目次
こんにちは、開発支援Gでインフラ運用をしている大島です。
VPC環境でIPが足りなくなってきた
弊社の英語学習サービスであるスタディサプリENGLISHでは、マイクロサービス化を進めていることと、おかげさまでユーザーも順調に増え規模も大きくなってきました。それに伴い、開発環境のインスタンスも増えたことで、VPCのIPアドレスが枯渇してきてしまいました。
当初、設定したVPCは開発環境ということもあり、CIDRは/24。IPアドレスでいうと254個使える状態です。その時は「まぁそれぐらいあれば大丈夫だろう」という気もしていたんですが、意外とこれが少ないんです。
こちらの図は一般的なAWSのネットワーク構成です。4つのsubnetに分かれています。64個というのは各subnetのIPアドレスの数です。実際はネットワークアドレス、ブロードキャスト用のアドレスやAWSのDNS用のアドレスなどに使われるので、もっと少ないです。
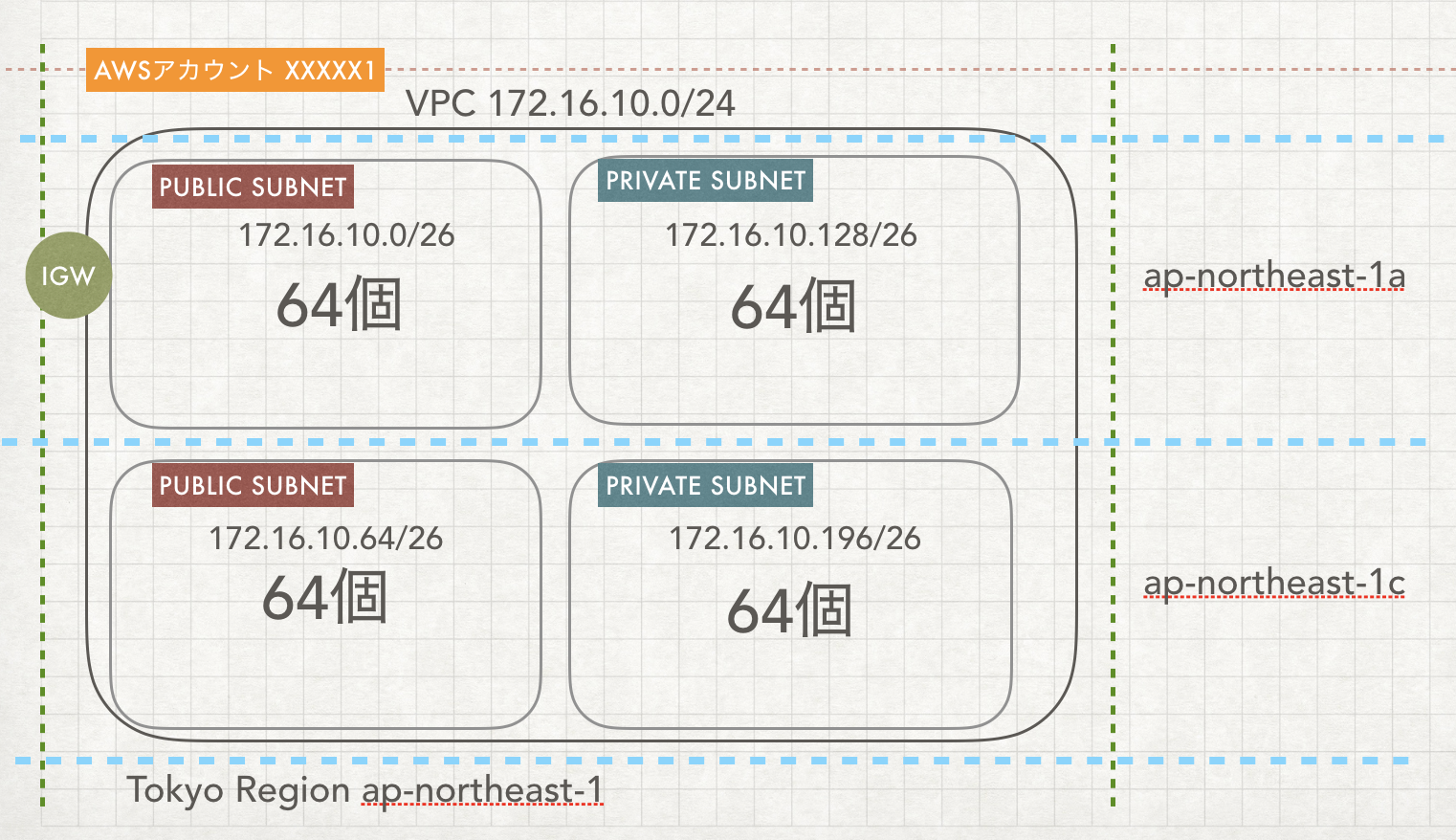
このようにセキュリティ面を考えて外部と直接繋がるpublic subnetとそうでないprivate subnetに分けることになり、さらにavailavility-zone(az)というTokyoの中でも複数のデータセンターで冗長化するために分割することになります。
誤解のないようにいうと、AWSが不便という意味ではなく、VPCのCIDR拡張や別VPCをたててpeeringするなどの方法で増やせるようになってます。今回はあくまでもCIDRを変更せずにIPを節約するときの話です。
Private Subnetだけが足りなくなるというジレンマ
public subnetに配置するのは基本的に外と通信するためのロードバランサー(ALB)ぐらいで、大抵のEC2インスタンスやDB(RDS)などはもちろんprivate subnetに置きたいわけです。そうすると、インスタンスはもう118個しか置けないことになります。さらにRDSやElasticache(Redis)など冗長化のためにazごとに1つずつ使ったりするわけです。そうなるともっと少なくなりますね。
さらにさらに、マイクロサービス化を進めると内部通信だけをする際のロードバランシングはわざわざpublic subnetにLBを置かずにprivate subnetにおいて隠蔽したくなります。
ELBはRDSと同様にazで冗長化するのでIPが2倍必要なのと、仕様としてsubnet内に最低限空きIPアドレスが8個ある状態でないと立ち上がってくれません。
IPアドレスはprivate subnet1つで59個使えますが、ELBの仕様で最低限8個ぐらいは余らせておかないといけないということと、RDSやElasticacheがあって、さらにELBが20個ぐらいあるとするともう、インスタンスは30個ぐらいしか立ち上げられないということになります。そしてサービスを分割すればするほど、ELBをたてなくてはならずこりゃやばいとなるわけです。
