目次
はじめに
株式会社リクルートでデータエンジニアとして働いている大拔と申します。 カーセンサーのデータ基盤において、インフラ〜データ連携までの開発・運用を担っています。
本エントリでは私の担当するデータ基盤において、 dbt™️ CLI を活用してデータ開発に自動テストを導入した取り組みについて紹介します。 同じような開発を行なっている方が、dbtを利用した開発改善イメージを持つ助けになれば幸いです。
ここでいうデータ開発とは、ソースデータを変換し、マートデータを生成するSQL及びSQLを実行する基盤の開発を指しています。
前提
dbt™️ CLI とは
詳細は 公式サイト を参照してください。
BigQuery等DWH上でデータ変換を行うためのツールで 「アナリティクスエンジニアリング」という考え方を提唱しており、アプリケーション開発の手法をデータ変換作業に用いているのが特徴です。
機能として下記を備えています。
- 拡張SQLを書いてデータ変換を行える
- Jinjaを使ったパラメータ埋め込み
- 条件分岐/繰り返し
- テストがかける
- 生成したデータがyamlで書いたルールに沿っているかを確認できる
- unique/not null etc…
- 生成したデータがyamlで書いたルールに沿っているかを確認できる
OSS の CLI版 と課金Cloud版があり、Cloud版はgit連携やスケジュール実行、CICDの設定等がブラウザを通してできます。 今回は既存システムにアドオンとしてデータテストのみを組み込みたいためCLI版を利用しました。
導入前環境
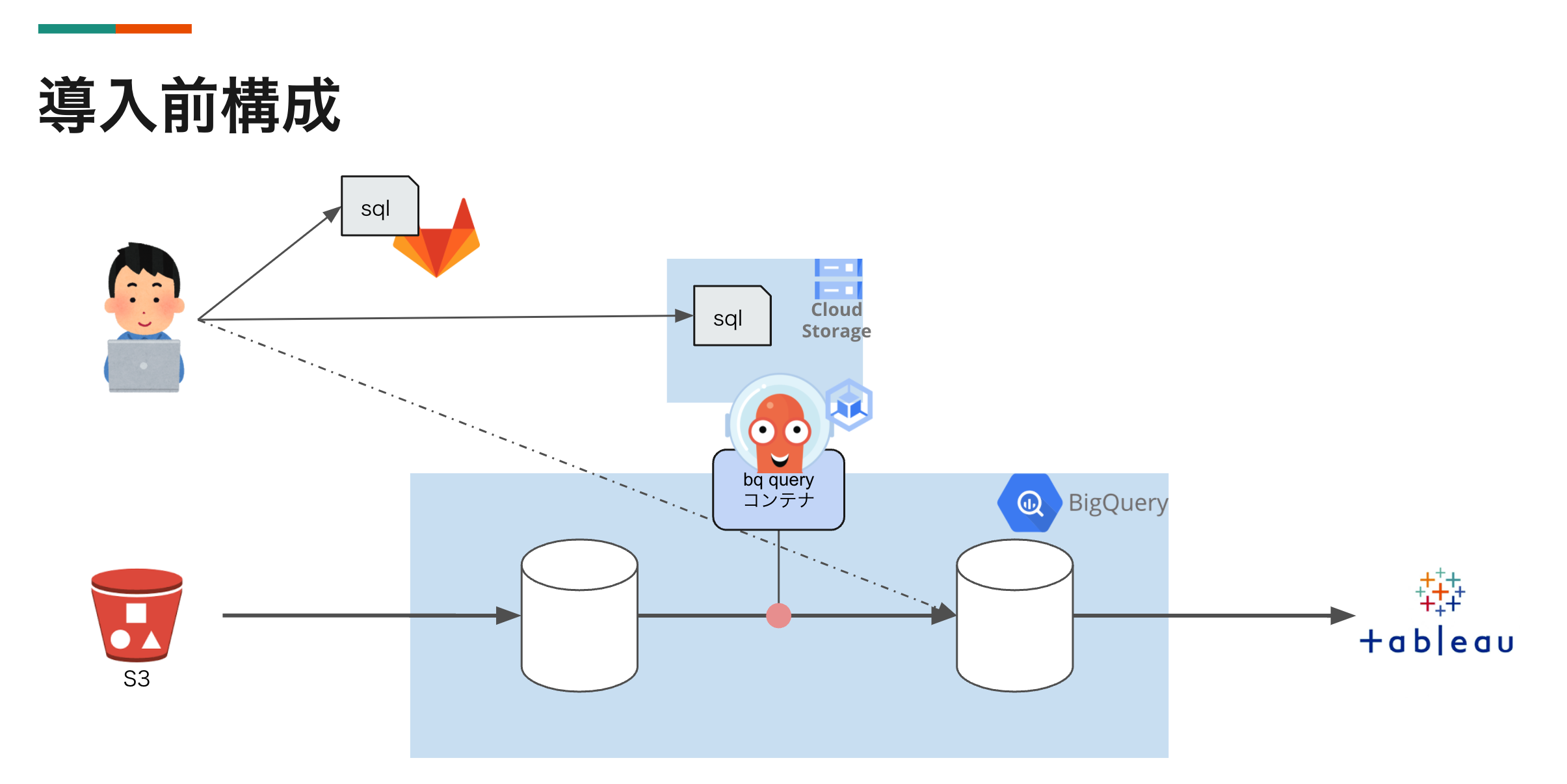
導入前は下記の流れでデータ生成ジョブが動作していました。
- データソースであるS3からBQにデータをロード
- argo workflow on GKE でスケジューリングされたジョブによってSQLを実行してデータ生成 SQL実行はSDKを使って実装した独自コンテナで行う
- SQLはgitで管理されデプロイスクリプトによってargo workflow ジョブが参照できるストレージ上に配置
- 生成されたデータはTableauから参照されて各種BIレポートのソースとして利用される
課題
課題感があった点は、データ開発の品質を保証しつつ、開発サイクルを回したいということです。
dbtを導入する前には以下のような課題が存在しました。
- 生成されたデータの検証は案件ごとに手動でsqlをデプロイした後、確認用sqlを書いたりBIから参照して行っていた
- 生成データは複数のBIレポートに参照され、障害時の後続影響が広い
- 検証環境から検証に足るデータを参照できず、本番データが参照できる、本番環境で検証を実施していた
そこでまずはフィジビリで既存の環境にアドオンする形で導入することにし、dbtのテスト機能のみをデータ開発フローに組み込みました。
導入
詳細な設定方法等は 公式サイト に譲ります。 ここでは、argo workflow on GKE に dbt CLI を導入する上で必要になった点について紹介します。
dbt 設定
導入前の構成でも説明した通り、argo workflow で動かすコンテナには、GCSをマウントすることで sqlを渡していました。 dbtの設定ファイルも同様にGCSを通して渡しました。
