目次
はじめに
こんにちは。チェコ料理とチェコビールの大ファンになったリクルートの長妻です。 (チェコは国民一人当たりの年間ビール消費量が世界一位とのこと!知らなかった…)
この度、2025年9月にチェコ・プラハで開催された 19th ACM Conference on Recommender Systems(RecSys 2025) の学会主催コンペ RecSys Challenge 2025 において、私たちのチーム「rec2」が優勝しました。本コンペティションには世界中から416チーム以上が参加し、その中で1位を獲得することができました。
本コンペティションには、武井、長谷川、澤田、阿内、長妻、米川の6名で参加しました。
本記事では、RecSys Challenge 2025で取り組んだ課題と得られた学びについて紹介します。

RecSys Challenge 2025の概要
コンペティションのテーマ
推薦システムの分野では、商品推薦、ユーザーの離脱予測、購買予測など、様々な予測タスクに機械学習が活用されています。従来、これらのタスクはそれぞれ個別のモデルとして構築されてきました。
しかし、このアプローチには以下のような課題があります:
- モデルの再利用性が低い: タスクごとに個別モデルを構築する必要がある
- システムの複雑性が高まる: 複数のモデルを管理・運用するコストが増大
- メンテナンスコストの増加: 各モデルの更新や改善を個別に行う必要がある
これらのタスクは同じユーザー行動データを基にしているにもかかわらず、効率的に活用できていないという問題がありました。
RecSys Challenge 2025のテーマは、この課題に対するアプローチとして「Universal Behavioral Profiles(UBP)」を開発することでした。UBPとは、複数のタスクに汎用的に適用可能なユーザー表現(埋め込み)のことです。ユーザーの行動パターンの本質を捉えることで、離脱予測や購買予測など様々なタスクで利用できる汎用的な表現を目指しています。
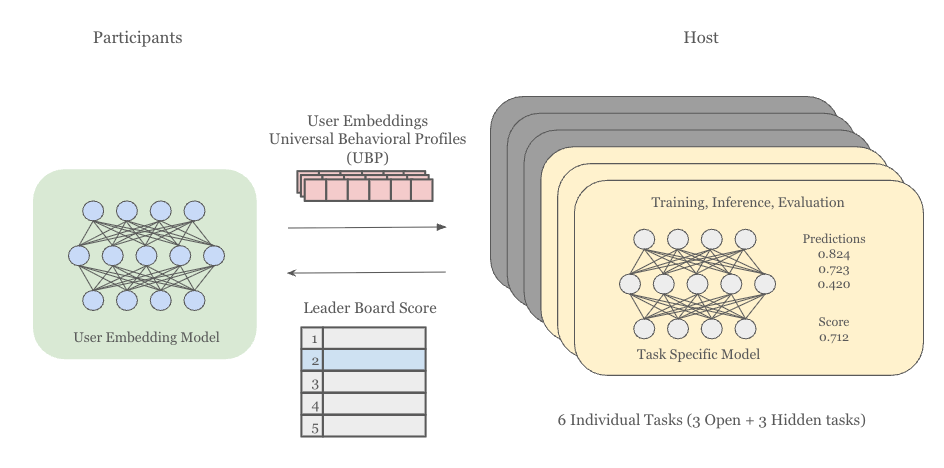
本コンペティションの最大の特徴は、予測モデルではなくユーザー埋め込み(UBP)を提出するという点です。参加者は自由にモデルを設計してユーザー埋め込みを生成しますが、評価は主催者が用意した固定の下流タスクモデルで行われます。このため、特定のタスクに過度に最適化された埋め込みではなく、6つの異なるタスク全てで高い性能を発揮する汎用的な表現が求められました。
後述する6つの評価タスクのうち3つの公開タスクについては、評価パイプラインが公開されており、参加者は学習データと検証データを分割してローカル環境でもある程度埋め込みの評価が可能になっていました。残る3つの非公開タスクについては、埋め込みを提出した時のみリーダーボード上でスコアを確認できる仕組みでした。
データセット
コンペティションでは、以下のようなデータセットが提供されました:
- 期間: 2022年6月23日〜11月9日