「じゃあpublic subnetの割り当てを減らせば?」というのも考えられますが、azごとに冗長化するとなると64 × 4が最大になる組み合わせというジレンマがあります。
対応策1: 強いインスタンスでクラスターのマシンリソースを増やす
ECSはコンテナをEC2インスタンス内で立ち上げる訳ですが、立ち上げられるコンテナの量には制限があります。その制限はEC2インスタンスのスペックによって制限されているので安いインスタンスを大量に立ち上げてもIPアドレスは増えるばかりで、動かせるコンテナはそれほど増えません。
例えば1vCPU、2GBのメモリを使いたいコンテナがあるとした場合は、m4.largeの場合は2個しか立ち上げられませんが、m4.xlargeなら4個立ち上げることができます。
| インスタンス | vCPU | メモリ | 立ち上げられるタスクの数 |
|---|---|---|---|
| m4.large | 2 | 8GB | 2vCPU ÷ 1vCPU = 2個 |
| m4.xlarge | 4 | 16GB | 4vCPU ÷ 1vCPU = 4個 |
そこで、開発環境やステージング環境は可用性を妥協できるのでSpot Fleetで安いお値段で強いインスタンスをたてるという方針にして、これでインスタンスの個数を大分減らすことができました。
対応策2: ALBのルールベースの振り分けを使う
ECSのサービスは基本的にロードバランサーがないと使えない仕組みになってます。『基本的』と言ったのは、なくても動くっちゃ動くという意味です。ただし、動的ポートマッピングされたコンテナのヘルスチェックやサービスディスカバリなど、現状ロードバランサーがやってくれることを自分でこなす必要があります。
ECSで運用する場合、通常httpやhttpsで通信するサービスはL7のロードバランサーであるALBを使うわけですが、今まではALB : ECS service = 1 : 1の関係で作っていました。しかしこれでは、apiやadminみたいなサービスが増えるたびにALBが必要になりどんどんIPアドレスが減っていきます。
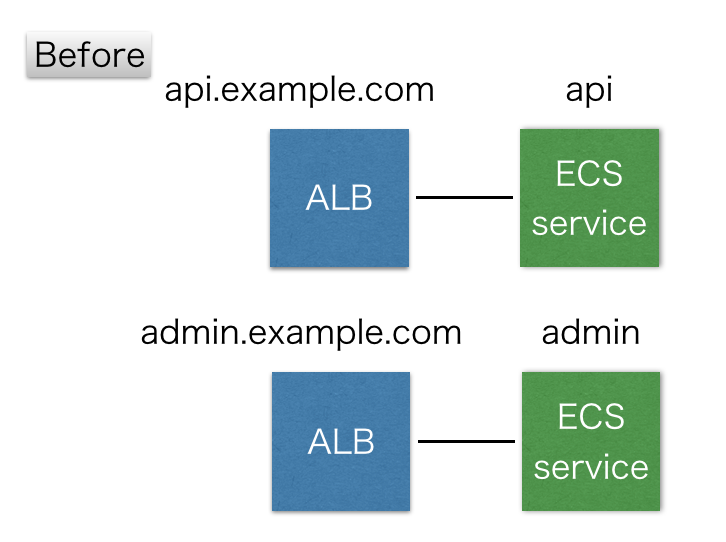
そこでサービスを増やすたびにALBを立てなくでも済むように『リスナールール』という仕組みで振り分けることにしました。あえて例えるなら、nginxとかapacheのvirtual hostみたいなものです。
リスナールールはホスト名かパスの値によってルーティングを書くことができます。図でいうとこのようになります。
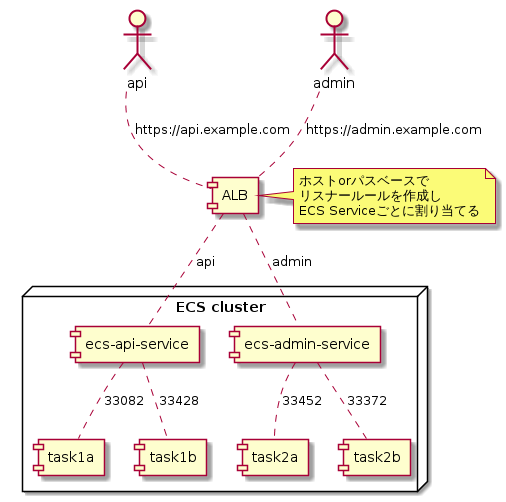
