目次
APソリューショングループの大杉です。
SFCの修士2年の加藤慶之さんが、機械学習を中心としたデータ分析について勉強してみたいと言ってきたので、OJT的に3ヶ月間ほど一緒に仕事をさせてもらいました。
その中で機械学習ツールを共同開発したのですが、世間に公開できるレベルまで作りこむことが出来たのでリクルートテクノロジーズのgithubレポジトリでxchainerという名前で公開することとなりました。
このツールについて、加藤さんが記事を書いてくれたので、本人の承諾のもと、ここにその記事も公開します。以下、加藤さんの記事です。
はじめに
近頃話題の、PFIが開発しているChainerというニューラルネットワークのライブラリはご存知の方も多いかと思います。ネットワーク構造の定義なども直観的に書くことができてとても素敵なライブラリなのですが、Scikit-learn1との互換性がないので予測率の評価が物足りなかったり、学習器を定義する際の記述が煩雑になりがちだったりしていました。そんなわけで、Scikit-learnの評価手法をそのまま使えて、かつ必要最低限の記述で学習器を定義できるよう、Chainerの拡張モジュールxchainerを作ることにしました。
先行ライブラリとしては、Scikit-learn likeなchainerインタフェースscikit-chainerがあります。(僕も最初同じライブラリ名で開発していたのですが先を越されました笑)
コンセプト
つつむ:ChainerをScikit-learnの学習器にする
まず最初に、ChainerをScikit-learnの学習器にしてあげます。このために、Scikit-learnの学習器の基底クラスである BaseEstimator を継承したChainerのインタフェースクラスを作ります。このクラスに求められるのは、 fit と predict の二つのメソッドです。大雑把な言い方をすれば、この二つを用意してあげればChainerのネットワークをScikit-learn化するお仕事はほぼ終了なのですが、それだけではあんまり嬉しくないので、他の機能を盛り込んでいきます。
まとめる:Chainerの学習プロセスを抽象化する
次にほしいのは、抽象化された学習プロセスです。ニューラルネットワークの場合、学習プロセスがネットワークのデザインに大きく依存する部分がありますが、それでも共通部分を切り出してパラメータ化することはできます。たとえば、次の二つがあげられます。
- エポック
- バッチサイズ
Chainerでは、ミニバッチを用いた学習を行うので、この二つは必ず設定することになります。さて、この二つはパラメータで指定できるとして、改めて学習プロセスを見てみると、未定義の部分としては forwardとbackwardしか残っていない ことがわかります。ここがネットワークのデザインに大きく依存する部分であり、逆に言えばここ以外にネットワークのデザインに合わせて定義しなければならない部分はありません。
ではどのようにforwardとbackwardを書くのか、ということになりますが、ここでChainerの FunctionSet の素晴らしさが実感できます。というのも、Chainerでは FunctionSet のおかげで backwardも一般化できてしまう のです。ここでパラメータとして渡すのは次の二つです。
- 損失関数
- 最適化手法
損失関数は chainer.functions で、最適化手法は chainer.optimizers で提供されているものからそれぞれ選択できます。
なぜこのようなことができるのかというと、Chainerでは FunctionSet がネットワークの各層ごとにニューロンのパラメータを管理し、これを損失関数と最適化手法を用いて随時更新していくことで学習を行うからです。ネットワークの各層の構造や伝搬手法の定義はforwardが担当します。つまり、基本的に 個別定義が必要なのはforwardのみ ということになります。
つなぐ:複雑なネットワーク構造を簡単に扱う
少し特殊なケースもあるかもしれません。 ネットワークの層をツリー状に連結する ようなネットワーク構造です。このようなネットワーク構造は、可能性の一つとして無いわけではありません。全く異なる二つの事柄が作用しあって、一つの結果をもたらす現象を表現するためのネットワークを考えます。たとえば、ミュージックビデオにおいて音楽と動画はそれぞれに独立していますが、一つのミュージックビデオとして違和感なく存在しています。このとき、音楽と動画それぞれのデータを別々に入力し、最終的に混ぜ合わせるようなネットワークでミュージックビデオという現象を表現しようとするのは一つの手段としてありうるでしょう。
