目次
リクルートの大杉です。
本ブログは、2021年2月から3月に弊組織(検索ソリューショングループ)で一緒に働いてもらったアルバイトの塚越駿さんが、今回のアルバイト期間中に実施したことをまとめたものです。
彼には、我々が社内向けに量産している「情報検索API」の内部改善の一環で、Amazon Elasticsearch Service を実サービスで展開するための性能検証を行っていただき、そこで得られた知見を広く共有すべく技術ブログを書いてもらいました。
—ここから塚越さんの記事です—
こんにちは、RECRUIT Job for Student 2021に参加していた塚越駿と申します。
本記事では期間中に取り組んだ、既存システムのAmazon Elasticsearch Serviceへの移行に向けた調査と、本番環境投入のための負荷試験についてご紹介します。
はじめに
改めまして、こんにちは。
塚越駿と申します(Twitter: @hpp_ricecake, hppRC)。
普段は所属している研究室で、自然言語処理の研究を行いつつ、趣味でちまちまコードを書いたりしています。
今回のアルバイトではエンジニアコースに応募し、検索ソリューショングループという部署に配属されました。
検索ソリューショングループは機能軸組織と呼ばれており、リクルートに存在する多くのサービスに対して、横断的に検索機能の改善を行っていくという組織です。
今回取り組んだタスクはその中でも、情報検索用の検索API(以下、チーム名からQass API と呼称します)の社内向け開発基盤に関連するものです。
Qass APIを利用して開発を行うことで、利用者側は一からAPIの全てを開発する必要がなくなり、検索のランキングやキーワードの最適化など、そのサービス特有の部分に集中することができます。
Qass APIの内部ではElasticsearchを検索エンジンとして利用しており、高効率なシステムの構築を可能としています。
加えて、通常のキーワードによる検索の他に、文書を表現するベクトルをあらかじめ用意し、検索クエリに含まれるベクトルと、保存されている各文書のベクトルとの類似度を計算することで、類似した文書を返却する機能を提供しています。
これにより、単純な文字列マッチ度的な指標だけでなく、文書の意味的な情報を元に類似文書検索を行うことができ、より高度にランキングを構築することができます。
Qass APIではこれまで、自前でFargateにElasticsearchインスタンスを立ち上げることで検索APIを提供していました。
しかし、マルチリージョン、マルチマスター、専用マスターノード等を考慮したクラスタ構成ができていなかったりと、可用性について改善の余地がありました。
そこで、自前のインスタンス管理からマネージドサービスへの移行に向けた機運が高まっており、私はその一環として、以下のタスクに取り組むことになりました。
- Amazon Elasticsearch Serviceへの移行に向けた差異の調査
- 本番環境投入に向けた負荷試験と将来を見据えたコストパフォーマンスの調査
アルバイト期間前半のタスクとして、既存のシステムを自前のElasticsearchからAmazon Elasticsearch Serviceへ移行するための、差異の調査を行いました。
アルバイト期間後半のタスクとしては、Amazon Elasticsearch Serviceを用いた負荷試験を行いました。
以降より、それぞれのタスクごとに、業務で実施した調査やその内容についてご紹介します。
Amazon Elasticsearch Serviceへの移行に向けた差異の調査
事前知識