これでサービスがいくら増えようがALBは増えないため、IPアドレスも増えることはありません。料金も安くなります。BeforeからAfterに変わってもクライアント側がアクセスするURLは変わってないのでクライアントに変更は不要です。
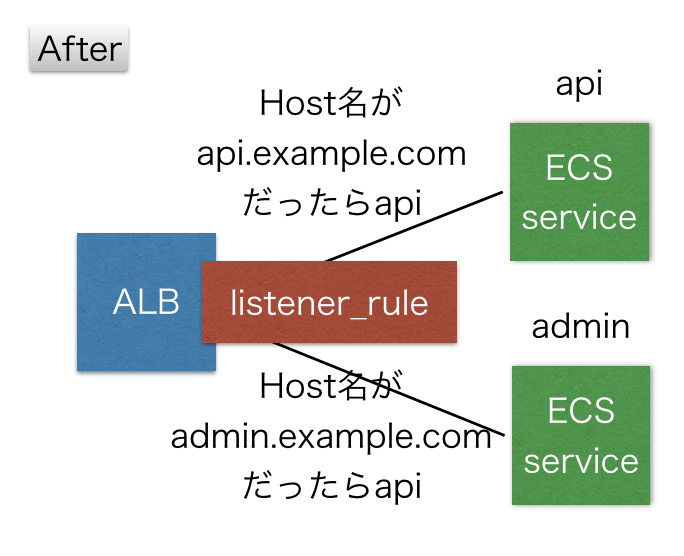
これを実現するためにterraformのmoduleも作ってあるので、サービスを増やす時は簡単に増やせるようになってます。これで気兼ねなくサービスをどんどん増やせるようになりました。
module "api_service" {
source = "../../module/ecs_service_with_alb_router"
name = "api"
env = "${var.env}"
cluster_id = "${module.english_cluster.cluster_id}"
ecs_service_iam_role = "${var.ecs_service_role}"
deployment_maximum_percent = 100
deployment_minimum_healthy_percent = 0
container_port = 80
network_mode = "bridge"
vpc_id = "${var.vpc_id}"
alb_health_check_path = "/healthz"
log_groups = ["${var.env}/api"]
use_host_header_rule = true
router_alb_listener_arn = "${module.alb_router.https_listener_arn}"
router_alb_dns_name = "${module.alb_router.alb_dns_name}"
router_alb_zone_id = "${module.alb_router.alb_zone_id}"
route53_zone_id = "${var.dns_zone}"
route53_record_name = "${var.env}-api"
}
対応策3: NLBでリスナーごとに振り分けを使う(しかしうまくいかなかった)
AWSのロードバランサーはいろいろと名前の変遷があったこともあり、大昔はELBというタイプのものが一つだけでした。その後、L7に対応したApplication Load Balancer(ALB)、L4に対応したNetwork Load Balancer(NLB)が出てきたことで、当初あったELBというのはClassic Load Balancer(CLB)と呼ばれるようになり、これらロードバランサー群の総称としてElastic Load Balancing(ELB)という名称になりました。
