この記事の効用
Python未経験者がPythonを使って、予測モデル作成のためのコーディングができるようになる
想定する読者
- データ解析の文脈でPythonに興味はあるが、まださわったことのない人
- そろそろMATLAB以外の言語もやってみようかなと思っている人
- プログラミング言語自体の勉強は積極的に行ってこなかった方
目次
- 自己紹介(スキップ可能)
- Pythonをすすめる理由
- MATLABに慣れたユーザーのためのPython環境構築
- MATLABのつもりでPython使おうとするとひっかかるところ
- 脚注
自己紹介
この7月からリクルートテクノロジーズのアドバンスドテクノロジーラボ(以下、ATLと略す)所属になった大杉直也です。よろしくお願いします。一応の専門は信号処理とか機械学習です。しかし、エンジニアというわけではなく、基礎研究で有名な 某研究所で昨年度までサルの脳波の解析を行っていました。
脳科学の分野ではデータ解析にMATLABを使用するのが一般的だったようで、自分もM1の頃から5年ほどMATLABをさわっていました。やはりMATLABは有償のソフトウェアでサポートがしっかりしていることもあり1 、再現性と信頼性が大切なアカデミックの世界では好まれていたのでしょう。自分もMATLABのsignal processing toolboxには大変お世話になりました。
そんな私が7月からATL所属になり、MATLABが使われていない環境に身を置くことになった2ため、流行のPythonを使ってみました。そして、少しさわってみたら「もうMATLABはいいかな」という気にさせられました。
Python歴1ヶ月の自分ですが、はまったツボを記事にしてみることでPythonを初めてみる心理障壁が少しでも下がれば幸いです。
Pythonをすすめる理由
私がPythonを好きになった理由とその内訳:
- scikitlearnがすばらしかった(およそ80%)
- 他にもモジュールが充実していた(およそ10%)
- 環境構築が楽だった(およそ5%)
- MeCabがあっさりと使えた(およそ3%)
- MATLABっぽい描画が簡単にできた(およそ2%)
なのでPythonそれ自体というよりもPythonのモジュールのひとつであるscikitlearnに力をいれて説明します。
scikitlearnは機械学習系のモジュールです。機械学習にまったく興味ない方でもPythonのオブジェクト指向な書き方のよい例になっているので、参考になるかと思います。
t検定などの仮説検定に興味がある方のためのscipyというモジュールのリファレンスをはっておきます。scipyはscienceで使用される数学をまとめたモジュールです。便利そうな関数がそろっています
scikitlearnの解説のため、特徴量にラベルの情報が含まれているかを、とりあえずサポートベクターマシン(以下、SVMと略す)を交差確認法で確認するといったユースケースを考えます。データはローカルにある2つのcsvファイルに書き込まれているものとします(特徴量(従属変数)の値(数字)が書かれたものと、その教師ラベル(目的変数)が書かれたもの)。
以下、そのコードです。短い。実質7行。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import numpy import sklearn #ファイル読み込み train = numpy.genfromtxt('./data/training.csv',delimiter=',',dtype='float') label = numpy.genfromtxt('./data/label.csv',delimiter=',',dtype='float') #モデル定義 model = sklearn.svm.SVC() #10-fold 交差確認法 score = sklearn.cross_validation.cross_val_score(model,train,label,cv=10) #成績表示 print score.mean() |
では、このコードを1行ずつ追いかけてみましょう。
import numpyとimport sklearnとあるのは
numpy, scikitlearnの2つのモジュールを利用します、といった宣言です。
train = numpy.genfromtxt('./data/training.csv',deliminiter=',',dtype='float')
と
label = numpy.genfromtxt('./data/label.csv',deliminiter=',',dtype='float')
でローカルのcsvファイルをPythonに読み込んでいます。ここでは特徴量データをtrainという名前の変数(観測数X特徴量数)、ラベルデータをlabelという名前の変数(観測数)に格納しました3。
numpy.genfromtxtではdeliminiterとdtypeの2つのオプションを指定しています。deliminiterは読み込むファイルの区切り文字が何かを指定しています。dtypeは読み込んだファイルをどのようなデータ型で変数に格納するかを指定しています。
numpy.genfromtxtで読み込むとPython標準のリスト4ではなく、numpyのarrayという形式5で読み込まれます。このnumpyのarray形式はMATLABの行列みたいな使い方をするためにあるのですが、MATLABと違って動的にサイズを変えることができない点には注意してください。
model = sklearn.svm.SVC()ではどのようなモデルを使うのかをscikitlearnのメソッドで指定しています。
!!!!!!!!!!この行がMATLABとの最大の違いであり、自分が最も感動した点です。!!!!!!!!!!