- 規模: 1.68億件のユーザーイベントログ
-
インタラクションタイプ: 5種類
- 購入(PRODUCT_BUY)
- カート追加(ADD_TO_CART)
- カート削除(REMOVE_FROM_CART)
- ページ閲覧(PAGE_VISIT)
- 検索(SEARCH_QUERY)
データは完全に匿名化されており、すべての特徴がIDレベルで表現されていました。商品名や検索クエリなどのテキスト情報はベクトル埋め込みとして、価格はパーセンタイルビンとして提供され、個人情報は完全に削除されている一方で、ユーザーと商品・URL等のエンティティ間のインタラクション情報は利用可能な形で保持されていました。
評価タスク
評価値は、100万人の選ばれたユーザー(以下、relevant clientsと呼びます)について、2022年11月10日〜12月7日の期間における行動を予測することで算出されます。このrelevant clientsは主催者が評価対象として選定したユーザー群であり、それ以外のユーザーはnon-relevant clientsとして区別されます。評価タスクは以下の6つで構成されていました:
公開タスク(3つ)
- Churn Prediction: アクティブユーザーの離脱を予測(評価指標: AUROC)
- Category Propensity: 指定された100カテゴリの購買予測(評価指標: 0.8 × AUROC + 0.1 × Novelty + 0.1 × Diversity)
- Product Propensity: 指定された100商品の購買予測(評価指標: 0.8 × AUROC + 0.1 × Novelty + 0.1 × Diversity)
非公開タスク(3つ)
- Hidden1: 全ユーザーの離脱に関する予測
- Hidden2: 20の未知商品に対する購買予測
- Hidden3: 100の価格帯に対する予測
非公開タスクは、コンペティション期間中はタスクの詳細が公開されず、提出時にスコアのみが確認できる仕組みでした。したがって、特定のタスクへ過学習せず、真に汎用的なユーザー表現を作成する必要がありました。コンペティション終了後に実際のタスク内容が公開され、上記の内容であることが明らかになりました。
最終的なリーダーボードのランキングは、これら6つのタスクにおける予測精度の総合評価に基づいて決定されました。
評価指標の詳細:Diversity と Novelty
Category PropensityとProduct Propensityのタスクでは、AUROCに加えてDiversity(多様性)とNovelty(新規性)が評価指標に含まれていました。これらの指標について、コンペティションでの具体的な定義を説明します。
Diversity(多様性):
Diversityは、推薦結果がどれだけ多様なアイテムを含んでいるかを測る指標です。本コンペティションでは、以下の手順で計算されます:
- 予測値(各アイテムに対するスコア)に要素ごとにシグモイド関数を適用
- 結果をL1正規化して確率分布に変換
