目次
検索体験を向上する Query Understanding とは
本記事は Recruit Engineers Advent Calendar 2019 – Adventar 25日目(最終日!)の記事です.
はじめまして.リクルートテクノロジーズの河野 晋策です.
私は,Qassチームというリクルート横断の検索改善を行うチームにて検索改善を行っています.
Qassチームは,検索基盤の運用や検索改善を行っているチームです.
詳しくは以下の記事をご覧ください.
- 「いい検索」を考える
- 検索組織の機械学習実行基盤
- リクルート全社検索基盤のアーキテクチャ、採用技術、開発体制はどうなっているのか
- Elasticsearch+Hadoopベースの大規模検索基盤大解剖
- Argoによる機械学習実行基盤の構築・運用からみえてきたこと (CNDT2019, OSDT2019)
本記事の想定読者:検索初学者の方,検索機能を使っているユーザの回遊率やCV率を向上したいが,何からすればいいかわからない方.
本記事の概要:Query Understandingとは何か,Query Understandingのコンポーネント概要説明,Query Understandingが検索改善にどのように貢献するか.
 |
|---|
|
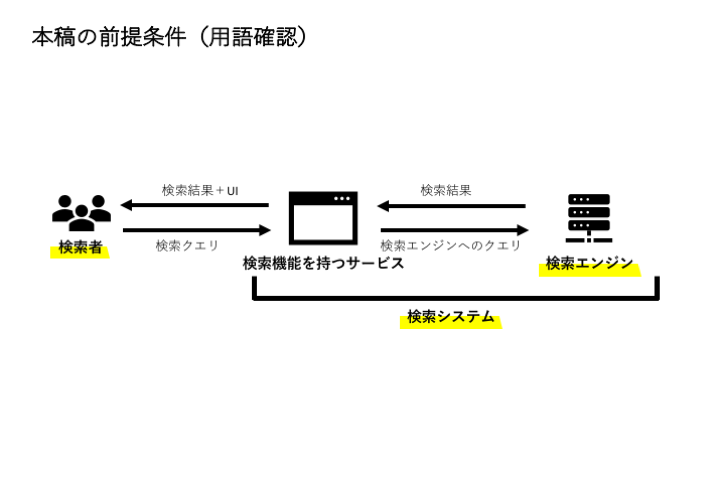
本稿の前提条件
|
本稿の目次は以下の通りです.
はじめに
近年,日本の各企業の検索事情が学会やwebに公開されるようになってきました.1
そのような情報の中には, 検索結果のランキングをどうする や 検索負荷どうする といった話が多いように思います.
これらは検索において非常に重要な分野です.
一方で,機能としての検索には,Query Understanding2という大事な分野があります.
残念ながら,この分野に関して日本語でまとまっているリソースはほぼないと言える状況です.
本稿では,検索分野において,検索者の検索体験を向上するQuery Understandingについて概要を共有し,検索改善のお手伝いができれば幸いです.
Query Understanding を語るにあたって,まずHCIR3という分野について説明する必要があります.
HCIRは,Gary Marchionini氏4によって定義されました.
Human-computer information retrieval (HCIR) is the study and engineering of information retrieval techniques that bring human intelligence into the search process. It combines the fields of human-computer interaction (HCI) and information retrieval (IR) and creates systems that improve search by taking into account the human context, or through a multi-step search process that provides the opportunity for human feedback.
上記定義によると,HCIRから考える検索は,単に Recall・Precision や NGCD
などの指標を追い求めるというものではなく,「検索の中にどのように人間が介在するのか」というHCIの文脈を取り入れた,言わば「検索者と検索システムとの対話」をモデリングしたものとなります.
この定義により,「検索者が,検索システムとの繰り返しの対話(multi-step search)の過程で学習し,検索クエリが変化していく過程」も検索の一部であると考えることができます.
ここからは,HCIRに沿って「検索」を理解するために,検索者観点と検索システム観点に分けて「検索」について説明していきます.
“検索者観点” の検索
検索者観点での検索は,以下の二面で説明できます.
- 何かを見つけたいという欲求(検索の目的)
- 1を満たすためのプロセス(どう検索するか)
それに従って検索の種類を分類すると,大きく2つに分けることができます.
- Known-Item Search
- 状況:自分の探しているアイテムを知っている
- 目的:自分の探しているアイテムにたどり着くこと
- 例:特定のドキュメント・人物の検索など
- Exploratory Search
- 状況:検索者が1つ以上の基準を持っている.検索者がゴールがわかっていない,ゴールにたどり着く方法がわかっていない.
- 目的:持っている基準を満たす(かつ,現状明らかになっていない追加基準を満たす)アイテムにたどり着くこと,ゴールを知ること,ゴールにたどり着く方法を知ること
- 例:特定のタイプの製品・特定の属性を持つ人の検索など
 |
|---|
|
検索例
|
Known-Item Search5では,検索者は自分の探しているアイテムを知っているので,目的のアイテムの名前,またはタイトルを検索する傾向にあります.6
こうした場合,Autocomplete や Spelling Correction といったコンポーネントは検索者が手間を掛けずに,誤字脱字無しで長いタイトル・名前を入力することができるため,検索者を助ける手段となるでしょう.