具体的にGCSにおいたファイルは下記です。
.
├── .dbt
│ └── profiles.yml # 出力先プロジェクト/データセットの切り替え、権限の設定に使用
├── dbt_project.yml # 共通設定 動作するdwhとしてbigqueryを指定したり、dbtで使える共通変数を書いたり
├── models # sqlを格納 dbtがmodelとして認識する 今回はテストのみ追加のためdbtで実行はしない
├── packages.yml
├── schema # dbtのリソース定義を格納
│ ├── exposures.yml
│ ├── rules.yml # modelごとのテストを記載
│ └── sources.yml
└── tests # テストを記載 rules.ymlで使いまわせる自作テストパッケージも置いている
└── generic
├── sameness.sql
└── sameness_by_columns.sql
dbt 権限設定
BQにアクセスすることになるためその権限をdbtに渡してあげる必要があります。
.dbt/profiles.yml に下記のように記載することでこれを実現しています。
ポイントは method: oauth 部分です。
この設定にすることによってdbt実行時に内部で gcloud コマンドを叩き、GCPへのアクセス権を引き継いでくれます。
今回の動作環境であるargo workflow on GKEでは、 workflow 実行に割り当てたGCPサービスアカウント 1 の権限でBQへのアクセスを行います。 このGCPサービスアカウントにBQのジョブ実行権とデータアクセス権を付与しました。
この方法だとサービスアカウントのキーファイルを作成する必要がなく、セキュリティ面でもよかったと思います。
config:
send_anonymous_usage_stats: false
bigquery:
target: dev
outputs:
prd:
type: bigquery
method: oauth
project: prd-project
dataset: prd_dataset
location: US
threads: 4
dev:
type: bigquery
method: oauth
project: dev-project
dataset: dev_dataset
location: US
threads: 4
argo workflow template
dbt CLIを実行する argo workflow templateとして下記を準備しました。
ポイントとしては下記の二点になります。
- dbt CLIとgcloudコマンドをインストールしたコンテナイメージを呼び出している
-
initContainersでdbt depsを実行し、dbtのパッケージをインストールしている
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: dbt-template-v1
spec:
templates:
- name: dbt
inputs:
parameters:
- name: WORKING_DIR