- この分布のエントロピーを計算(エントロピーが高いほど分布が均一で多様性が高い)
- 全ユーザーの予測について平均を取り、最終的なDiversityスコアとする
エントロピーを用いることで、推薦スコアが特定のアイテムに集中せず、幅広いアイテムに分散しているかを評価します。例えば、少数のアイテムだけに高いスコアを付ける場合はDiversityが低く、多くのアイテムに均等にスコアを分配する場合はDiversityが高くなります。
Novelty(新規性):
Noveltyは、推薦結果がどれだけ人気の低いアイテムを含んでいるかを測る指標です。本コンペティションでは、以下のように計算されます:
- 各予測について、トップk個の推薦アイテムの人気度(全ユーザーにおける購入頻度など)の重み付き合計を計算
- この値を正規化し、人気度スコア1は「最も人気のあるk個のアイテムをモデルが絶対的な確信を持って予測している」状態に対応
- データのスパース性により生の人気度スコアは0に近く、対応するNoveltyスコアは1に近いため、1付近の小さな変化をより敏感に捉えるために、人気度スコアを100乗する
- Noveltyは1から人気度スコアを引いた値として算出される
これにより、人気の高いアイテムばかりを推薦するとNoveltyが低く、ニッチなアイテムや購入頻度の低いアイテムを推薦できるとNoveltyが高くなります。
これらの指標を組み込むことで、単純な予測精度だけでなく、推薦システムとしての実用性を総合的に評価できます。本コンペティションでは0.8 × AUROC + 0.1 × Novelty + 0.1 × Diversityという重み付けが用いられ、精度を重視しつつも新規性と多様性のバランスを取ることが求められました。
※評価指標の詳細については、 RecSys Challenge 2025公式サイト および 公式GitHubリポジトリ を参照してください。
解法の全体像
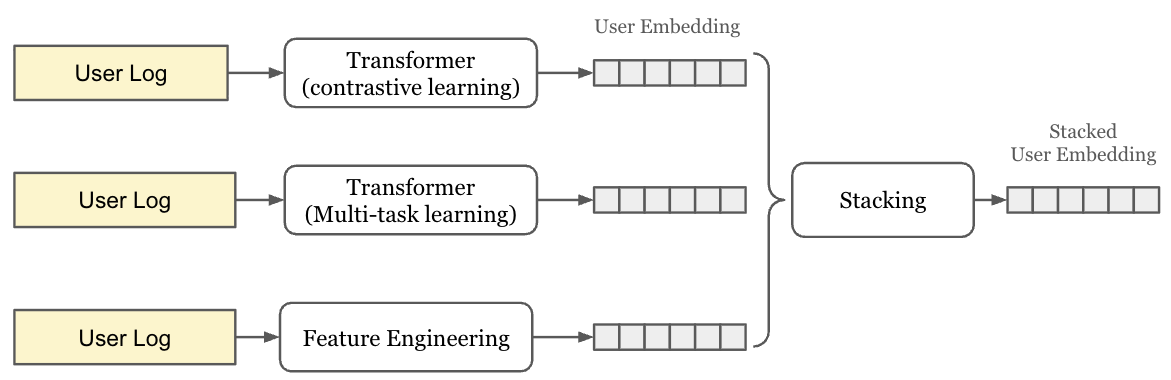
私たちのアプローチは、3種類の異なる手法で生成したユーザー埋め込みを、アンサンブル手法で統合するという戦略を採用しました。
3つの埋め込み生成手法
- Contrastive Learning Transformer: 対照学習を用いたTransformerベースの埋め込み
- Multi-task Learning with User Representation: マルチタスク学習フレームワークであるPLE(Progressive Layered Extraction)による埋め込み
- Aggregated Feature Embeddings: 統計特徴量を集約した埋め込み
これら3つの手法は、それぞれ異なるアプローチでユーザーの行動パターンを捉えます:
- Contrastive Learning Transformer: 時系列パターンと対照学習により汎用的な表現を得る
- Multi-task Learning: 複数タスクの同時学習によりタスク間の共通性を捉える