また,Known-Item Searchでは,間接的な検索が行われることがあります.(例えば,「北村吉弘」と検索するのではなく,「リクルート 社長」と検索するなど)
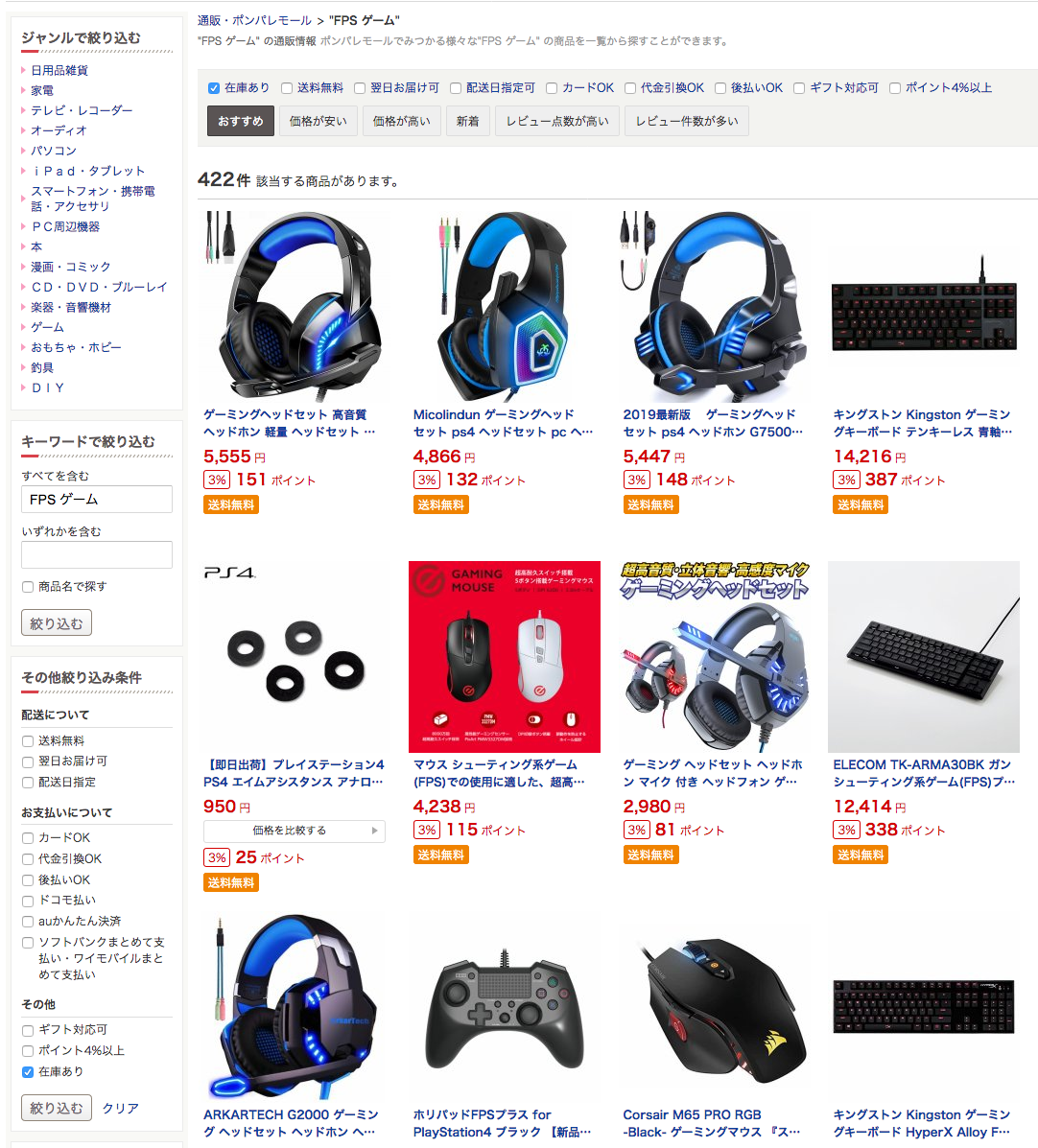
この場合,さらに検索結果を絞り込むことができるコンポーネント,「Faceted Search」や「Related Search Suggestions」を提供することで,検索者を助けることができるでしょう.
またExploratory Search7では,検索者は繰り返しの検索の過程で,当初持っていた条件を満たすアイテムの領域を学習し,その理解に基づいて条件をさらに増やす,あるいは変更します.
例えば,
- 1回目の検索:「FPSのいいゲームないかな」 → 「〇〇というゲームが良さそう」
- 2回目の検索: 「〇〇というゲームは,どのゲーム機でソフトがあるんだろう」 → 「このゲーム機なら持ってる」
- 3回目の検索: 「このゲーム機で,〇〇というソフトの最安はいくらだろう」
- 以降省略
こうした場合はAutocompleteを用い,検索者が何を検索していいかわかっていないときに検索クエリに新たな側面を与えることで,支援することができます.
前述の「Autocomplete」や「Spelling Correction」,「Related Search Suggestions」は,Query Understandingにおける重要なコンポーネントの一部です.
このように, Query Understanding は検索者と検索システムの対話を支援する考え方なのです.
 |
 |
|---|---|
| ホットペッパーグルメのAutocomplete | ポンパレモールのFaceted Search |
“検索システム観点” の検索
一方,検索システムには3つの責務があります.
- 検索者の意図しているものを把握する
- その意図に関連している結果を返す
- 検索者がクエリを明確化・再構築する機会を提供する
検索者の意図しているものを把握するというタスクは,Query Understandingの考え方そのものです.
また,理解した検索者の”意図”を検索エンジンが理解できるクエリとして発行するところまで含め,Query Understandingの責務です.
そのクエリに応じて,意図に関連している結果を返すのは検索エンジンの責務です.
(その中に検索結果のランキングの話がありますが,ランキングの話は本稿では触れません.)
検索システムはこれらの責務を果たすことで,検索者が「ゴールへたどり着く」,「ゴールへたどり着く方法を理解する」,「たどり着くべきゴールを明確化する」ことを支援します.
加えてここで重要なのが,検索者が検索を繰り返す過程でドメインや検索方法を学習することで上記の支援が成立するということです.
Query Understanding は,こうした一連の流れを経て繰り返しの検索の過程における検索者の意図を解釈することで,検索者と検索システムの対話を支援するのです.
Query Understanding
いよいよここからは,Query Understanding について説明していきます.
検索エンジンは検索クエリを入力として受け入れ,検索クエリとの関連性によってランク付けされた結果のリストを返すシステムです.
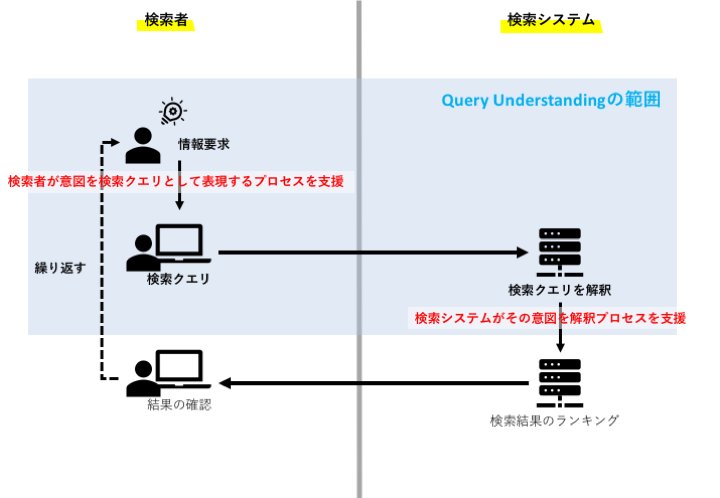
Query Understanding は,検索エンジンが結果をスコアづけしてランキングする前に起こることです.
つまり,検索者が意図を検索クエリとして表現するプロセス,および検索システムがその意図を解釈するプロセスです.
言い換えれば,Query Understanding は,検索者と検索エンジン間の通信チャネル,あるいはプロトコルです.
|
|---|
|
Query Understandingの範囲
|
Query Understanding を支援するコンポーネントには様々なものがありますが,大きく以下の二つに分けられます.
- 検索者が意図を検索クエリとして表現するプロセスを支援するコンポーネント群
- 検索システムが検索意図を解釈するプロセスを支援するコンポーネント群
上記を順に説明していきます.
1 検索者が意図を検索クエリとして表現するプロセスを支援するコンポーネント群
検索者が意図を検索クエリとして表現するプロセスを支援するコンポーネント群には,以下の3つのコンポーネントがあります.
- Autocomplete
- Spelling Correction
- Related Search Suggestions
この3つのコンポーネントは検索者の検索クエリ入力を支援します.
モバイルが主流となるサービスでは特に,検索クエリの作成と再構築をサポートし,検索者を無効な検索クエリ送信による遅延やフラストレーションから保護することが重要です.