Chainerの提供するネットワーク構造は自由度が非常に高いので、そのようなネットワークを扱うことは可能です。しかし、バッチ処理におけるデータの切り分けや、構造の定義など、定義が煩雑になることは避けられません。
このようなケースを簡単に扱うために、xchainerでは エントリーポイント と 親子ネットワーク の考え方を導入します。エントリーポイントとは、ネットワーク構造全体の中でデータの入力を受け付ける部分、親子ネットワークとは、ツリー状になったネットワーク構造のことを指します。親子ネットワークの各ノードは、それぞれ小さなネットワーク構造になっていて、子ノードのネットワークにおける処理結果は親ノードに送られます。最下層の子ノードから順に処理を行い、最終的に最上位の親ノードの出力結果をネットワーク全体の出力結果として扱います。各ノードごとに任意の数のエントリーポイントを作ることができますが、最下層の子ノードは必ずエントリーポイントを持つことになります。ミュージックビデオの例では、親子ネットワークを構成するノードは三つあります。一つ目が音楽を担当するネットワーク構造、二つ目が動画を担当するネットワーク構造、三つ目は一つ目と二つ目の結果を混ぜ合わせるネットワーク構造です。これら三つについて、エントリーポイントと親子関係を整理すると以下のようになります。
- 音楽を担当するネットワーク構造(エントリーポイント:音楽データ、親ノード:混ぜ合わせるネットワーク構造、子ノード:なし)
- 動画を担当するネットワーク構造(エントリーポイント:動画データ、親ノード:混ぜ合わせるネットワーク構造、子ノード:なし)
- 混ぜ合わせるネットワーク構造(エントリーポイント:なし、親ノード:なし、子ノード:音楽・動画を担当するネットワーク構造)
このように、小さなネットワーク同士の親子関係と、データの入力部分を定義することで、 複雑なネットワーク構造をセグメントごとに小分けにして扱う ことができるようになります。
使い方とサンプル
xchainerは上記のコンセプトに基づいた機能を提供します。ここでは、手書き文字認識を行う学習器のコードを例に、xchainerの使い方について話を進めていきます。インストールについては、xchainerリポジトリのREADMEをご参照ください。
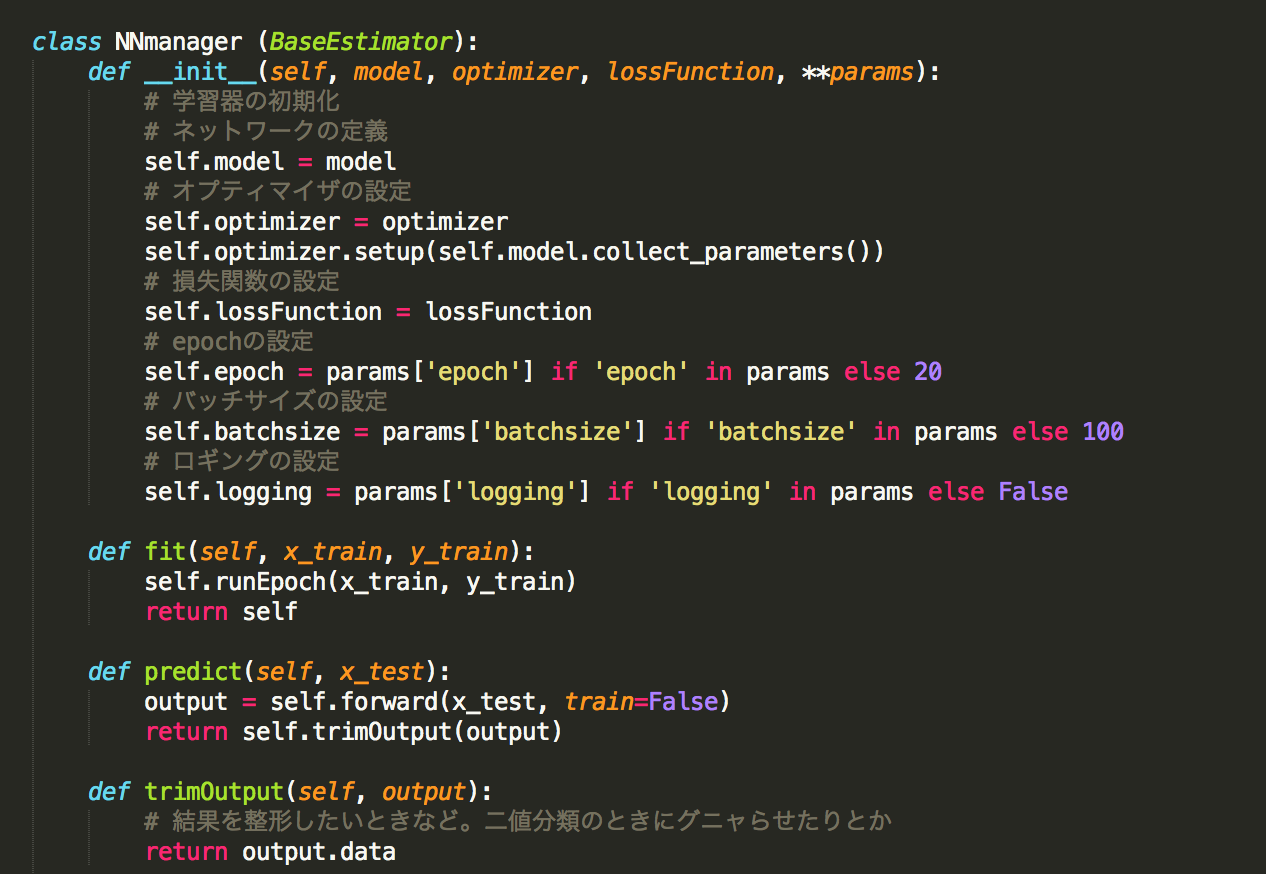
つつむ、まとめる:NNmanager
「つつむ」と「まとめる」を実現するクラスが NNmanager です。 NNmanager は学習器の枠組みを提供するインタフェースとして実装されています。 NNmanager を継承し、目的に応じて拡張することで、学習器を作ることができます。 NNmanager はScikit-learnの BaseEstimater を継承しているため、交差検定やAUC評価など、Scikit-learnから提供されている様々な評価・検定モジュールを利用することができます。
また、扱う問題に応じて、 NNmanager に加えてScikit-learnのミックスインを継承する必要があります。ミックスインには、回帰問題を扱う際に利用する RegressorMixin と、分類問題を扱う際に利用する ClassifierMixin があります。
サンプルコード
以下のコードは、手書き文字認識を行う学習器の例です。以下の説明は、このコードに即したものとなります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
from xchainer import NNmanager import numpy as np from chainer import FunctionSet, Variable, optimizers import chainer.functions as F from sklearn.base import ClassifierMixin # NNmanagerとClassifierMixinの継承 class MnistSimple(NNmanager, ClassifierMixin): def __init__(self, logging=False): # ネットワーク構造の定義 model = FunctionSet( l1=F.Linear(784, 100), l2=F.Linear(100, 100), l3=F.Linear(100, 10) ) # 最適化手法の選択 optimizer = optimizers.SGD() # 損失関数の選択 lossFunction = F.softmax_cross_entropy # パラメータの設定 params = {'epoch': 20, 'batchsize': 100, 'logging': logging} NNmanager.__init__(self, model, optimizer, lossFunction, **params) def trimOutput(self, output): y_trimed = output.data.argmax(axis=1) return np.array(y_trimed, dtype=np.int32) def forward(self, x_batch, **options): x = Variable(x_batch) h1 = F.relu(self.model.l1(x)) h2 = F.relu(self.model.l2(h1)) output = F.relu(self.model.l3(h2)) return output |
