目次
はじめに
こんにちは!2025 年度新卒データスペシャリストの宇川・酒井・武井です。 新人研修の様子を紹介するブログシリーズ、今回は「前処理研修」についてお伝えします。
リクルートの新卒データスペシャリストは、入社後すぐに約 2 ヶ月間の新人研修に参加します。 その中でも前処理研修は、本格的な技術的内容に初めて触れる研修となっています。 この記事では、研修の様子や学んだことを紹介していきます。
研修の概要
前処理とは
研修ではデータ分析を大まかに以下のステップに分けて説明されました。
- データ収集
- 前処理
- 分析やモデリング
前処理は、収集されたデータを加工し、分析のための準備を行う工程です。 データの抽出、結合、集約、変換などを通じて、後続の分析や機械学習のモデリングで扱える形にデータを整えます。
研修の内容
今回の研修では、高度な特徴量エンジニアリングや非構造化データ(画像・自然言語など)の前処理には触れず、以下の 2 点に重点を置きました。
- テーブルデータを対象とした基礎的な前処理の理解
- Pandas/Polars での基礎的な前処理操作の習得
研修の進め方
前提条件は Python が軽く書ける程度で十分で、丁寧な講義・演習形式で進むため、あまり馴染みがない方でも無理なくついていける内容でした。

1 日目は導入の講義から始まりました。 講義では、前処理やデータ分析の基礎的な概念について解説していただきました。 DWH や RDB、行指向・列指向、MapReduce など、中には初めて知ることも多く勉強になりました。
1 日目後半から 2 日目までは、テーブルデータの処理について各トピックごとに講義 → 演習の形で進めていきました。
使用したツールとライブラリ
研修では、環境構築からデータ処理まで複数のツールとライブラリを使用しました。主なものを紹介します。
環境構築
環境構築では、 uv というツールを使いました。uv は高速な Rust で実装されており、余分なコピーを減らしたりキャッシュを最適化するなどの工夫によって動作が非常に速いという特徴があります。
研修では以下のコマンドで環境構築を行いました。
$ uv venv # 仮想環境の作成
$ uv sync # 研修で用意されたpyproject.tomlに基づきパッケージをインストール
$ source ./.venv/bin/activate # 仮想環境のアクティベート
体感として、 Poetry より高速な印象がありました。また、プロジェクトごとにサクッと環境を作れるのは便利だなと感じました。
データ処理
今回の研修では、Pandas と Polars というライブラリを使用しました。
Pandas
Pandas は 2009 年に公開されたデータ解析ライブラリです。ライブラリとしての歴史が長く、広く一般的に使用されています。今回の研修でも Pandas を使ったことがある人は多かったです。 一方で、大量のデータを扱う際に処理速度が落ちることがあり、実装に工夫が必要な場面がある点も学びました。
Polars
Polars は 2020 年に登場した比較的新しいライブラリで、Rust で実装されており高速なことで注目されています。 研修では初めて Polars に触れる人が多く、使い方だけでなく、設計思想や高速化の仕組みについても詳しく解説していただきました。
高速化を実現する様々な工夫の中でも特に印象的だったのは遅延評価です。 一つ一つのデータ操作をその場では実行せず、必要になった時にまとめて最適化してから処理することで、無駄な処理を避けることができます。
