目次
はじめに
このエントリは全9回を予定する18卒新人ブログリレーの第6回です。
はじめまして。今年の4月にリクルートテクノロジーズに新卒入社した小松凌也です。
約3ヶ月に渡る新人研修を終え、7月にサービスオペレーションエンジニアリング部プロジェクト基盤グループに配属されました。現在はインフラエンジニアとして、新規プロダクトの基盤構築や既存プロダクトのインフラ運用フロー改善などに取り組んでいます。
今回この記事で紹介するのは、Amazon Web Services (AWS) 上に構築済みの既存サービスの開発環境を別のAWSアカウントに分離し、Terraformというツールを用いてソースコードでインフラの構成を管理できるようにした事例です。
事例の紹介に加えて、Terraformを使用する上での実践的なテクニックについても随所で解説します。
前提
アカウント分離とTerraform化の背景
この記事における「アカウント分離」は、「一つのAWSアカウントに混在する複数の本番、ステージング、開発環境を別のAWSアカウントに分離する」という作業のことを指します。今回の対象となったサービスでは一つのAWSアカウントに本番を含む複数の環境が混在しており、それに伴う開発や運用上の負をもたらしている状態でした。
一般的には本番環境が存在するAWSアカウントに本番以外の環境を混在させるのは良くないパターンです。しかし、このサービスに関しては開発時に必要な品質を担保した上でスピードを重視する必要があったこと、初期の段階でアカウントを分離する作業とその対応作業に割けるリソースが充分ではなかったことなどの理由により当時選択できるベターな方針としてAWSアカウントを一本のまま開発を続けた背景があります。
また、各種クラウドプロバイダの台頭によってインフラのクラウド化が進む中で、いかにしてインフラの構築コストを下げるか、ベストプラクティスとしての既存サービスのアーキテクチャをどのように流用し他の新規サービスに活かすかということも重要です。それらの考慮も含めて、Infrastructure as Code (IaC) を積極的に活用した Site Reliability Engineering (SRE) 的な取り組みの一環としてTerraformを使う計画がありました。
目的
大きな目的として「AWSアカウントの分離」と「リソースのTerraform化」があり、それに付随する副次的な目的も設定されました。
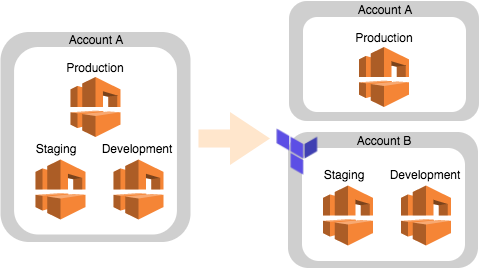
図. アカウント分離作業前後のイメージ
- 開発用の環境(ステージング環境、開発環境)を別のAWSアカウントに分離する
- 本番環境以外のリソースを既存アカウントから削除し、開発用の環境に対する操作で本番用の既存アカウントを触る必要がなくなるようにする
- 開発用の環境で障害などが発生した際に本番環境が不意に巻き込まれなくなるようにする
- Terraformを利用してインフラのリソースをコード化する
- ステージング環境、開発環境の面を増やしたいときに、同じ構成で簡単に立ち上げられるようにする
- リソースの抽象化によって他のサービスなどにも容易に流用できるようにする
- インフラ自体をソースコード化しGitで管理することによって、インフラのリソースに関して何をどのように変更したのかを追従できるようにする
Terraformについて
Terraformとは
TerraformはHashiCorp社が開発しているインフラの構成管理ツールで、インフラのリソースをソースコードとして宣言的に定義することでプロダクト開発におけるIaCの導入を可能にしてくれます。