学習器のパラメータ
NNmanager はいくつかのパラメータを渡すことで、ChainerのネットワークをScikit-learnの学習器にします。このとき、ネットワークの定義に必要なパラメータは以下の通りです。
- ネットワーク構造
model - 最適化手法
optimizer - 損失関数
lossFunction
ここで、 model はchainer.FunctionSetクラスのインスタンスで、ネットワークのパラメータを全てまとめて管理する役目を持ちます。 optimizer はchainer.optimizersで提供される最適化関数、 lossFunction はchainer.functionsで提供される損失関数です。
詳しくはchainerのリファレンスマニュアルをご参照ください。
これらに加えて、オプションとしてparamsを渡すことができます。 params はdict型です。設定できる項目は、エポック数 epoch 、バッチサイズ batchsize 、学習ログ表示フラグ logging です。
学習プロセスの定義
学習プロセスを定義する際に必要になるのは、 forward メソッドと trimOutput メソッドの定義です。 forward メソッドは名前の通り順伝播処理を定義するメソッドで、Chainerにおけるネットワーク処理の根幹です。一方、 trimOutput メソッドは、Chainerのネットワークの出力をScikit-learnが扱える形(Numpy.array)に変換するためのメソッドです。Chainerは基本的に chainer.Variable という型のデータを扱いますが、この型はChainer独自のものでScikit-learnなどでは扱うことができません。
forward
forward メソッドは、ネットワークへの入力 x_batch を受け取り、出力 output を返します。ここで、 output は chainer.Variable クラスのインスタンスです。 train はネットワークの学習フラグで、 fit の際には True 、 predict の際には False が入ります。
|
1 2 3 4 5 6 7 |
# 上略 def forward(self, x_batch, train): x = Variable(x_batch) h1 = F.relu(self.model.l1(x)) h2 = F.relu(self.model.l2(h1)) output = F.relu(self.model.l3(h2)) return output |
trimOutput
trimOutput メソッドは、 forward メソッドの結果である output を受け取り、ネットワークの出力値をラベル(被説明変数)と比較可能な形で取り出します。 trimOutput メソッドは、デフォルトで output.data を取り出して返すので、回帰問題の際にはメソッド・オーバーライドは必要ありません。今回は10クラスの分類問題であるため、10次元列ベクトルの出力値の中で最も大きな値を持つ行番号をラベル値として取得しています。
|
1 2 3 4 |
# 上略 def trimOutput(self, output): y_trimed = output.data.argmax(axis=1) return np.array(y_trimed, dtype=np.int32) |
実際に学習させる
ここまでで定義した MnistSimple に実際のデータを投入し学習させます。学習に用いるデータには、Scikit-learnが提供している手書き文字データセットを利用します。また、Scikit-learnのクロスバリデーションを利用した評価を行います。Scikit-learnがデフォルトで提供している学習器と同じようにして、評価モジュールを利用することができます。
|
1 2 3 4 5 6 7 8 9 10 |
