目次

はじめに
SIGNATE主催の国立公園の観光宿泊者数予測に弊社羽鳥、堀江でチーム参加しました。
本コンペでは、全国にある国立公園の”観光宿泊者数”の予測がテーマとなっており、1submit以上のユーザ数が124名で、実質4/124位という成績でした。
本記事では、実際に使用したアルゴリズムや特徴量、得られた知見について紹介します。
目次
1.コンペ概要
- 開催期間: 2018/10/24 – 2018/12/13 のおよそ1ヶ月半
- 全参加者数: 471名 (投稿者数: 124名)
- 目的変数: 各国立公園の 宿泊者数
- 予測期間: 2017/1/1~2017/12/31
- 学習期間: 2015/1/1~2016/12/31
- 外部データ: 第三者の権利を侵害しない無償で誰でも手に入るオープンなデータであれば外部データとして予測に使用してもよい
- 評価指標:Mean Absolute Error(MAE)
- 対象の国立公園
- 阿寒摩周国立公園
- 十和田八幡平国立公園
- 日光国立公園
- 伊勢志摩国立公園
- 大山隠岐国立公園
- 阿蘇くじゅう国立公園
- 霧島錦江湾国立公園
- 慶良間諸島国立公園
2.特徴量加工
データセットは、各公園の年間宿泊者数の予測、ということで時系列のデータになっています。
いくつかの公園は同じような動きをしているのですが、一部の公園には異様な盛り上がりがあるなど特性が異なる部分も多く、そのあたりをどのようにうまくモデリングするかが肝だったように思います。
昨年同日実績
各公園について、昨年同日の宿泊者数を変数化しました。2015年分については過去実績が取得できないため、この特徴はすべてnullになってしまいます。これを学習に使うかは悩ましいところだと思いますが、LightGBMで2015年を抜いて学習した場合と、2015年を入れて学習した場合は後者のほうが精度が良かったので、今回はそのまま残しました。
昨年同曜日実績
2019/2/2(土)に対して2018/2/3(土)を対応させるような形で、1年前に近い日付の同じ曜日の実績を変数化しました。上記同様2015年のデータもそのまま学習に使用しています。LightGBMの変数重要度では昨年同日実績よりも昨年同曜日実績のほうが上位に入っていました。
