目次

この記事は リクルート ICT統括室 Advent Calendar 2023 18日目の記事です。
こんにちは、ICT統括室の別府(@tky_bpp)です。この記事は、社内の情報流通を社内プロダクト起点で改善しようとしている取り組みの紹介です。
具体的には「社内・社外に分散している情報」を集約することで「各従業員がこれまでどのような仕事をしてきたのか」を可視化しようとしている取り組みです。その中でも、主にプロセス、工夫した点について書いています。そのため、特定の技術スタック、ツールの紹介といった技術的な内容にはあまり触れません。
同じような課題に取り組んでいる方にとって、少しでも参考になれば幸いです。
はじめに
私は現在、リクルートの社内で利用されている従業員検索システムのプロダクトマネージャーをしています。
このシステムには、従業員毎の個人ページがあり、連絡先や所属部署、使用しているパソコンや携帯などの端末、さらには各種システム/SaaSサービスのアカウント情報など、一人ひとりの従業員に関連する情報が集約されています。このシステムにはリクルートグループ全体で約5万人の情報が掲載されており、毎月100万PV以上ものアクセスがあります。
各従業員の個人ページには、社内報での特集記事や部署での表彰歴、社外での講演資料やインタビュー記事などの情報も掲載しています。これらの情報は、その人のバックグラウンドを理解するために有用な情報です。記事のタイトルを見て、詳細が気になったら、元のメディアのページにアクセスできるよう、リンクを設けています。
本記事は、この掲載情報の記事「データ」をいかにして集めたか、という内容です。
-
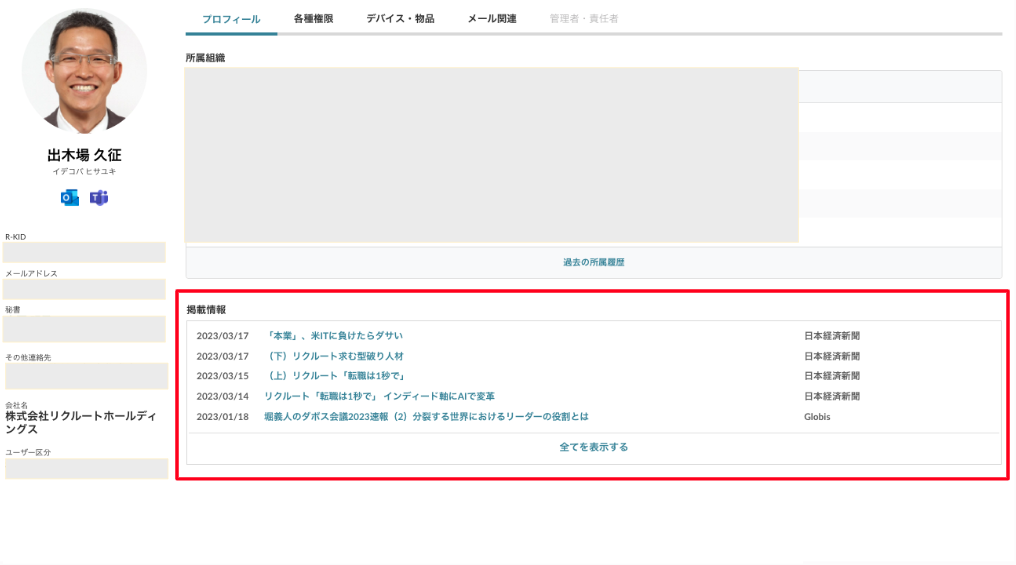
図1:掲載情報の実例 (リクルートホールディングスCEOの出木場)
元々、これらの情報は社内・社外の様々な組織に散在していて、「どの情報がどこにあるのか、どこを探せばよいのかわからない」という問題がありました。この問題を解消し、「ここを見ればOK!知りたい情報はここにまとまっている!」という状態を目指して取り組んでいます。
なぜやったか (背景・課題)
社内で誰が何をしているのかがわからない問題
業務を進める中で問題に直面したり、他のプロダクトやプロジェクトの事例を参考にしたい場合、誰に問い合わせればよいかを知るために、他の人に連絡し、担当者につないでもらうという流れがよくあります。私自身もこれを何度も経験してきました。
グループ全体で約5万人もの従業員がいるのであれば、社内には先行事例や具体的な知見を持つ人がいるはずです。しかし、社内で誰が何をしているかを効率的に知る手段がないので、他の人に聞いて探すしかないという状況が続いていました。なかには、社内の人物を理解するために Google で検索し、公開されたインタビュー記事を読むことで把握している人もいました。
ここで、「トランザクティブ・メモリー」という概念を紹介します。これは、組織の学習能力やパフォーマンスを向上させるためには、組織内のメンバーが同じ知識(What)を共有するのではなく、組織内の「誰が何を知っているか(Who knows what)」が共有されている状態を重視することが重要だという考え方です。これは1980年代にハーバード大学のダニエル・ウェグナー教授によって提唱されました。(*)