一方で、Pandas の Index のような機能がないなど、設計思想が大きく異なる部分もあり移行には少し慣れが必要だと感じました。
演習
演習は、講義で扱った内容を実際に手を動かして実装するものでした。題材には研修用に用意されたホテルの予約データを使い、データの抽出や集約、結合といった処理を実装しました。Pandas と Polars の両方で同じ課題を解くことで、それぞれのライブラリの書き方や処理の違いを学べる形になっていました。
演習の進め方
演習は基本的に個人ワークで進められました。具体的には各自に課題が与えられ、制限時間内に解いていきました。 課題は Pandas や Polars を用いて実装をし、解き終わった人は Slack 上でスタンプを押して完了報告をするという形でした。

他の新人研修と同様に前処理研修専用の Slack チャンネルが作られ、質問や雑談が自由に飛び交っていました。演習についての感想や Tips などが共有されており、楽しみながらも非常に学びの多い場でした。


この Slack チャンネルはかなり盛り上がっており、やりとりが活発に行われていました。制限時間内に解かなければいけない緊張感がありながらも、和気あいあいとした雰囲気があったのが印象的でした。
演習で扱った内容
演習では、様々な処理を実際に手を動かして実装しました。問題は段階的に難易度が上がるように設計されており、後半になるにつれて頭を使う場面が多くなっていきました。
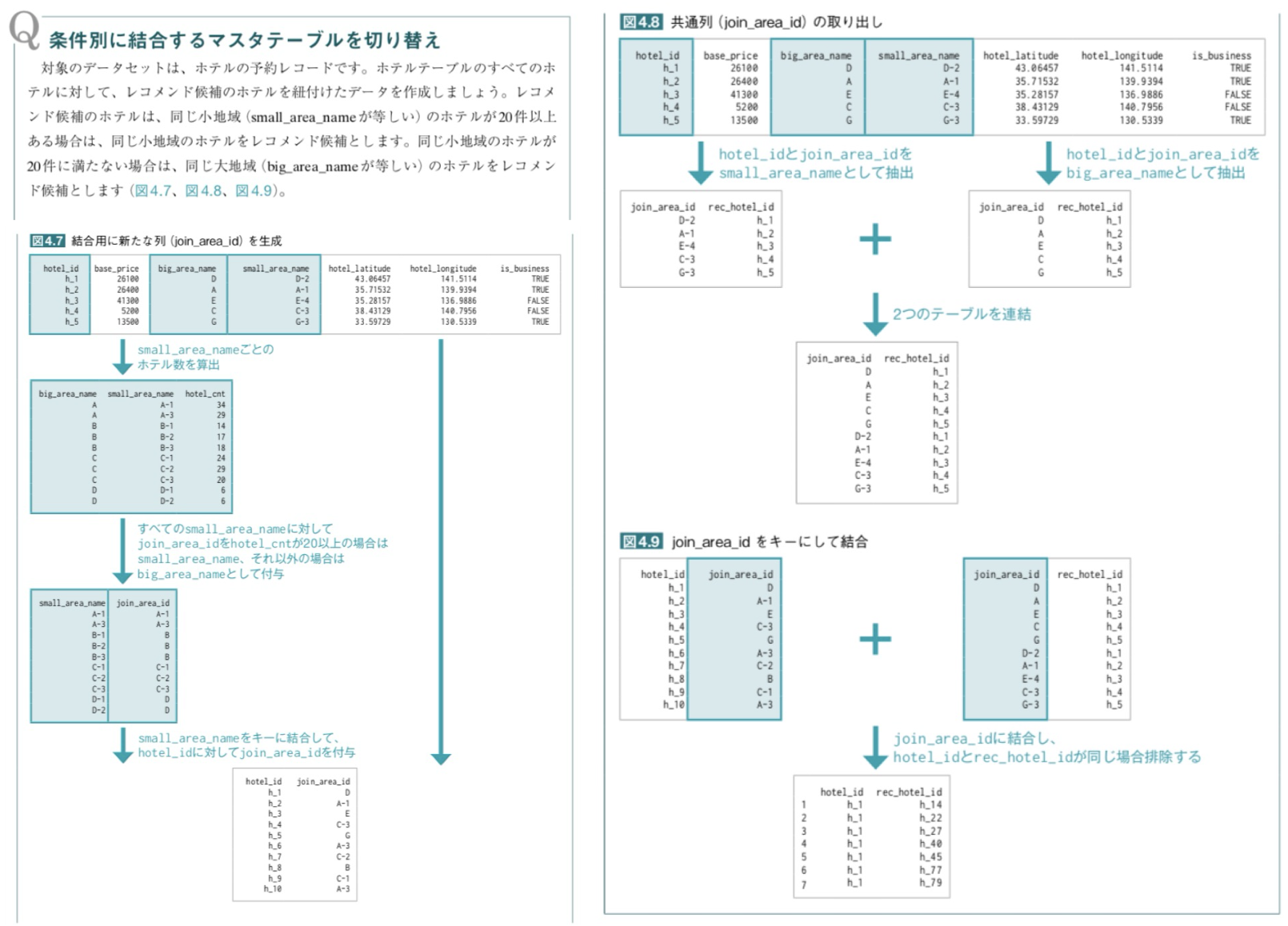
例えば、最初は CSV ファイルを読み込んで特定の列を削除するというものでしたが、後半では近隣ホテルの情報からそのホテルを予約した人におすすめのホテルをレコメンドするなど、条件が複雑な課題もありました。Pandas についてはほとんどの人が解けていましたが、慣れない Polars には苦戦している人が多かったです。単にライブラリの文法を知っているだけでなく、データの流れや処理手順を論理的に考える必要があり、実務でのデータ処理を体感できました。
書影は技術評論社 前処理大全 より引用いたしました。
Pandas と Polars の比較
予約データを使って、Pandas と Polars の書き方と処理速度を比較してみます。各カスタマーについて 2 回前までの支払い総額を求める問題を考えます。
実際に実装してみました。Pandas では処理をいくつか分割して書きましたが、Polars では複数の処理をまとめて記述でき、シンプルに実装することができました。加えて、Polars では遅延評価を表す .lazy() を用いることで高速化を狙いました。
# Pandas による実装例
result_df = reserve_df.sort_values(
by=["customer_id", "reserve_datetime"],
axis=0,
).set_index("customer_id")
result_df["prev_total_price"] = pd.Series(
result_df["total_price"].groupby("customer_id").shift(periods=2)
)
result_df = result_df.reset_index(drop=True)
