目次
1. はじめに
こんにちは!株式会社リクルートに2025年に新卒入社した井上翔太と杉山海斗と申します。
「AIや機械学習の分野でキャリアを築きたい」と考えている学生の皆さんにとって、入社後の研修は特に気になるポイントではないでしょうか。
リクルートでは、データスペシャリスト/エンジニアコースで入社した新卒向けに、現在最も注目されている技術の一つである 大規模言語モデル (LLM) をテーマにした専門研修を実施しています。
この研修のタイトルは 「つくって納得、つかって実感!大規模言語モデルことはじめ」。その名の通り、ただ講義を聞くだけでなく、実際に手を動かしながらLLMの仕組みを学び、簡単なアプリケーションを自分で作るなど、実践的な内容が盛り込まれていました。
研修のゴールは以下の3つ:
- 「大規模言語モデルとは何か?」を人に説明できるようになる
- ClosedモデルをAPIで利用し、簡単なアプリケーションを作れるようになる
- 活用に向いている/向いていないユースケースをイメージできるようになる
この記事では、私たちが受けた研修の内容として「 仕組み編 」「 現場の声編 」の2章に分けてご紹介します。現場の第一線で活躍するために、どのような学びからスタートするのか、その雰囲気を感じていただければ嬉しいです。
2. 大規模言語モデルとは
「大規模言語モデルって結局なんなの?」 そんな疑問からこの研修は始まり、まずは「大規模言語モデル」という言葉を「大規模」「言語モデル」と分解して理解するところからスタートしました。
言語モデルとは?
最初に解説されたのは、核となる「言語モデル」でした。これは、ある単語列がどれくらい「自然か」(=その並びで出現する確率がどれくらいか)を数値で表すモデルのことです。たとえば、
-
「私は今日学校へ行きました」→ 自然な文章であり、この単語の並びが出現する確率が高いと判断される。 -
「学校私は今日行きましたへ」→ 不自然な文章であり、この単語の並びが出現する確率が低いと判断される。
この時点では「なるほど、そういうものか」というくらいの理解度でした。しかし、この研修のすごいところは、ここからすぐにハンズオンに移る点です。
講義で聞いたばかりの「ある単語列がどれくらい自然かを数値で表す」という概念を実感するため、私たちはGoogle Colabを用いて、実際にPythonコードを動かしました。
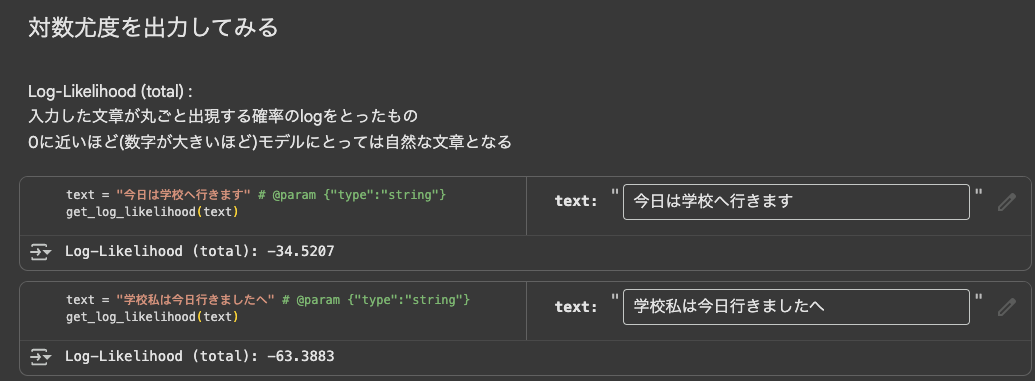
いくつかの文章をモデルに入力し、それぞれの「対数尤度(Log-Likelihood)」という数値を計算してみる、というものです。この数値が0に近いほど、モデルがその文章を「自然だ」と判断していることを意味します。
「私は今日学校へ行きました」と 「学校私は今日行きましたへ」を実際に入力して、後者の数値が明らかに低くなるのを見たとき、聞いたことを実際に理解する感覚がありました。これが、研修タイトルの「つかって実感!」の部分なのだと思います。
何が「大規模」なのか?