「誰が何を知っているか」が明確になれば、効率的なコミュニケーションと業務の遂行が可能になります。担当者を人づてに探していくという手間を省き、適切な人物にすぐにアクセスできるようになるからです。今回の取り組みは、まさに「誰が何を知っているか」を社内のプロダクトを通じて共有しようとするものです。
何をやったか (施策)
冒頭でも紹介しましたが、各従業員の個人ページにて、社内・社外のメディアへの掲載情報や表彰歴を確認出来るようにしました。約90の組織やメディアからの記事が1万件以上掲載されており、社員の約5人に1人は何らかの記事が紐づいています。
具体的に掲載している情報は以下の通りです:
社内コンテンツ
・社内報
・各事業部のニュースレター
・各組織の表彰
社外コンテンツ
・コーポレートブログやテックブログの投稿記事
・社外メディアでのインタビューや寄稿記事
・社外イベントでの講演資料
これらの情報は、まさに、その人がどのような業務に取り組んできたのかを示すものであり、記事を参照することでその人の経歴やスキルなどを理解するための有用な情報となります。現在も、まだまだ情報を拡充している最中であり、まだ道半ばの状況ですが、すでに現場からは「本人に聞かなくてもある程度把握できるようになってとても有り難い」「自分の登壇資料や取材記事が探しやすくて助かる」といった嬉しい声が上がり始めています。
どのようにやったか (工夫)
① 前提:部分最適ではなく全体最適で考える
情報が各組織に分散しているという事象は、リクルートが2012年から2021年にかけて分社化から再統合へと移行していく過程で発生した結果のように思います。これは「コンウェイの法則」にあてはまります。「ITシステムは組織のコミュニケーション構造と同じ構造になってしまう」というものです。
とはいえ、会社が統合されたからといって、情報が分散しているという課題が自然と解決するというわけでもありません。データソースの統合の難易度は高く、時間と労力がかかるため、各部署が個別に管理を継続することになりがちです。その結果、部分最適が進行していきますが、部分最適の積み上げが全体最適になるとは限らないので、全体最適の視点で手を打つことが重要です。
そのため、全社共通で利用できるデータ基盤としての設計が重要です。前部署の同僚であり、今は様々な企業におけるデータ経営の最前線で活躍している yuzutas0氏 は、 データ基盤を「複数のデータソースと複数の利用者をリボンのように結びつけるもの」と定義しています。

今回の取り組みは、全体最適の視点で検討し、まさに「社内で複数の部署に分散したデータソースを一箇所に集約し、複数組織の利用者が使えるようにしたもの」です。これにより他の部署に存在していたデータにアクセスしやすくなり、全体最適に一歩近づきました。構築したアーキテクチャの概要図は後続の章で紹介します。
② 方針:構造化データとして管理する
全体最適を目指すとしても、データソースの統合は難易度が高いため、今回は一元管理とは異なるアプローチを採用しました。データの実体は各組織がそれぞれ管理することは変わらず、それらを直接保持するのではなく、実体にたどり着けるようにインデックスとして管理しています。
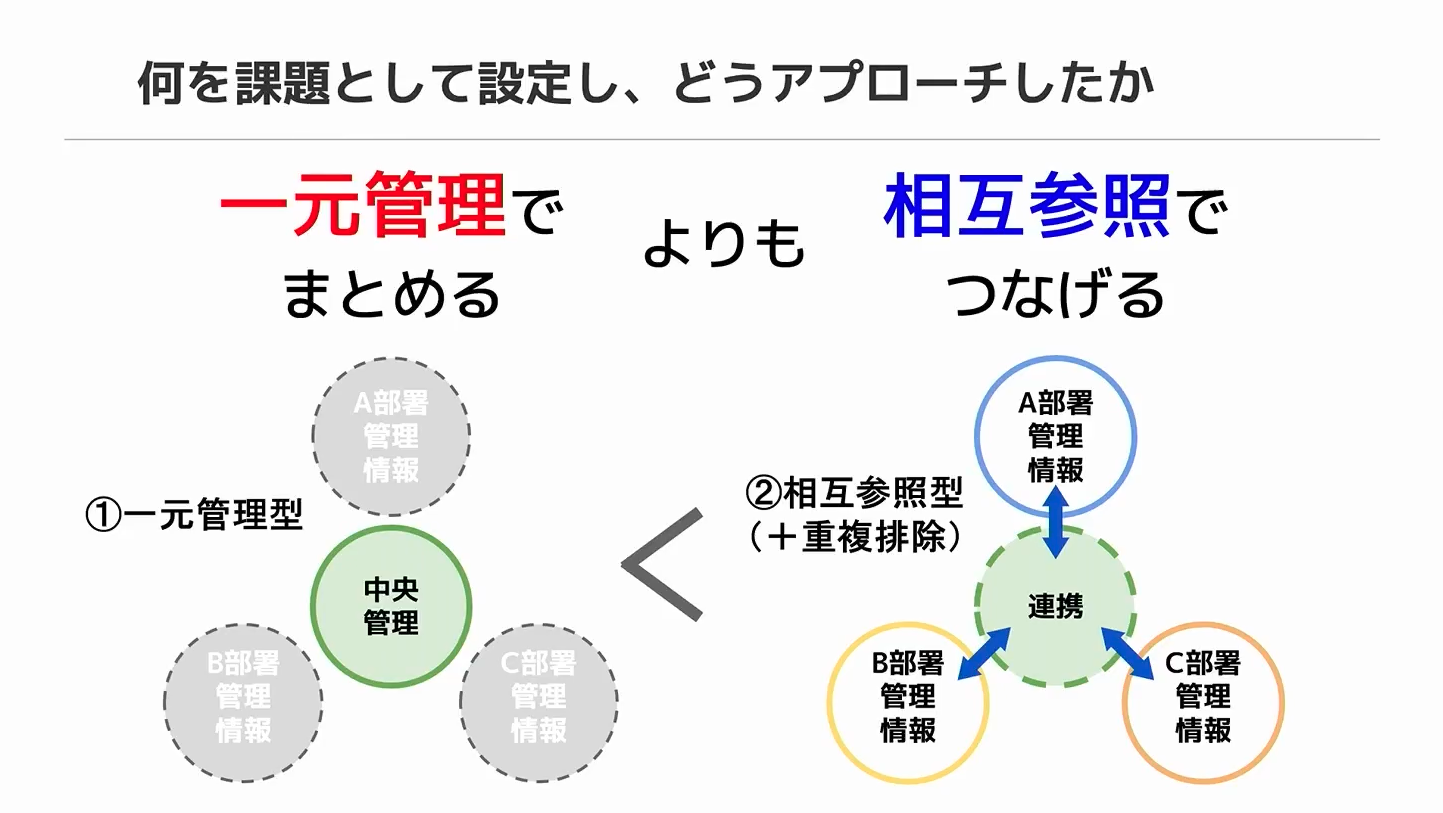