基礎的な時系列情報
月、曜日、日、一年の中の何日目か、クオーター、週、月初フラグ、月末フラグ、Q初フラグ、Q末フラグなど基礎的なものを一通り作成しました。
日本の休日
GW、お盆、シルバーウィーク、年末、年末年始、土日+祝日、3連休、3連休初日、3連休中日、3連休最終日など思い浮かぶ特異な休日をフラグ変数化しました。
循環する変数を円周上に落とし込んだもの
予測対象日と類似している状況をeuclid距離で算出するために、月・日・曜日という繰り返しが発生する変数を均等に円周上に配置、sin・cosに変換し、変数化しました。
海外の休日
各種統計情報を確認すると、海外からの宿泊客も多いことがわかったので主にアジア圏 (中国、韓国、台湾) の祝日を追加しました。
また、それぞれの祝日に対して、前日祝日フラグ、翌日祝日フラグを追加しました。
気象情報
配布されているデータセット中には、欠損値が多かったため気象庁から周辺地域の気象情報を取得し、適当な重みによる平均をとり欠損値補完を行いました。その上で、1、3、5daysのlagおよび1,2 weeksのlagを追加し、変数化しました。
交通機関情報
交通機関情報には、各都道府県への発着情報が存在していました。データとしては、国立公園へ向かうルートと国立公園から帰るルートが混在していたため、ルートごとおよび発着ごとに計算したところ目的変数との相関が大幅に改善しました。しかし公園によってはそもそも公共の交通機関を使うことが少ない (車での移動が主) こともあるので、この特徴は公園ごとのモデリングのときにのみ利用しました。
3.その他の考察
- 日光の宿泊者数
2015年の宿泊者数が2016年と大きく乖離しており、年間のトレンドとしてそれを盛り込んでしまうと大きくPublicLBが落ちるといったことがありました。
実際に2015年、2016年の観光客数を確認したところ、伸びはあるもののそこまでの乖離はないということを確認し、ある程度手での補正を行いました。 - 目的変数