1.1 Autocomplete
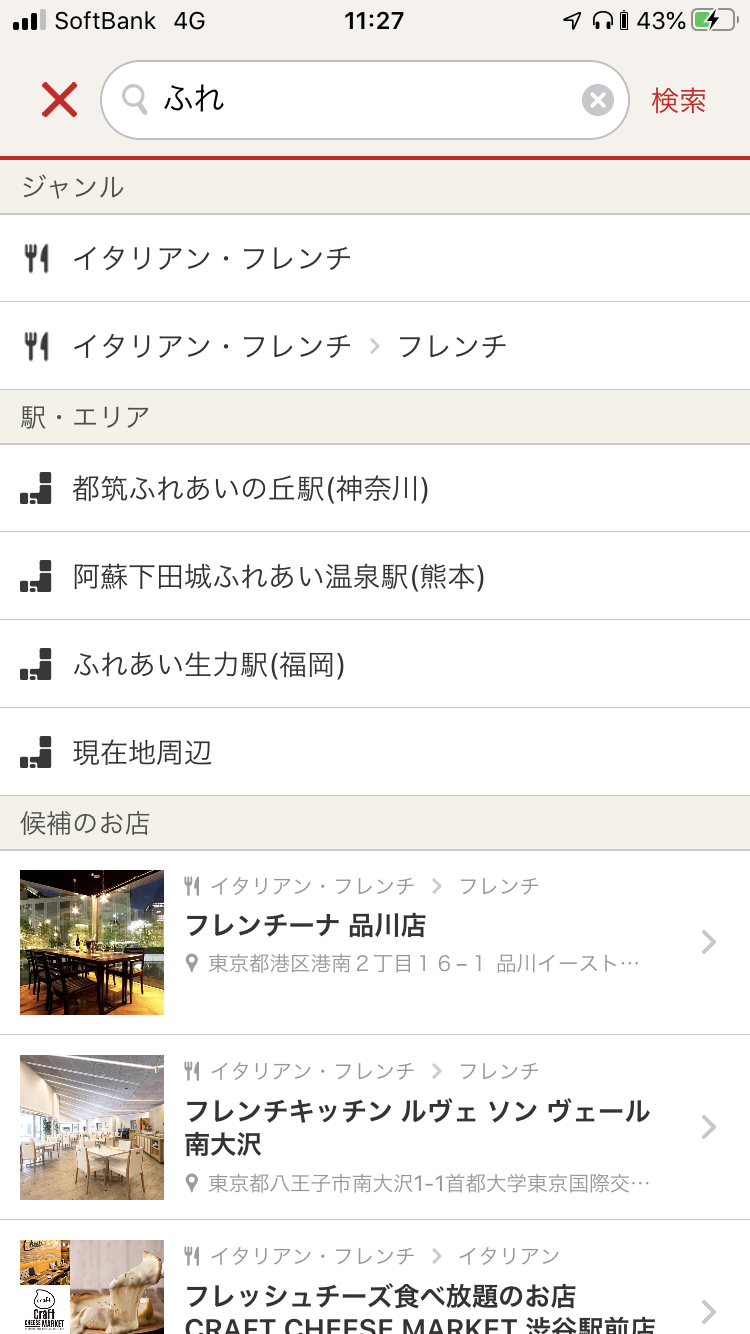
Autocomplete は,冒頭に記載したように検索者の入力のガイドを行います.
検索者の入力などに応じて,その入力がどう続くのか,どう続くべきなのかを予測し,提案します.
|
|---|
|
ホットペッパーグルメのAutocomplete
|
Autocomplete の実現方法はいくつかあります.
ルールベースではない単純な実現方法は,条件付き確率を用いることです.
まず,検索者の入力が検索クエリのプレフィックスであると考えます.
次に,例として検索者の入力が「ふれ」である場合を考えます.
検索ログを使用して,「ふれ」で始まるクエリでログ全体の割合を最も多く占める検索クエリをAutocompleteの候補とすることができます.
さらに高度なAutocompleteを行うには以下のようなことを考慮する必要があるでしょう.
- 検索クエリのパフォーマンス: その検索クエリがどれだけクリックなどのアクションに結びついたか
- ログの鮮度,季節性,時間依存など
- 検索者の情報: 場所,セッションコンテキストなど
- 入力がプレフィックスではなくトークン中間である場合: 「株式会社リクルートテクノロジーズ」に対して「テク」から入力するなど
- Typo: 後述の Spelling Correction と組み合わせる必要があるかもしれません
- Negative Sampleの除外: 同セッション内で選択しなかった(選択した)候補の除外
Autocompleteの機能は,検索者の入力のガイドだけではありません.
検索者が検索しようとしている分野に関してどんな検索クエリが有効か学習する重要な機会となります.
また,検索エンジンが自信を持って提供できるランキングへ検索者を導いてあげることもできます.
1.2 Spelling Correction
Spelling Correctionは検索者からの入力に対してスペルの修正を行います.
具体的にはすべての訂正候補(元の入力を含む)の中から,正しい可能性が最も高い訂正案を見つけます.
(例えば,検索者からの入力「ふれち」に対して「フレンチ」を提案するなど)
そのためには,2つのモデルが必要となります.
入力の事前確率を示す言語モデルと,入力が与えられた時のクエリ文字列の条件付き確率を示す誤差モデルです.
これら2つのモデルとベイズの定理8により,スペル修正候補をスコア付けし,それらの確率に基づいてランク付けすることができます.
これ以上の詳細は,本稿の概要説明の範疇をこえるので別の機会とします.
待ちきれない方は,Peter Norvig の How to Write a Spelling Corrector9を参照してください.
1.3 Related Search Suggestions
Related Search Suggestionsは,検索クエリに対して類似の検索クエリを提案します.
検索者が検索を通して学習した結果,違う検索クエリを入力したくなったと仮定します.
そうした時,関連する検索キーワードとして検索者に提案することができれば,検索者はその提案をクリックするだけで意図した検索を行うことができます.
 |
|---|
|
Google検索「リクルート」の関連キーワード
|
2 検索システムが検索意図を解釈するプロセスを支援するコンポーネント群
検索システムが検索意図を解釈するプロセスを支援するコンポーネント群は,3つのパートに分けられます.
- 検索者の高レイヤーの目的を判断する
- 検索クエリを構成要素に分割し,それぞれの意味を理解する
- 上記結果から検索エンジンへの問い合わせを構築する
ここからは,世界各地からECサイトを出店できるプラットフォームサービスを想定してください.
このサービスでは,各ECサイトが出品している商品 と 各ECサイト自体 を検索することができるとします.