まず、Elasitcsearchについて簡単に概要を述べます。
ElasticsearchはElastic社が主に開発を行っている、Java製の全文検索エンジンです。内部でApache LuceneというJava製の検索エンジンライブラリを利用しています。
文書の検索に強く、例えばキーワードにヒットする求人原稿を高速で求めたい場合などへの利用が考えられます。
他にも、分散処理をいい感じにやってくれるので、大規模なログデータを保存して、異常検知などに役立てることもできます。
Elasticsearchのマネージドサービスには、開発元であるElastic社が提供するElastic CloudのElasticsearch Serviceや、GCPが提供するElasticsearch Serviceがあります。
Qass APIではもともとAWSをメインで利用していたこともあり、諸々の事情で今回はAmazon Elasticsearch Serviceを採用することとなりました。
しかし、ここに移行をする上での問題が存在します。
背景から順を追って説明します。
現状、Elasticsearchは大きく分けて二つ存在します。
一つはElastic社が主に開発を行っているElasticsearchです。
もう一つは、Amazonが独自に公開しているOpen Distro for Elasticsearchです。
そして、Amazon Elasticsearch Serviceは、Open Distro for Elasticsearchを用いて構築されています。
これは、もともとElastic社が公開していたElasticsearchにプロプライエタリなコードが含まれていたことを理由としてAmazonが独自ディストリビューションを作ったためです。
これに対抗して、Elastic社がElasticsearchのライセンスを変更しています。
つまり、Amazon Elasticsearch ServiceとそのほかのElasticsearchのマネージドサービスとでは、使用しているElasticsearchそのものが異なります。
Qass APIで使用していたElasticsearchは、Elastic社が公開しているものだったため、Amazon Elasticsearch Serviceに移行する上で使用できる機能に差が生じます。
そして、その差異の中で最も影響が大きいのが、類似ベクトル検索を行う機能です。
Elastic社が公開するElasticsearchにはdense vector field typeという文字通り密ベクトルを表現するためのフィールド型が存在し、このフィールド型を通してベクトルの類似度をコサイン類似度やユークリッド距離の逆数などで測ることができます。
Elasticsearchはpainlessという独自のスクリプト言語を用いて、検索結果のランキングを行うことができますが、painless scriptの中で以下のように直接コサイン類似度を測る関数を呼び出すことができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
{ "size": 10, "_source": {"includes": ["DESC"]}, "query": { "script_score": { "query": { "terms": { "DESC": ["term1"] } }, "script": { "source": "cosineSimilarity(params.query_vector, 'VECTOR') + 1.0", "params": { "query_vector": [0.1, 0.2, ...] } } } } } |