今回のデータセットで最も注意しなければならないのは、観光で訪れた人数ではなく、宿泊者数というところでした。
当初、ある程度精度に寄与するであろうと考えていた気象情報は、実験してみたところ実はそれほど寄与しないということがわかりました。おそらくは、宿泊のために以前から予定をたてている観光客は天気にあまり左右されない (ある程度悪天候であろうと宿泊はする) ということなのかもしれません。結果、方針の転換が必要となり多くの時間を費やしました。 - 予測値の妥当性検証
モデルによって得られた予測値を検証する際には1年分の予測値と昨年同日の値、昨年同曜日の値を公園ごとに時系列プロットして妥当性を確認しました。これによって「LightGBMは大まかなトレンドをうまく捉えられている、kNNはピークをうまく検出できている」などのアルゴリズムごとの特性を定性的に把握することができました。これは複数の実験結果からsubmitする予測値を選定するときや、アンサンブル戦略を考える際に有効でした。
4.アルゴリズム
SIGNATEでは、submit時に分析手法、使用ソフトウェアを選ぶ欄があり、ランキングページから参加者がどのような分析を行っていたかを見る事ができます。 当該コンペ分析手法ページ
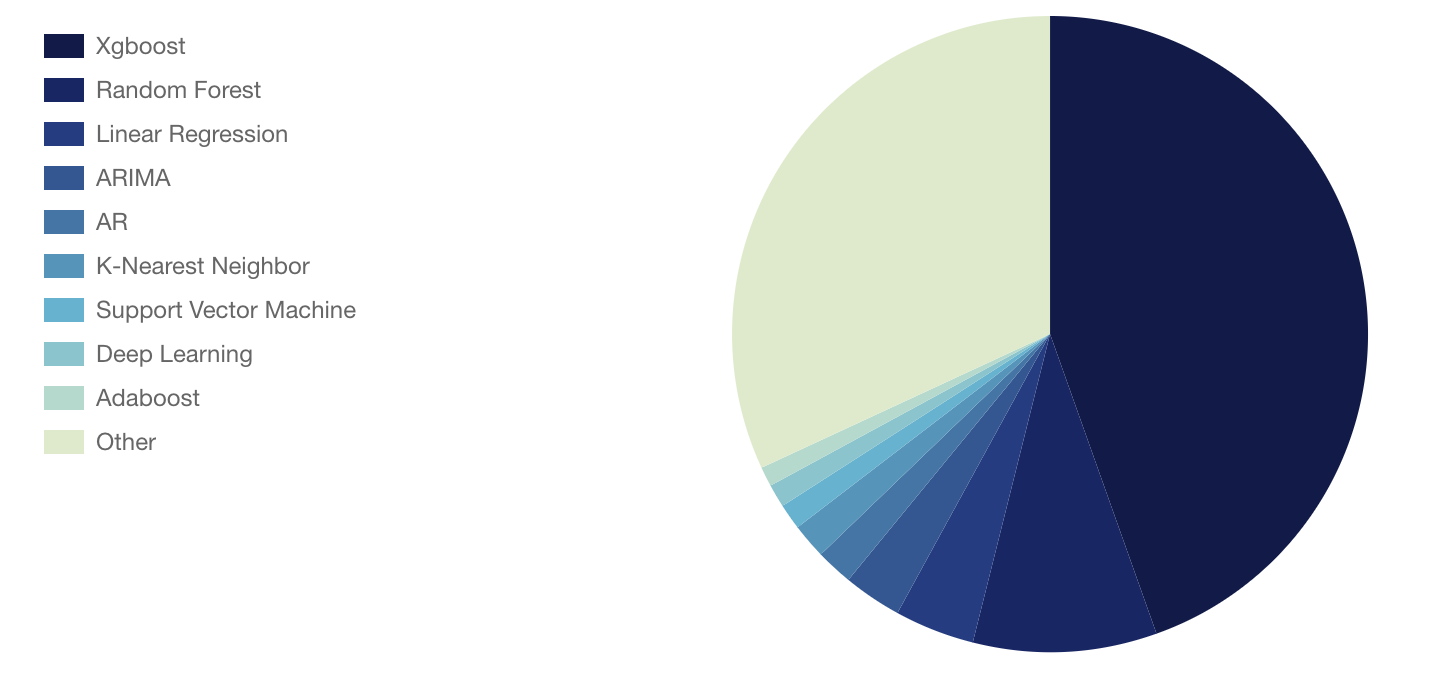
Xgboostが圧倒的であり、次にRandom Forest、Linear Regression、ARIMAといわゆる時系列のアルゴリズム以外が主に使用されていたようです。
私達は今回、Public LBへの過学習を避けるために異なる特性のモデルを複数用意しました。
4.1.LightGBM
- 機械学習コンペの常連であるLightGBMでしばらくの間は実験を行いました。
今回はサンプルサイズが小さく、容易に過学習を起こすため、ハイパーパラメータのチューニングと特徴量の選定には気を使いました。 - ハイパーパラメータに関しては木の深さを浅くすること、feature fractionを行うことでだいぶ過学習を抑えられました。特徴量は大量に入れると学習がうまく進まなかったり、予測値が大きすぎたり小さすぎたりということになったので、昨年同曜日実績、昨年同日実績、時系列・休日情報のみ投入し、公園をまとめてモデリングしました。