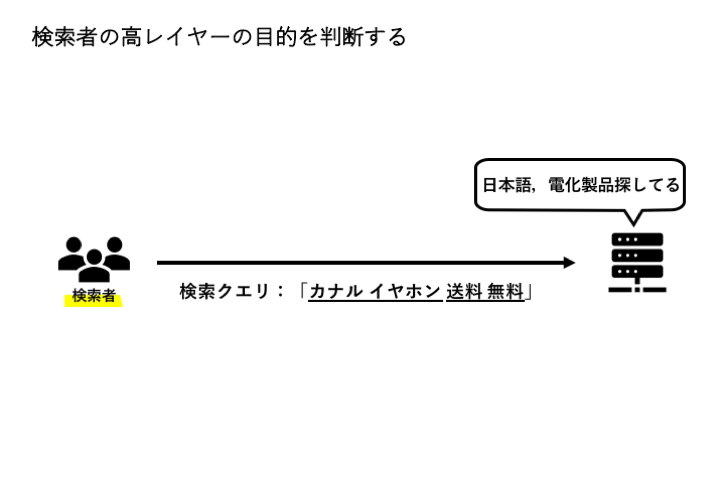
2.1 検索者の高レイヤーの目的を判断する
 |
|---|
|
検索者の高レイヤーの目的を判断する
|
検索者の高レイヤーの目的を判断する のゴールは,検索クエリを広く分類することです.(深くではない)
ここでは,3つのタスクが存在します.
- Language Identification
- Query Categorization
- 検索者の意図の確立
Language Identificationでは,検索者が使用している言語を識別します.
英語の場合は,単語レベルで文字が分かれていますが,日本語の場合は,単語が連結している場合があります.
言語を識別することは,多言語対応している検索アプリケーションにおいて,さらなるクエリ処理を行う上では重要となります.
「イヤホン」という検索クエリを考えてください.
ここに隠された検索者の意図は何でしょう?
仮に「送料無料のカナル型イヤホンを探している」検索者が上記の検索クエリを入力したとします.
Query Categorizationでは,分類の細分度合いに応じて,「イヤホン」というクエリを「電化製品」または,「オーディオ」というジャンルに分類します.
検索者の意図の確立では,「イヤホン」というクエリを「イヤホンを買いたいという意図」なのか,「イヤホンというECストアが知りたいという意図」なのか,はたまた,全く別の意図なのかを関連づけます.
一連のタスクは,明示的な検索者のフィードバック,または過去の検索行動(クリックに基づいてクエリをカテゴリにマッピングするなど)からモデリングすることができます.
モデリングは,ルールベースから初めて,次にembeddingを活用するのがいいでしょう.
検索クエリは通常短い文字列であるため,fastText10などからembeddingを始めてみてはいかがでしょうか.
検索者の高レイヤーの目的を判断する上では,検索クエリ全体を見ることで,検索クエリを深くではなく,広くすることを目的としました.
これは,後の検索クエリ処理の基礎となります.
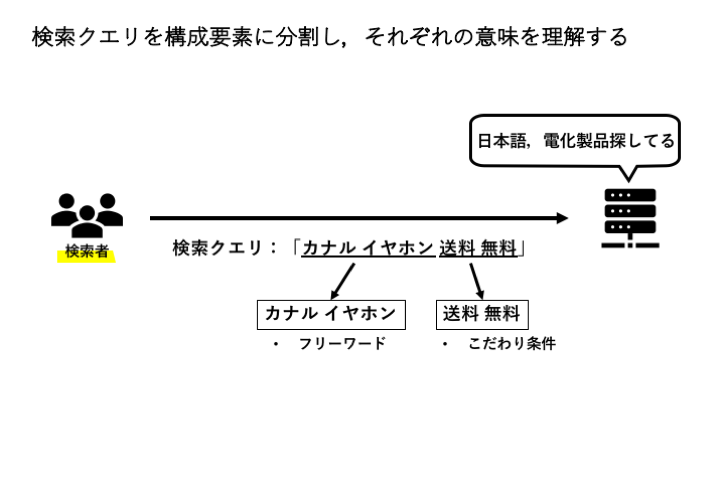
2.2 検索クエリを構成要素に分割し,それぞれの意味を理解する
 |
|---|
|
検索クエリを構成要素に分割し,それぞれの意味を理解する
|
ここでは,2つのタスクが存在します.
- Query Segmentation
- Entity Recognition
2.2.1 Query Segmentation
Query Segmentationでは,検索クエリを一連のセマンティック単位に分割します.
セマンティック単位は一つ以上のトークンで構成されています.
先ほどの「送料無料のカナル型イヤホンを探している」検索者について思い出してください.
この検索者は「カナル イヤホン 送料 無料」と検索クエリを構築するかもしれません.
私たちは,このクエリをみて「送料無料のカナル型イヤホンを探している」クエリだと予想することができます.
しかし,検索エンジンはそうではありません.
このクエリを検索エンジンに直接投げると「”カナル” AND “イヤホン” AND “送料” AND “無料”」というクエリになるでしょう.
するとどうでしょう,「”送料無料”のジュエリーを扱っている”イヤホン”というECサイト」が検索でヒットするかもしれません.
これは,検索エンジンが,所持しているアイテム中の「”カナル” と “イヤホン” と “送料” と “無料”」というトークンが入っているアイテム全てを返却するためです.
Query Segmentationは,「カナル イヤホン 送料 無料」というクエリを「”カナル イヤホン” AND “送料 無料”」というクエリに置き換えます.
これによって,”カナル イヤホン”という一つの繋がりで検索されるので,「”送料無料”のジュエリーを扱っている”イヤホン”というECサイト」が検索結果になる問題は発生しなくなるでしょう.
2.2.2 Entity Recognition
Entity Recognitionでは,Query Segmentationで特定されたセマンティック単位それぞれに対して,分類を行います.
先ほどの検索クエリのセグメント例について考えましょう.
Query Segmentationによるセグメントは「”カナル イヤホン” AND “送料 無料”」でした.
Entity Recognitionでは,この2つのセグメントに対して分類を行います.
前フェーズの検索者の高レイヤーの目的を判断するから得られたジャンル: 電化製品を利用して,分類例は以下のようになるかもしれません.
- ジャンル: 電化製品
- フリーワード: “カナル イヤホン”
- こだわり条件: “送料 無料”
これはあくまで例です.
ここで得られた分類を用いて,最後のパートである検索エンジンへの問い合わせを構築する段階において,その内容をより賢くすることができる可能性があります.
2.2.3 Query Segmentation と Entity Recognition のモデリング
これらのコンポーネントは,検索者の高レイヤーの目的を判断すると同様に明示的な検索者のフィードバック,または過去の検索行動(クリックに基づいてクエリをカテゴリにマッピングするなど)を用いてモデリングすることができます.
エンティティはカテゴリによって大きく異なるため,一つのモデルを構築する代わりに,検索者の高レイヤーの目的を判断するの検索者の意図の確立で用いたモデルを使って,モデルの集合を構築するモデリング戦略が有効かもしれません.
検索者の意図の確立で用いたモデルは,検索クエリに合った言語・エンティティのカテゴリを選択することを支援してくれます.
具体的なモデルとしては,Hidden Markov model(隠れマルコフモデル)(HMM)11 や Conditional random fields(条件付き確率場)(CRF)12,Bidirectional LSTM-CRF13 が有効かもしれません.