dense vector field typeを使うことで、類似ベクトル検索を非常に手軽に行うことができますが、残念ながらこの機能はもともとElastic社が商用ライセンスで提供していた機能の中に含まれており、Open Distro for Elasticsearchを用いる場合、つまりAmazon Elasticsearch Serviceを用いる場合は、dense vector field type は使うことができません。
また、この影響で、既存のシステムで使われている上記のクエリを、そのままAmazon Elasticsearch Serviceで使うことはできません。
具体的には、現在のAmazon Elasticsearch Serviceで使われているOpen Distro for Elasticsearchにおいて、painless scriptの中でcosineSimilarityなどの関数を使うことができません。
(Open Distro for Elasticsearch v0.1.13からは、painless scriptの中でベクトル類似度関数を使えるようにするPull Requestがmergeされているので、改善される見込みです)。
よって、Amazon Elasticsearch Serviceへの移行を考える上で、クエリをどのように書き換えれば良いか、ということを調査する必要があります。
Open Distro for Elasticsearchとの差異
dense vector field typeの代替として、Open Distro for Elasticsearchではknn vector field typeという別のフィールド型が提供されています。
k-NNはk-nearest neighbor(k近傍法)の意味なので、dense vectorと比べると名前の違和感がすごいですが、それは飲み込んでknn vector field typeについて見ていきましょう。
knn vector field typeはOpen Distro for Elasticsearchのk-NN pluginで提供されており、Amazon Elasticsearch Serviceでは特に追加の設定なく使うことができます。
k-NN pluginでは二つのベクトル類似度によるk近傍探索を行うことができます。
一つ目は、exact k-NN、つまり、正確なk近傍を返します。
二つ目は、approximate k-NN、つまり近似k近傍法です。
HNSW(Hierarchical Navigable Small World)というアルゴリズムを用いて、大規模なデータに対してもスケールします。
Elasticsearchのdense vector field typeを用いた類似ベクトル検索は、以上のどちらかを用いて実現することができます。
では、実際にどのようにクエリが変化するかみてみましょう。
knn vector field typeを利用する場合は、まずindexの設定が必要です。以下のようにk-NN plugin用の設定を追加します。
設定する項目は、k-NNを使う上での距離空間(コサイン類似度)と、各データの型、ベクトルの次元の指定です。