社内ポータル上のコンテンツや講演資料などの情報は、一見、非構造データに見えますが、同じフォーマットで表現することで、共通の意味を持つデータとして構造化して管理ができるようになります。以下のような、シンプルなフォーマットで各組織のデータを共通化し、各データに従業員IDを関連付けて管理しています。

従業員IDをキーにすることも重要なポイントです。
元々社内で管理されていたデータには従業員IDが記載されていないものもありました。その状態では、今回のような取り組みをしようとすると問題が発生します。
・氏名しか記載していない → ✕ 同姓同名の区別が出来ない
・氏名とメールアドレスしか記載していない → ✕ メールアドレスは変更される可能性がある
・従業員IDが記載されている → ◎ 従業員を一意に識別できる
そのため、各メディアの担当者に対して、従業員IDを含めて管理してもらうよう説明し、対応してもらいました。
③ 効率化:集約は可能な限り自動化する。手動でもなるべく負荷を増やさない
現在も更新が続いているメディアは複数あり、そのようなメディアの情報を継続的に収集・更新する仕組みも検討しました。
その構造化するプロセスには効率性が求められます。各メディアの管理者に登録用のデータを別途用意してもらうよう依頼することは、作業負荷を増やすことを意味しています。全てを手作業で実施することはあまり現実的ではありません。

自動連携
社内の各組織のニュースレターには、Microsoft SharePoint を利用しているメディアがあります。各記事には、掲載者のプロフィール欄があり、そこに個人ページへのリンクを記載してもらうようにしています。
このリンクの URL には従業員IDが含まれているので、SharePoint のデータを API 経由で取得し、このリンクのURLを元に個人を識別しています。これにより、記事の一覧を別途用意して管理することが不要となり、自動での連携が実現しました。
ただし、記事にリンクを記載する作業が必要にはなりますが、これにより記事の読者は、気になった人物の連絡先などを記事から直接確認できるようになるという利点があります。自動連携されることで、従業員検索システムの掲載情報からアクセス出来るようになるため、メディア側の閲覧数増加にも結果的に繋がります。
半自動連携
社外向けのブログなどのオウンドメディアの場合、上記の運用のように自動化することはできず、どうしても記事と当該従業員の紐づけ作業が必要です。
しかしながら、RSS データの利用やクローリングを経由して記事の情報を取得することで、連携に必要な情報の大半を自動取得することができます。具体的には「メディア名」「記事タイトル」「記事URL」「掲載日」 は自動で取得し、「従業員ID」 のみを手動で記載するだけで十分になりました。
RSS データの取得やクローリングは Google Apps Script で実装し、取得したデータは Google スプレッドシート に登録しています。これにより、シートにそのまま追記することで掲載するデータを用意しています。
これらの工夫により、情報の収集・更新を可能な限り自動化し、手動でも負荷を増やさないようにすることができました。
④ 効果最大化:「見られる」場所に掲載する
社内に情報は存在しているが認知されていない ・・・ではどうやって認知してもらうか?という課題は、社内マーケティングの課題として捉えることが可能です。つまり、各コンテンツの潜在的な見込み顧客を最大化するためにどうすればいいのか?という問いに言い換えることが出来ます。
