目次
はじめに
こんにちは! リクルートマーケティングパートナーズで iOS アプリの開発を主に担当している保坂です。弊社の井原と共に 6 月 5-9 日に開催された WWDC 2017 に初参加してきました。Keynote では iOS 11 や macOS High Sierra などの発表があり、開発者の一人としてもワクワク感に溢れた1週間になりました。
今回は、iOS 11 で新規追加されたいくつかの Framework の中から Vision.framework という画像処理の機能を提供する標準ライブラリを試してみました。サンプルプロジェクトも用意しましたので、『どんな感じで使えるのかな?』と興味を持っている方に読んでいただけると幸いです。
Vision.framework とは
Apply high-performance image analysis and computer vision techniques to identify faces, detect features, and classify scenes in images and video.
こちらのリファレンスにもある通り、 デバイス単体で顔認識や特徴検出、画像の分類などが出来る比較的抽象度の高いライブラリ です。Core ML という Vision.framework と同じく今回の WWDC 2017 で発表された機械学習に関する機能を提供するライブラリが内部で使われています。
Vision.framework で提供される機能には以下のようなものがあります。
| 顔検出 | Face Detection and Recognition |
|---|---|
| 機械学習による画像分析 | Machine Learning Image Analysis |
| バーコード検出 | Barcode Detection |
| 画像の位置合わせ | Image Alignment |
| テキスト検出 | Text Detection |
| 水平線検出 | Horizon Detection |
| オブジェクト検出とトラッキング | Object Detection and Tracking |
オブジェクト識別などの機能を利用するには Core ML のモデルデータが必要になりますが、それ以外は機械学習のことを詳しく知らなくとも利用できるシンプルなインターフェイスになっています。
Vision.framework のテキスト検出を試す
今回は Vision.framework が提供する機能の中でも個人的に気になったテキスト検出を試してみることにしました。百聞は一見にしかず。まずはこちらの gif アニメでサンプルアプリの動作をご覧ください。
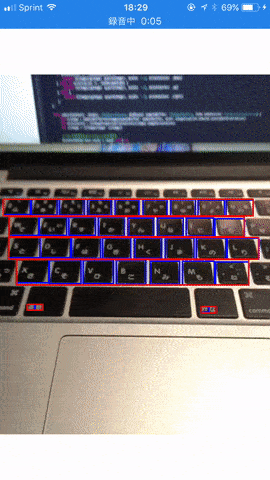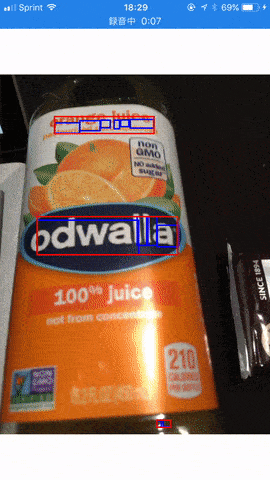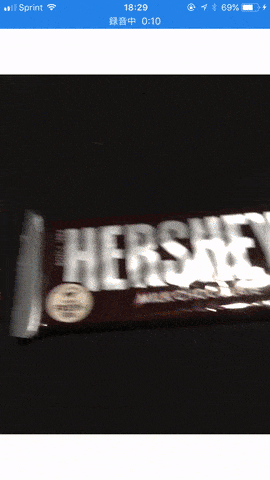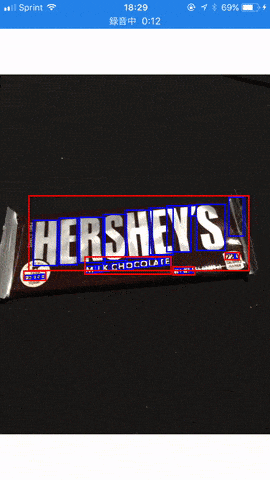
ご覧の通り十分な精度でテキストの領域が検出されていることが分かりますね。 Vision.framework 単体では残念ながら具体的な文字の内容までは認識できませんが、前述の Core ML を用いた文字認識と組み合わせることにより、 Google Translation アプリ のようなリアルタイム文字認識も可能になるのではないかと思います。
カメラプレビューの処理を含むサンプルアプリ全体のコードは上記リポジトリからご覧ください!
Vision.framework による画像処理フロー
簡単に Vision.framework を使い画像処理を行う際のフローを紹介します。
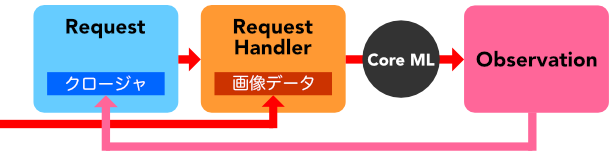
Request, RequestHandler, Observation という3つのオブジェクトが登場します。
処理対象の画像を用意し、画像処理タスクをシステムに要求する Request オブジェクトを作成します。その後、ターゲットの画像を保持し Request をハンドルする RequestHandler オブジェクトを作成します。 RequestHandler を使い Request を実行すると、処理結果として Observation オブジェクトが Request の保持しているクロージャーに渡されます。
今回試すテキスト検出では、次の Request, RequestHandler, Observation の組み合わせを利用します。
| 役割 | 具体的なクラス名 |
|---|---|
| Request | VNDetectTextRectanglesRequest |
| RequestHandler | VNImageRequestHandler |
| Observation | VNTextObservation |
次の節では実際のコードを見ながら使い方を解説していきます。
RequestHandler の作成
単体の画像を処理するには、RequestHandler として VNImageRequestHandler を使います。 VNImageRequestHandler のイニシャライザには CIImage や CGImage, CVPixelBuffer, Data などを引数にとるものがあります。ここでは処理の都合上 UIImage を CIImage に変換して使います。
let uiImage = ...
let orientation = CGImagePropertyOrientation(uiImage.imageOrientation)
let ciImage = CIImage(image: uiImage)!