次に「大規模」という言葉が何を指しているのか、について解説されました。これは主に以下の3つの要素が、従来のモデルとは比較にならないほど大きいことを意味しています。
- モデルパラメータ数
- 学習データ量
- 必要となる計算資源
研修では、これら3つの要素を大きくすればするほど、モデルの性能(精度)が予測可能な形で向上していくという 「スケーリング則(Scaling Law)」 についても学びます。LLMの驚異的な性能が、こうした研究に裏打ちされた理論に基づいていることを知るのは、非常に興味深いポイントです。
どうやって動いているのか?
「大規模言語モデル」の基本を体感した上で、講義はLLMの内部構造へと進みます。私たちが入力した文章が、どのように処理され、返答として生成されるのか。そのプロセスは 「Tokenizer(トークナイザー)」 と 「Model(モデル)」 の2つの主要な役割に分けて解説されました。
- Tokenizer :文章をモデルが理解できる最小単位の「トークン」に分割し、数値IDに変換する翻訳機のような役割 。
- Model :入力された数値IDの並びから、次に続く確率が最も高いトークンを予測し、それを繰り返すことで文章を生成していくエンジン 。
Tokenizerの違いを体感する
ここでも、ただ説明を聞くだけではありません。再びハンズオンとして、異なる種類のTokenizerで同じ日本語の文章を分割させてみるという演習がありました。
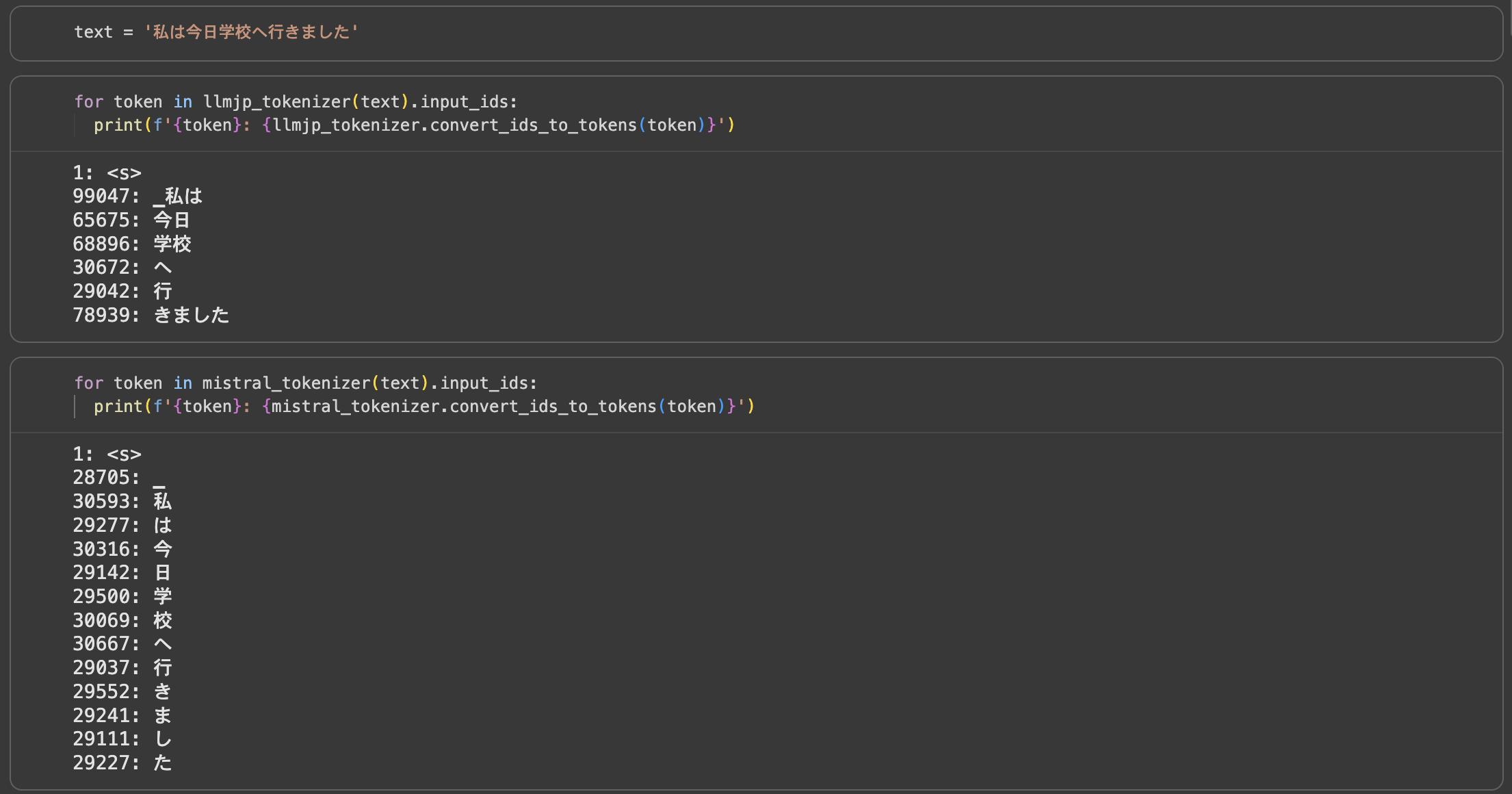
画像のように、日本語に最適化されたTokenizerは意味のある単語で分割するのに対し、最適化されていないTokenizerは一文字ずつ分割します。この違いを自分の目で確認することで、Tokenizerの重要性や設計思想の違いを理解することができました。
ClosedモデルとOpenモデル
次に、実際のモデルを使って入力から生成までの流れを体感しました。研修では、Closed Model(企業がAPI経由で提供するモデル)と Open Model(誰でもダウンロードして利用できるモデル)の両方を扱いました。