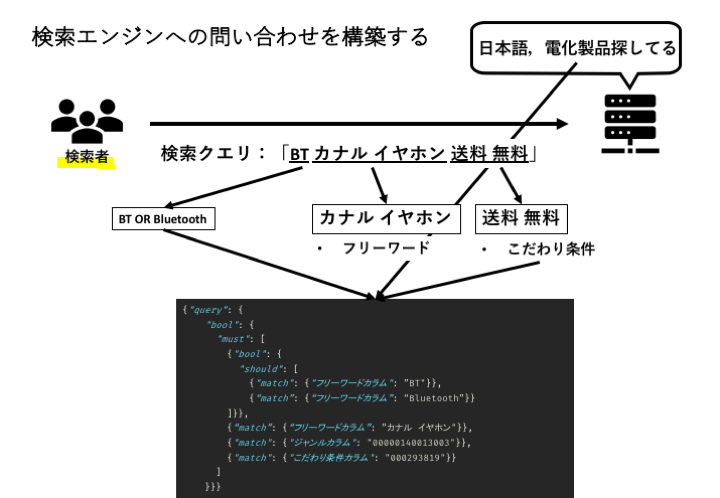
2.3 検索エンジンへの問い合わせを構築する
 |
|---|
|
検索エンジンへの問い合わせを構築する
|
検索エンジンへの問い合わせを構築するでは,ここまでの二つのフェーズの結果すべてを使用して検索エンジンへのクエリを組み立てます.
ここでは,3つのタスクがあります.
- Query Scoping
- Query Expantion と Query Relaxation
- 上記の結果を一つにまとめ,検索エンジンへのクエリを構築する
2.3.1 Query Scoping
Query Scopingでは,Entity Recognitionによって分類されたエンティティを検索エンジンへのクエリ要素にマッピングします.
ここでは,検索エンジンが持っているアイテムのマスターデータを使用することもあります.
Query Segmentationでの検索クエリ「カナル イヤホン 送料 無料」を思い出してください.
「”カナル イヤホン” AND “送料 無料”」とセグメントを分けることで「”送料無料”のジュエリーを扱っている”イヤホン”というECサイト」が検索結果に出てしまう問題はすでに解決されました.
しかし,今度は新たな問題が発覚しました.
「”カナル イヤホン”を過去取り扱っていたECサイト」が検索結果に出てしましました.
検索者の要求は「送料無料のカナル型イヤホンを探している」なので,この結果は惜しいかもしれませんが,厳密には違うでしょう.
ここで役に立つのが,Entity Recognitionの分類結果です.
Entity Recognitionでの分類結果を思い出してください.
- ジャンル: 電化製品
- フリーワード: “カナル イヤホン”
- こだわり条件: “送料 無料”
この時のシステムの与件条件は以下とします.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
- 検索エンジンのアイテムは,ジャンル,こだわり条件カラムをもつ - 検索エンジンのアイテムのジャンル,こだわり条件カラムは,マスターコード値が入っている - マスターコード値定義は以下 マスターコード = { "ジャンル": { "店": "00000140015445" "電化製品": "00000140013003", ... }, "こだわり条件": { "送料無料": "000293819", ... }, ... } |
この場合のQuery Scopingの結果は以下のようになります.
- フリーワード: “カナル イヤホン”
- ジャンル: 電化製品 : [“00000140013003” in “ジャンルカラム”]
- “送料 無料” : こだわり条件 : [“000293819” in “こだわり条件カラム”]
“ジャンル: 電化製品”は,検索エンジン内のアイテムが持つジャンルカラムに直接問い合わせされます.
“こだわり条件: 送料無料”は,検索エンジン内のアイテムが持つこだわり条件カラムに直接問い合わせされます.
これによって,”ジャンル: 電化製品”のアイテムのみを絞り込むことができるので「”カナル イヤホン”を過去取り扱っていたECサイト」が検索結果に出ることはもうありません.
Query Scopingが終わると,検索エンジンへのクエリを構築するフェーズで,Query Scopingの要素を組み合わせ,検索エンジンへのクエリを構築します.
例えば,上記の例では,以下のような検索エンジンへの(擬似)クエリが作成されます.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "query": { "bool": { "must": [ {"match": {"フリーワードカラム": "カナル イヤホン"}}, {"match": {"ジャンルカラム": "00000140013003"}}, {"match": {"こだわり条件カラム": "000293819"}} ] } } } |
この実現方法は,検索エンジンが持つアイテム定義やミドルウェアによって大きく変わってくるでしょう.
2.3.2 Query Expantion と Query Relaxation
2.3.2.1 Query Expantion
別のシチュエーションを想像してください.
検索を通して,検索者の要求は「Bluetoothのカナル型イヤホン」が欲しいというものに変化しました.
それに応じて検索者は検索クエリも変更しました.
新たな検索クエリは次のようなものです.
「BT カナル イヤホン 送料 無料」
見ての通り,検索者は “Bluetooth” を “BT” と省略して入力しました.
残念ながら検索エンジンが持っているアイテムの中には “Bluetooth” を “BT” と表記しているものはありません.
よって,このままでは,”送料無料のBluetoothのカナル型イヤホン”はアイテムとして存在しているのにも関わらず,検索者に「検索にヒットしたアイテムはありません.(ゼロ件ヒット)」と返すことになります.
ここで,解決策となるのがQuery Expantion14です.
Query Expantionでは,検索クエリにトークンやフレーズを追加します.
この例では,「”BT” AND “カナル イヤホン” AND “送料 無料”」を「(“BT” OR “Bluetooth”) AND “カナル イヤホン” AND “送料 無料”」とすることで ゼロ件ヒット を回避することができます.
Query Expantion は以下のようなパターンで有用です.
- 略語: 「Bluetooth と BT」
- 言い換え表現: 「(株)と 株式会社」
- 同義語:
- iPad※ -(抽象化)→ タブレット
- コンピュータ -(具体化)→ ラップトップ
- web -(厳密には違うけど一緒に扱いたい)→ インターネット
※ iPadは,米国およびその他の国で登録されたApple Inc.の商標です.
Query Expantion を実現するには,シソーラスや,検索アイテムから Word2Vec15 などを用いて得られるembeddingを利用するのが有効でしょう.
日本語シソーラスには Sudachi同義語辞書16 などがあります.
2.3.2.2 Query Relaxation
今度は,また別の検索クエリを想像してください.
検索者は次のような検索クエリを検索窓に入力しました.
「絶対に送料無料のカナル型イヤホン」
この検索クエリを検索エンジンにそのまま投げたところ,”絶対に送料無料のカナル型イヤホン” という文字列を含むアイテムが存在しないため,ゼロ件ヒットになってしまいました.
ここで,解決策となるのがQuery Relaxation1718です.
Query Relaxation では,検索クエリのトークンやフレーズを削除します.
もっとも単純な Query Relaxation はストップワード19を削除することです.
上記検索クエリからストップワードを削除した例は以下です.
「絶対 送料無料 カナル型イヤホン」
これでうまくいく場合もあるでしょう.
しかし,”絶対” というトークンはストップワードを削除したことで,繋がりが見えず浮いて見えます.
“絶対” を削除する Query Relaxation の戦略は トークンの specificity を用いることです.