IaCを実現する類似のツールとしては AWS CloudFormation や Red Hat Ansible などがありますが、Terraformは AWS, Google Cloud Platform (GCP), Microsoft Azure, Heroku, OpenStack を含む約90種類ものプラットフォームに対応している点や、拡張性や機能性が高い点、ツールの開発が活発である点などにより、社内でも使われる場面が増えつつあります。
Terraformによるインフラのコード化のメリット/デメリット
メリットとして、HashiCorp Configuration Language (HCL) で宣言的にリソース定義が記述されたTerraformの設定ファイルは、構築時の状態と依存関係の整合性が常に担保されているインフラの構築を可能にしてくれます。これはTerraformに限らず、宣言的にリソースを定義できるインフラ構成管理ツールにおいては共通して言える利点の一つです。リソース間の変数参照によって依存関係を表現することで、リソース作成順序を自動的に判断させることや、選択ミス・記述ミスのようなヒューマンエラーを回避することができます。
そもそもAWSに加えてHCLやTerraformの学習コストが掛かってしまうことや、ツールとして完成度が完璧というわけではなく部分的に管理できないリソースがあるなどいくらかの不自由さはありますが、
- リソースのソースコードベースでの構成管理が可能になる
- 構築の工数が激減する
- ヒューマンエラーから解放される
などの恩恵を受けられることは、インフラ側だけではなくアプリケーション側ひいてはプロジェクト全体の開発プロセスとスケジュールの改善にも寄与してくれるでしょう。
デメリットとしては、コード化されたインフラの保守と管理には学習コストを含めて相応の手間がかかってしまうという点があります。コードのメンテナンスがされなくなってしまうと次第にリソースの管理も杜撰になり、Terraformを導入した恩恵を受けることもできなくなってしまいます。
開発環境
私が普段使用している Visual Studio Code では Visual Studio Marketplace でTerraformのプラグインが提供されています。他のプログラミング言語用のプラグインでも提供されているような Linting, Syntax Highlight, Formatting, Auto-Completion などの基本的な機能に加えて、リソース定義のジャンプ機能も備えています。リソースや変数の参照がある場合には、それがどこで参照されているのか、何箇所で参照されているのかを確認することができ、更に定義と参照のそれぞれを一括で置換することもできます。
TerraformはVisual Studio Code の他にも様々なIDEやエディタ向けのプラグインが提供されているので、使っているものに合わせてプラグインを使用することが推奨されます。
- HashiCorp Terraform / HCL language support – IntelliJ IDEA
- vim-terraform – Vim
- syohex/emacs-terraform-mode – Emacs
また、この記事ではTerraform v0.11.7を使用した例として紹介します。
作業前の準備
現状の把握
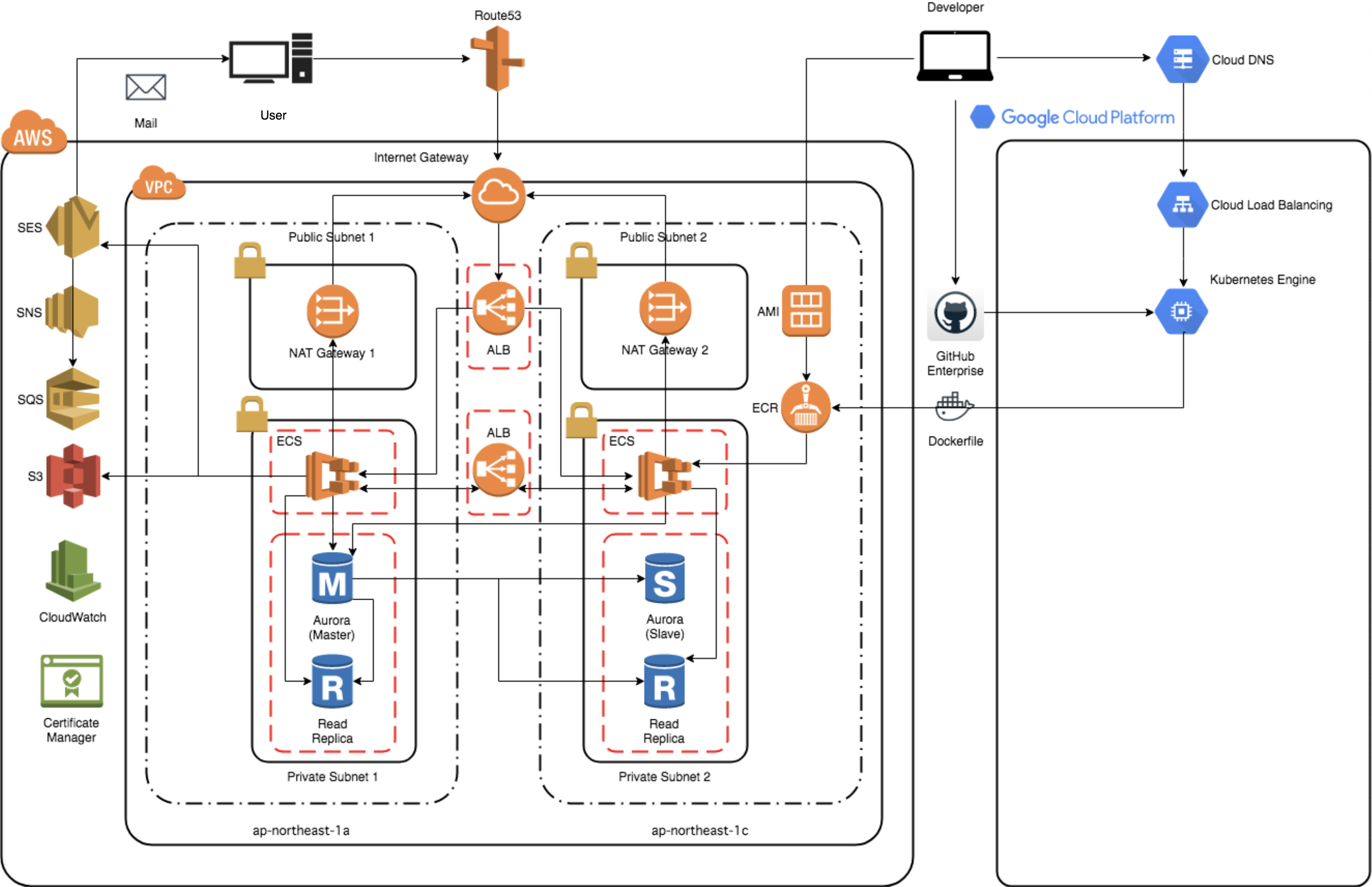
図. 今回の作業の対象となったサービスのアーキテクチャ
着手段階では上図の左のAWSの範囲でカバーされているリソースが一つのAWSアカウントにほぼ同じ構成の本番環境・ステージング環境・開発環境の3つの環境として混在している状態でした。ファイアウォール周りの設定やセキュリティグループの設定などは環境ごとに部分的に異なっていましたが、大部分が共通の構成になっていたため、モジュールと変数による抽象化が可能なTerraformにとっては非常に好都合です。