- Aggregated Features: 統計的な集約特徴により深層学習とは異なる視点で行動を捉える
アンサンブル学習
3つの異なる埋め込みをStacking-based Ensembleで統合し、最終的なユーザー埋め込みを生成しました。ニューラルネットワークベースのスタッキングにより、各埋め込みの強みを活かしながら最適な表現を学習しました。
主要な手法の紹介
ここでは、私たちが開発した3つの埋め込み生成手法とアンサンブル手法について詳しく説明します。
1. Contrastive Learning Transformer(3つの手法の中で最高性能)
概要
Contrastive Learning Transformerは、対照学習を用いて、同一ユーザーの過去と未来の行動パターンを表現空間上で整列させる手法です。これにより、複数の予測タスクに汎用的に適用可能なユーザー表現を学習します。
本手法では、時系列データを特定のタイムスタンプで分割します。分割点より前の期間をInput-term(入力期間・過去の行動)、後の期間をTarget-term(ターゲット期間・未来の行動)として扱います。同一ユーザーのInput-term埋め込みとTarget-term埋め込みを近づけ、異なるユーザーの埋め込みを遠ざけることで、ユーザーの行動特性を捉えた表現を学習します。
アーキテクチャ
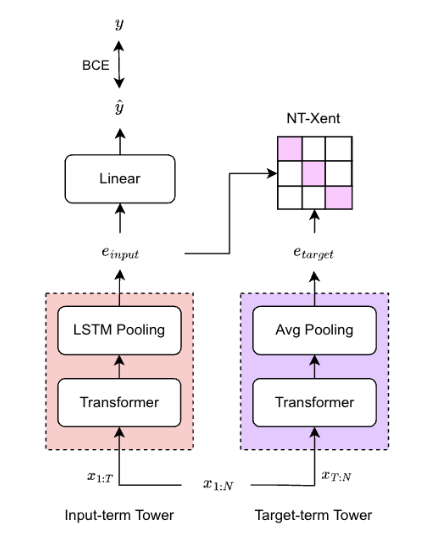
2つの独立したTransformerベースのタワーを使用します:
Input-term Tower(過去の行動を処理):
- 2層のTransformer層
- LSTM Pooling層
- 入力特徴:
- 基本イベント情報(イベントタイプ、SKU ID、URL ID、カテゴリID、価格)
- テキスト埋め込み(検索クエリ、商品名)
- 協調フィルタリング特徴(SVDで生成したSKUベクトル、URLベクトル)
- 時間特徴( Piecewise Linear Encoding で符号化)
Target-term Tower(未来の行動を処理):
- 1層のTransformer層
- Average Pooling層
- Input-term Towerと同様の特徴(時間特徴を除く)
Input-term Towerは行動の集約だけでなく時間的なパターンも捉え、未来の行動を予測できる埋め込みを生成します。一方、Target-term Towerは単純に行動を要約することを目的としています。
学習方法
学習では、以下の2つの損失関数を組み合わせました:
1. 対照学習損失(NT-Xent):
- 同一ユーザーのInput-term埋め込みとTarget-term埋め込みをpositive pairとして扱う
- 異なるユーザーの埋め込みをnegative pairとして扱う
- バッチ内ネガティブサンプリングを使用
- Target-termに行動が存在しないユーザーはInput-term Towerの損失計算から除外する
2. 補助タスク(Binary Cross Entropy):