トークンはspecificityがそれぞれ異なります.
これはどういうことかというと,「絶対 送料無料 カナル型イヤホン」という検索クエリにおいて,トークンの “具体性” をみるということです.
この検索クエリにおいて,”カナル型イヤホン”というトークンは,”絶対”トークンよりも具体的です.
同様に,”送料無料”というトークンは,”絶対”トークンよりも具体的です.
specificityはこのトークンの具体性を利用して,より抽象度の高いトークンを削除します.
具体性の測定は,Inverse Document Frequency (idf)20 や WordNet21 のようなレキシカルデータベースを用いて行うことができます.
Query Relaxation の他の戦略としては,検索クエリに対して,Syntactic AnalysisやSemantic Analysisを行うことが挙げられます.
Syntactic Analysisの例は,検索クエリの大部分は名詞句であるという特徴から,名詞を修飾するトークンを判別して,削除します.これには MeCab22 や GiNZA23 が有効でしょう.
Semantic Analysisの例は,相互に関連するトークンの意味を考慮します.
例えば,「オーディオ イヤホン カナル型」というクエリを考えます.
“オーディオ” とは”音楽を聴くための機器”なので24, “オーディオ” は “イヤホン” に暗示されています.
よって,「オーディオ イヤホン カナル型」は「イヤホン カナル型」に Query Relaxation することができます.
Word2Vec15 などで得られるembeddingを利用して,トークンが互いにどの程度重複しているかを認識できるかもしれません.
Query Understanding まとめ
以上,Query Understanding の概要説明でした.
Query Understanding コンポーネントの中には破壊的な変更を行うものもあります.
例えば, Query Relaxation が検索者が本当に必要だと思っているトークンを削除してしまったらどうでしょう.
誤字ではないのに Spelling Correction が勝手に検索クエリを変えてしまったらどうでしょう.
検索者はまともに検索できず,そのサービスを離れてしまうかもしれません.
これを回避するために,本来の検索クエリに戻る選択肢,あるいはQuery Understanding を行うことを許可するという選択肢を検索者に提供すべきです.
 |
|---|
|
「本来の検索クエリに戻る」Google検索の例
|
Query Understanding コンポーネント
ここまで出てきた,Query Understandingのコンポーネントを以下にまとめます.
|
コンポーネント名
|
概要
|
課題例
|
|---|---|---|
|
Language Identification
|
検索者の入力が何語であるか判別 | 使用言語によってはうまく検索ヒットしない |
|
Query Categorization (検索者の意図の確立含む)
|
検索者の入力の意図がなんなのか広く分類(探しているものはなんなのか,モノ・店,モノならジャンルは?など) | 検索結果が多すぎて検索者が絞り込むのに時間がかかる・絞り込めない,検索結果の適合率が低い |
|
Autocomplete
|
検索者の入力などに応じて,その入力がどう続くのか,どう続くべきなのかを予測し,提案 | 検索者の検索回数が多く,ゴールにたどり着くまで時間がかかっている |
|
Spelling Correction
|
検索者からの入力に対してスペルの修正 | 検索クエリの誤字脱字によるゼロ件ヒットが目立つ |
|
Query Expantion (検索クエリの変更)
|
検索クエリにトークンやフレーズを追加 | 略語や同義語によりゼロ件ヒットが発生している |
|
Query Relaxation (検索クエリの変更)
|
検索クエリのトークンやフレーズを削除 | 検索クエリが修飾語・ストップワードを含む,文章になっている |
|
Query Segmentation (検索クエリの変更)
|
検索クエリを一連のセマンティック単位に分割 | 検索結果が多すぎて検索者が絞り込むのに時間がかかる・絞り込めない,検索結果の適合率が低い |
|
Query Scoping (Entity Recognition含む) (検索クエリの変更)
|
Query Segmentationで特定されたセマンティック単位それぞれを分類,検索エンジンへのクエリ要素にマッピング | 同上 |
|
Related Search Suggestions
|
Query 検索クエリに対して類似の検索クエリを提案 | ゴールにたどり着くことなく検索をすぐにやめてしまう |
Query Understandingのコンポーネントの処理順序例は以下です.
(ここでは,Language Identification,Query Categorizationを省いています.)
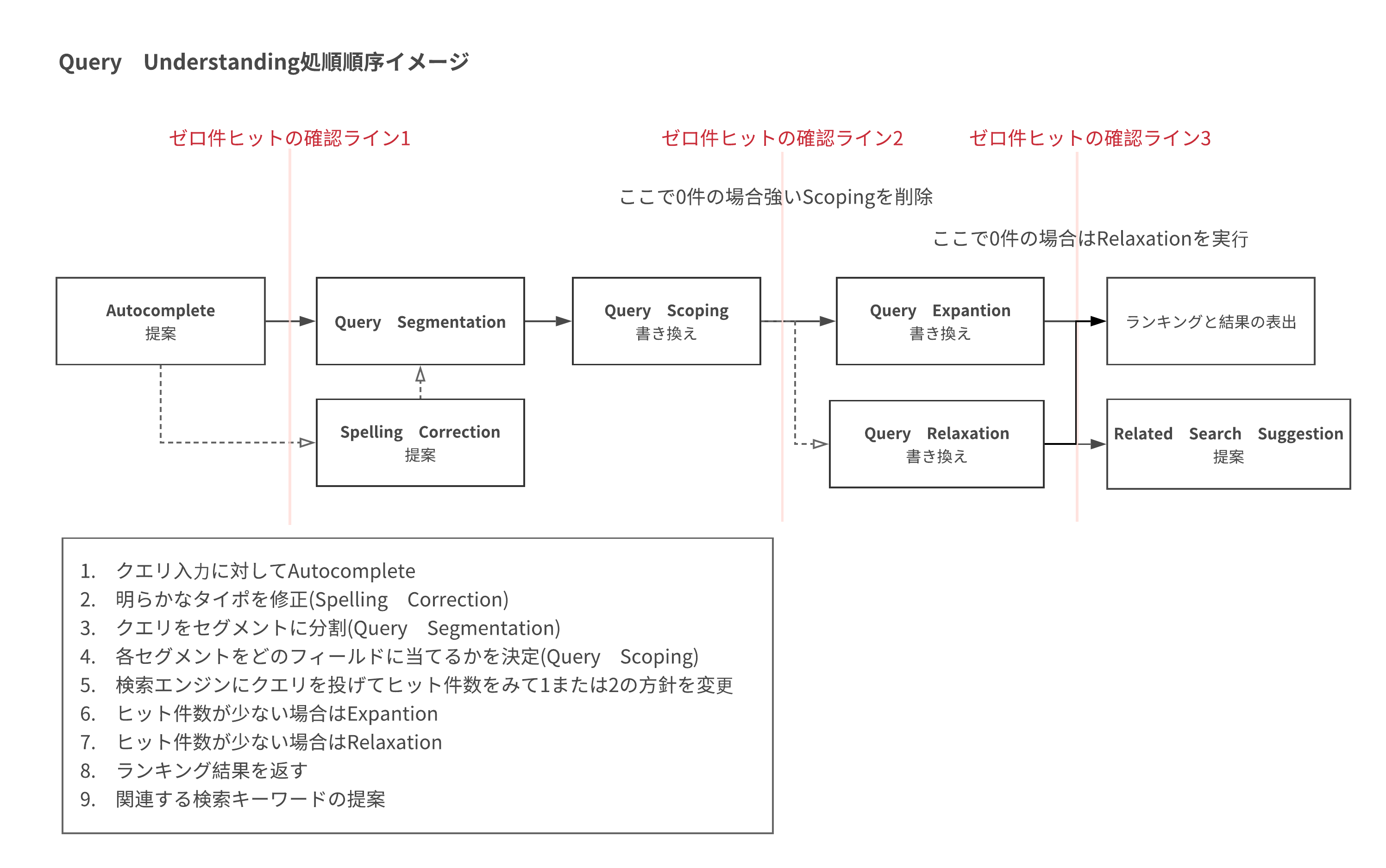 |
|---|
|
Query Understandingの処理順序例
|
Query Understanding コンポーネントの効果
例として,リクルートのビジネスモデルに当てはめ,Query Understandingの各コンポーネントが検索者や出稿クライアント・事業運営サイドにどのようなメリットがあるのか,図にまとめて考えてみました.