また、今回の分離作業によって新しいAWSアカウントに移行するのはステージング環境と開発環境のリソースだけなので、対象となるリソースを正確に洗い出す必要がありました。数がかなり多いので作業量はそれなりでしたが、
- 分離作業の進捗状況確認
- 移行作業中のミス防止(間違えて移行してしまう、又は移行し忘れる)
- 移行後の既存アカウント上のリソース削除作業中のミス防止
などを考慮すると移行対象リソースを洗い出してドキュメントとして残したのは正解だったと言えます。
更に今回のアカウント分離とTerraform化の対象になったサービスは、これから作る新規サービスではなく既にインターネットに公開されて動いているサービスです。実際にユーザーが触れている本番環境はもちろん、他の社員が現在進行形で開発を進めるステージング環境と開発環境に関してもアカウント分離作業の影響で障害を引き起こさないように厳重に注意をする必要がありました。
やること/やらないことの切り分け
- やること
- 可能な限り全てのリソースのコード化
- コード化できないリソースの詳細な再現手順のドキュメント化
- Terraformのコード全体の構造や運用に関してのドキュメント化
- やらないこと
- Terraformが対応していないリソースのコード化
- 制約によってコード化が難しいリソースのコード化
環境の分離とポータビリティの向上を目指している今回の作業では、管理の可否と対象の取捨選択を判断をしつつ基本的に全てのリソースをTerraformの管理下に置く方針で進めることにしました。
しかし前述のメリット/デメリットにもある通り、Terraformではそもそも管理ができないものや管理が難しいものがいくつかあります。例えば、使用に規約の同意のステップが必要であるようなリソースは扱えなかったり、規約の同意以外にもメールアドレスの手動での認証プロセスを挟む必要があるものやサービスの構造上実現が不可能だったりと様々で、そういった理由で管理対象外となったリソースに関しては構築と運用手順を細かくドキュメントにまとめることになります。
Terraformによってリソース間の関連の整合性と環境差分が担保されない部分は、意図しない不整合や環境差分が発生したときに障害の原因になり得るため正確な手順を書き残す必要がありました。Terraformを実際に運用するフェーズになったときに、開発した本人が介入しなくてもドキュメントとソースコードを追えば完全な環境の再現が可能になっているのが理想の状態です。
分離作業
モジュール構造・方針
Terraformにおいてリソース定義をどのように分割して構造化するかを考えるとき、多くのユーザーはなんとかしてベストプラクティスを探し出し最も綺麗なモジュール構造で設計しようと考えると思います。しかし残念ながら、GitHubを探し回っても記事を読み漁っても自分たちにとってのベストプラクティスは見当たらないため、基本的に自分が作りたいものに合わせたベストな構造と設計を自分で考える必要があります。
今回のケースでは、
- 管理対象となるリソースがかなり多くなる見積りであること
- 多面化を前提とした設計が好ましいこと
- モジュールの抽象化により外部からの値の注入で柔軟な環境構築が可能であるのが好ましいこと
などの前提条件により、モジュールに関しては以下のようなディレクトリのツリー構造で開発を進めることにしました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