- Input-term埋め込みからTarget-termにイベントが存在するかの二値分類を行う
- 未来の行動が続かないユーザーの特性をInput-term Towerに学習させる意図で実施
NT-XentとBCEの係数はどちらも1です。
また、サンプルの重み付けも非常に有効的に働きました。 前述の通り評価対象となるユーザーはrelevant clientsのみであることに着目し、以下の3つのサンプルの重み付けを検証しました。
- relevant clientsのみで学習
- 全てのユーザーで学習
- 別のモデルでrelevant clientsか否かの2値分類タスクを解き、relevant clientsには重み1を、それ以外にはrelevant clientsである確率を重みとして使用
その結果、3の方法が最もスコアが良かったため採用しました。
オプティマイザーには RAdamScheduleFree を用いました。 学習率スケジューリングに関するハイパーパラメータを特に意識することなく非常に高い精度を出せるため、学習率や他の重要なパラメータ調整に注力することができ、最終的なモデル精度の詰めに大きく貢献したと感じています。
推論時には、学習済みのInput-term Towerのみを使用し、すべてのイベントデータを入力して埋め込みを生成します。
2. Multi-task Learning with User Representation
概要
2つ目の手法は、Transformerによるユーザ表現のエンコーダとMulti-task Learning(
PLE: Progressive Layered Extraction
)を組み合わせたアプローチです。
エンコーダが出力したユーザ表現を元に複数の予測タスクについて最適化することで、エンコーダが汎用的なユーザ表現を出力することを期待しています。
アーキテクチャ
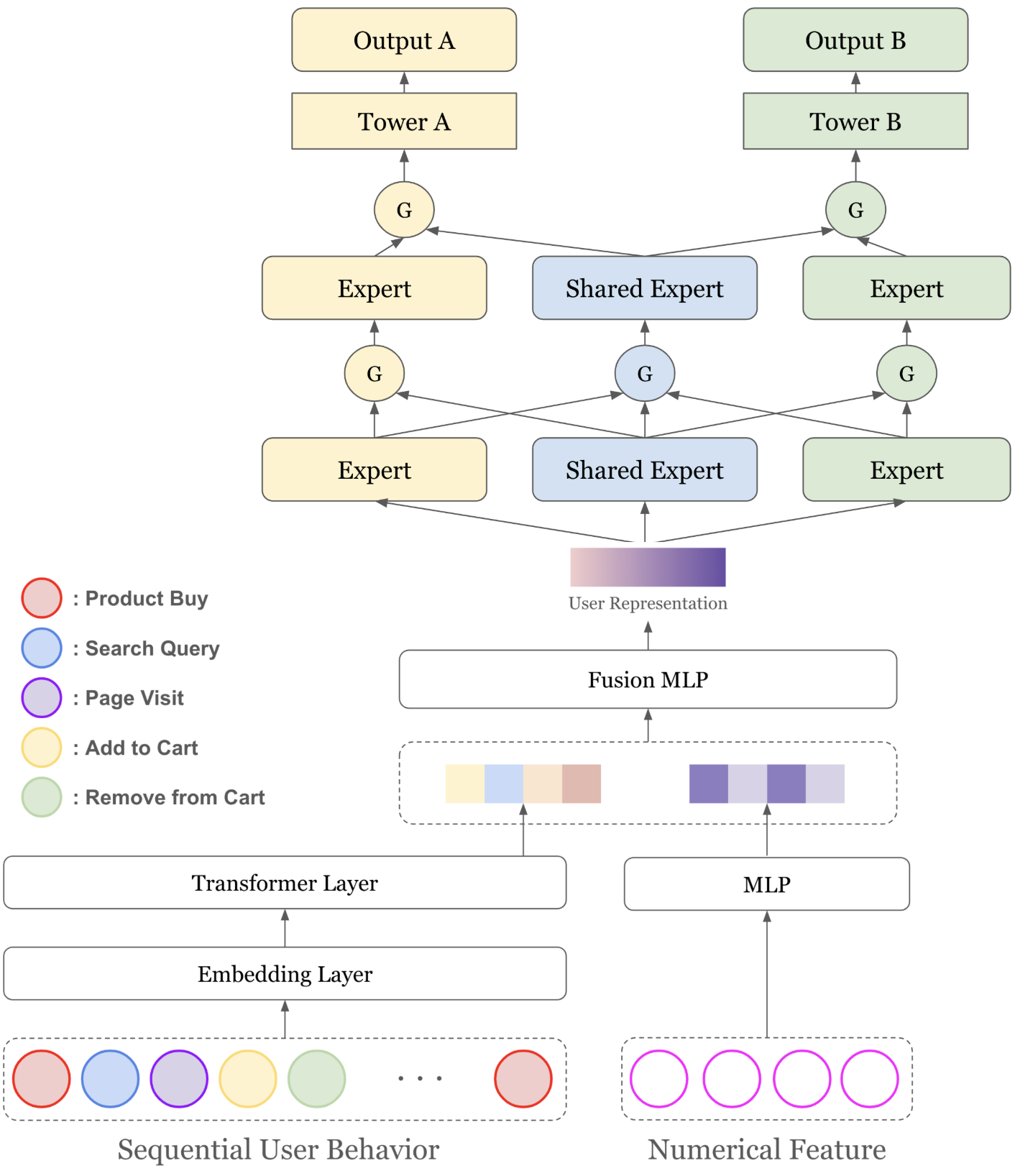
本手法は以下の3つの要素で構成されています:
1. Transformerエンコーダ: ユーザーのイベントシーケンスから時系列パターンを抽出
2. 統計特徴との融合: Transformerの出力と統計特徴(イベントタイプごとの行動回数、購入アイテムの平均価格など)を融合
3. PLE(Progressive Layered Extraction):
- Shared Expert:すべてのタスクで共有される特徴抽出層
- Task-specific Expert:各タスク専用の特徴抽出層
- Gating Network:エキスパートの出力を動的に重み付け
PLEは複数の層から成り、共有される表現とタスク固有の表現を段階的に抽出・精緻化するアーキテクチャになっています。
学習タスク
学習タスクとして、以下の8つのタスクについて同時に最適化しています:
-
2値分類:
- churn(離脱予測)
- cart_add(カート追加有無)
-
マルチラベル分類(100個の候補について分類):