- コンペ中盤以降は目的関数を変更すると予測値の傾向が変わることがわかってきたので、多様性を担保する意味もあり、objective=’poisson’、objective=’regression’と2種類の予測値を作成し、ブレンディングして使用しました。また、objective=’regression’の場合は負の予測値が登場することがあるので、最小値が0になるようクリッピングしています。
4.2.kNN
昨年同日、昨年同曜日などの結果を実験的にsubmitする中で、基本的に昨年と今年ではあまり傾向が変わらないということが判明してきました。ここでKaggleで以前開催されていた Web Traffic Time Series Forecasting では、適当な間隔で中央値をとる手法やkNNがそこそこの強さだったことを思い出し、kNNを選択しました。最終的には、各種休日フラグ、周期的な時系列変数、交通機関情報で各公園ごとにモデリングし、LBの精度でLightGBMを上回るほどになりました。
4.3.RandomForest
overfitが怖かったので、コンペ終盤にブレンドのための候補として選定しました。特徴量は基本的にkNNと同じものを使用し、各公園ごとにモデリングしました。上記2つに比べるとあまり思い入れのないモデルでしたが、後から見るとprivateスコアで最も良かったのはRandomForestのシングルモデルでした。
5.アンサンブル
「時系列コンペのLBスコアは信用してはいけない」というのはチーム内の共通見解だったので、多少LBスコアが悪かろうが、アンサンブルモデルを最終提出に選ぶという強い意志が私達にはありました。このためコンペ最終局面ではアンサンブル戦略をひたすら考えていました。
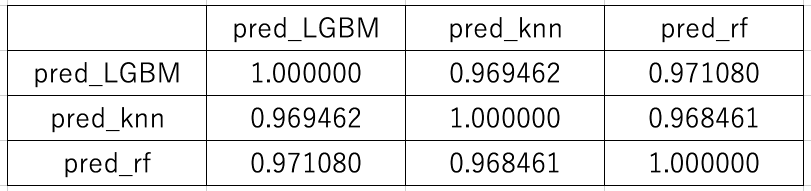