今回は、従業員検索システムの各個人ページに情報を掲載することが最適なのでは、と考えました。なぜなら、現状、連絡先の確認や所属部署の確認などのために、日々の業務で頻繁にアクセスされる場所となっており、月間100万PVを超える社内でも最大級の「メディア」だからです。
この場所に掲載することで、その人を知りたいと思う人が情報を見つけられるようになるだけでなく、連絡先を確認するといった別の目的でアクセスした人が「偶然」掲載情報を目にすることも可能になります。
社内コンテンツは、公開当初は注目を集めますが、時間が経つと見られる回数は減少していきます。さらに、「どこに情報があるのか」という情報自体が暗黙知であるため、後から入社した人がそれを探し出すのは容易ではありません。
だからこそ、過去のコンテンツが「後から」参照される機会を増やせる、というのは非常に価値があります。実際に、月間のアクセス数がユニークユーザー(UU)ベースで25%増加した社内メディアもあります。
IBMのナレッジ・マネジメント研究所所長などを歴任したローレンス・プルサック氏らのナレッジマネジメントに関する著書にも同様の主張が記載されています。
「グローバル企業になると、組織のどこに知識があるのかを把握し、アクセスできなければならない。組織のどこかにある、では役に立たない。アクセスできた時のみ、価値ある企業資産となり、アクセスの程度に応じて、その価値が増大する」『ワーキング・ナレッジ―「知」を活かす経営
今回の取り組みは、まさにこの主張を具現化したものです。社内に蓄積された情報を、後からでも容易に見つけられるような仕組みを目指しています。
以上、①〜④の工夫をまとめると
(1) 社内・社外に分散しているデータを1ヶ所に集約した (かつ継続的に集約できるようにした)
(2)集約したデータを社内の目立つ場所に配置した
と言えます。これは小売業と同様のアプローチだと考えています。
(1)は、商品の仕入れに注力すること、そして継続的に効率よく仕入れができるように物流を整備すること
(2)は、商品が売れるようにマーケティングに注力すること
(1)だけでは不十分で、(1)と(2)を同時に取り組むことが重要だと考えています。
終わりに
今回の取り組みを通して、「人を知る」ことに関しては少しですが改善が出来ました。しかしながら、他にも「人を探す」ことの課題もあります。掲載するデータの拡充は引き続き推進しつつ、今後は、集約したデータを活用して、もっと簡単に「人を探す」ことが出来る仕組みの検討にも取り組んでいきたいと考えています。
今回の取り組みは、各事業部のインナーコミュニケーション担当や広報担当など、各メディアの管理者の皆様の協力があったからこそ実現に至りました。関係者の皆様には、改めて感謝を申し上げます。
もし、これを読んでくださっている方の中で、同じ課題を抱えている方がいたら、ぜひ情報交換させていただけると幸いです。ご連絡お待ちしています。
リクルート ICT統括室 Advent Calendar 2023 では、リクルートの社内ICTに関する記事を投稿していく予定です。もし興味があれば、ぜひ他の記事もあわせてご参照ください。
- 社内ICT領域全体でのデータ利活用の記事:リクルートの社内ICT領域におけるデータ利活用の取り組み
- 本記事の取り組みをサポートしてくれている上司の記事:無茶振りのよい/わるいを考えてみた件