通常のElasticsearchのdense vector field typeを用いた場合との違いを、コメントで示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "settings": { "index": { "knn": true, # 追加 "knn.space_type": "cosinesimil" # 追加 } }, "mappings": { "properties": { "VECTOR": { "type": "knn_vector", # `dense_vector`から変更 "dimension": 512 # `dims`から名前変更 } } } } |
まずは、先ほどお見せしたクエリに対応する例として、exact k-NNを利用してコサイン類似度で類似ベクトル検索を行う例を以下に示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "size": 10, "_source": {"includes": ["DESC"]}, "query": { "script_score": { "query": { "terms": { "DESC": ["hoge"] } }, "script": { "source": "knn_score", "lang": "knn", "params": { "field": "VECTOR", "vector": [0.1, 0.2, ...], "space_type": "cosinesimil" } } } } } |
painless scriptを用いてクエリを書く場合と比べるとhackyに見えますが、やっていることとしては、事前に定義されているコサイン類似度の関数を内部的に呼び出し、類似度を計算しているのみです。
単純なコサイン類似度だけでなく、複数の類似度関数やBM25などのスコアを利用したり、それらに重み付けをしたりして複雑なクエリを書きたい場合があるかもしれません。
このような時、Elasticsearchではfunction scoreを用い、複数のクエリを組み合わせてスコアリングをすることができます。
例として、コサイン類似度とユークリッド距離の二つを用いてスコアリングを行うクエリ例を以下に示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
{ "size": 10, "query": { "function_score": { "score_mode": "sum", "boost_mode": "sum", "min_score": 1, "query":{ "bool": { "must": [ { "match": {"DESC": "hoge" } } ] } }, "functions": [ { "script_score": { "script": { "source": "knn_score", "lang": "knn", "params": { "field": "VECTOR", "vector": [0.1, 0.2, ...], "space_type": "cosinesimil" } } }, "weight": 3 }, { "script_score": { "script": { "source": "knn_score", "lang": "knn", "params": { "field": "VECTOR", "vector": [0.3, 0.5, ...], "space_type": "l2" } } }, "weight": 5 } ] } } } |
いままで見てきたクエリはexact k-NNによるもの、つまり、正確に類似度計算を行うものです。
ただ、全てのベクトルに対して愚直に類似度計算を行うと、データ数xベクトルの次元数の計算コストがかかり、非常に高価な計算になってしまいます。