それぞれの特徴は以下の通りです:
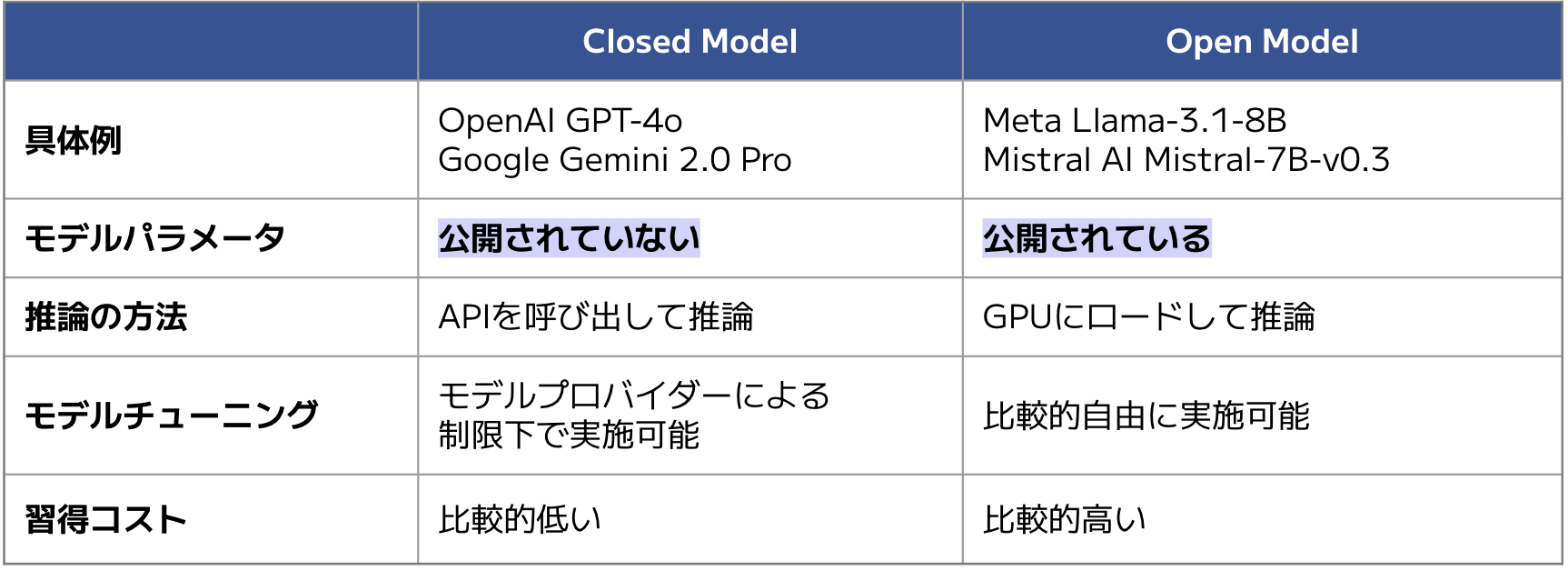
研修では、ClosedモデルとしてGeminiのAPIを呼び出し、Openモデルとして llm-jp-3-150m を自分の環境にロードして使用しました。両方を実際に動かすことで、それぞれの利用方法や特徴の違いを理解することができました。
実際に作ってみる
研修の最後には、これまでに学んだ知識を総動員するWorkshopがありました。ここでは、LLMを単なる文章生成ツールとしてではなく、より実用的なシステムの一部として組み込むための技術を、ハンズオン形式で開発していきました。
構造化 (Structured Output)
最初のテーマは、LLMの出力をプログラムで扱いやすくする 構造化 (Structured Output) です。 LLMは便利な反面、出力が自由な文章であるため、そのままではシステムに組み込みにくいことがあります。例えば「以下の文章から名前と職歴を抽出して」とお願いしても、モデルによっては毎回少しずつ違う形式で返してくるかもしれません。
このWorkshopでは、LLMへの指示に一工夫加えることで、出力をJSONのような決まった形式にきっちり整える演習を行いました。
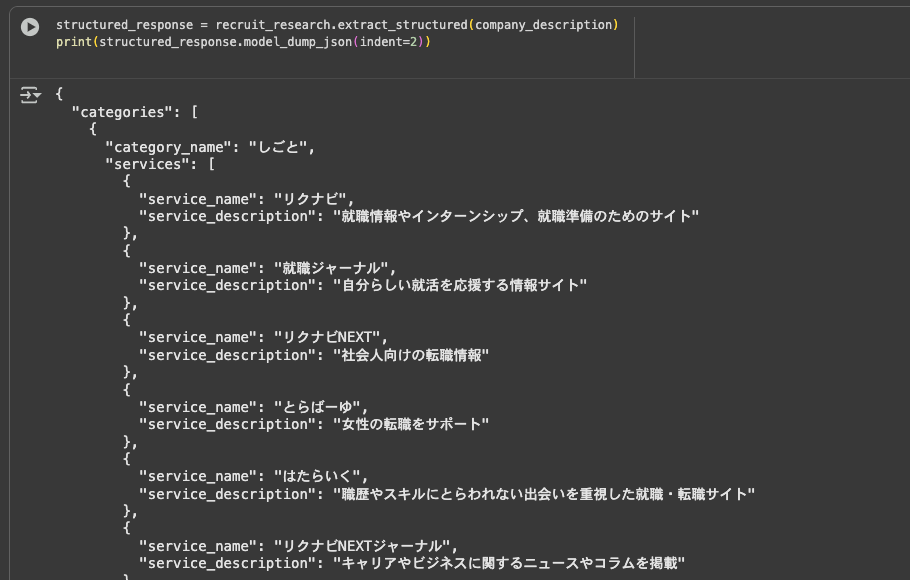
これまでフワッとした文章で返ってきていたものが、上の画像のようにカチッとしたデータ形式で出力されるのを見たとき、「これなら後続のプログラムで確実に処理できる!」と、LLMを実用化するイメージが明確になりました。
RAG (Retrieval Augmented Generation)
次に取り組んだのが、今最も注目されている技術の一つである RAG (Retrieval Augmented Generation) の簡易システム構築です。
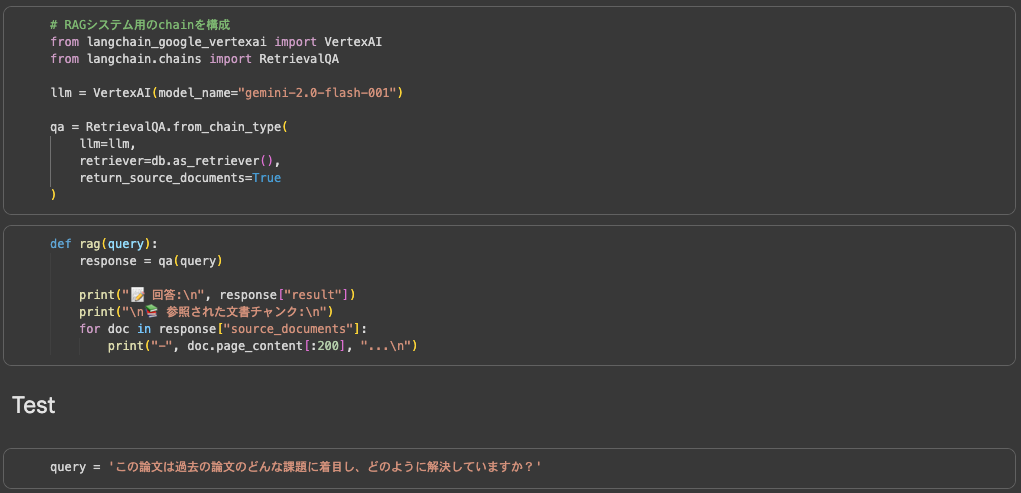