...
let handler = VNImageRequestHandler(ciImage: ciImage, orientation: Int32(orientation.rawValue))ここで画像が持つ orientation の情報を正しくイニシャライザに渡してあげる必要があります。
わたしが最初にサンプルを実装した際にはイニシャライザに orientation を渡すのを忘れてしまったため、画像を表示するときの向きと処理結果が食い違ってしまうという問題に遭遇しました。
// 公式のサンプルを参考にしました
// https://developer.apple.com/videos/play/wwdc2017/506/
extension CGImagePropertyOrientation {
init(_ orientation: UIImageOrientation) {
switch orientation {
case .up:
self = .up
case .upMirrored:
self = .upMirrored
...
}今回のサンプルでは、 UIImageOrientation から CGImagePropertyOrientation を得るために上記のような extension を用意しました (公式のサンプルを参考にしました) 。
Request の作成
下記のコードで VNDetectTextRectanglesRequest オブジェクトを作成します。
let request = VNDetectTextRectanglesRequest() { request, error in
// request.results の使い方は後述
}
request.reportCharacterBoxes = trueVNDetectTextRectanglesRequest のイニシャライザにリクエスト完了後の処理をクロージャーで渡します。クロージャー内では request.results で処理結果の配列が得られます。また、エラーが発生した場合は error パラメータでエラーの詳細を得ることができます。
request.reportCharacterBoxes = true の行は、検出したテキストブロックの矩形を得る以外に 1 文字ごとの矩形を処理結果として得るために必要になります。
Request の実行
上記で作成した VNImageRequestHandler の perform([VNRequest]) メソッドで画像処理を実行します。サンプルコードなので、エラーのときはとりあえずアプリをクラッシュさせるようにしました。
perform メソッドが Request の配列をとることからも分かるように、複数の Request を同時に実行することも想定されているようです。
Observation の取得
VNDetectTextRectanglesRequest のイニシャライザに渡したクロージャーを再掲します。
let request = VNDetectTextRectanglesRequest() { request, error in
// テキストブロックの矩形を取得
let rects = request.results?.flatMap { result -> [CGRect] in
guard let observation = result as? VNTextObservation else { return [] }
return [observation.boundingBox]
} ?? []
// 文字ごとの矩形を取得
let characterRects = request.results?.flatMap { result -> [VNRectangleObservation] in
guard let observation = result as? VNTextObservation else { return [] }
return observation.characterBoxes ?? []
} ?? []
...
}request.results の型は [Any]? なので、後でビジュアライズするのに適した型に変換しています。最終的にテキストブロックに対応する矩形の配列が [CGRect] として、各文字に対応する矩形の配列が [VNRectangleObservation] として得られます。
ビジュアライズのためのTips
検出結果として得られる矩形の各点は画像の左下を (0, 0) 、右上を (1, 1) とする座標系で表現されています。そのため、 元画像に検出結果を重畳するには得られた各点の座標を適切な座標系に変換 してから描画しなければなりません。

今回のサンプルコードでは、下記のようなメソッドを実装し、座標の変換を行っています。
private func convertedPoint(point: CGPoint, to size: CGSize) -> CGPoint {
// view 上の座標に変換する
// 座標系変換のため、 Y 軸方向に反転する
return CGPoint(x: point.x * size.width, y: (1.0 - point.y) * size.height)
}
private func convertedRect(rect: CGRect, to size: CGSize) -> CGRect {
// view 上の長方形に変換する
// 座標系変換のため、 Y 軸方向に反転する
return CGRect(x: rect.minX * size.width, y: (1.0 - rect.maxY) * size.height, width: rect.width * size.width, height: rect.height * size.height)
}おわりに
今回は Vision.framework を用いてテキスト検出を行うためのフローを簡単に解説しました。 Request, RequestHandler, Observation からなる画像処理のフローは Vision.framework に共通しているので、一度理解すれば他の機能もすぐに実装できるかと思います (Core ML のモデルが必要な機能だけは、いくつか追加のステップが必要ですが……) 。
今回実装したコードは カメラプレビューや画像フォーマットの変換などに必要な分を含めても 240 行ほどでした。特徴認識や領域検出など一昔前なら OpenCV などでゴリゴリ書く必要のあった処理がここまでシンプルに実装できるのは素直に驚きですね。
WWDC 2017 で発表された ARKit もそうですが、専門的な知識がなくとも高度な画像処理を実現できる良い時代になりました。普段の業務の中でもこうしたライブラリを活用できる可能性を探すことができたらと思います。
それではまた! ヨーソロー!