幸い、Open Distro for Elasticsearchでは近似k-NNを用いた類似ベクトル検索によって、大規模データにも対応することができます。
近似k-NNによる類似ベクトル検索のクエリ例は以下のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "size": 10, "query": { "knn": { "VECTOR": { "k": 10, "vector": [0.1, 0.2, ...] } } } } |
このクエリによって、インデックス内の全データに対して類似するベクトルを近似的に計算して得ることができます。
近似k-NNでは事前に計算する件数を絞ってから類似度計算を行うということができないので、もし検索結果に条件付けを行いたい場合は、以下のようにpost_filter句を利用して、データを取得してからそれをフィルタリングするという流れになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
{ "size": 10, "query": { "knn": { "VECTOR": { "vector": [0.1, 0.2, ...], "k": 10 } } }, "post_filter": { "range": { "price": { "gte": 5, "lte": 10 } } } } |
以上までで、Amazon Elasticsearch Serviceに移行した際の、類似ベクトル検索のクエリ例を見てきました。
次は、実際にこれらのクエリを用いた場合にどれくらいの性能が出るかを見ていきます。
本番環境投入に向けた負荷試験と将来を見据えたコストパフォーマンスの調査
実験設定
負荷試験は、実際にプロダクションで用いられているクエリを使用することが望ましいですが、今回は利用できるクエリログが存在しなかったため、本番環境を想定した疑似データを作成して行うことになりました。
今後、Qass APIではベクトル検索を用いたAPIの提供に力を入れていくことを考えているため、今回行った試験では類似ベクトル検索のパフォーマンスを評価しました。
実験のための疑似データは、以下の設定で作成しました。
– データサイズは100万
– データを1000分割するクラスを付与(例: クラス0に属するデータは1000件)
– 512次元のベクトルをデータとして持つ
– ベクトルは-1から1の範囲で一様乱数により生成
ベクトルを乱数で生成しているので、Elasticsearchのキャッシュの効果が小さいようなクエリが投げられることになります。
Amazon Elasticsearch Serviceのドメイン(Elasticsearchクラスタのこと)は、以下の設定で作成しました。
– Master nodes
– r5.large x 3
– Data nodes
– r5.xlarge x 3
– EBS: General Purpose SSD, 45GiB
knn vector field typeのためにある程度メモリが必要になるため、Data nodesのインスタンスタイプはAmazon Elasticsearch Serviceのデフォルトのr5.largeではなく、4 vCPU、メモリ 32GiBのr5.xlargeを使用しました。
1ヶ月このインスタンスを用いた場合の料金は以下の通りです。
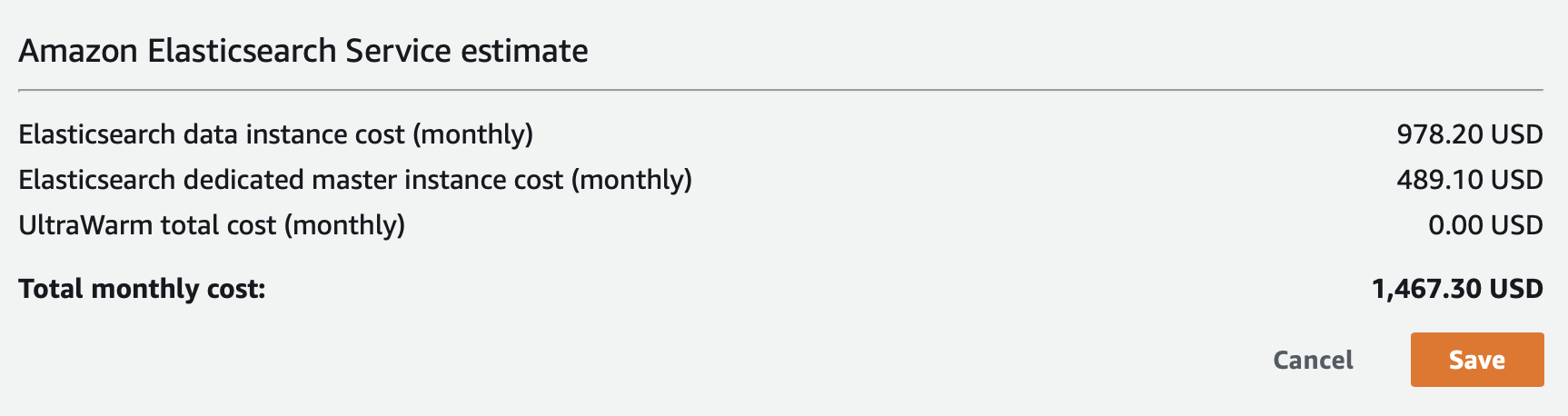
料金計算はAWS Pricing Calculatorを用いて行っています。