from sklearn import cross_validation from sklearn.datasets import fetch_mldata mnist = fetch_mldata('MNIST original') x_all = mnist['data'].astype(np.float32) / 255 y_all = mnist['target'].astype(np.int32) ms = MnistSimple(logging=True) score = cross_validation.cross_val_score(ms, x_all, y_all, cv=2) print score.mean() |
logging を True に設定しているので、実行すると以下のように学習過程が表示されます。二回繰り返してエポックのループが表示されるのは、クロスバリデーションのパラメータ cv を 2 に設定しているからです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
[0 epoch] mean loss: 1.904027, mean accuracy: 0.552625 [1 epoch] mean loss: 1.112880, mean accuracy: 0.722099 [2 epoch] mean loss: 0.888869, mean accuracy: 0.741673 . . . [18 epoch] mean loss: 0.463573, mean accuracy: 0.846459 [19 epoch] mean loss: 0.455422, mean accuracy: 0.848429 [0 epoch] mean loss: 2.081117, mean accuracy: 0.396185 [1 epoch] mean loss: 1.269159, mean accuracy: 0.684208 . . . [19 epoch] mean loss: 0.615833, mean accuracy: 0.777162 0.807939806752 |
このサンプルコードは、 xchainer の examples/mnist_simple.py にあります。
つなぐ:NNpacker
「つなぐ」を実現するクラスが NNpacker です。 NNpacker は、ネットワーク構造をカプセル化することにより、ツリー状に連なるネットワークの操作を簡略化します。
サンプルコード
上述の NNmanager で用いた手書き文字認識のサンプルケースを改造し、少し変わったネットワークを作ります。ここでは、手書き文字画像の上半分と下半分を別々に学習する場合を考えます。この場合、ネットワークは、上半分と下半分を受け取るネットワークが一つずつと、それらの結果を集約するネットワークが一つの合計三つのセグメントからなります。このネットワークは、一つの親ノードと二つの子ノードという形で表現することができます。 NNpacker は、ネットワーク構造をノード一つ一つに凝縮し、つなぎ合わせることができるようにします。
以下の説明は、このコードに即したものとなります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
from module.packer import NNpacker import chainer.functions as F class Upper(NNpacker): def __init__(self): layers = { 'upper_l1': F.Linear(392, 100), 'upper_l2': F.Linear(100, 100), 'upper_l3': F.Linear(100, 50) } NNpacker.__init__(self, layers, entryPoints=['upper']) def network(self, entry, __nochild__, train): data = entry['upper'] h1 = F.relu(self.layers['upper_l1'](data)) h2 = F.relu(self.layers['upper_l2'](h1)) output = F.relu(self.layers['upper_l3'](h2)) return output class Lower(NNpacker): def __init__(self): layers = { 'lower_l1': F.Linear(392, 100), 'lower_l2': F.Linear(100, 100), 'lower_l3': F.Linear(100, 50) } NNpacker.