- propensity_sku(購入アイテムのID)
- propensity_category(購入アイテムのカテゴリ)
- propensity_price(購入アイテムの価格帯)
- cart_sku(カート追加アイテムのID)
- cart_category(カート追加アイテムのカテゴリ)
- cart_price(カート追加アイテムの価格帯)
公開されているタスクだけでなく、自前で用意した補助的なタスクも導入することで、汎用的なユーザ表現の学習を狙っています。
上記のタスクにおいて、離脱有無やカート追加有無といった2値分類タスクは、全ユーザを予測対象としています。 一方で、購入アイテムのIDやカテゴリを予測するタスクは、そもそも購入ログを持つユーザのみが対象となります。
Multi-task Learningを行う際には、タスクごとに学習データの空間を分離し、各タスクの対象ユーザに対してのみ損失を計算するという形式で学習を実施しました。
これは、今回採用したPLEでの学習空間の設計を参考にしています。
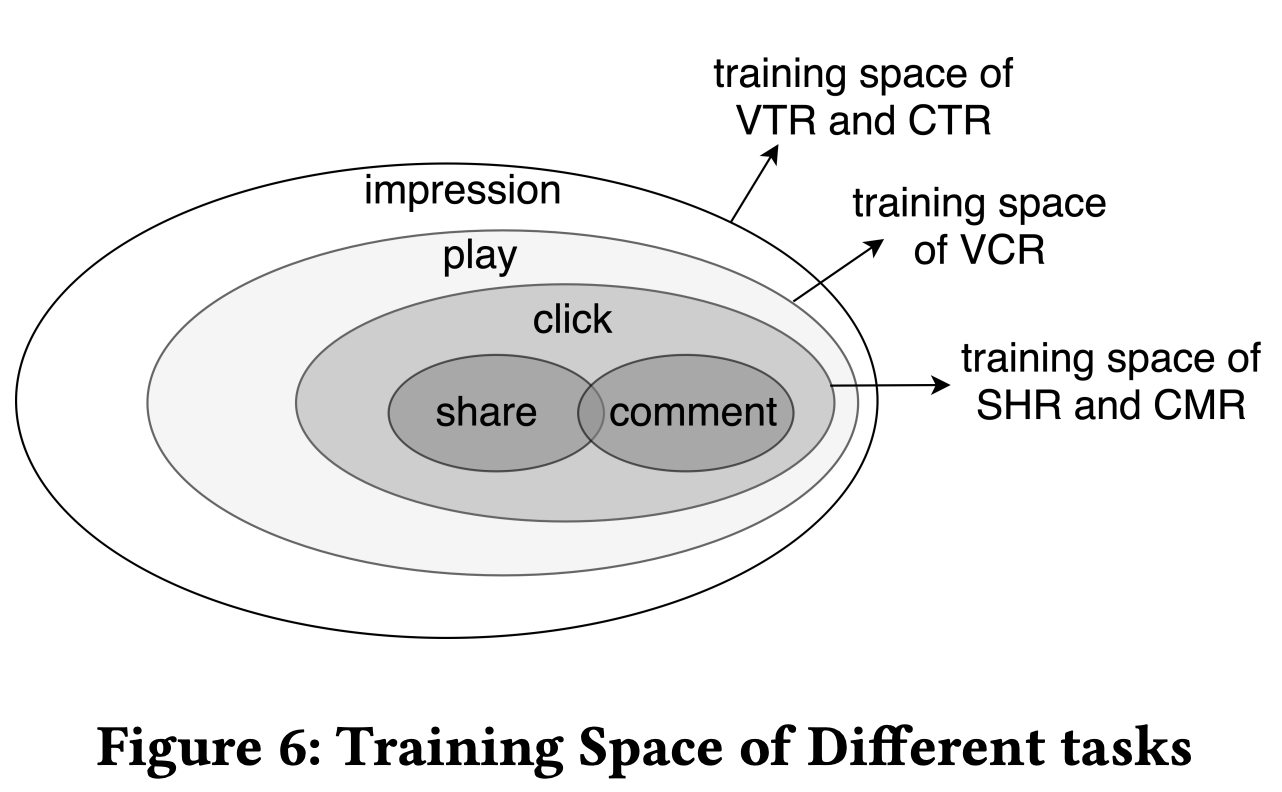
Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendationsより引用
各タスクの重み係数については、それぞれのタスクにおけるラベルの数や、ホスト側ロジックによるスコアなどを確認しながらチューニングを行いました。
最終的に、2値分類についてのタスクの重み係数は0.025、マルチラベル分類の重み係数は1として、損失の計算を行っています。
3. Aggregated Feature Embeddings
概要
3つ目の手法は、ユーザー特徴を表すのに重要な統計特徴量を作成・取捨選択し、効果的な組合せをベクトルとして表現します。
特徴構成
全体で166次元の特徴ベクトルを構築しました。インタラクションタイプごとに以下のような特徴を設計しています:
- SEARCH_QUERY(16次元): 検索クエリ埋め込みの時系列平均
- PAGE_VISIT(11次元): 上位10 URLの訪問回数 + ユニークURL数
- ADD_TO_CART(45次元): 上位10カテゴリの統計(カウント、最小・最大・平均価格、ユニークカテゴリ数)
- PRODUCT_BUY(45次元): 上位10カテゴリの統計(同上)
- REMOVE_FROM_CART(45次元): 上位10カテゴリの統計(同上)
- GLOBAL_STATS(4次元): 総購入数、総訪問数、カート放棄率、平均購入価格
これらの特徴は、ユーザーの検索興味、閲覧パターン、購買検討行動、実購買行動、購買判断の慎重さなど、多様な行動側面を捉えています。
4. Stacking-based Ensemble Strategy
概要
3つの異なる手法で生成した埋め込みを統合するため、ニューラルネットワークベースのスタッキングを採用しました。
アーキテクチャと学習
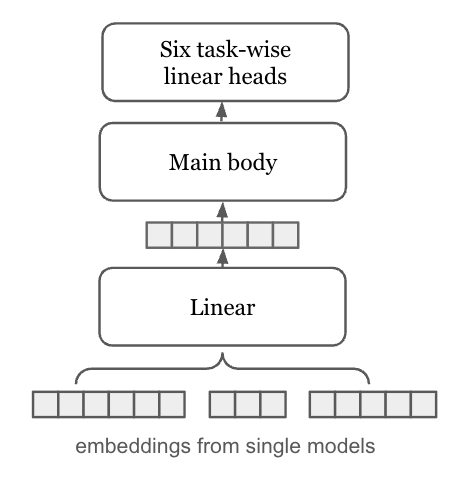
