目次
アドバンスドテクノロジーラボの塩澤繁です。
前回、「低コストで導入可能な最新リテールテック!(前半)」と題して、「顧客属性推定」と「視線検出」についてご紹介しましたが、今回は「動線分析」と「商品判別」への利用を想定した検証の取り組みをご紹介します。今回の取り組みも、Nvidia社のJetson Nano を利用し、弊社のオフィス内の環境を使用した検証となっています。
なお、Jetson Nanoに関しては、前回の記事でも紹介させていただいていますので、ご覧ください。
■動線分析
動線分析とは、店舗等に来た顧客が、どのようなルートで店舗内を移動したかを分析するものです。この分析により、通路の混雑具合や流量、棚や商品陳列の前で立ち止まる滞留時間なども分析することができます。
今回は技術検証の観点から、詳細な分析よりも、Jetson Nanoのエッジ端末でどの程度まで検知できるのかに主眼を置いて検証しました。
【検証の手順】
動線分析の検証の手順は次のようになっています。
・フロア内で人の流れが分岐する部分を見下ろす角度でカメラを設置
↓
・人物を検出
↓
・カメラ画角のイメージに線を描画
【使用技術と機材】
・Webカメラ
→Buffalo社 BSW20KM11BK(広角120度)
・人物検出
→(deep-sort-yolov3[https://github.com/Qidian213/deep_sort_yolov3])
今回は広範囲に映像を得るために、120度という広角撮影が可能なUSB接続のWebカメラを使用してみました。ハード的にも1080Pの画質で30FPSの動画にも対応しています。
●人物検出
人物検出に利用したのは、deep-sort-yolov3 というツールです。deep-sort-yolov3は、Darknet YOLOのV3のモデルを利用して人物検出を行い、同一人物にID(番号)を付与する機能を持っています。これにより、同じ番号をトラッキングすることが可能です。このツールは、実験的に作成されたツールのようですが、Githubにあるサンプル動画を見ると、以下のように人物検出とID付与ができることが確認できます。
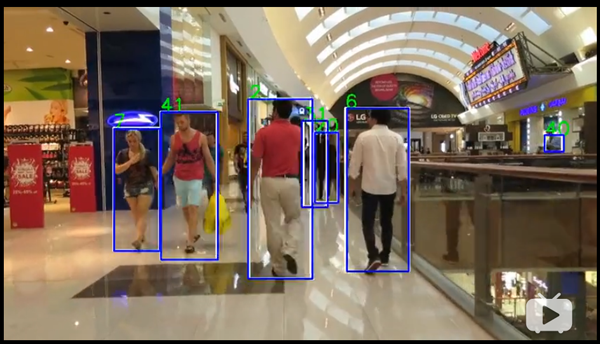
《deep-sort-yolov3 検出イメージ》
今回は、このツールを使って動線分析の検証を行いました。カメラや各種ライブラリが揃っていれば、deep-sort-yolov3 cloneとモデルデータを導入するだけで、動作確認を行うことが可能になります(コマンドは下部を参照)。また、検証に利用するJetson Nanoには、純粋な keras を導入できていないため、公式サイトでも導入をサポートしているtensorflowに含まれるtensorflow版keras を利用しました。これにより、import部分のソース(.py)を一部修正するだけでデモを実行することができます。
さらに、モデルデータに関して、deep-sort-yolov3の人物検出は、Darknet YOLO の.weight のモデルデータではなく、kerasで利用されている HDF5 形式を使用します。Darknetからダウンロードし、自前で変換することも可能ですが、変換済みモデルデータは、deep-sort-yolov3 のGithubのリンク先にあるため、実行前に入手しておく必要があります。
実際に、Jetson Nanoで以下のコマンドを実行してみます。
|
1 |
$ python3 demo.py |
UVCに対応したWebカメラを接続していれば、demo動作を確認できますが、何点か注意事項があります。
1つは、Jetson Nano上で他のアプリ(ブラウザなど)を起動しておくことは禁物という点です。このツールはメモリを多く消費するため、メモリ不足で起動しない可能性があります。
2つ目は、コマンドを叩いてから、画面が出るまで4分前後かかるという点です(環境に応じて所要時間は多少変わる可能性もあります)。
動作を見ると、0.9~1.0 FPS(秒間0.9~1コマ)と非常に遅いコマ送りのような感じになり、決して良いパフォーマンスとはいえません。しかし、人物の検出とID(番号)は付与されていたため、卓上で検証していた際は「人物が歩く速度を考慮すれば秒間1コマでもトラッキングは可能だろう」と考え開発を進めました。
画面上への線の描画など、ある程度、開発を終えた時点で、実際にフロアにカメラを設置してみました。