__init__(self, layers, entryPoints=['lower']) def network(self, entry, __nochild__, train): data = entry['lower'] h1 = F.relu(self.layers['lower_l1'](data)) h2 = F.relu(self.layers['lower_l2'](h1)) output = F.relu(self.layers['lower_l3'](h2)) return output class Union(NNpacker): def __init__(self): layers = { 'union_l1': F.Linear(100, 50), 'union_l2': F.Linear(50, 50), 'union_l3': F.Linear(50, 10) } children={'upper': Upper(), 'lower': Lower()} NNpacker.__init__(self, layers, children=children) def network(self, __noentry__, childrenOutput, train): upper = childrenOutput['upper'] lower = childrenOutput['lower'] data = F.concat((upper, lower)) h1 = F.relu(self.layers['union_l1'](data)) h2 = F.relu(self.layers['union_l2'](h1)) output = F.relu(self.layers['union_l3'](h2)) return output |
親子ネットワークのノードを作る
各ノードは、 NNpacker を継承する具体クラスとして定義します。ここで、親ノードのクラスを Union 、子ノードのクラスを Upper と Lower とします。 Upper と Lower は、それぞれ一つのエントリーポイントでデータ入力(画像の上半分と下半分のそれぞれ)を受け付けるネットワークで、最下層のネットワークにあたります。一方、 Union は二つの子 Upper と Lower を持つネットワークで、最上位のネットワークにあたります。 Union はエントリーポイントを持たず、子である Upper と Lower の出力のみを扱います。
このネットワークを図示すると下図のようになります。

各ノードを具体的に定義する
ノードを具体化する際にまず必要になるのは、ネットワークの層(レイヤー)です。 NNpacker ではネットワーク構造の各層に名前をつけて、辞書オブジェクト layers で管理します。たとえば、 Union ノードのネットワーク構造の各層は以下のように表すことができます。
|
1 2 3 4 5 |
layers = { 'union_l1': F.Linear(100, 50), 'union_l2': F.Linear(50, 50), 'union_l3': F.Linear(50, 10) } |
エントリーポイント entryPoints と親子関係 children は、 __init__ メソッド内で定義し、 NNpacker のコンストラクタにパラメータとして渡します。 entryPoints は、エントリーポイントの名前のリストです。 Upper と Lower はそれぞれ画像の上半分と下半分を受け取るエントリーポイントを1つ持つので、以下のように書きます。
|
1 |
entryPoints = ['upper'] |
|
1 |
entryPoints = ['lower'] |
children は、子ノードの辞書オブジェクトで、子ノードの名前をキーにして該当する NNpacker オブジェクトを割り当てます。 Union は Upper と Lower のインスタンスをそれぞれ子ノードとして持つので、以下のように children を書きます。
|
1 |
children = {'upper': Upper(), 'lower': Lower()} |
ここで登録されたエントリーポイント宛のデータと子ノードの処理結果とが、 network メソッドに渡ってきます。
network
network メソッドは、文字通り各ノードのネットワーク処理について定義するメソッドです。 layers で管理されているネットワークの各層にどのようにデータを流すかを記述します。このメソッドで書かれる内容は、 NNmanager では順伝播処理 forward で実行される内容です。
network メソッドには、エントリーポイントへのデータと、子ノードの処理結果が入力として渡ってきます。 train はネットワークの学習フラグで、 NNmanager の forward で登場したものと同じです。 network メソッドの出力 output は、 NNmanager の forward の時と同じく chainer.Variable クラスのオブジェクトです。ただし、ここでの目的はあくまで学習ではなくネットワーク構造の定義なので注意してください。