疑似データはPythonのスクリプトを書いて生成し、用意しておいたAmazon Elasticsearch Serviceのドメインに、Bulk APIを用いて投入しました。
データサイズは10GB程度で(一度にBulk APIでインデクシングできるデータサイズには限りがあるので)、データを1000分割して保存したファイルを、順に登録していきました。
適宜sleepを挟みつつこの処理を行い、4時間ほどかかってデータの投入が完了しました。
データ投入の際に用いたmapping(Elasticsearch内部の型の指定)は以下の通りです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
{ "settings": { "index": { "number_of_shards": 1, "number_of_replicas": 2, "knn": true, "knn.algo_param.ef_construction": 512, "knn.algo_param.m": 16, "knn.space_type": "cosinesimil" } }, "mappings": { "properties": { "large_label": { "type": "keyword" }, "middle_label": { "type": "keyword" }, "small_label": { "type": "keyword" }, "label": { "type": "text" }, "vector_512": { "type": "knn_vector", "dimension": 512 } } } } |
shard数は1つで、レプリカを2つ用意しています。
その後force merge APIを呼び出して、segmentファイルのマージを行いました。これには3時間ほどかかりました。
負荷試験の実施方法
負荷試験のために、Pythonで負荷試験を手軽に行うことのできるLocustというツールを利用しました。
Locustでは、シナリオファイルという負荷試験で行うべき処理をPythonで記述でき、かつmaster/worker構成を簡単に整えることができます。
今回はdocker imageとしてmaster/workerのimageを用意し、AWS Fargateで各コンテナを立ち上げることで、負荷試験を行いました。
タスク定義としては、以下のスペックで行いました。
- master用タスク定義
- タスクメモリ: 10GB
- vCPU: 2
- worker用タスク定義
- タスクメモリ: 8GB
- vCPU: 1
この設定だと、かけられる負荷は1 workerインスタンスあたり大体30 RPS(Request Per Second)程度だったので、大きな負荷をかける際は適宜worker側のインスタンスを増やして行いました。
負荷試験の流れとしては、以下の通りです。
- Amazon Elasticsearch Serviceのドメイン(クラスタ)を作成
- 疑似データ作成 / 投入
- Locust用のDocker imageをECRに登録
- Fargateからmaster/workerコンテナを立ち上げ
- 所望のクエリ/負荷で試験開始
負荷試験に用いるクエリとしては、正確なk-NNと、近似k-NNの二種類のクエリを用いました。
それぞれ、Pythonでクエリを組み立てて、locustを通してAmazon Elasticsearch Serviceに投げています。
クエリとして投げられるベクトルは、データ作成時と同様に一様乱数から生成しています。
実際のコードは以下の通りです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