《設置したカメラ》
カメラの設置の際は、なるべく高めの場所に取り付けて、広範囲に撮影できるよう、そして死角が少なくなるように考慮しました。写る範囲はこのようなイメージです。

《実際のカメラ画像》
実際にdeep-sort-yolov3 を起動し、カメラの前で歩行を開始。

《歩行時の検知の様子》
すると、このように人物を検知した青枠が表示されいるものの、ID(番号)が付与されていません。試しに、その場で立ち止まってみるとID(番号)が付与されました。

《静止時の検知の様子》
deep-sort-yolov3 は、動画のコマ間の映像差異(特徴)から同一人物と判断していると推測されます。その一方で、動画のコマ間での移動距離が長く、画像が大きく変化した場合は、同一人物とは判断されず、その結果、IDが付与されないと考えられます。ちなみに、検証時はかなりゆっくり歩行していました。
これより、deep-sort-yolov3を利用した場合、1FPS程度の性能では、その場に滞留した場合などは検出ができるものの、徒歩の速度でも動線の検出は難しいことがわかりました。一方、卓上で検証していた際は、カメラの前で自分自身が徒歩のように大きく動作しなかったため検出できています。つまり、実際に現場に設置してみると期待通りに動かないという、典型的な事例になってしまったわけです。
●処理速度向上に向けて
そこで、今回は秒間あたりの処理速度を向上させるべく、同じDarknet YOLOでも軽量な、YOLOのTinyモデルを利用することにしました。これは、Tinyモデルが他のプロジェクトの中でJetson Nanoによる動作実績もあり、現状よりも秒間の検知数が改善するのではないかとの考えによります。
deep-sort-yolov3 のデフォルトでは、Tinyのモデルには対応していないため、次の手順で対応をしています。
・モデルと設定ファイルの入手
・モデルの変換(.weight → .h5)
・deep-sort-yolov3の改造
yolov3-tiny のモデルデータ(yolov3-tiny.weights)と設定ファイル(yolov3-tiny.cfg)はそれぞれYOLOのサイトから入手しています。続いて、deep-sort-yolov3 にも含まれる convert.py を使って、.weight を .h5 へコンバートします。ところが、付属のconvert.pyには yolov3-tiny のネットワークの一部が対応していないため、コンバートできません。そのため、MaxPoolingへの対応、さらにoutputのstreamをio.BytesIO()からio.StringIO()へ変更するなどして、.h5 ファイルへコンバートすることを可能にします。
|
1 |
$ python3 convert_tiny.py config_path weights_path output_path |
続いて、YOLOのモデルが変わりましたので、モデルに合わせたアンカーファイル(mode_data配下のyolo_anchors.txt)をyolov3-tiny への合わせ込みと、ソースの一部を修正して、Jetson Nano + deep-sort-yolov3のtinyモデルでの動作が可能になりました。
yolov3標準モデル→yolov3-tinyモデルに変更し、大きく改善した点は以下の通りです。
・起動時間:4分 → 2分
・検出速度:0.9~1.0FPS → 4.0~4.5FPS
起動時間の短縮もそうですが、秒間あたりの検出数が約4倍に大きく改善しました。これにより、徒歩スピードでのトラッキングがある程度可能になります。実際に動作させ、数人でフロアを歩き、検知領域の特定の点を結んでみた画像は以下のようになります。

《動線の検出》
一部、ポイント間が長い個所もありますが、ビジュアル的にはこのような感じになりました。
しかしながら、yolov3のデフォルトモデルから、yolov3-tinyへモデルを変更した際に、処理速度の改善だけではなく、低下してしまったものもありました。低下したのは、人物の検出精度です。yolov3標準モデルではその検出率の高さに定評がありましたが、yolov3-tinyでは、ディープラーニングのネットワーク層自体がyolov3よりも簡略し、動作が軽くなるように設定しているため、検出精度の低下は仕方がない部分です。
見た目で大きく変わった部分には、次のようなものがありました。

