目次
こんにちは。スタディサプリ ENGLISH SREグループの木村です。
はじめに
障害調査などでALBのアクセスログを解析したいというときが皆あると思います。
私はあります。
今回はAthenaを使ってALBのログを解析する方法と新機能で発表されたPartition Projectionを利用するとどのようなメリットがあるのか説明したいと思います。
ALBのアクセスログ
ALBには標準でアクセスログを出力する機能があり、有効化することで自動でS3にアクセスログを保存することができます。
しかし、標準でアクセスログはgz形式で出力されており、通常解析するにはS3からダウンロードをしてきて、その後にgzを解凍してから、別途ツールを使って分析するなどの面倒な作業が発生してしまいます。
また、アクセスログはデータが大量になることも多く、DLして利用する場合でも一度に多くの範囲を分析するのは困難です。
Amazon Athena
Amazon AthenaはS3をデータレイクとして利用し、S3に対するデータに対してSQLでデータの集計をすることが出来るサービスです。Athenaを使うことでS3に出力されたアクセスログをそのままSQLで集計することができます。
※ 今回はAthenaを最初に始める設定に関しては省略しています。databaseの作成などはQuickStartなどを参考して構築してください。1)Athene Getting Started
Tableの作成
Athenaで解析出来るようにするためには既存のS3に対して、Athenaのtableのマッピングを行う必要があります。
公式docにクエリがあるので、こちらを利用して実行していきます。ALBのログの各項目に関してはdocを参照ください2)Access logs for your Application Load Balancer
※ SQLに関しては環境固有の値に関しては自分の環境に読み替えて実行してください。
CREATE EXTERNAL TABLE IF NOT EXISTS alb_logs (
type string,
time string,
elb string,
client_ip string,
client_port int,
target_ip string,
target_port int,
request_processing_time double,
target_processing_time double,
response_processing_time double,
elb_status_code string,
target_status_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
request_url string,
