目次

リクルートテクノロジーズの叶内です。以前告知させていただいた、第5回リクルート自然言語処理ハッカソン の報告です。作業時間およそ3.5日という短い期間でしたが、皆さん全力で課題に取り組んでくれました。以下について書いていきます。
- ハッカソン環境
- データと課題
- 表彰
- まとめ
- 運営紹介
ハッカソン環境
BigQuery と Google Colaboratory(jupyter notebook)を用いた分析環境を用意しました。
事業のデータを元にハッカソン用のデータウェアハウスを運営側で作成し、学生が直接BigQueryでデータを確認できるようにしました。
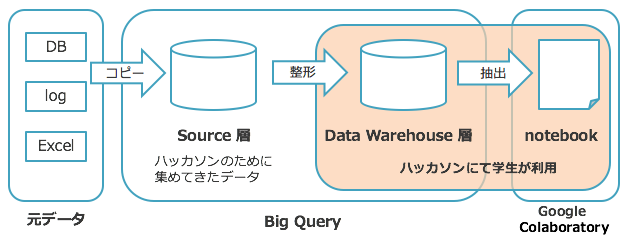
また、Google Colaboratoryのサンプルコードとして、BigQueryからデータを引き抜きpandasのDataFrame型に格納したものや、MeCabやCaboCha、Word2VecがColab上で動作するものを用意しました。今回は自然言語処理ハッカソンということもあり、SQLの経験が浅い学生も多かったですが、みなさんサンプルコードを使いながら圧倒的成長を見せてくれました。
作業中の情報のやり取りは対面での会話かSlackで、エラーで詰まった時もColabを共有設定にしてもらうだけで確認できたため、楽に進行することができました。そしてデータのやり取りは、Googleアカウントを利用することで、データ抽出(Big Query)・データ分析(Colab)・発表(Googleスライド)の全てを完結させました。
データと課題
ある2つのサービスのコンテンツと、それらに紐づいたPVなどのアクセスログ、そしてそれぞれのサービス内での退会アンケートデータを提供しました。普段どんな人達がサービスを使ってるのか、どのコンテンツがどのくらい見られているか、実際にどんなアンケート結果が寄せられているのか、皆さん集計して探っていました。
本ハッカソンでやることは基本的に自由でしたが、分析のモチベーション・分析結果、そしてこうすべきだという何かしらの提言を発表に含めてもらい、それを評価しました。
表彰
表彰は総合的に最も優れていた人に送る最優秀賞の他に2種類の優秀賞(ビジネス部門とテクノロジー部門)を用意しました。それぞれの結果と選ばれた理由を報告します。
最優秀賞:苅野さん(東京大学大学院)「アンケートドリブンで課題を見つける」

まず、退会アンケートに記載された不満点についての自由記述に対して、LDAを用いて不満要因を推定するためのトピックを抽出しました。次に、そのトピックに該当しそうな、とある利用者層の人数を推定し、サービスにとって重要な利用者層であることを確認しました。最後に、その利用者層の中でアンケートに満足と答えた方が不満と答えた方よりも、関連するサービスの閲覧回数が有意に高いことを発見しました。
今回評価した点は技術観点とビジネス観点の2つです。
技術観点ではさらに以下の2点を評価しました。
(1) アンケートにLDAをかけることだけで満足せず、その結果をアンケートからの不満点の抽出のため、自分で使って、実際に不満を持ちがちな利用者層の推定に成功した点です。教師なしの手法は、出てきた結果をどう扱うかに苦労しがちなので、実際に自分でその有用性を実証した点は大きいと考えました。
(2) その利用者層の中での満足・不満と答えた方の行動の違いを、検索回数など考えられそうな指標を一通り調べた上で、関連サービスの利用回数に違いがあったということを発見しました。本ハッカソンのようなかなり限られた時間の中で調べられた点は、彼のいわゆる「手の速さ」といった技術力の高さを示していました。
ビジネス観点では、”不満がある方へ記事コンテンツによって支援できる可能性”を強力に示唆した点を高く評価しました。今後の分析やビジネス応用についての大きな可能性を感じました。
優秀賞(ビジネス部門):佐伯さん(東京大学)「CVR向上のためのユーザープロフィール分析および改善提案」

今回のサービスにおいて、利用者が入力する際のテンプレート文をあらかじめ複数パターン用意するポイントがあります。このテンプレート文において、現在のテンプレート文には含まれていないが、入れたほうがCVRが向上する単語をデータマイニングにより発見しました。
この発見は、サービスの改善にすぐに反映可能であり、それもサービスにとって最重要項目のCVRを向上するであろうことが推察されたため、ビジネス観点で高い評価をさせて頂きました。
優秀賞(テクノロジー部門):佐嘉田さん(九州大学大学院)「退会アンケートの感情分析と自動分類」

感情評価・キーワード取得・類似内容のクラスタリングの3つの手法を組み合わせることでアンケート結果を集計する際の手助けとなるシステムの提案をしてくれました。また、各感情キーワードやクラスの分布について集計や考察もしてくれました。今回評価した点は以下の2点です。
(1) ハッカソン内のデータだけに頼らず複数の外部データを組み合わせてアウトプットを最大化してくれた点で、感情分析のための外部リソースとして SNOW D18 や ML-Ask を利用することでアンケート結果を感情毎に分類し、またWikipedia2VecとK-meansを組み合わせることで、類似アンケートを確認しやすくしてくれました。
(2) 正しく仮説を立てた上で必要と思われる感情分析をしてくれた点です。退会アンケートを書くということは、まさにサービスを退会しようとしており、退会するということは何かがきっかけになっている、そしてそこには感情の変化がありそうだという仮説です。何となく言語処理をするのではなく、仮説を検証するために言語処理をしてくれました。結果的にアンケートと感情分析の相性も良かったです。
まとめ
今回は提供したデータの幅が広かったため、自由度高くやりたいことができたのではないでしょうか。一方で自由度が高いが故に、どんなデータがあるのか確認する手間や、問題設定や分析方針の決定で悩む学生も多かったようです。2,3日目には、「まだデータの確認しかできてない」とか「SQLが記憶の彼方で辛い」などという嘆きの声が聞こえてきましたが、それでもみなさん最後は自分の仮説を立てて、分析できていたようです。
また、今回は言語処理ではない属性データも多く利用できたため、それこそ言語処理を使わずに分析を進めてくれている学生もおり、かえって潔く、大変興味深いものがありました。自分の仮説を検証するために言語処理が必要であれば使うというのが正しい判断で、今回入賞した学生達に関しても言語処理を使ったモチベーションには納得感がありました。
かたや違う声として、「自分で立てた仮説について、もっと早くメンターに相談しておけば良かった」というものがありました。他人に話してみて初めて自分の仮説のおかしな点に気付くことがあり、数日間のハッカソンだとちょっとしたロスが命取りになることを経験したようです。これも大きな学びですので、ぜひ次に活かしてくれたらなと思います。
参加していただいた学生の皆様、本当にありがとうございました。今後も、今回のような企画を開催できるように尽力して参ります!

運営紹介
大杉 直也

叶内 晨

櫻井 一貴