これは、LLMが元々持っている知識だけでは答えられない専門的な質問や、社内情報に関する問い合わせに答えるための技術です。簡単に言うと、「検索」と「文章生成」を組み合わせることで、LLMに特定の文書に基づいた正確な回答をさせる仕組みです。
この演習では、まず検索対象となるドキュメントを準備し、それを「文章埋め込みモデル」で検索可能なベクトル形式に変換しました。入力の際はユーザの質問に対して関連性の高いページを探し出し、関連情報と質問をセットでLLMに渡します。
この一連の流れを自分の手で実装することで、LLMに外部の専門知識を与え、より正確な回答をさせるとはどういうことかを、まさに「つくって納得」することができました。
3. リクルートでの現場活用
その後の講義では、データ室で実際にLLMプロダクトの開発をしている先輩に話を聞かせてもらいました。 Goodness(工夫すべき点)やAnti-pattern(良くない使い方)など、実際の経験をもとにしたリアルなお話がとても印象的でした。
Goodness、Anti-Pattern
登壇者の方から、LLMプロダクトの開発での工夫すべき点がいくつか挙げられていましたが、改めて見返してみて刺さった点がいくつかあります。
一点目は企画段階でHowが先行しないようにするという点です。 LLMを使ってプロダクトを作ろうとする場合は「LLMを利用したらこんなことができるのではないか → だからやろう」というようにHowが先行してしまいがちです。しかし、このような形でプロダクトの開発を進めると最終的に目指していることが曖昧になりがちです。ここが曖昧なまま進むとどう進めればいいかがわからなくなり、迷走してしまいます。
そのためユーザの課題ベースでプロダクトを作っていくことが大事になります。つまり「LLMを使う」というHowにとらわれず、ユーザにとって価値になるものは何で、それに対してLLMはどう有効に使えるかということを考えることが必要です。