request_proto string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string,
domain_name string,
chosen_cert_arn string,
matched_rule_priority string,
request_creation_time string,
actions_executed string,
redirect_url string,
lambda_error_reason string,
target_port_list string,
target_status_code_list string,
new_field string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' =
'([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) ([^ ]*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^\s]+)\" \"([^\s]+)\"(.*)')
LOCATION 's3://your-alb-logs-directory/AWSLogs/your-account-id/elasticloadbalancing/your-region/'
このSQLのLOCATIONを環境の各々環境のALBのアクセスログを出力先に変更して実行します。
今回はこのtechblog自体もAWSで運用しており、ALBを使っているので、実際にTechblogのALBを分析するのに適応します。
CREATE TABLE
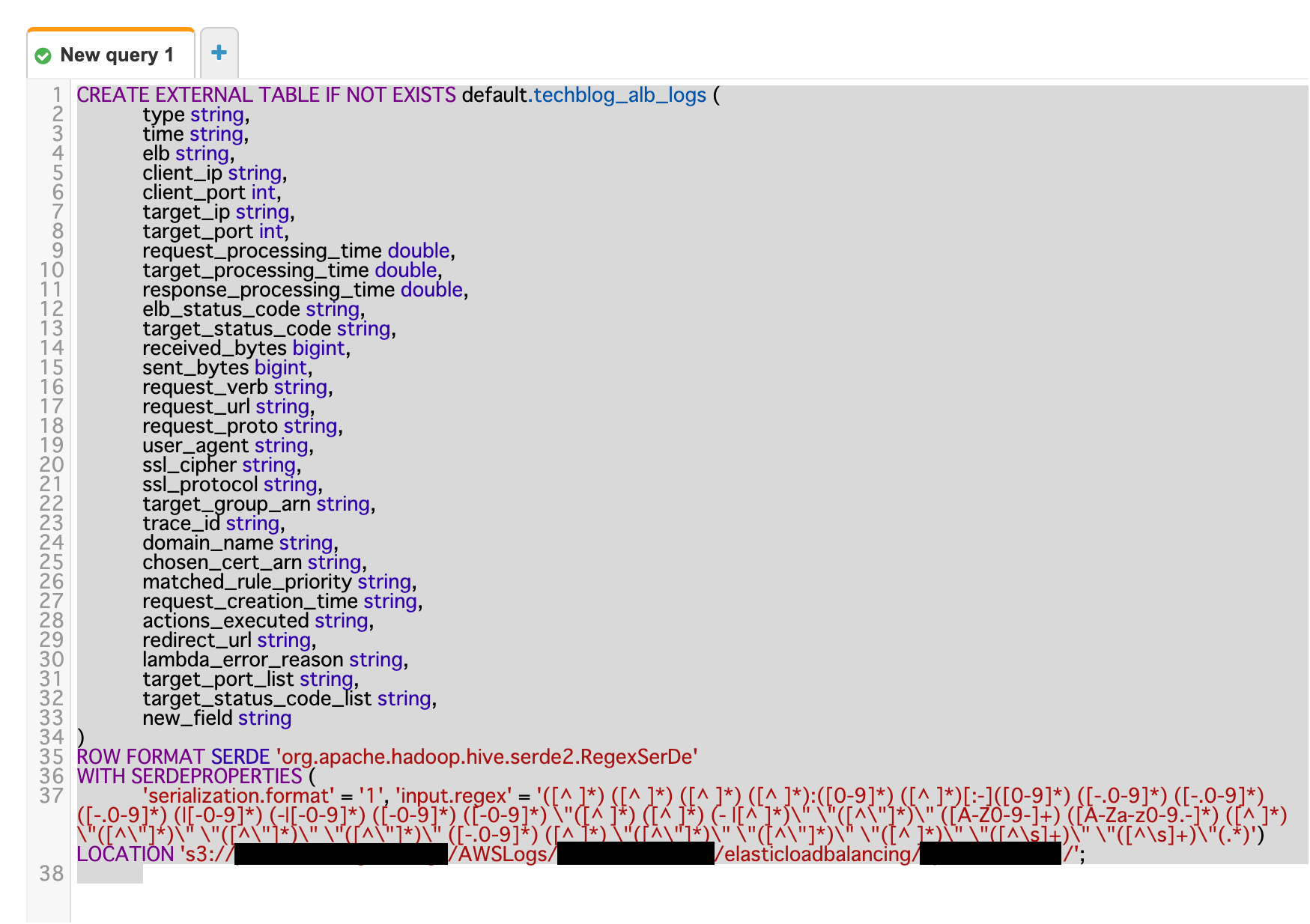
試しにSELECTを実行した結果
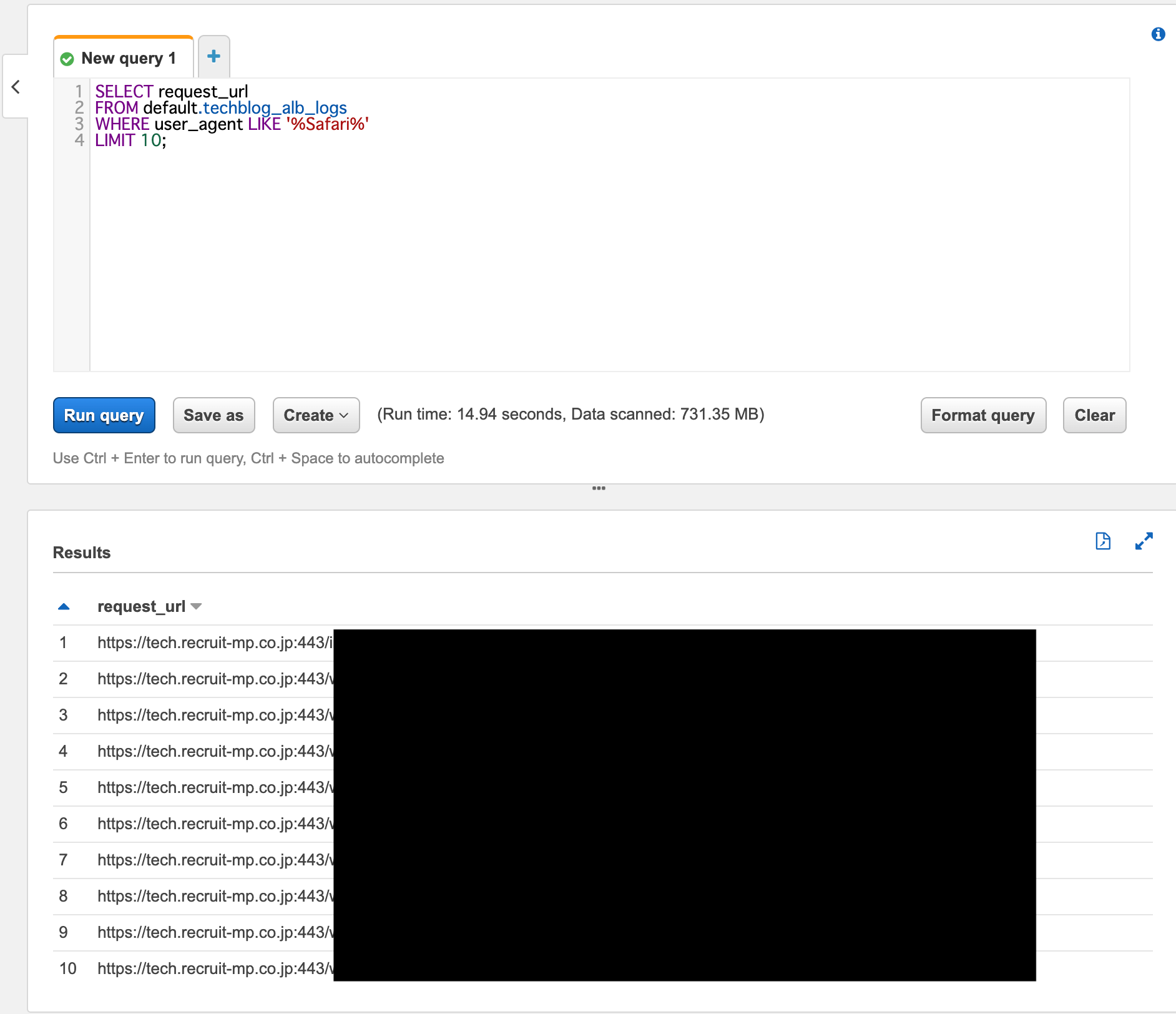
ちゃんと取得できました。
やったーこれでALBのログを気軽に分析できますね。めでたしめでたし!
といいたいところですが、このクエリでも利用出来るのですがまだ課題が残っています。
Partition分割
Athenaのクエリはスキャンされたデータに対して課金されます。データ量が増えてくると一度のクエリが大量のデータをスキャンしてしまい、料金が上がり、検索速度が下がってしまうなどの問題が発生してしまいます。
その場合はPartitionを追加して、検索するデータの範囲を限定してあげることで料金を抑えたり、検索速度を上げることができます。
既存のPartition分割の課題
