017年時点では、深層学習が凄まじい発展をしていますが、最初にある程度の探索空間の絞込はまだまだ必要そうです。ネットワークの形だったり初期値だったり学習データだったりに制御されてます。画像や言語はその特性から畳み込みや再帰的な構造をもつニューラルネットワークに多くを任せれますが、利用者の欲求みたいな捉えにくいものはどんなネットワークに流し込めばよいのかについての知見はまだ少ないようです。(とっくに研究されていて公表されていないだけの可能性も) ↩
- 継続する、といった姿勢が非常に重要ではないか、という話です。数回のアプローチで高精度なモデルを作るのは難しそうです。モデルを作るだけでなく、作ったモデルの評価こそ最も重要です。本ブログの趣旨はここです。科学のように「巨人の肩にのる」ように進めないと高精度なモデルは達成できないと考えています。 ↩
- 今のサービス改善のための試みは、錬金術師が試行錯誤を繰り返して金を作り出そうとしているような状態に似ています。この錬金術師の取り組みの蓄積が化学の法則につながったように、A/Bテストなどで蓄積された知識のモデルを作ることで、錬金術師たちが思いもよらなかった成果が得られるようになるかもしれません。「なぜ良いのか」のモデルができたら、錬金術師たちの仕事は人工知能にすぐ取られるので、今の試行錯誤できる環境を活用して人工知能を作る側になりたいものです。 ↩