ここでは
- どのようなモデルを使うか
- そのハイパーパラメータはどんな値か
を指定しています。
オブジェクト指向に多少慣れている人にはコンストラクタだと言えば伝わると思います。オブジェクト指向何それ食えるの状態のMATLABユーザーもいると思うので6簡単に補足するとオブジェクトとは「構造体に関数が引っ付いたもので、その関数を使用すると構造体の値も変えられる便利なもの」です。今回のケースにはこの理解で十分です。
1の点ですが、今回はSVMを呼び出していますが他にもランダムフォレストや一般化線形回帰なども指定できます。詳細は公式ページにて
2の点ですが、サンプルコードでは何も指定していないのでデフォルトの値(例えばカーネルはデフォルトではrbf)になっていますが、カーネルに何を使用するかやC値やノルムをどうするかなど各種ハイパーパラメータをここの引数で指定できます8。
このように今回はmodelという名前のオブジェクトがrbfカーネルのSVMになりました。
modelのパラメータ学習にはfitという関数を使います。
|
1 2 |
model.fit(train,label) |
パラメータを学習できたら、その出力はpredictという関数で以下のようにかけばOKです。
|
1 2 |
model.predict(train) |
MATLABでは中々ない書き方ですが、これのおかげで交差確認法などが楽に書けます9
score = sklearn.cross_validation.cross_val_score(model,train,label,cv=10)で交差確認法で求めた予測率をscoreという変数に格納しています。
今回は10-fold 交差確認法です。
楽です。本当に
モデルをそのまま引数にとれるので、このモデルのハイパーパラメータを調整したり、違うモデルを試したりするには直前のmodelを呼び出す1行をわずかに書き換えるだけです。
例えばL2-ロジスティック回帰は以下の通りです。
|
1 2 |
model = sklearn.linear_model.LogisticRegression(penalty='l2’) |
最後に
score = sklearn.cross_validation.cross_val_score(model,train,label,cv=10)
で交差確認法で導出された値の平均値をコンソールに出力しています。print 変数名で変数の中身がコンソールに出力されます。
sklearn.cross_validation.cross_val_scoreは前述のnumpyのarray形式になります。
array形式はsumとかmeanとかの基本的な関数を持っています。
平均値の導出は
|
1 2 |
numpy.mean(score) |
と書く他に
|
1 2 |
score.mean() |
とも書けます。どっちの方が好ましいのかはよくわかっていないのですが、後者の方が書くのが楽なので、そちらを多用しております。
ここまでで自分がPythonを好きになった理由の80%近くの説明が終わりました。他にも便利なモジュールがたくさんあるのですが(理由の10%)、私自身がまだまだ勉強中ということもあり今回の記事はscikitlearnの教師付き学習の簡単なサンプルで留めます。反響(=PV数)あれば他の例で今回みたいな簡単なユースケースを書きます。
もちろんMATLABでもwekaなどの外部のツールを使用すれば似たような書き方ができると思いますが、以上のコードをチェックするための環境構築が思いのほか簡単であった点もポイント高いです10(5%)
以下、自分が導入しやすい&使いやすいと感じた環境です。
MATLABに慣れたユーザーのためのPython環境構築
用意するもの
両方とも検索には不便な名前なのですが、導入が非常に簡単で上記のコードを簡単に確認できます。
下の写真はmacでの導入後のイメージ図です。Windowsでも似たようなものです。
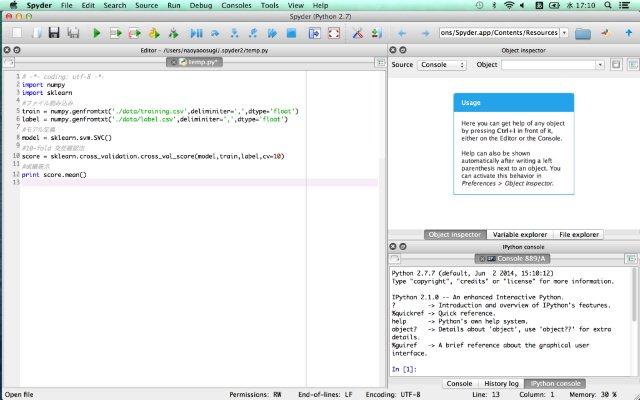
まずanacondaについて解説します。
anacondaにはPythonの便利パッケージが大量に含まれており、有名なパッケージはanacondaを使えば簡単にインストールやアップデートが可能です。
下記のサイトからDLしてください。インストールにも大変なところはないと思うので割愛いたします。
https://store.continuum.io/cshop/anaconda/
anacondaだけで先ほどのコードが使用可能になるのですが、MATLABのGUIに慣れ親しんだ人ですとCUIで全部操作するのは取っ付きにくいと思います。
そこでspyderという開発環境も紹介いたします。
anacondaの公式ページによるとanaconda内のXXXでダウンロードできるようですが、どうやらリンクが切れているようです(2014年8月現在)
なので以下のサイトからDLしてインストールしましょう。
https://bitbucket.org/spyder-ide/spyderlib/downloads
ancondaが既にインストールしてあればspyderを起動した際にanacondaのPythonが立ち上がると思うのですがいかがでしょうか?