今までテーブルにPartitionを追加したい場合は、定期的にALTER TABLE table_nameのSQLをPARTITIONを追加したいテーブルに対し、手動で実行したり、定期的にPartitionを追加する処理をlamdbaやGlue Clowlerを使って切ってあげる作業が必要でした。
ADD PARTITION
実際、今回Partition Projectionが入るまでは、Glue Clowlerを使って、ALBのログを解析していましたが3)albの解析に利用していたコード
athena-glue-service-logs、
Glueは気軽なのですが、料金体系が最小で10分からかかり(DPU 時間あたり 0.44USD が 1 秒単位で課金され、Apache Spark または Spark Streaming タイプの ETL ジョブごとに最小 10 分)
一時間に一回実行して、最小の1分稼働するとしても、0.44 * 10/60 * 24 * 31で、月に54.56ドルの料金がかかり、ALBごとにClowlerを作ってしまったりすると、料金の増加が気になっていく状態でした。
この手間を解消できるのが新機能のPartition Projectionです。
Partition Projection
新機能のPartition Projectionを使うと、Partitionの分析と追加を自動化して行うことが出来るようになります。
公式からの説明の抜粋4)Amazon Athena Supports Partition Projection
クエリを処理する際、Athena は、パーティションプルーニングを実行する前に、AWS Glue データカタログや Hive Metastore などのメタデータストアからメタデータ情報を取得します。テーブルに多数のパーティションがある場合、メタデータの取得に時間がかかる可能性があります。パーティションプロジェクションは、これを回避するために使用できます。パーティションプロジェクションでは、パーティションの形成に一般的に使用されるパターン (例: YYYY/MM/DD) などの設定情報を指定できます。これにより、メタデータストアからメタデータ情報を取得せずに、パーティションを構築するために必要な情報が Athena に提供されます。Athena は、AWS Glue データカタログなどのリポジトリからではなく、設定からパーティションの値と場所を読み取ります。多くの場合、インメモリ操作はリモート操作よりも高速であるため、パーティションプロジェクションは、高度にパーティション分割されたテーブルに対するクエリの実行時間を短縮します。
Partition Projectionで解析できる形式
enum、integer、date、または injected パーティション列の型の任意の組み合わせを使用できます。
- 列挙型(enum)