エントリーポイントと子ノードの処理結果という二つの入力について、実際の例を見てみます。 Lower と Upper は子ノードを持たず、エントリーポイントでデータの入力を受け付けます。
|
1 2 3 4 5 6 7 |
#上略 def network(self, entry, __nochild__, train): data = entry['upper'] h1 = F.relu(self.layers['upper_l1'](data)) h2 = F.relu(self.layers['upper_l2'](h1)) output = F.relu(self.layers['upper_l3'](h2)) return output |
|
1 2 3 4 5 6 7 |
#上略 def network(self, entry, __nochild__, train): data = entry['lower'] h1 = F.relu(self.layers['lower_l1'](data)) h2 = F.relu(self.layers['lower_l2'](h1)) output = F.relu(self.layers['lower_l3'](h2)) return output |
ここで、 entry には、 entryPoints で設定したエントリーポイントの名前をキーとして、対応するデータが辞書オブジェクトで渡ってきます。 Upper には entry['upper'] に画像の上半分のデータが、 Lower には entry['lower'] に画像の下半分のデータが渡ってきます。
一方、 Union は、エントリーポイントを持たず、子ノードの処理結果のみを扱います。
|
1 2 3 4 5 6 7 8 9 |
#上略 def network(self, __noentry__, childrenOutput, train): upper = childrenOutput['upper'] lower = childrenOutput['lower'] data = F.concat((upper, lower)) h1 = F.relu(self.layers['union_l1'](data)) h2 = F.relu(self.layers['union_l2'](h1)) output = F.relu(self.layers['union_l3'](h2)) return output |
ここで、 childrenOutput には、 children で設定した lower と upper という二つの子ノードの処理結果が辞書オブジェクトで渡ってきます。これらの値は chainer.Variable クラスのオブジェクトです。
ネットワークにデータを流し込む
ここまでで、 Union 、 Upper 、 Lower からなるツリー状の複雑なネットワーク構造の定義ができました。次は、実際にネットワークにデータを流し込む方法についてですが、これにはネットワークの最上位ノードの execute メソッドを使います。今回は、最上位のノードである Union クラスのオブジェクトから execute メソッドを呼び出します。
execute
execute メソッドは、全エントリーポイント宛のデータを、エントリーポイント名をキーに格納した辞書オブジェクト datasets を受け取ります。また、キーワード引数で学習フラグ train を受け取ることができます。今回エントリーポイントは、手書き文字データの上半分と下半分を受け取る upper と lower の二つなので、 datasets は以下のようになります。
|
1 2 3 4 5 6 7 8 9 |
mnist = fetch_mldata('MNIST original') data = mnist.data / 255 mnist_upper = data[:, 0:392] mnist_lower = data[:, 392:784] datasets = { 'upper': mnist_upper, 'lower': mnist_lower } |
各ノードの execute メソッドは、 datasets からエントリーポイントに割り当てられたデータを取り出し、子ノードからの出力と合わせてnetworkメソッドを呼び出します。
execute メソッドは、ノード間の親子関係に従い再帰的に呼び出されます。最上位ノードの execute メソッドを呼び出すと、最下層ノードまで順に execute メソッドを呼び出すことでデータを分配し、それらの返り値としてネットワークの処理結果をまとめあげます。
