目次
2017年度新卒エンジニアの三上(@mikaji_jp)です。現在はWebアプリケーションエンジニアとしてRailsアプリケーションの開発を行っています。9月18日~20日の期間、広島にて開催された RubyKaigi 2017 に参加してきました。

今回はその中でワークショップとして開催された、「RubyData Workshop 2017」の内容を紹介します。
RubyData Workshop 2017
今年のRubyKaigiでは、データサイエンスに関するセッションに注目しました。RubyKaigiといえばRubyの言語仕様や今後の進化の方向性、またRuby on Railsに関するセッションがほとんどだと思っていた1)個人的にRubyでテキストエディタ作った話が面白かったです。のですが、今年はデータサイエンスに関するセッションが多かったのが特徴的でした。そこで、イベント中にRubyData Workshop in RubyKaigi 2017 というRubyでデータを扱うためのワークショップが行われていたので参加しました。
参加したのは以下の二つです。
- PyCall Lecture
- Getting started to Red Data Tools project
PyCall Lectureでは @mrkn 氏が作成したPythonのインタプリタをRubyから呼び出す PyCall というgemを実際に動かし試すことができました。
Getting started to Red Data Tools projectではApache Arrowの説明と Red Data Tools project というRuby用のデータ処理ツールを提供するプロジェクトについての紹介がありました。
以下では「PyCall Lecture」の内容をコードとともに振り返ります。
ちなみに会場は参加者が非常に多く急遽増席されるほどの賑わいでした。世間的にもデータサイエンスに注目が集められていることがわかると思います。

PyCallを使う
では実際にPyCallを動かしてみます。紹介するコードは以下の資料を引用しております。PyCallのメカニズムなど詳しい説明はこちらをご覧ください。
セットアップ
$ git clone https://github.com/rubydata/rubykaigi2017.git
$ cd rubykaigi2017
$ rake docker:pull
$ docker run -p 8888:8888 rubydata/rubykaigi2017 # コンソール上に表示されるURLでアクセスする上記のコマンドを実行すると、Jupyter Notebookが起動されるはずです。

はじめてのPyCall
まずはPythonモジュールを実際に呼んでみます。
require 'pycall'
pymath = PyCall.import_module('math')これによりPythonオブジェクトであるMathモジュールが、Rubyによるラッパーオブジェクト(ここでは pymath )として扱えるようになります。
pymath.pi
#=> 3.141592653589793また、返す値はPythonのFloatオブジェクトがRubyのFloatオブジェクトにコンバートされます。
pymath.pi.class
#=> Floatsin関数を呼びたい場合はこのように
pymath.sin(pymath.pi)
#=> 1.2246467991473532e-16とするとPython側のメソッド math.sin をマッピングした pymath.sin として呼ぶことができます。またPythonのsin関数とRubyのsin関数は同等となります。
pymath.sin(pymath.pi) == Math.sin(Math::PI)
#=> truePyCallは自動的にRubyのfloat値をPythonのfloat値に変換してくれます。
pymath.sin(Math::PI)
#=> 1.2246467991473532e-16このように pymath.sin の引数にRubyのfloat値 Math::PI を渡すこともできます。したがってPyCallはPythonとRuby間の受け渡しとなる役割を果たし、Rubyオブジェクトとして特に意識せずPythonオブジェクトを扱えるようになります。
PyCallのオーバーヘッド
PyCallを経由してPythonを呼び出す場合と、生のRubyで同じ関数を呼び出す場合のベンチマークを計測します。まずはsin(π)を呼び出してみます。
require 'pycall'
require 'benchmark'
pymath = PyCall.import_module('math')
Benchmark.bm(7) do |x|
x.report("ruby:") { 1_000_000.times { Math.sin(Math::PI) } }
x.report("python:") { 1_000_000.times { pymath.sin(pymath.pi) } }
end
nil私の手元の環境では生のRubyの方がPythonより3倍ほど速いことがわかりました。PythonはPyCall経由で動かしているのでこれがPyCallのオーバーヘッドとなります。