- 値が列挙セットのメンバーであるパーティション列には、enum 型を使用します (空港コードや AWS リージョンなど)。
- projection.columnName.valuesに
us-west-2,ap-northeast-1などのような決まった値を入れることで解析出来る。 - 整数型(integer)
- 値が列挙セットのメンバーであるパーティション列には、enum 型を使用します (空港コードや AWS リージョンなど)。
- projection.columnName.range に
0001,9999のような最小値、最大値の範囲を指定することで連続した値を解析出来る。 - 日付型(date)
- 定義された範囲内の日付 (オプションで時刻を含む) として解釈可能な値を持つパーティション列には、日付型を使用します。
- projection.columnName.rangeに日付の範囲
201701,201812,NOW-3YEARS,NOWのような日付の範囲を入れて連続した値を解析出来る。(今回はこの形式を利用するので細かくは後述)
Partition Projection追加版のSQL
CREATE EXTERNAL TABLE projection_alblog (
type string,
time string,
elb string,
client_ip string,
client_port int,
target_ip string,
target_port int,
request_processing_time double,
target_processing_time double,
response_processing_time double,
elb_status_code string,
target_status_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
request_url string,
request_proto string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string,
domain_name string,
chosen_cert_arn string,
matched_rule_priority string,
request_creation_time string,
actions_executed string,
redirect_url string,
lambda_error_reason string,
target_port_list string,
target_status_code_list string,
new_field string
)
PARTITIONED BY (