《検出精度の差》
yolov3標準モデルでは、小さく映った人物や、人物の一部が隠れていても比較的高い精度で検出している傾向にありました。しかし、yolov3-tinyモデルでは、斜めになった人物や、足が隠れるなどした場合には検出できていないケースが多く見られています。
店舗の通路など障害物が少ない場所であれば、モデルの違いによる大きな差が生じない可能性もありますが、精度の観点だけみると、yolov3標準モデルの方が上です。ただし、前述したように処理速度には問題があります。
今回は、新たに検出用のモデルなどは作成しませんでしたが、人物検知に特化したモデルでの高速化や、実際の動線分析を行うための、データの平面へのマッピングなど、まだ多くの考慮は必要です。ただし、今回の検証を通じて、Jetson Nanoのエッジ処理でもここまでの用途に利用できることがわかりました。
■商品判別
続いて、商品判別の例として、Jetson Nanoで冷蔵庫カメラの検証を行ってみましたので、ご紹介します。
店舗用の冷蔵庫でも、家庭用の冷蔵庫でも、庫内の在庫把握を自動で行えたらどうでしょうか? 店舗であれば「○○が売れました」という通知、家庭内でも「牛乳がなくなりました」など通知されるイメージです。
今回は、検証用に商品判別をディープラーニングのモデルを利用して行っています。これは以前のブログ
「カメラをかざすだけでカート内金額計算と最安値表示のAIショッピング計算機『ピクサム』のR&D」 にて紹介した際に作成したAIモデル(以下、ピクサムAI)を流用しています。リンゴやバナナなど果物の検出も可能ですが、まずはオフィスの冷蔵庫に複数の缶コーヒーを入れて検証してみました。
【検証の手順】
今回の概要は次のようになっており、これらをすべて、Jetson Nano上で実施します。
・カメラ(USB Webカメラ)で冷蔵庫内撮影
↓
・ピクサムAIを応用した画像分析
↓
・保存状態と比較し変化があれば通知
検証の場は、視線検知でも利用したガラス張りの冷蔵庫を利用しました。
一般家庭用の冷蔵庫に比べると、
・ドアではなく引き戸タイプ
・扉を閉めていても外光が入るため内部が見える
などの違いがあります。そのため、一般家庭用の冷蔵庫に応用するには、開閉のセンサーや、内部で明るく照らすためのライトを装備するなど、少し工夫が必要になります。
【使用技術と機材】
検証で使用した技術と機材は、次の通りです。
・Webカメラ
→Buffalo社 BSWHD06M
・商品検出
→Darknet Yolo AlexeyAB版[https://github.com/AlexeyAB/darknet]+ピクサムAIモデル
・GPIOスイッチ機材(後述)
→ Nvidia Jetson GPIO[https://github.com/NVIDIA/jetson-gpio]
●ピクサムAIの利用
まずは、まだJetsonでの動作実績のない、ピクサムAIの動作確認です。ピクサムAIは、本家のDarknetのYOLO V3がベースとなっていますが、今回は、画像認識時にスクリプトで動作させるため、AlexeyABのDarknet を使用しました。
AlexeyABのDarknetも本家と同じ学習済みのモデルを利用できます。clone後は、Darknetをビルドします。なお、不足しているライブラリなどがあれば追加が必要になりますが、基本的にはMakefileに以下の設定とmake コマンドのみでビルドが可能です。
|
1 2 3 4 5 6 7 8 9 10 |
GPU=1 CUDNN=1 CUDNN_HALF=1 OPENCV=1 AVX=0 OPENMP=0 LIBSO=1 ZED_CAMERA=0 : ARCH= -gencode arch=compute_53,code=[sm_53,compute_53](有効化) |
実行コマンドは次のようになります。
|
1 |
./darknet detector test shopping/shopping.data shopping/shopping_jetson.cfg shopping/shopping.weights -dont_show test.png |
shopping.xxx は、AIショッピング計算機「ピクサム」で使用した各種データです。本家のYOLO と異なるのは、-dont_show オプションが利用できるため、表示させない環境でも利用することができます。
●冷蔵庫内の撮影
続いて、冷蔵庫内の撮影です。カメラは、以下のように設置しました。