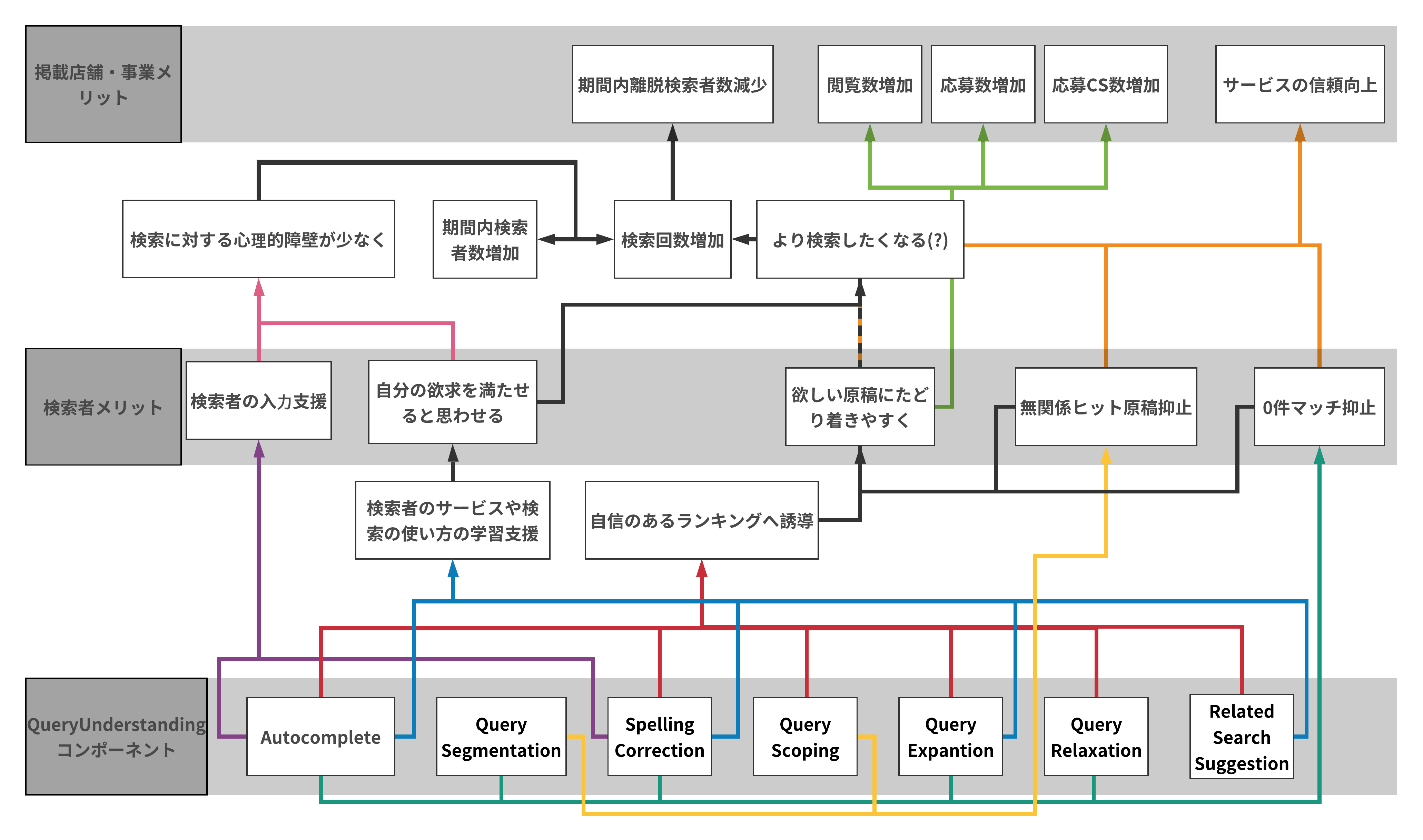 |
|---|
|
Query Understandingの効果
|
「他にもこんなメリットがあるのではないか」と考えつく方は,コメントいただけたら幸いです.
おわりに
ここまで読んでくださってありがとうございます.
サービスのアーキテクチャが複雑であればあるほど,関係者が多ければ多いほど,これらのコンポーネントの導入は,困難になるかもしれません.
Daniel Tunkelang氏25の言う通り,Query Understandingはそう容易いものではありません.
Like Rome, query understanding can’t be built in one day.
Daniel Tunkelang より
しかし,これらのコンポーネントの導入は検索者の検索体験を向上させることでしょう.
本稿が,あなたが関係するサービスの検索体験を改善するささやかなガイドになれば幸いです!