modules/ ├── acm/ ├── asg/ │ └── template/ ├── cloudfront/ ├── cloudwatch/ │ ├── log/ │ └── metric/ ├── dms/ ├── ec2/ │ ├── ami/ │ ├── keypair/ │ └── loadbalancer/ ├── ecr/ │ ├── lifecycle_policy/ │ └── repository/ ├── ecs/ │ ├── cluster/ │ └── service/ ├── elasticache/ │ ├── cluster/ │ └── subnet_group/ ├── es/ ├── guardduty/ │ └── detector/ ├── iam/ │ ├── policy/ │ └── role/ ├── inspector/ ├── lambda/ ├── rds/ │ ├── cluster/ │ ├── instance/ │ └── parameter_group/ ├── route53/ │ ├── health_check/ │ ├── record/ │ └── zone/ ├── s3/ ├── ses/ │ ├── domain_dkim/ │ ├── identity/ │ └── verification/ ├── sns/ │ ├── subscription/ │ └── topic/ ├── sqs/ │ └── queue/ ├── vpc/ │ ├── elastic_ip/ │ └── securitygroup/ └── waf_shield/ └── waf/ ├── conditions/ │ ├── ipsets/ │ └── regex/ ├── rules/ └── web_acl/ |
モジュール分割の方法は原則としてAWSマネジメントコンソール上で管理されているリソースの粒度に合わせています。別のパターンとしてインフラの構成コンポーネント単位でディレクトリを切り分ける方法もあると思いますが、今回この構造を採用したのは、
- 一つの環境でどれだけのリソースがTerraformの管理下にあるのかをコードレベルで可視化すること
- サービスや特定のインフラに依存したユビキタス言語をなるべくソースコードの中に含めないこと
の2つを重視したためです。
モジュールを表す末端の各ディレクトリには、
- main.tf … モジュールが内包するリソース、データソースなどの定義
- variables.tf … モジュールが受け取る変数の定義
- outputs.tf … モジュールが出力するAttributeの定義
の3つのTerraform設定ファイルをそれぞれ配置して各ファイルのコードが煩雑にならないようにしました。
tfstateの分割と管理方法における工夫
tfstateファイルの管理をローカルではなくS3バケットに任せるのは一般的なテクニックです。今回のケースでもtfstateファイルは全てS3バケットに配置することになりました。
|
1 2 3 4 5 6 7 |
terraform { backend "s3" { bucket = "bucket-name" key = "path/to/terraform.tfstate" region = "ap-northeast-1" } } |
今回少し悩んだのは、環境の数だけ増えるtfstateファイルをどのように整理し管理するかという問題でした。
モジュール全体を抽象化して容易に多面化できる構造になっている一方で、多面化に伴ってtfstateファイルは同じ数だけ増加します。また、ECRリポジトリ、IAMロール、セキュリティ関連のリソースなどは全ての環境で共通して使うことになるため、環境ごとにtfstateファイルを持って管理する場合無駄なリソースが増えたり名前の衝突が発生する原因になります。