class ESSLoadTestQueryFactory: @staticmethod def approximate_knn(dim: int, k: Optional[int] = None): if k is None: k = 50 return { "size": 50, "_source": ["large_label", "middle_label", "small_label", "label"], "query": { "knn": { f"vector_{dim}": { "k": k, "vector": [random.random() * 2 - 1.0 for _ in range(dim)] } } } } @staticmethod def pre_filter_knn( label_name: str, label: int, dim: int, distance_space: str ): return { "size": 50, "_source": ["large_label", "middle_label", "small_label", "label"], "query": { "script_score": { "query": { "term": { label_name: f"{label}", } }, "script": { "lang": "knn", "source": "knn_score", "params": { "field": f"vector_{dim}", "space_type": distance_space, "vector": [random.random() * 2 - 1.0 for _ in range(dim)] } } } } } |
100万データを均等に分割するクラスを各データに割り当てており、それによって類似ベクトル検索を行う件数を調整できるのがポイントです。
それぞれデータをlargeクラスは10分割、middleクラスは100分割、smallクラスは1000分割します。
そして、term句によって該当するクラスを絞ることで、類似ベクトル計算を行うべき件数をプログラム的に記述することができます。
また、コマンドラインからどのように分割を行うかを指定することで、docker imageに手を加えることなく、Fargateのコンソールから負荷試験を行う対象を選択することができるようになります。
今回のアルバイト期間では時間が足りず、smallクラス(1000件に対して類似ベクトル検索を行う)に対する評価しかできませんでしたが、より大規模なデータに対する検証も行えるように設計していました。
負荷試験の結果
まず、exact k-NNについて負荷試験を行った時の、Locustによる可視化結果をお見せします。
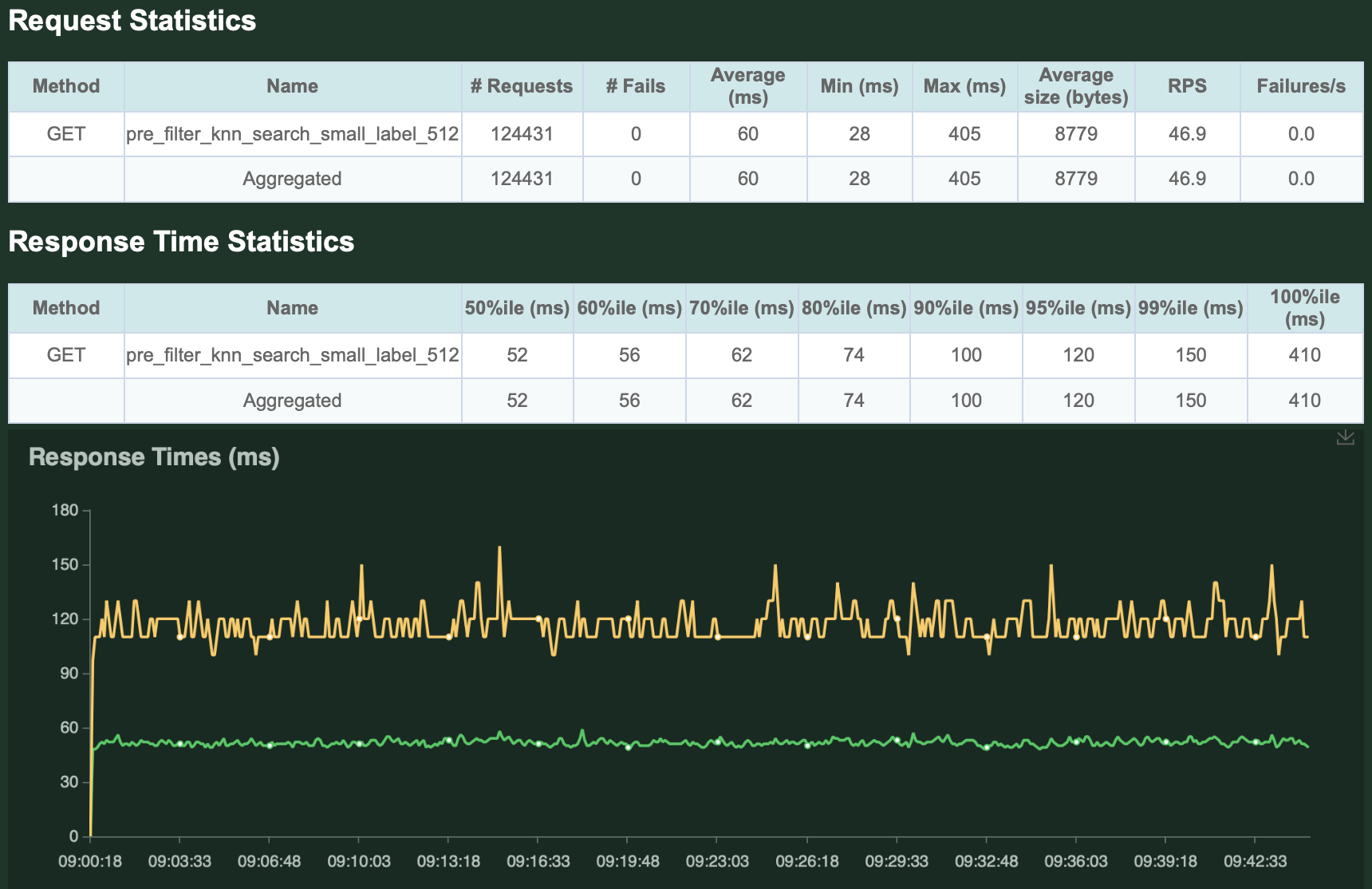
負荷は50 QPSで30分間行い、レスポンスに含まれるデータの件数は50件、対象はsmallクラス(類似度計算を1000件に対して行う)です。
ご覧の通り、50 QPS程度ならかなり早く捌けていることがわかるかと思います。
今回使用しているインスタンスであれば、この程度の負荷は余裕そうです。
次に、今回の試験では性能が頭打ちとなった 150 QPSでの負荷試験による結果を以下に示します。
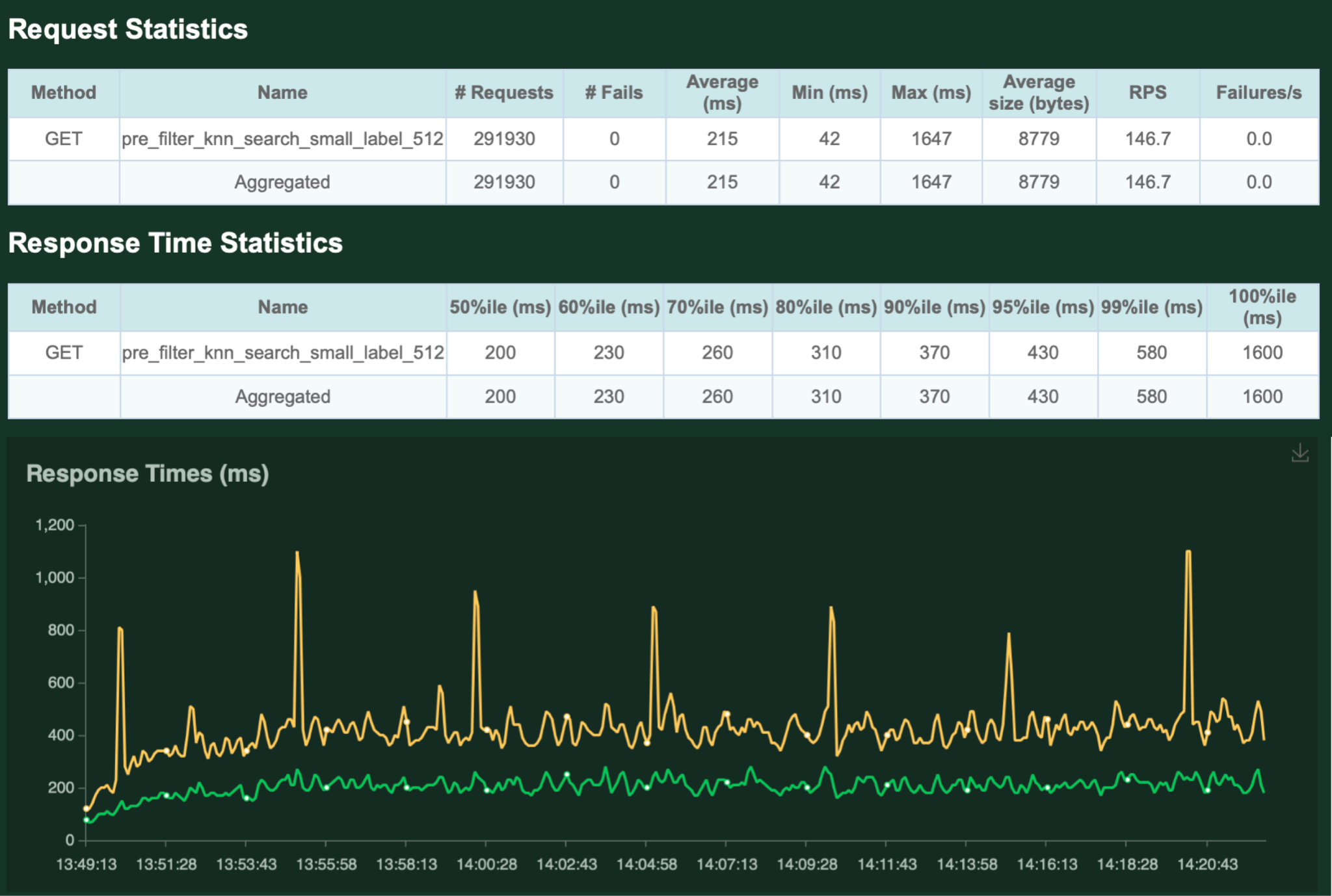
試験の結果、平均して215ms、99%ileで580msと、遅くはないという結果になりました。一方で、ところどころにレスポンスタイムのスパイクが見られます。