個別にチューニングを行った結果、LightGBM、kNN、RandomForestの3種類のモデルが1600程度のLBスコアを出すようになりました。ここでそれぞれの予測値の相関を見てみると、0.96~0.97程度と (blendの候補としては) そこまで高くないので、最終的にはこの3種類の予測値の重みを変えつつ、ブレンディングを行いました。こうした複数回の実験の結果、最終日の2submit目でLBスコアが1600→1500と大幅に改善しました。
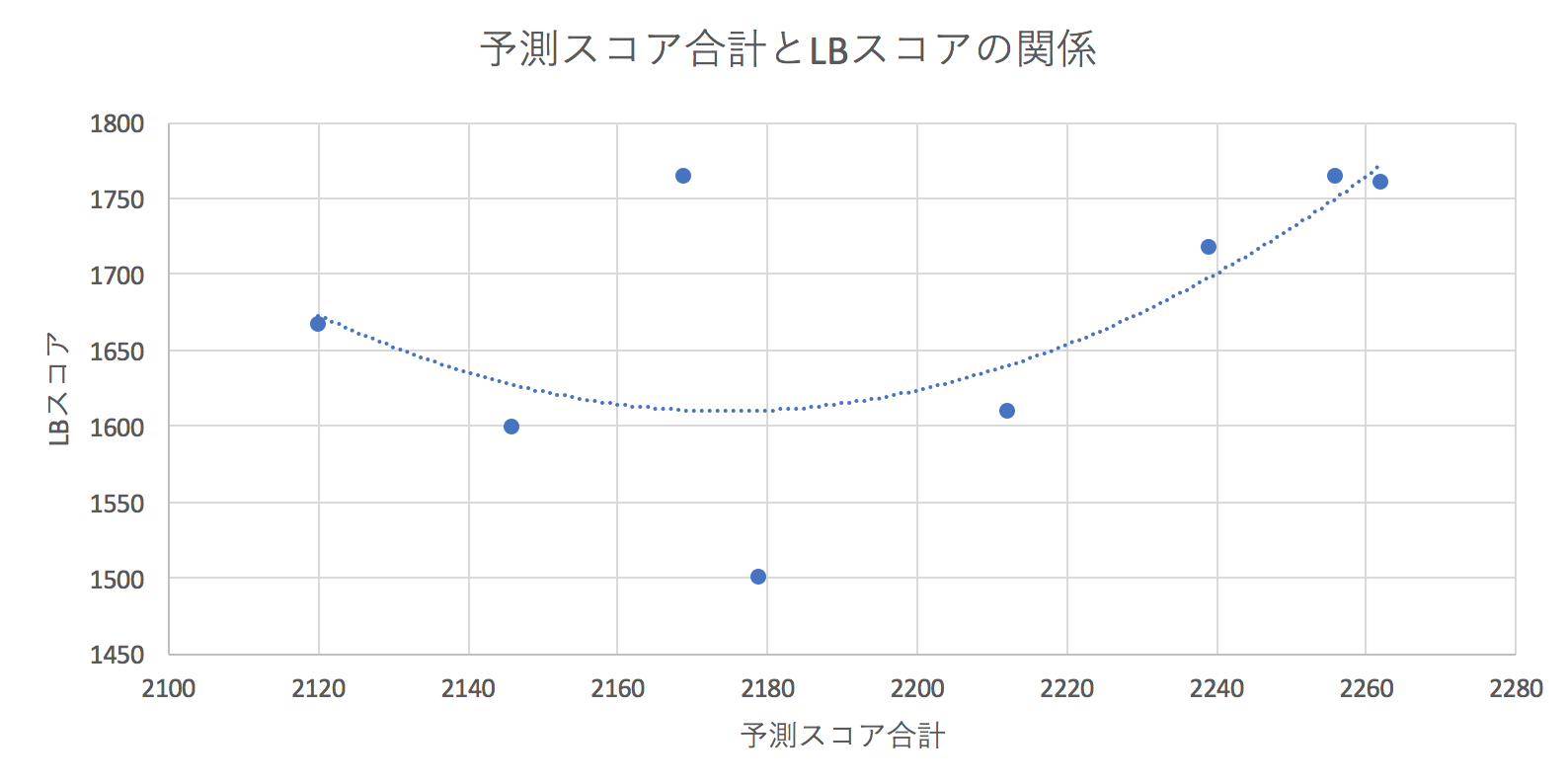
最後のsubmitの際に各モデルの重みをどう決めるかというのは悩ましいところでしたが、今回はスコアの合計値に注目してみることにしました。比較するsubmitごとの予測スコア合計とLBスコアをプロットし、二次近似してみたところ、予測スコア合計を現在の最良モデルよりもやや小さくしたほうが良さそうであることがわかりました。
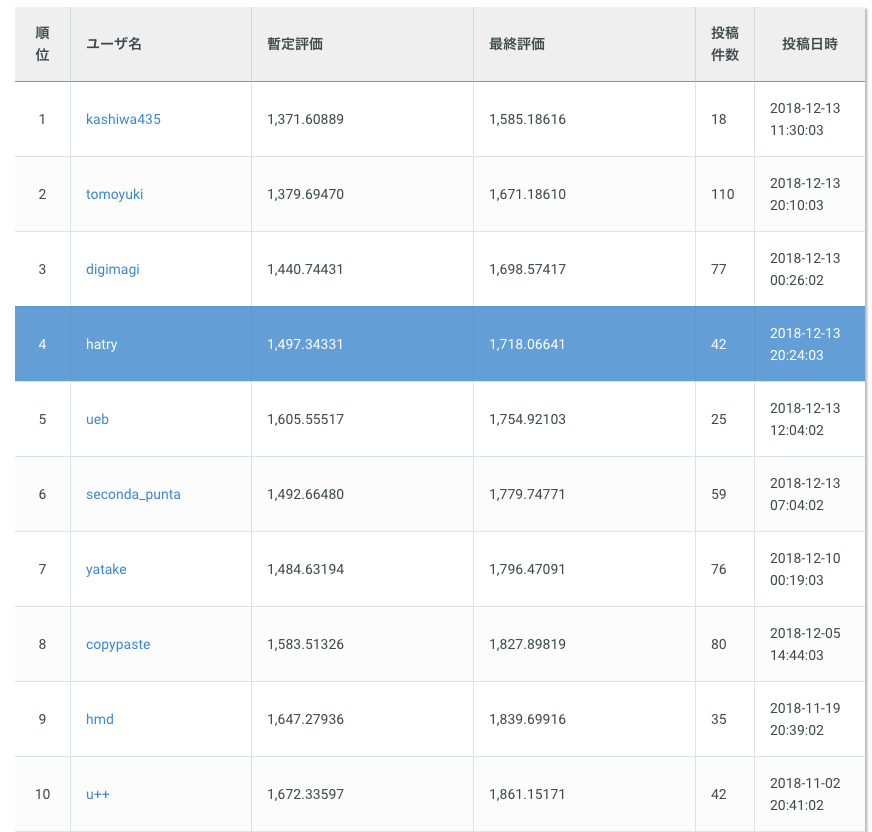
このようにして最終的な重みを設定したlgbm+kNN+rfモデルはLBスコア1500→1497と僅かな改善でしたが、privateスコアでは1757→1718と大きく改善していました。これによってLBからprivateでは見事10位→4位にshake upすることができました。
6.チーム参加について
- 環境の共通化
- 役割分担、アイデアの共有について
- コンペ終盤には毎日時間を取って対面で会話しながらモデリングを行いました。ここで日毎に本日お互いがやることを確認したり、データから得られた知見を共有することでスムーズに作業を進められました。また、どのような方針で特徴量を作り込んでいくか、アンサンブル戦略をどうするかなどは議論しながら分析することで新たな発想が生まれたりすることもあり、ここはチーム参加の意義を大きく感じた点の一つです。
7.終わりに
弊部署では、コンペで得た知識を業務に活かして今回のような時系列の未来予測を行ったり、リクルートのプロダクトのデータを使用したレコメンドエンジン構築など様々な分野で予測・分析を行っています。
機械学習コンペが大好きな皆さん、ぜひ一緒に働きましょう!
次は優勝したいですね。