value: "/home/dbtuser/dbt"
- name: JOB_ID
- name: DBT_TARGET
value: DBT_TARGET_replaced
- name: DBT_COMMAND
- name: SELECTOR
artifacts:
- name: dbt
path: "{{inputs.parameters.WORKING_DIR}}"
gcs:
bucket: GCS_BUCKET_replaced
key: "{{inputs.parameters.JOB_ID}}"
container:
image: location-docker.pkg.dev/hoge/job-images/dbt:v1
securityContext:
runAsUser: 0
workingDir: "{{inputs.parameters.WORKING_DIR}}"
command: [dbt]
args:
- "--no-use-colors"
- "{{inputs.parameters.DBT_COMMAND}}"
- "--profiles-dir={{inputs.parameters.WORKING_DIR}}/.dbt"
- "--target={{inputs.parameters.DBT_TARGET}}"
- "--select"
- "{{inputs.parameters.SELECTOR}}"
initContainers:
- name: deps
image: location-docker.pkg.dev/hoge/job-images/dbt:v1
securityContext:
runAsUser: 0
workingDir: "{{inputs.parameters.WORKING_DIR}}"
mirrorVolumeMounts: true
command: [dbt]
args:
- "--no-use-colors"
- "deps"
- "--profiles-dir={{inputs.parameters.WORKING_DIR}}/.dbt"
- "--target={{inputs.parameters.DBT_TARGET}}"
テスト例
テストはdbtリソース定義に記載することができます。 下記一例です。
- name: reporting_table
tests:
- dbt_utils.unique_combination_of_columns:
combination_of_columns:
- hoge
- fuga
columns:
- name: test_column
tests:
- accepted_values:
values: ['a','b','c']
上記設定の上、dbt test の実行によりテストが実行されます。
$ dbt test --select reporting_table
07:00:48 Running with dbt=1.0.1
07:00:49 Found 48 models, 120 tests, 0 snapshots, 0 analyses, 581 macros, 0 operations, 0 seed files, 73 sources, 11 exposures, 0 metrics