`date` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' =
'([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) ([^ ]*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^\s]+)\" \"([^\s]+)\"(.*)')
LOCATION
's3://your-alb-logs-directory/AWSLogs/your-account-id/elasticloadbalancing/your-region'
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.date.type' = 'date',
'projection.date.range' = 'NOW-5YEARS,NOW',
'projection.date.format' = 'yyyy/MM/dd',
'projection.date.interval' = '1',
'projection.date.interval.unit' = 'HOURS',
'storage.location.template' = 's3://your-alb-logs-directory/AWSLogs/your-account-id/elasticloadbalancing/your-region/${date}',
'classification'='csv',
'compressionType'='gzip',
'typeOfData'='file'
)
SQLの違い
- Partition Projectionを利用しているSQLには
PARTITION BYとTBLPROPERTIESにprojection.*の項目を追加しています。
'projection.enabled' = 'true',
'projection.date.type' = 'date',
'projection.date.range' = 'NOW-5YEARS,NOW',
'projection.date.format' = 'yyyy/MM/dd',
'projection.date.interval' = '1',
'projection.date.interval.unit' = 'DAYS',
- 各項目の説明
'projection.enabled' = 'true'- Partition Projectionを有効化するには
projection.enabled=trueを設定します。 - 今回の場合は
dateというPartitionを追加しているのでprojection.date.*にprojectionの設定を追加しています。 -