|
1 2 |
union = Union() union.execute(datasets) |
そのため、最上位のノードの execute メソッドを呼び出すだけで、ネットワーク全体の処理結果を得ることができます。
NNmanagerと組み合わせる
NNpacker を使って構成した複雑なネットワークは、他のChainerのネットワークと同じように NNmanager を使ってScikit-learnの学習器にすることができます。このために必要なのは、全体のネットワーク構造を FunctionSet のインスタンスにすることです。
getFunctions
getFunctions メソッドは、ネットワークの最上位ノードから呼び出すと、ネットワークを構成するすべての層を辞書オブジェクトで取得します。より具体的には、各ノードの layers を結合して一つの大きな layers を返しています。このネットワークの各層を格納した辞書オブジェクトを、キーワード引数に展開することで、全体のネットワーク構造を FunctionSet のインスタンスにすることができます。
以下のコードでは、これまでに定義した Union のインスタンス union を NNmanager と組み合わせて用いています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
from xchainer import NNmanager import numpy as np from chainer import FunctionSet, Variable, optimizers import chainer.functions as F from sklearn.base import ClassifierMixin class MnistComplex(NNmanager, ClassifierMixin): def __init__(self, nnpacker, logging=False): self.nnpacker = nnpacker # getFunctionsでネットワーク全体のlayersを取得してキーワード引数に展開 model = FunctionSet(**nnpacker.getFunctions()) optimizer = optimizers.SGD() lossFunction = F.softmax_cross_entropy params = {'epoch': 20, 'batchsize': 100, 'logging': logging} NNmanager.__init__(self, model, optimizer, lossFunction, **params) def trimOutput(self, output): y_trimed = output.data.argmax(axis=1) return np.array(y_trimed, dtype=np.int32) def forward(self, x_batch, train): x_data = {'upper': x_batch[:, 0:392], 'lower': x_batch[:, 392:784]} return self.nnpacker.execute(x_data) mc = MnistComplex(union, logging=True) score = cross_validation.cross_val_score(mc, x_all, y_all, cv=2) print score.mean() |
先ほどと同じように、Scikit-learnのクロスバリデーションを用いて評価しています。実行すると、学習過程が表示されます。
このサンプルコードは、 xchainer の examples/mnist_complex.py にあります。
まとめ
今回用いたChainer、Scikit-learnをはじめとして、オープンソースの機械学習ライブラリは非常に充実してきています。おかげで、適切なデータセットさえあれば誰でも機械学習の恩恵にあずかることができますが、一方で実データに適用する際の難しさは依然として立ちはだかります。
理論上適用可能であると言われているような対象分野であっても、データサイズの問題、特徴選択の問題などもあり、システムの導入・運用コストに見合うような成果を上手くあげられるケースばかりではないでしょう。最初から分析をすることを目的に収集されたわけではないデータの方が明らかに多い中で、機械学習の実用可能性はお世辞にも高いとは言えません。2
微力ながら、今回作ったものが、機械学習という技術の門戸を少しでも広げて、どこかで何かの役に立てばいいと思っています。