07:00:49
07:00:51 Concurrency: 4 threads (target='dev')
07:00:51
07:00:51 1 of 2 START test accepted_values_hoge [RUN]
07:00:51 2 of 2 START test dbt_utils_unique_combination_of_columns_hoge_fuga [RUN]
07:00:54 1 of 2 PASS accepted_values_hoge [PASS in 2.50s]
07:00:57 2 of 2 PASS dbt_utils_unique_combination_of_columns_hoge_fuga [PASS in 6.08s]
07:00:57
07:00:57 Finished running 2 tests in 6.08s.
07:00:57
07:00:57 Completed successfully
07:00:57
07:00:57 Done. PASS=2 WARN=0 ERROR=0 SKIP=0 TOTAL=2
内部的には定義したルールに違反する行のcountを取るSQLが生成・実行されているようです。
複雑なSQLではないですが、これがyamlの設定だけで自動生成され、定義に沿っているか確認してくれることは、 生成するデータが増えれば増えるほど恩恵が大きいと感じます。 また上記のようなunique/accepted_valueテストだけでなく、様々なテストがパッケージとして提供されており、それに当てはまらないテストは自分で記載することも可能です。
dbt導入後
dbt導入後構成
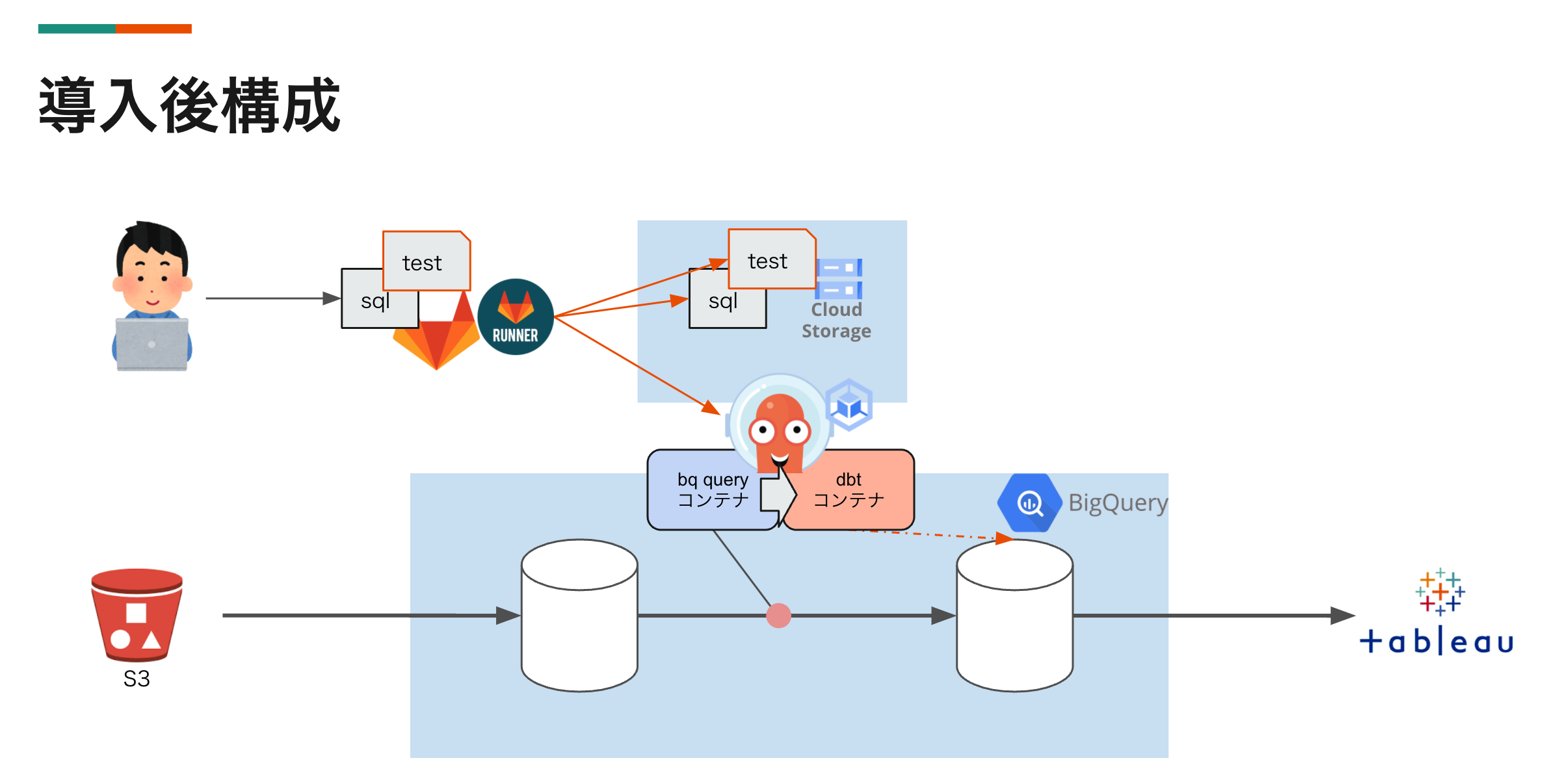
大きな処理は変えずに、SQL実行によるデータ生成後にdbt コンテナを使って 生成したデータに対してテストを実行する構成に変更しました。
SQLの開発が自動テストによる最低限のガードレールに守られるようになりました。
今後の取り組み予定
現状はdbtの機能のうち、テストだけを先行して導入しました。 これだけでも毎回SQLを手で書いて生成データを確認していたときに比べれば、 安心してデータ開発が行えるようになったと思いますが、
dbtの他の様々な機能を活用し、データ開発の効率化、高度化を進めるため、 データ変換処理自体にもdbtを導入予定です。
テストを導入できるようにしたことで、テストをしやすい単位にSQLを分割するモチベーションも生まれました。 データ開発をより安全に効率よくしていく第一歩がdbtによって踏み出せたと思います。
最後まで読んでいただきありがとうございました。
We are Hiring
弊社では、様々な職種のエンジニアを募集しています。興味のある方は、以下の採用ページをご覧ください。
===========================
株式会社リクルート 中途採用サイト
リクルート 学生向けキャリアサイト
===========================
-
workflow 実行にGCPサービスアカウントを割り当てるためにWorkloadIdentityを使っています。 ↩︎