スタディサプリENGLISHは内部通信にgRPCを使ってるので、HTTP2でお話ができないといけません。ALBはHTTP2に対応はしていますが、SSL終端をしてサーバーとはHTTP1.1で通信するようになってます。なので今までは、L4の分散ができるが動的ポートマッピングができないCLBを使うしかありませんでした。
そこにECSで動的ポートマッピングができるというNLBの登場でついにCLBから卒業できるということに!! NLBにたくさんListenerを生やしてportを変えることでECSのserviceを割り当てればできるはずでした。
しかし、実際にやってみるとつながらない・・なぜ・・ 😨
生まれて初めてtcpdumpをしたり、いろいろと調べたり聞いたりして、ようやく原因が分かりました。
残念! awsvpcモードでないと同一インスタンス宛のリクエストは破棄される
NLBは高速化のために、今までのALBやCLBと違い通信経路が異なります。いつもお世話になっているDevelopers.IOさんの記事を読んで理解が進みました。ありがとうございます。
要はNLBはIPの変換処理を行わないことでLBの処理を減らしている訳です。
一方で上記のNLBの仕様により、下の図のように、同一インスタンス内にあるタスク同士がNLBを経由してECSのtask間通信をする場合につながらないという状況になってしまいました。
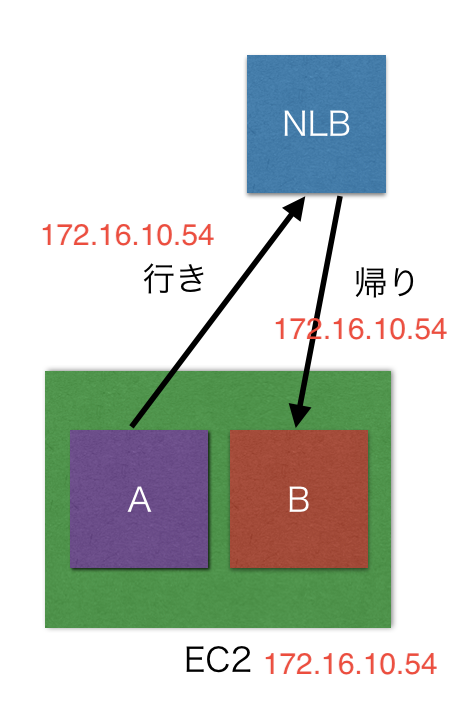
ざっくり言うと、NLBでIPが変換されないので行きも帰りも自分のマシンのIPアドレスがターゲットという謎のパケットになってしまうため、通信できないということでした。
特定のインスタンスに入ってるタスク同士で通信したいなんてことはレアケースでもなんでもなく普通にありえるので、これは採用できないということになり、あきらめて今まで通りCLBで立ち上げるしかありませんでした。
もちろん、awsvpcモードにすれば各TaskごとにIPアドレスがふられるのでこういった問題は起きませんが、IPアドレスを消費したくないという謎の縛りプレイの最中だとあまり意味がありません。なので、gRPCサービスだけは増えるたびにCLBが増えるという構造になってしまっています。
まとめ
CIDRが広い場合でも、本記事ではロードバランサーの節約やインスタンスの節約をしたいなど使える部分はあると思います。
最後に、リクルートマーケティングパートナーズでは冒頭でも紹介したスタディサプリENGLISHなどの複数のプロダクトを運営しています。まだまだ改善の余地がたくさんあるおもしろいフェーズで、今回のような工夫を楽しんでやっていってくれるインフラメンバーも絶賛募集中です。
興味を持った方がいましたらご連絡お待ちしております。