user system total real
ruby: 0.530000 0.000000 0.530000 ( 0.529225)
python: 1.410000 0.040000 1.450000 ( 1.455163)sin関数は軽い処理ですが、より重たい処理で現実的な行列計算ではどうでしょうか。そこで次にDGEMMという行列積の計算を行います。なお、Rubyのベンチマークにはnumoを使用します。
require 'benchmark'
require 'numo/narray'
require "numo/linalg/linalg"
Numo::Linalg::Blas.dlopen("/opt/brew/opt/openblas/lib/libopenblas.dylib")
Numo::Linalg::Lapack.dlopen("/opt/brew/opt/openblas/lib/libopenblas.dylib")
require 'pycall'
require 'numpy'
scipy_blas = PyCall.import_module('scipy.linalg.blas')
ENV['OMP_NUM_THREADS'] = '4'
a = Numo::DFloat.new(1500,1500).seq
b = Numo::DFloat.new(1500,1500).seq
c = Numpy.arange(1500*1500, dtype: :float64).reshape(1500, 1500)
d = Numpy.arange(1500*1500, dtype: :float64).reshape(1500, 1500)
p a.shape
p b.shape
p c.shape
p d.shape
nil
n = 100
Benchmark.benchmark('', 15) do |x|
x.report('numo-linalg') { n.times{ Numo::Linalg::Blas.dgemm(a,b) } }
x.report('numpy-linalg') { n.times{ scipy_blas.dgemm(1.0, c, d) } }
end
nilPyCallによるオーバーヘッドが非常に小さいことがわかると思います。
numo-linalg 33.400000 1.460000 34.860000 ( 5.738896)
numpy-linalg 34.210000 1.440000 35.650000 ( 9.099735)このように、重たい処理をする場合はPyCallのオーバーヘッドを無視できることがわかりました2)https://github.com/mrkn/numpy.rb/blob/master/example/benchmarking.ipynb の結果を引用しています。。
ワークショップでは時間ではなくメモリのオーバーヘッドはどうか?という質問がありましたが、PyCallでオーバーヘッドが生まれる箇所は
- Pythonオブジェクトのポインタに対してRubyオブジェクトを生成する
- Ruby側で我々が操作するオブジェクトを生成する
となります。
実際に識別する
次にデータを扱ってみます。ここではデータを読み込み主成分分析による次元削減、結果を可視化します。
require 'numpy'
require 'pandas'
Pandas.options.display.max_rows = 20
require 'matplotlib/iruby'
Matplotlib::IRuby.activateサンプルデータセットとなる iris(150 rows × 5 columns) を読み込みます。
5次元のデータセットとなります。これを主成分分析により次元削減し2次元にします。
150 4 setosa versicolor virginica
0 5.1 3.5 1.4 0.2 0
1 4.9 3.0 1.4 0.2 0
2 4.7 3.2 1.3 0.2 0
3 4.6 3.1 1.5 0.2 0
4 5.0 3.6 1.4 0.2 0
5 5.4 3.9 1.7 0.4 0
6 4.6 3.4 1.4 0.3 0
7 5.0 3.4 1.5 0.2 0
8 4.4 2.9 1.4 0.2 0
9 4.9 3.1 1.5 0.1 0
... ... ... ... ... ...
140 6.7 3.1 5.6 2.4 2
141 6.9 3.1 5.1 2.3 2
142 5.8 2.7 5.1 1.9 2
143 6.8 3.2 5.9 2.3 2
144 6.7 3.3 5.7 2.5 2
145 6.7 3.0 5.2 2.3 2
146 6.3 2.5 5.0 1.9 2
147 6.5 3.0 5.2 2.0 2
148 6.2 3.4 5.4 2.3 2
149 5.9 3.0 5.1 1.8 2カラムvirginicaはラベル(0,1,2)になっているので、これを使用して残りの4次元を2次元空間に投影します。そこでまず、最初の4列をnumpyの配列に変換します。