《冷蔵庫内に設置したカメラ》
実際に撮影された画像です。

《冷蔵庫内サンプル》
ここで、撮影方法を2通り検討しました。
今回、ピクサムAIを動作させ続けることで、ほぼリアルタイムでの商品検知を行うことが可能になります。しかし、Jetson Nanoで認識AIを稼働させたままとなるため、負荷も消費電力も高い状態が続きます。しかも、「商品の在庫を管理する」という目的ではそこまでリアルタイム性は求められません。
そこで、
・インターバル撮影(5分や10分に1回撮影)する方式
・冷蔵庫の開閉などのトリガーを使用する方式
を検討しました。
インターバル撮影は、cron などで撮影用のスクリプトを実行することで、実現は比較的容易にできます。今回は、Jetson Nano らしい、GPIO(General-purpose input/output)も試してみているので、ご紹介します。
Jetson Nano は、Raspberry Piと同じような40ピンのGPIOを持っています。その中の1つに、押しボタンスイッチを取り付けて、そのボタンをトリガーとするスクリプトの実行を実験しました。今回の検証では、押しボタンスイッチを利用していますが、冷蔵庫に合わせて開閉スイッチやセンサーなどに置き換えることも可能です。
ただし、Jetson Nano のGPIOを利用するには少し準備が必要です。公式のGithub[https://github.com/NVIDIA/jetson-gpio]にある手順または、以下の手順でGPIOを使用する準備を行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# Download wget https://github.com/NVIDIA/jetson-gpio/archive/master.zip sudo unzip master.zip -d /opt/nvidia/ cd /opt/nvidia/ sudo tar zcvf jetson-gpio_bk.tar.gz jetson-gpio ← バックアップ suro rm jetson-gpio sudo mv jetson-gpio-master jetson-gpio # Install Python Lib cd /opt/nvidia/jetson-gpio # python3 sudo python3 setup.py install → 必要に応じて pythonでも # Setting User Permissions sudo groupadd -f -r gpio sudo usermod -a -G gpio # Install custom rules cat /opt/nvidia/jetson-gpio/etc/99-gpio.rules sudo cp /opt/nvidia/jetson-gpio/etc/99-gpio.rules /etc/udev/rules.d/ # Reload the rules sudo udevadm control --reload-rules && sudo udevadm trigger |
続いて、GPIOを実際に利用してみたいと思いますが、Jetson Nanoの場合、単純なスイッチを取り付ける場合でもプルアップ(※)と呼ばれるスイッチの方式を利用する必要があります。そのため、ジャンパーワイヤー(オス-メス)を2本使って、抵抗付きのジャンパーワイヤーを作りました。
(※)単にショートorオープンではなく電源と対象ピン、GNDの3ピンを利用して安定化させる方式

《抵抗付きジャンパーワイヤー》
このワイヤーに、自作PCなどでおなじみの押しボタンスイッチケーブルを取り付けて利用します。

《スイッチ全体像》
回路図と実際の配線は次のようになっています。13番ピンをInputとして利用しています。
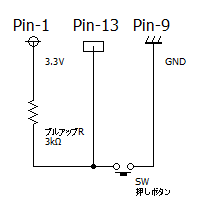
《プルアップ回路図》

《Jetsonへの配線の様子》
プルアップ抵抗は今回、3kΩ としましたが、正しい抵抗値がわかりませんでした(仕様が不明)。複数のサイトを検索すると、10kΩを取り付けている方もいるようですが、NvidiaのQAでは大きすぎるという見解もあります。今回、10kΩでは、オープン時にHigh状態が安定せず、3kΩの抵抗を利用して9kΩ(NG)→ 6kΩ(NG)→ 3kΩ(安定)となったため、3kΩを採用しています。状態確認だけのテストコードは次のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import Jetson.GPIO as GPIO GPIO.setmode(GPIO.BOARD) # 初期設定 GPIO.setup(13, GPIO.IN) # 入力設定 try: while True: if GPIO.input(13) == GPIO.HIGH: print("GPIO:13 = High") else: print("GPIO:13 = Low") finally: GPIO.cleanup() # GPIO初期化 |
これをベースに、冷蔵庫の扉の開閉時間などを考慮し、適度にSleepを入れて扉が open → close になったタイミングで撮影することを想定しました。
●商品認識
インターバル、または、スイッチによるトリガーで撮影された画像をピクサムAIに投入することで、以下のように3つの状況を想定してみました。

《1.2種類認識(初期状態)》

《2.1種類認識(1本売れた状態)》

《3.2種類認識(手に取った商品が戻された状態)》
これらの画像を見てわかるように、1枚目は2種類の缶コーヒーが認識されています。2枚目は1本なくなり(売れたとの仮定)庫内は1本になっています。3枚目は、1枚目にと比べると、青い缶の向きが変わっています。例えば「顧客が手に取ったものの、購入には至らなかった」というような状況を想定しています。
現状のピクサムAIでは特定の商品しか判別できませんが、このように、向きなどに変化があった場合でも、その商品を判別することができるようになっています。これにより冷蔵庫内の商品の増減を検知する仕組みが完成しました。
●通知
通知に関しての詳細は割愛しますが、画像認識結果のテキストログの差分を、メールやチャットツールなど(検証ではSlackを採用)に通知する仕組みを構築することで実現可能となります。
今回は、以前作成した学習モデルである、ピクサムAIのモデルをJetson Nanoに搭載して、特定の商品ではあるものの、商品認識を行うことができました。
ターゲットを冷蔵庫内の特定の商品に限定し、かつ、リアルタイムを考慮したものではありませんが、GPIOを利用したスイッチとの連携など、Jetson Nanoによる"エッジ処理×リテール"で利用するための検証を行うことができました。