最も遅いレスポンスには1600msかかっているので、サービスの安定性を保つためには、ノード数を増やしたり、インスタンスタイプを上げるという選択が必要になるでしょう。
長期間にわたって稼働しても問題ないかを検証するため、100 QPSで6時間稼働し続けた際の結果を以下に示します。
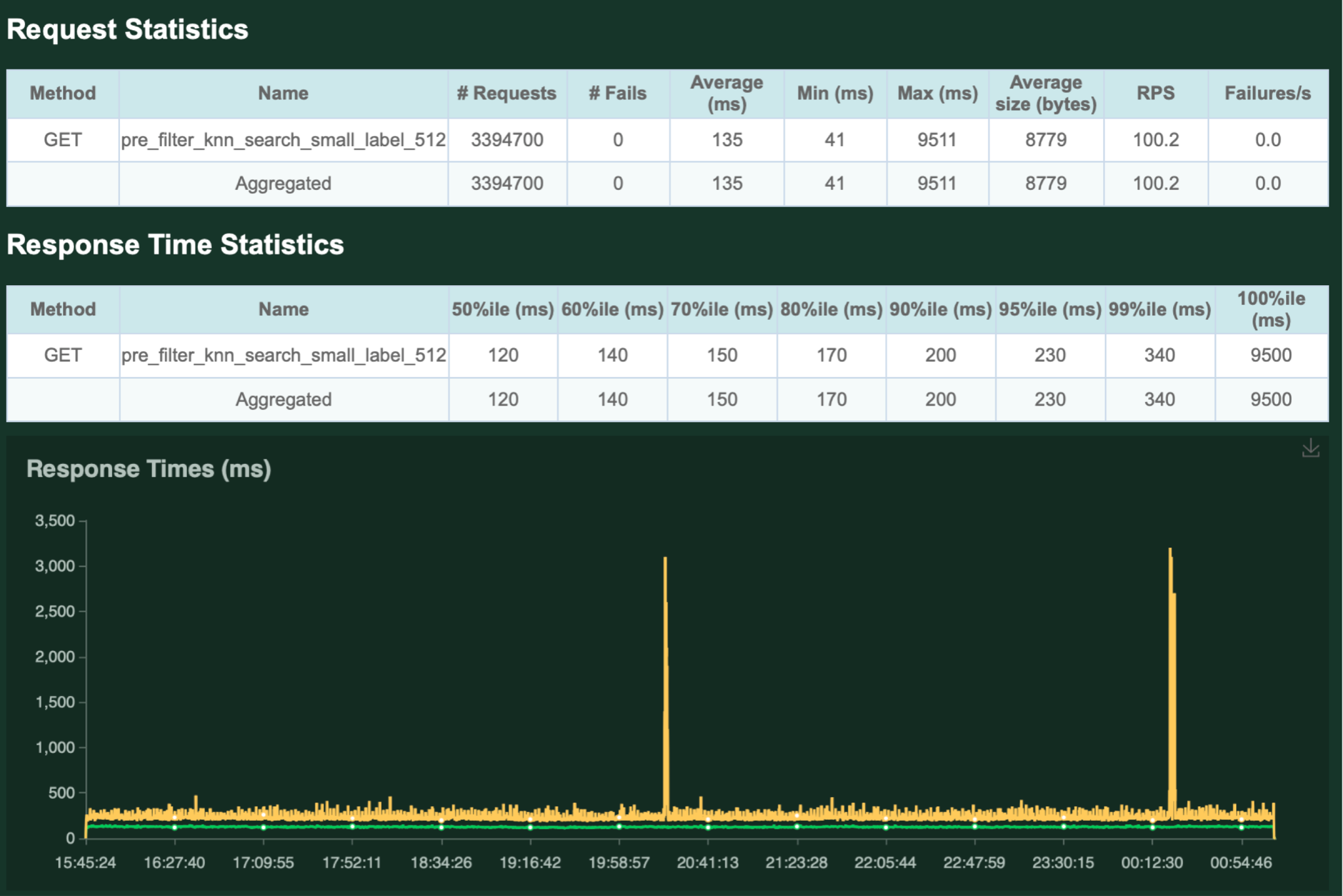
ヒートランの結果、稀ですが非常に大きなスパイクが観測されることがわかりました。
平均135ms、99%ileで340msと、全体の結果としては良好ですが、本番投入を考える上では気になる現象です。
残念ながら今回のアルバイト期間中にこの原因調査までは行うことができませんでしたが、チームの方に調査を引き継いでいます。
次に、近似k-NNを用いた負荷試験を行いました。
まず、50 QPSで30分間負荷試験を行った結果を以下に示します。
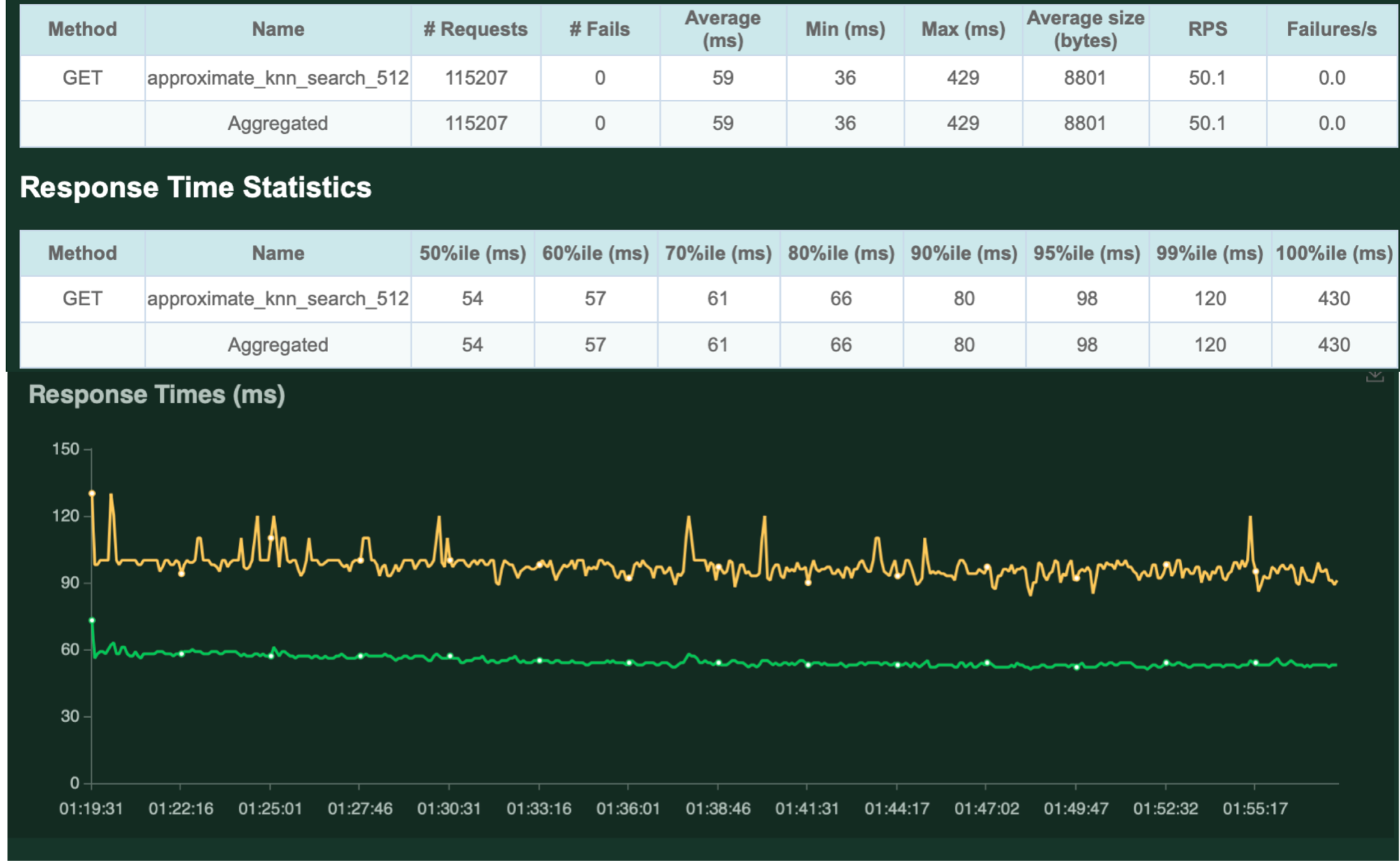
近似k-NN検索では、対象となるデータの件数は100万件と非常に大規模ですが、十分高速に結果を返せていることがわかります。
また、レスポンスも十分安定していることがわかります。
次に、今回の試験で性能が頭打ちとなった 200 QPSでの負荷試験の結果を以下に示します。
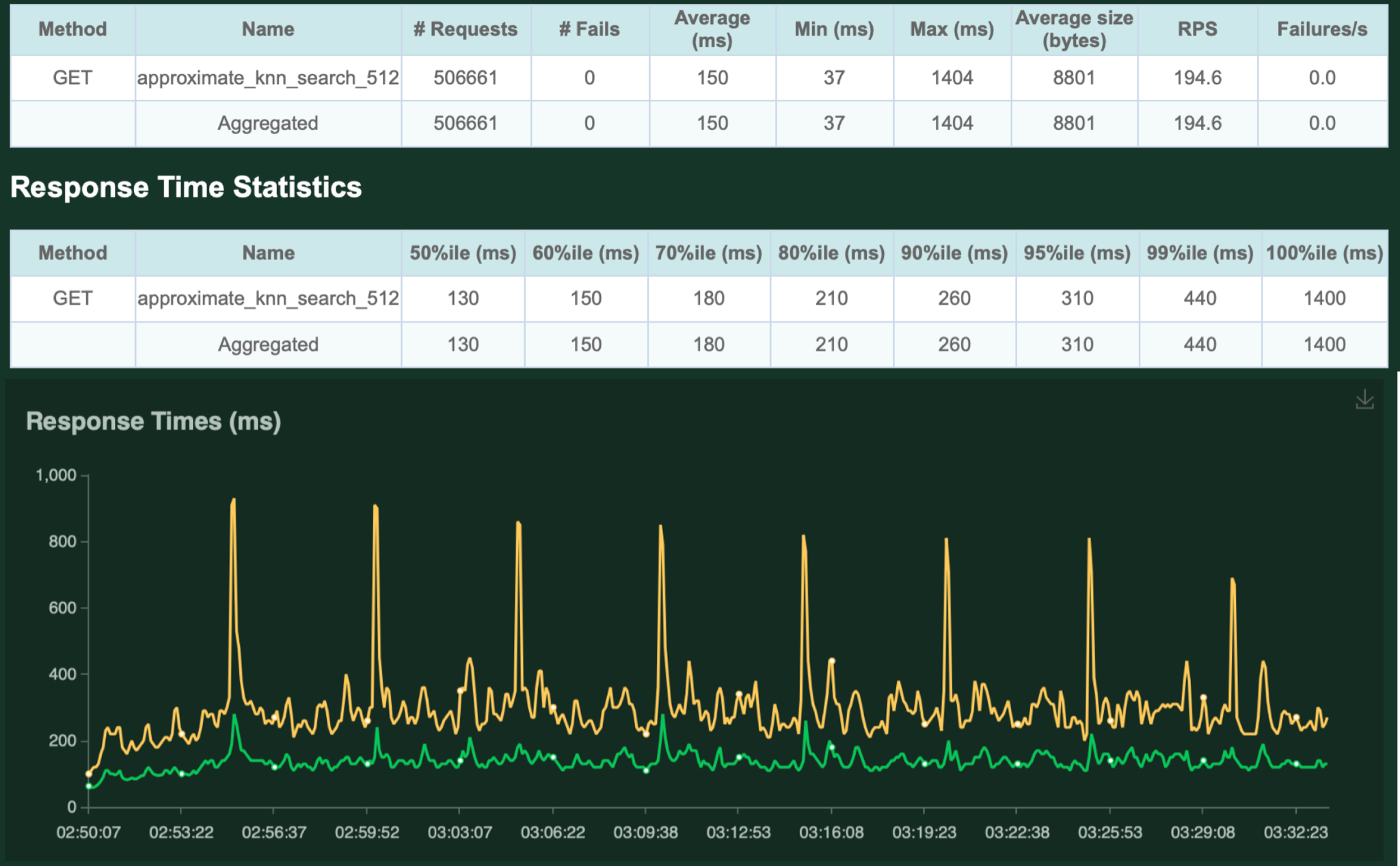
exact k-NNの時と同様、スパイクが生じていますが、平均150ms、99%ileで 440msという結果になりました。
さらに、200 QPSで7時間負荷試験を行った際の結果は以下の通りです。
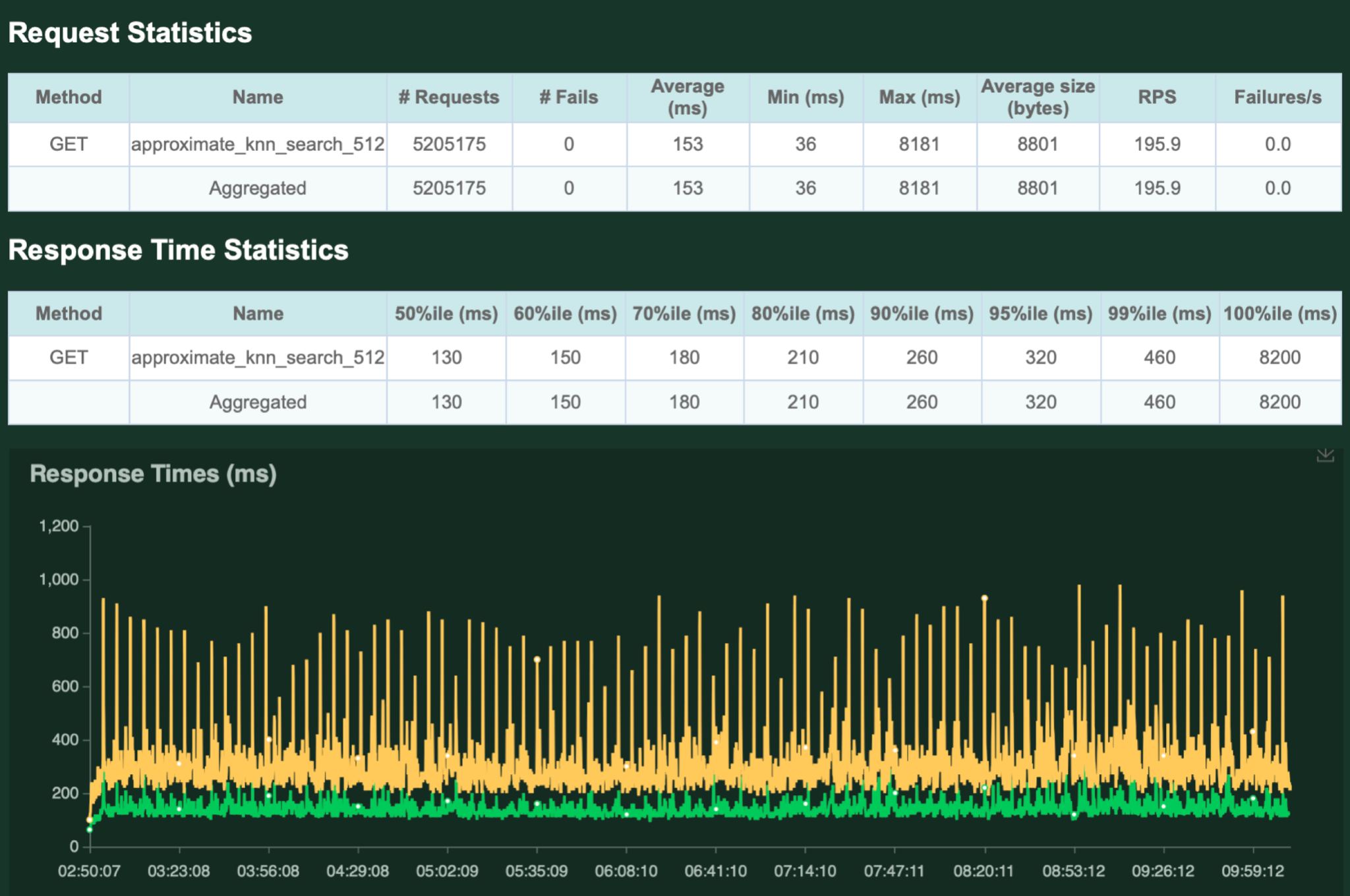
exact k-NNの時と同様定期的なスパイクが見られ、最大レスポンスタイムが非常に悪化しているタイミングがあることがわかります。
全てのレスポンスを安定して高速に返したい場合、水平/垂直スケーリングを行う必要がありそうです。
負荷試験のまとめとしては、以下の通りです。
– 現在のシステムで必要なQPSは十分対応可能
– あとはどれだけコストを抑えるか
– 近似KNNによって大規模なデータも捌けるので、適用範囲を広げられる
– キャッシュが効けばもっと楽になりそう
– 稀にレスポンスタイムのスパイクが見られる
– Amazon Elasticsearch Service側の問題と見られるが、調査しきれず
まとめ
今回のアルバイトでは、Elasticsearchへの移行に伴う差異の調査と、実際に移行した場合を想定した負荷試験を行いました。
実際に大規模なアクセスを捌く信頼性の高いシステムを作る上で、性能に関する調査は欠かせません。
約1ヶ月のアルバイトという短い期間でしたが、今後のサービスの根幹に関わる部分についてチームに貢献することができ、非常に有意義な体験になりました。
実際にサービスを支えている基盤のために、何ができるかを考えながら業務に取り組むことができたと思います。
また、検索システムを扱うエンジニアの方と間近でお話ししたことで、将来のキャリアについて可能性と解像度をあげることができました。
調査や開発、負荷試験の準備を進めていく上で、チームの方とは非常に密な対話を行うことができました。
個人開発では、サービスの信頼性・将来性や、使用する技術の発展可能性を考える機会が多いとは言えないので、非常に貴重な経験になりました。
総じて、とても楽しんで業務に取り組むことができました。
技術的にも精神的にもお世話になったチームの皆さん、配属先や労働環境などご深慮いただいた人事の方々、本当にありがとうございました!!