本アプローチでは、3つの埋め込みを入力として受け取り、下流タスクで使用される最終的な埋め込み(512次元)を出力します。
Embedding Transformation Layer:
- 各埋め込みを512次元に変換してGELU活性化
- 変換後の埋め込みを結合して統合表現を生成
Downstream Task Compliant Main Body:
- コンペティション主催者が提供した下流モデルと同じアーキテクチャを採用
- Inverted Bottleneck blocks(MobileNetV2の構造)を3層使用
- 入力の512次元を2048次元に投影し、残差ブロック内で4096次元に拡張
実験結果と考察
最終結果
| モデル | Churn | Category | SKU | Hidden1 | Hidden2 | Hidden3 | Total |
|---|---|---|---|---|---|---|---|
| Contrastive Learning Transformer | 0.7361 | 0.8139 | 0.8095 | 0.7701 | 0.7984 | 0.8128 | 4.7408 |
| Multi-task Learning | 0.7282 | 0.7916 | 0.7937 | 0.7424 | 0.8089 | 0.7963 | 4.6611 |
| Aggregated Features | 0.7083 | 0.7780 | 0.7627 | 0.7253 | 0.7134 | 0.7802 | 4.4679 |
| Ensemble(最終提出) | 0.7375 | 0.8179 | 0.8224 | 0.7717 | 0.8293 | 0.8161 | 4.7949 |
Contrastive Learning Transformerが最も高性能な単体モデルでしたが、アンサンブルにより全体スコアで約0.05ポイント(4.7408 → 4.7949)の向上を達成しました。特にHidden2タスク(未知商品の購買予測)において大きな改善(0.7984 → 0.8293)が見られ、異なる手法が補完的に精度を向上させていることが確認できました。
Ablation Study
Contrastive Learning Transformerの各コンポーネントの効果を検証しました。
| 設定 | Churn | Category | SKU | Total |
|---|---|---|---|---|
| Full | 0.8206 | 0.8137 | 0.8014 | 2.4357 |
| LSTM Poolingなし | 0.8178 | 0.8089 | 0.7984 | 2.4251 |
| relevant clientsのみで学習 | 0.8033 | 0.8008 | 0.7943 | 2.3984 |
LSTM Poolingは全タスクで精度向上に寄与しました。さらに重要な発見として、non-relevant clients(評価対象外のユーザー)も学習データに含めることで、大幅な性能向上が得られました。これは多様な学習データがモデルの汎化性能を高めることを示しています。