ちなみに iloc は表の行と列を整数のインデックスとして指定できるメソッドです。PyCallはRubyのRangeオブジェクトをPythonのSliceオブジェクトに変換してくれます。
次に、主成分分析(PCA)を定義します。主成分分析の計算手順はおおまかにいうと
- 重心(平均値)を求める
- ベクトルから平均値を引く
- 特異値分解をする
- 計算した特異ベクトル行列をかける
となります。つまり、ばらつき(分散)が大きいほど元のデータの情報量を含むことを表すので、その軸を探していきます。
def pca(x)
x_bar = x - Numpy.mean(x, 0)
u, s, v = *Numpy.linalg.svd(x)
x_bar.dot v
end
x_pca = pca(x)では求めたx_pcaをmatplotlibを使って可視化します。
plt = Matplotlib::Pyplot
spices = iris[:virginica]
colors = spices.tolist.map {|s| "C#{s}" } # The colors of points
plt.scatter(x_pca[0..-1, 0], x_pca[0..-1, 1], c: colors)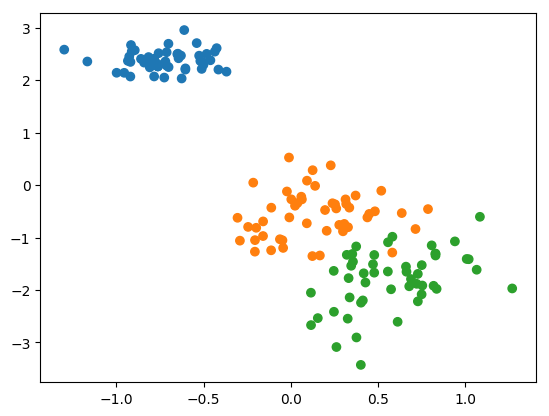
2次元空間で可視化されていることがわかります。このようにPyCallを使うことでRubyによる数値解析とデータの可視化もできました。またPyCallはPython用の機械学習用ライブラリscikit-learnやニュラルネットワークライブラリkerasも利用できるので、データモデリングや作成したモデルによる識別といった機械学習もRubyでスムーズに行えるそうです。
Rubyでのデータサイエンス
Rubyと聞くと、一般的にはRuby on Railsを始めとするアプリケーション開発が主な用途とイメージされることが多いでしょう。ではRubyとデータサイエンスを結びつけて考えたことがあるでしょうか?
そもそもRubyをデータサイエンスで利用する、数値計算に利用するといったイメージはあまりないと思います。PyCall があれば Ruby で機械学習ができるでも言及されているとおり、Rubyには充分な品質を保てるレベルでのデータサイエンスに利用できるライブラリがありませんでした。私も大学時代はPython/R/Matlabのような数値計算に強い言語を使用していました。しかし、レコメンドシステムなど機械学習を利用したサービスがwebの世界でも求められる時代です。にもかかわらず、言語の壁によって開発効率が下がってしまうのは非常に悲しいことです。もちろん言語に関係なく実装するという選択肢も存在しますが、ディープラーニング用のライブラリも整備されWebサービスに普通に使われるコモディティ化した昨今では、普段から慣れ親しんでいる言語で実装できるというのはとても大きな価値です。
今回のワークショップや@mrkn氏のプレゼンテーションを通して、PyCallは上記で述べた問題を解決する選択肢として非常に大きな可能性を感じました。またPyCallの開発スピードからみてもデータサイエンスにおけるRubyの現在の位置づけと可能性で言及されている「実用的な環境を短い期間で整備し、Rubyを使ってデータサイエンスに取り組むユーザを増やす必要がある。」という問題への取り組む姿勢にとても感動しました。
Red Data Tools project
一方で、@mrkn氏は「PyCallはあくまで通過点であって、Rubyがデータサイエンスの領域において利用される準備のためのもの」だと述べています。そこで、Rubyで他のツールと同じ最前線でデータサイエンスができる時代をつくるために活動している、Red Data Tools projectというプロジェクトを紹介します。
Red Data Tools projectではRuby用のデータ処理ツールを提供するため、Apache ArrowというライブラリをRubyで使えるようにしようと取り組んでいます。Apache Arrowは複数のシステム間のデータのやりとりを共通の内部メモリ表現で実現するためのもので、pandasなどの頻繁に用いられるツールでも採用されています。
この取り組みは非常に素晴らしいことですし、私もPyCallを利用したりRed Data Tools projectに参加してRubyの未来のために貢献したいと思いました。いままで大きくビハインドしたRubyでのデータサイエンスの取り組みが、これからはRubyが先陣を切っていく。
-- そんな未来をつくっていきたいですね。
最後に
PyCallによってRubyでも数値解析がよりスムーズにできるようになりました。また、今回のワークショップを通して、今後仕事や趣味でもRubyで機械学習を用いたシステムを実装するきっかけとなるような体験ができ、とても良い時間を過ごせました。
来年のRubyKaigiは仙台でやるそうですが、またぜひ参加したいです!
脚注
| ↑1 | 個人的にRubyでテキストエディタ作った話が面白かったです。 |
|---|---|
| ↑2 | https://github.com/mrkn/numpy.rb/blob/master/example/benchmarking.ipynb の結果を引用しています。 |