環境構築は以上です。このanacondaとspyderでたいていの解析はできそうです11。
本記事のメインコンテンツは以上で終わりです。
自分もまだまだ初学者なので至らない点も多々ある拙い記事を読んでいただき、ありがとうございました。
MATLABのつもりでPython使おうとするとひっかかりそうなところ
最後にMATLABユーザーがPythonでつまりやすそうな点を列挙しておきます。
1. for やif の中身が括弧でなくてインデントで区切られる
こちらをご覧ください。
|
1 2 3 4 5 6 |
count = 0 for i in [0,1,2,3]: count = count + 1 print count |
Python初見のMATLABユーザーではforがどこまで続いているのか分かりにくいかと思います。
この場合countの値はfor文が終わった一度しか出力されません。
Pythonではインデント12をそろえることでifやforの範囲が定義されています。
慣れればどうってことはないのですが、自分はエディタからコンソールにコピペして実行するときにインデントがそろっていないことが理由でしばしばエラーを起こしてました。
2.途中結果の保存が面倒
MATLABは変数だろうが変数のセットだろうが図だろうが途中結果をsaveやsaveasコマンドで簡単13に保存できましたが、Pythonではちょっとハードル高いようです。
numpyのarray形式ならnumpy.saveとnumpy.loadでいけるのですが、さきほどの学習したモデルパラメータごと保存したいときなどには使用できません。
pickleというモジュールを使うのが良さそうですが、まだ自分もどのやり方がベストか決めかねてます。いい方法が見つかったら追記します。
3.日本語文字コードの扱いが若干面倒
日本語の扱いに面倒なところがあります。
基本は
ファイル入力→ユニコードにエンコード→処理→UTF-8などにデコード→ファイル出力
になるのですが、面倒な点がいくつかあります。長くなるので今回は割愛いたします。
脚注
- MATLABはMathWorks社の製品です。メール等のサポートの手厚さは素晴らしいです。↩
- 予算不足だと誤解された場合に備えて念のための補足。予算不足だとかケチだとかは全くないです↩
- 今回は現在のディレクトリからの相対パス./data/training.csv と./data/label.csvでファイル場所を指定していますが、当然絶対パスでも指定できます。現在のディレクトリを変更する場合はcd コマンドを使えばOKです。↩
- Pythonのデータ形式であるリストは色々なタイプのデータをごちゃまぜに格納できます。リストにリストも格納可能↩
- arrayは単一のデータ型しか格納できないので、最初にデータ型を指定する必要があります。省略しても自動でデータ型を決定してくれますが、この手のものはいちいち自分で宣言する癖をつけた方が不幸にならずにすみます↩
-
数ヶ月前の自分です。ろくにさわったことがあるのがMATLABくらいでした。MATLABの代表的なコンストラクタは
figure()だといえば、オブジェクトについてピンとくるのではないでしょうか。↩ - 線形に特化したSVMで、計算時間や要求されるメモリが非常に少ないです。感動しました。↩
- プロセッサを並列に使用するかまでここで選択できます。すげぇ↩
- ブースティングなどのアセンブル学習もモデルを引数にすることで楽に実装できます。↩
- MATLABを新しい計算機に入れ直すさいにライセンスまわりの認証があり、個人的にとても面倒です。仕方ないこととは思いますが!↩
- さすがに日本語の形態素解析ツールのMeCab-Pythonはサポートされていなかったので自分でいれる必要がありました↩
- タブとかスペースのことです。Pythonでは意味のないスペースが行頭にあるとエラーになります。↩
- saveとsaveasで引数の順番が違うとかの罠はありますが、今思えば簡単でした。↩