参考・引用
- 「いい検索」を考える: https://www.slideshare.net/shuryouchida/ss-133351464
- 検索組織の機械学習実行基盤: https://recruit-tech.co.jp/blog/2018/09/10/qass_ml/
- リクルート全社検索基盤のアーキテクチャ、採用技術、開発体制はどうなっているのか: http://www.atmarkit.co.jp/ait/articles/1507/08/news009.html
- Elasticsearch+Hadoopベースの大規模検索基盤大解剖: http://www.atmarkit.co.jp/ait/series/2047/
- Argoによる機械学習実行基盤の構築・運用からみえてきたこと (CNDT2019, OSDT2019): https://www.slideshare.net/ShinsakuKono/argo-156876353
- Query Understanding: A Manifesto: https://queryunderstanding.com/query-understanding-a-manifesto-367dc0be6745
- Query Understanding: An Introduction: https://queryunderstanding.com/introduction-c98740502103
- Language Identification: https://queryunderstanding.com/language-identification-c1d2a072eda
- Character Filtering: https://queryunderstanding.com/character-filtering-76ede1cf1a97
- Tokenization: https://queryunderstanding.com/tokenization-c8cdd6aef7ff
- Spelling Correction: https://queryunderstanding.com/spelling-correction-471f71b19880
- Stemming and Lemmatization: https://queryunderstanding.com/stemming-and-lemmatization-6c086742fe45
- Query Rewriting: An Overview: https://queryunderstanding.com/query-rewriting-an-overview-d7916eb94b83
- Query Expansion: https://queryunderstanding.com/query-expansion-2d68d47cf9c8
- Query Relaxation: https://queryunderstanding.com/query-relaxation-342bc37ad425
- Query Segmentation: https://queryunderstanding.com/query-segmentation-2cf860ade503
- Query Scoping: https://queryunderstanding.com/query-scoping-ed61b5ec8753
- Entity Recognition: https://queryunderstanding.com/entity-recognition-763cae840a20
- Taxonomies and Ontologies: https://queryunderstanding.com/taxonomies-and-ontologies-8e4812a79cb2
- Autocomplete: https://queryunderstanding.com/autocomplete-69ed81bba245
- Autocomplete and User Experience: https://queryunderstanding.com/autocomplete-and-user-experience-421df6ab3000
- Contextual Query Understanding: An Overview: https://queryunderstanding.com/contextual-query-understanding-65c78d792dd8
- Session Context: https://queryunderstanding.com/session-context-4af0a355c94a
- Location as Context: https://queryunderstanding.com/geographical-context-77ce4c773dc7
- Seasonality: https://queryunderstanding.com/seasonality-5eef79d8bf1c
- Personalization: https://queryunderstanding.com/personalization-3ed715e05ef
- Search as a Conversation: https://queryunderstanding.com/search-as-a-conversation-bafa7cd0c9a5
- Clarification Dialogues: https://queryunderstanding.com/clarification-dialogues-69420432f451
- Relevance Feedback: https://queryunderstanding.com/relevance-feedback-c6999529b92c
- Faceted Search: https://queryunderstanding.com/faceted-search-7d053cc4fada
- Activate 2018: Search in Practice: https://medium.com/@dtunkelang/activate-2018-search-in-practice-1bccc173c8d7
- Query Understanding, Divided into Three Parts: https://medium.com/@dtunkelang/query-understanding-divided-into-three-parts-d9cbc81a5d09
- Search: The Whole Story: https://medium.com/@dtunkelang/search-the-whole-story-599f5d9c20c
- Exclusive: Interview with Daniel Tunkelang, Head of Query Understanding at LinkedIn: https://www.kdnuggets.com/2014/03/exclusive-interview-daniel-tunkelang-head-query-understanding-linkedin.html
- Search Federation Architecture at LinkedIn: https://engineering.linkedin.com/blog/2018/03/search-federation-architecture-at-linkedin
- Query Understanding at LinkedIn [Talk at Facebook] : https://www.slideshare.net/abhimanyulad/query-understanding-at-linkedin-talk-at-facebook
- Better Search Through Query Understanding : https://www.slideshare.net/dtunkelang/better-search-through-query-understanding
- Search Quality at LinkedIn: https://www.slideshare.net/dtunkelang/search-quality-at-linkedin
- Google検索. https://www.google.com/
- Recruit Co.,Ltd. ホットペッパーグルメ アプリ. https://www.hotpepper.jp/app/
- Recruit Co.,Ltd. ポンパレモール. https://www.ponparemall.com/
- 検索技術勉強会: https://search-tech.connpass.com/ ↩
- W.Bruce Croft; Michaes Bendersky; Hang Li; Gu Xu. “Query Representation and Understanding Workshop”. 2010, SIGIR Workshop. http://sigir.hosting.acm.org/files/forum/2010D/sigirwksp/2010d_sigirforum_croft.pdf ↩
- HCIR: https://en.wikipedia.org/wiki/Human%E2%80%93computer_information_retrieval ↩
- Gary Marchionini: https://sils.unc.edu/people/faculty/profiles/Gary-Marchionini) ↩
- Wildemuth, Barbara; O’Neill, Ann. “The “Known” in Known-Item Searches: Empirical Support for User-Centered Design”. College & Research Libraries. 1995. ↩
- Lee, Jin Ha; Renear, Allen; Smith, Linda. “Known‐Item Search: Variations on a Concept.”, Proceedings of the American Society for Information Science and Technology. 2006. ↩
- Ryen W. White; Resa A. Roth. “Exploratory Search: Beyond the Query-Response Paradigm”. 2009, San Rafael, CA: Morgan and Claypool. ↩
- wikipedia. ベイズの定理. https://ja.wikipedia.org/wiki/%E3%83%99%E3%82%A4%E3%82%BA%E3%81%AE%E5%AE%9A%E7%90%86 ↩
- Peter Norvig. “How to Write a Spelling Corrector”. http://norvig.com/spell-correct.html ↩
- facebook research. fastText. https://github.com/facebookresearch/fastText/ ↩
- Baum, L. E.; Petrie, T. “Statistical Inference for Probabilistic Functions of Finite State Markov Chains”. The Annals of Mathematical Statistics. 1966. ↩
- Lafferty, J.; McCallum, A.; Pereira, F. “Conditional random fields: Probabilistic models for segmenting and labeling sequence data”. ICML. 2001, pp. 282–289. ↩
- Zhiheng Huang; Wei Xu; Kai Yu. “Bidirectional LSTM-CRF Models for Sequence Tagging”. CoRR. 2015. ↩
- Vectomova, Olga; Wang, Ying. “A study of the effect of term proximity on query expansion”. Journal of Information Science. 2006, 32 (4), pp. 324–333. ↩
- Mikolov, Tomas; et al. “Efficient Estimation of Word Representations in Vector Space”. 2013. ↩ ↩
- ワークス徳島人工知能NLP研究所. “Sudachi 同義語辞書”. https://github.com/WorksApplications/SudachiDict/blob/develop/docs/synonyms.md ↩
- Hurtado, C.A.; Poulovassilis, A.; Wood, P.T. “A Relaxed Approach to RDF Querying”. 2006. ISWC. LNCS, vol. 4273. ↩
- Hai Huang; Chengfei Liu. “Query Relaxation for Star Queries on RDF”. ISWC. LNCS, 2010, vol. 6488. ↩
- Rajaraman, A.; Ullman, J. D. “Data Mining”. Mining of Massive Datasets. 2011, pp. 1–17. http://i.stanford.edu/~ullman/mmds/ch1.pdf ↩
- Christopher D. Manning; Prabhakar Raghavan; Hinrich Schütze. “Introduction to Information Retrieval”. Cambridge University Press. 2008. ↩
- NICT. “日本語 WordNet”. http://compling.hss.ntu.edu.sg/wnja/ ↩
- “MeCab: Yet Another Part-of-Speech and Morphological Analyzer”. https://taku910.github.io/mecab/ ↩
- megagonlabs. “GiNZA – Japanese NLP Library”. https://megagonlabs.github.io/ginza/ ↩
- DENON official Blog. “超初心者のための「オーディオって何?」”. https://www.denon.jp/jp/blog/3595/index.html ↩
- Daniel Tunkelang: https://www.linkedin.com/in/dtunkelang/ ↩