特徴量重要度の分析
Aggregated Feature Embeddingsの特徴重要度を分析しました(LightGBMを使用):
Churn予測:
- total_purchases(総購入数)
- purchase_c7_count(カテゴリ7の購入回数)
- add_cart_c7_count(カテゴリ7のカート追加回数)
コンバージョン行動に関連する特徴が重要で、ユーザーのロイヤルティを示す指標が離脱予測に有効であることが分かりました。
Category/SKU Propensity予測:
- rm_cart_c7_min(カテゴリ7のカート削除最小価格)
- total_purchases
- rm_cart_c1_mean(カテゴリ1のカート削除平均価格)
カテゴリ固有の集計特徴と購買特徴が重要で、購買検討行動(カート削除も含む)が将来の購買予測に有効であることが示されました。
学びと今後の展望
RecSys Challenge 2025を通じて、Universal Behavioral Profilesの可能性を実証できました。
主な学び:
- 対照学習とTransformerの組合せ: 汎用的なユーザー埋め込みに特に効果的。時系列パターンと対照学習の組合せが、未知のタスクにも汎化する表現を学習
- 多様なモデルのアンサンブル: 異なるアプローチ(深層学習ベース vs 統計ベース)を組み合わせることで、補完的な情報を捉え性能向上
- タスク非依存の表現学習: 複数の既知タスクで学習した埋め込みが、未知のタスク(Hidden tasks)も効果的に表現
今後の展望:
本コンペティションで開発した手法は、実サービスへの応用が期待できます。例えば、多様なサービスにおいて:
- 一度学習したユーザー埋め込みを、離脱予測・推薦・LTV予測など複数のタスクで再利用
- 新規タスク追加時も、既存の埋め込みを活用することで開発コストを削減
Universal Behavioral Profilesは、推薦システムの実用性と効率性を大きく向上させる可能性を秘めています。
おわりに
本記事では、RecSys Challenge 2025の優勝解法を紹介しました。
対照学習を用いたTransformer、多タスク学習、統計特徴の集約という3つの異なるアプローチを組み合わせ、それらをスタッキングで統合することで、汎用性の高いユーザー表現を実現しました。
本解法のコードは、GitHubで公開しています: https://github.com/yukia18/recsys-challenge-2025-1st-place
また、詳細な技術情報については論文をご参照ください: https://dl.acm.org/doi/10.1145/3758126.3758137
最後に、本コンペティションの開催に尽力されたSyneriseとRecSys Challenge 2025の運営チームの皆様に感謝申し上げます。