# Polars による実装例
q_plan = reserve_df.lazy().with_columns(
pl.col("total_price")
.sort_by("reserve_datetime")
.shift(2)
.over("customer_id")
.name.prefix("prev_"),
)
result_df = q_plan.collect()
それぞれの処理速度は以下にまとめました。データ数は 4,000 行 × 9 列程度です。
| 手法 | 10 回平均の実行時間(ミリ秒) |
|---|---|
| Pandas | 2.97 |
| Polars(遅延評価なし) | 1.21 |
| Polars(遅延評価あり) | 1.18 |
Pandas よりも Polars の方が高速であることがわかります。また遅延評価については、今回の処理数は少ないのでそこまで大きな差にはなりませんでしたが、処理が重くなるにつれてさらに差は開くと思います。Pandas と Polars の処理速度の差については、Polars 公式が 比較している ので参考にしてみてください。
まとめ
以上、前処理研修の内容について紹介してきました。 今回の研修では実際に手を動かす演習を通じて、Pandas や Polars を使いながら前処理の基礎を学びました。 Pandas/Polars での操作一つ一つをとっても、その裏にある設計思想が垣間見えたり、今まで知らなかった便利な機能を知ることができたりし、データ処理の奥深さを実感しました。
本研修で扱ったのはデータ処理の一部であり、この分野は日々進化し続けています。 この研修で得た知識をベースとして、実務での経験を通じてスキルを磨いていきたいと思います。
感想
宇川
Polars、uv ともに使ったことがありませんでした。使ってみる中で、これらの性能の高さに驚きました。知らないところで世の中の技術は常に発展し続けており、安住の地だと思い込んでいる場所に留まっていると、すぐ置いて行かれてしまうのだと早くも気づけたことが今回の大きな学びです。日頃から「モダン」を目指して勉強を続けていきたいです。
今回の研修は、データ処理の基礎を固める貴重な機会となったのはもちろん、同期との絆を深める体験にもなりました。お互いの学びを共有する中で、共に成長していける関係性を育めたことを嬉しく思います。
酒井
Pandas と Polars は学生時代から使用していましたが、本研修を通じて十分に使いこなせていなかったことに気づかされました。 ライブラリの使い方だけでなく、その背景にある思想や関連するデータ処理の概念についても学ぶことができました。 特に Polars の遅延評価など、これまで活用できていなかった機能については、今後も理解を深めながら使いこなしていきたいです。
また、Slack でのやり取りが非常に活発で、協力し合いながら学べる環境だった点が良かったです。 詰まった箇所を助け合ったり、同じ講義でも人によって注目する点が異なり、それを共有することで新しい気づきが得られました。
武井
普段から Pandas と Polars は使っていましたが、これまで自己流で書いていた部分が多かったため、研修を通じて基本的な操作や各ライブラリの設計思想を改めて整理でき、良い学びの場になりました。
演習には時間制限があり緊張感もありましたが、同期と協力しながら楽しく取り組むことができました。研修を通じて仲を深められたため、とても良い機会だったと思っています。