同様の話としてチャットというHowにとらわれないというお話もありました。 チャットUIは極めて高い汎用性を持つことができますが、それはその分ユーザに入力の負荷をかけるということでもあります。 ChatGPTもチャットUIをもっていますが、それは汎用性を追求した上での結果であって、LLMを使ってプロダクトを作るときにチャットUIが本当にユーザの課題を解決するのか?という点を考える必要があります。
二点目はLLMの出力の評価についてです。 LLMの出力をStructured Outputできて、かつそれらの中身が評価しやすい場合は良いのですが、LLMの出力が文章となるケースもあります。 そのような場合にLLMの出力をどう評価するかは単純ではない問題ですが、評価指標を作るべきというお話でした。
評価指標を具体的に定めていない場合には「プロンプトを改善 → 人に意見を聞く → よくなった気がする」を無限に繰り返し、本当に良くなっているのか判断が難しいまま進んでしまうこともあります。 そのため、LLMの出力に求めるものとそれを測る評価指標を定義し、それベースで進めていくことが重要です。
評価指標を定めるのも難しいですが、人手でのこの出力は「良い、悪い」というアノテーションを行い、チーム内でその「良い、悪い」の感覚を言語化することで評価指標を定め、その指標ベースで改善をしていくことで継続的な改善ができるとのお話でした。
その他の点としてはLLM周りの環境は変わりやすいため、モデルやプロンプトを高速に変更していけるような実装をするなどがありました。
僕は今ちょうどLLMを使ったプロダクトの開発をしている中で、この研修内容を改めて見返してみると確かにそうだなと頷ける点ばかりでした。
おわりに
本記事を最後まで読んでいただきありがとうございます!
LLMの内部の仕組みから、LLMを使ったプロダクトにおけるGoodness/Anti Patternまで幅広い内容をカバーしており、とても勉強になる研修でした。 研修資料の一部(LLMの仕組みについてのパートのみ)は こちら で公開しているため、興味がある方はぜひ目を通してみてください!
まだまだ25卒研修に関するブログは投稿予定です。引き続き楽しみにしていてください!