'projection.date.type' = 'date' - projection.columnName.typeはenum、integer、date,、または injectedの複数のtypeがサポートされています。今回はdate型を使って、日付の形式で保存されているパスを利用してパーティションを切っていきます。
- 他の構造については公式docを参考にしてください
'projection.date.range' = 'NOW-5YEARS,NOW'- dateの形式では遡る期間と最新の日付を指定する必要があります。今回の場合は5年前から、最新の日付までのパスを解析しています。
'projection.date.format' = 'yyyy/MM/dd'- DateTimeFormatterに基づく、日付の形式を渡します。今回はELBのS3のパス形式に合わせた
yyyy/MM/ddを指定 'projection.date.interval' = 1- 今回は1日毎にパーティションをきるので1に
'projection.date.interval.unit' = 'DAYS'- 日毎にパーティションを切りたいのでDAYSに設定
storage.location.template- 設定するS3のlocationを設定、 ${date}の部分は、
projection.dateで設定したパスが入ります。今回だとALBは日付のパスが入るyyyy/MM/ddの形式のパスごとにパーティションが作成されます。(e.g 2020/07/01)
実行結果
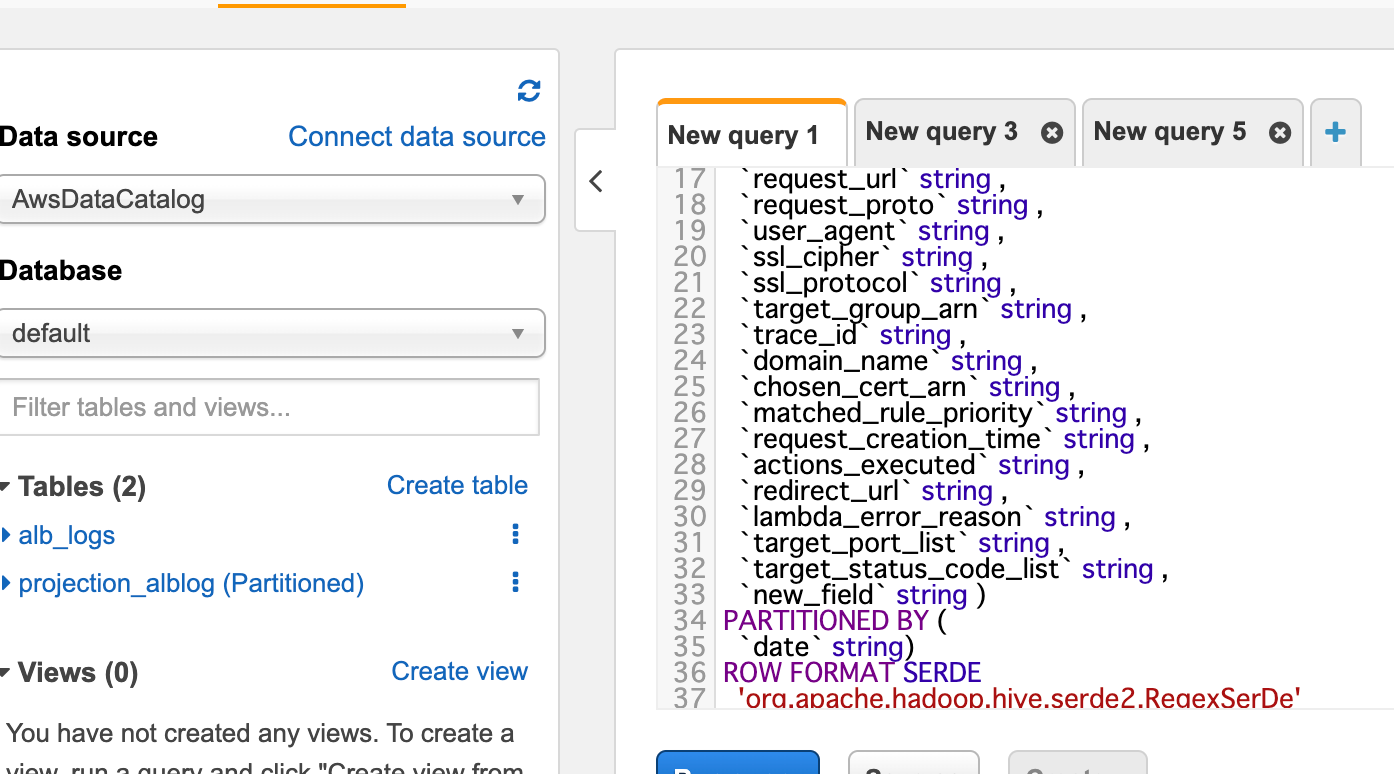
Partition Projectionの設定が追加されたtableに対して、(Partitioned)が追加されたことが確認できます。
- 設定された
dateのpartitionを使って検索をかけることが出来るようになりました。これでデータ全体に実行されるよりも安全にクエリを書くことができます。
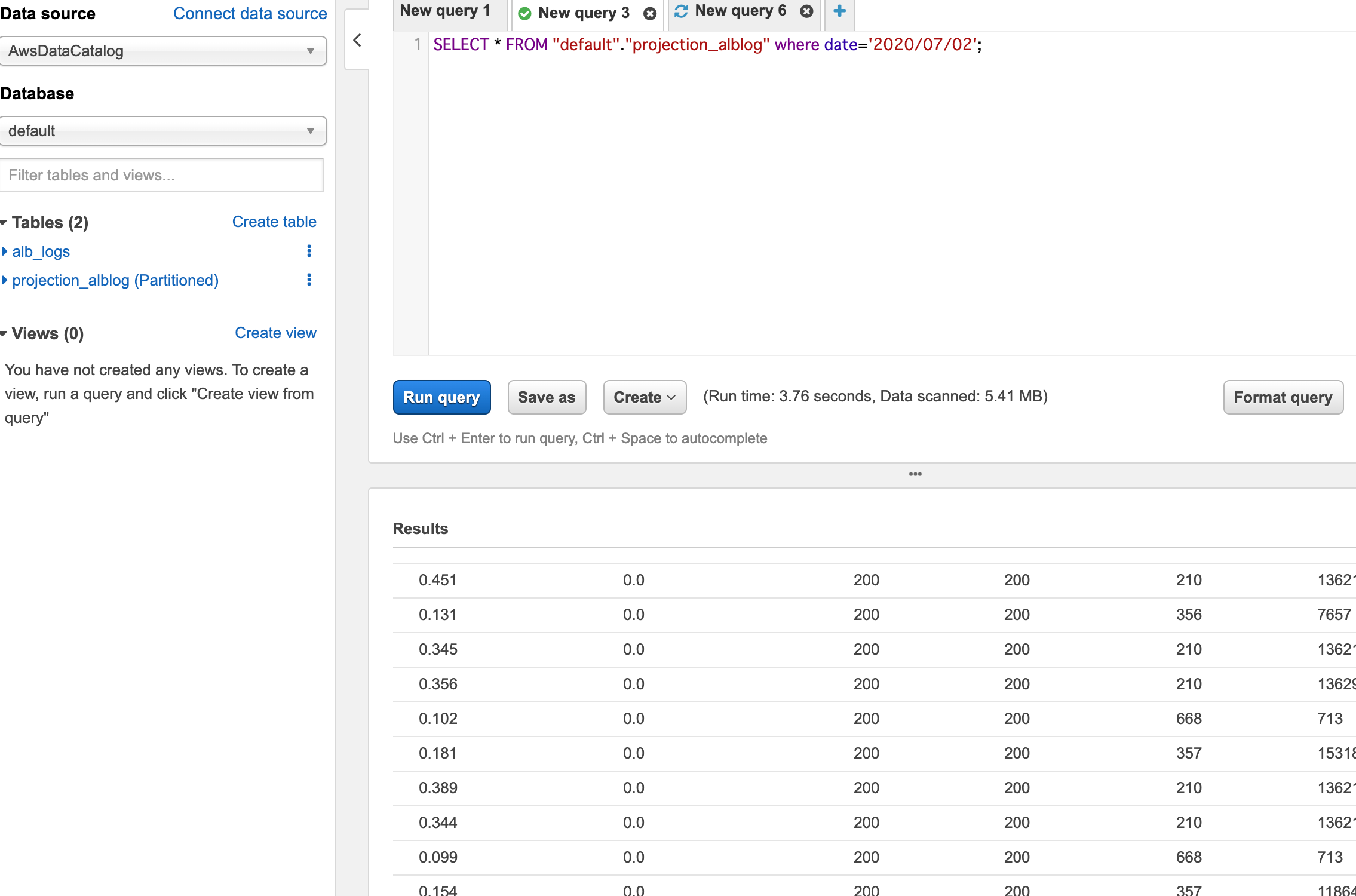
Terraformを使って構築する
今回の手順で一番面倒なのはCREATE TABLEのSQLを作る部分なのですが、実際にはTerraform化して作成しました。
Terraform resources
variable "workgroup_id" {
description = "ID of workgroup used in athena."
type = string
}
variable "database_name" {
description = "Name of database used in athena."
type = string
}
variable "table_name" {
description = "Name of table used in athena."
type = string
}
variable "bucket_location" {
description = "S3 path where alb log is output location."
type = string
}
data "aws_caller_identity" "current" {}
data "aws_region" "current" {}
resource "aws_athena_named_query" "create_table" {
name = "${var.database_name}_${var.table_name}_create_table"
workgroup = var.workgroup_id
database = var.database_name
query = templatefile("${path.module}/sql/alb_log_create_table.sql.tmpl",
{
database_name = var.database_name
table_name = var.table_name
bucket_location = "s3://${var.bucket_location}/AWSLogs/${data.aws_caller_identity.current.account_id}/elasticloadbalancing/${data.aws_region.current.name}"
})
}
解説
CREATE TABLE文をTerraformの templatefile 機能で作成し、Athenaの名前付きQueryとして保存されます。
また、ALBの出力されるパスの中の account-id と region に関しては各々 data.aws_caller_identity ,data.aws_region から取得されるようにしてユーザーは入力しなくても使えるようにしています。
このTerraformでQueryを作成し、Athena側で作成されたクエリを実行することでalbの解析用のテーブルが作成されます。
Module
今回作成したTerraformに関してはmodule化して、Githubで公開しているので使ってみてください。
Tips
LOCATIONの指定間違い
AthenaのLOCATIONを間違って指定しても、テーブルは作成されますがデータの取得には空のデータが返ってきます。
storage.location.templateの指定間違い
storage.location.templateのパスを指定間違いをしても、テーブルは作成されますが、Select Queryを実行しようとすると、
Access Denied (Service: Amazon S3; Status Code: 403; Error Code: AccessDenied; Request ID: xxxxxxxxxxxxxx; S3 Extended Request ID: xxxxxxxxxxxx) のようなErrorが返ってきます。おそらくpartitionを見ようとして、S3の存在しないpathにアクセスしようとして403が返っているようです。
Terraform String Templatesの中でTemplateで予約された文字列を使う場合
Terraform String Templatesの中で ${ や %{ のような変数の埋め込みやifやforを使うためのtemplateの文字列を使いたい場合は $${ や %%{ のように記号を二回連続を使って書いてあげることでescapeすることが出来ます。5)Terraform String Templates
今回はCREATE TABLEの中でPartition Projectionの設定の中で ${date} という文字列をそのまま使うために利用しています。 templateファイル内で $${date} が該当箇所です。
実際のtemplateファイル
CREATE EXTERNAL TABLE `${database_name}.${table_name}`(
type string,
time string,
elb string,
client_ip string,
client_port int,
target_ip string,
target_port int,
request_processing_time double,
target_processing_time double,
response_processing_time double,
elb_status_code string,
target_status_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
request_url string,
request_proto string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string,
domain_name string,
chosen_cert_arn string,
matched_rule_priority string,
request_creation_time string,
actions_executed string,
redirect_url string,
lambda_error_reason string,
target_port_list string,
target_status_code_list string,
new_field string
)
PARTITIONED BY (
`date` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' =
'([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) ([^ ]*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^\s]+)\" \"([^\s]+)\"(.*)')
LOCATION
'${bucket_location}'
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.date.type' = 'date',
'projection.date.range' = 'NOW-5YEARS,NOW',
'projection.date.format' = 'yyyy/MM/dd',
'projection.date.interval' = '1',
'projection.date.interval.unit' = 'DAYS',
'storage.location.template' = '${bucket_location}/$${date}',
'classification'='csv',
'compressionType'='gzip',
'typeOfData'='file'
)
終わりに
今までも同様の基盤を作ることは可能でしたがCREATE TABLEだけでPartitionを切ることが出来るようになり、今回のようなALBでも利用ができますし、CloudtrailやVPC flowlogsのような決まった形式へのパスへの解析も同様に出来、自分たちで作ってS3に保存しているデータなどの解析もなども可能で、さらにQuickSightとの連携で可視化をするようにすることでログの分析基盤をより気軽に作れるようになるなど、S3単体で分析基盤を構築するのに非常に有用な新機能だと感じたので、是非活用してみてください!
参考資料
- Access logs for your Application Load Balancer
- Querying Application Load Balancer Logs
- Partition Projection with Amazon Athena