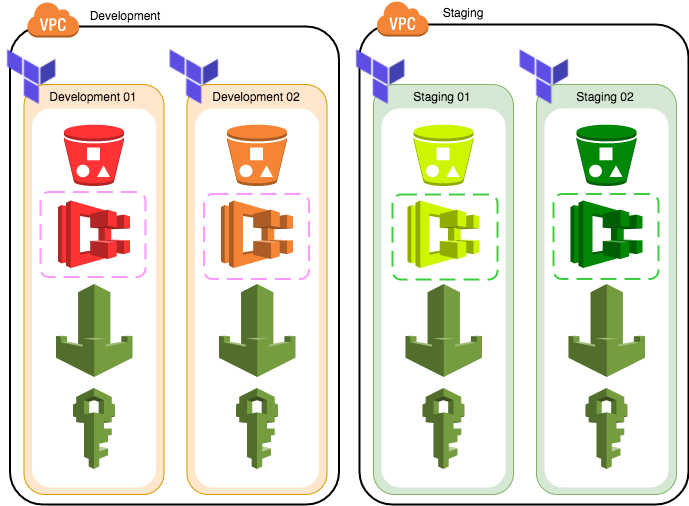
図. それぞれの環境で別個に一つのtfstateファイルを持つ場合。S3バケットやECSは別々でも、SecurityGroupがDevelopmentとStagingごとに共通だったり、IAMロールやWAFが全環境で共通だったりするので非常に無駄。
共通になるリソースをTerraformの管理下から外して手動構築するという手もありましたが、tfstateファイルはS3バケットのようなリモートで管理されている場合にそのoutputを別のTerraform実行環境から参照できるという機能を利用して、外部モジュールのような形で抽象度別にモジュールを切り分けることにしました。tfstateファイルをモジュールの抽象度別に分割して互いに参照することで、共通になるモジュールを一つのtfstateファイルにまとめることができ、同時にそれらが同一であることも担保できます。

図. tfstateファイルを分割管理するように変更した場合
上の図ではIAMロールとWAFがGlobalという名前の環境として別のtfstateファイルで管理されていて、Globalは他のtfstateファイルから terraform_remote_stateデータソースとして参照することができます。同様にSecurityGroupやAMI、Elastic IPなど各環境ごとに共通のリソースはそれぞれDevelopmentとStagingとして管理し、更に粒度の細かい各面のtfstateファイルから参照できるようにしました。

図. tfstateファイルで管理されているリソースのイメージ
既存リソースのimportと修正作業
Terraformで既存のインフラを管理下に置くためには泥臭い手順を踏む必要があります。 terraform applyコマンドはHCLで記述されたTerraform設定ファイルをパースしてtfstateファイル(JSON)を生成することができますが、逆に既存のtfstateファイルをパースしてTerraform設定ファイルを生成することはできません。 terraform importコマンドによって既にAWS上に存在するリソースをtfstateファイルとして取り込むことはできても、それをTerraform設定ファイルとしてパースすることは不可能です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
resource "aws_s3_bucket" "sample-bucket-terraform" { bucket = "sample-bucket-terraform" region = "${var.region}" request_payer = "BucketOwner" versioning { enabled = false mfa_delete = false } force_destroy = true } variable "region" { type = "string" default = "ap-northeast-1" } output "sample-bucket-arn" { value = "${aws_s3_bucket.sample-bucket-terraform.arn}" } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
{ "version": 3, "terraform_version": "0.11.7", "serial": 4, "lineage": "********************", "modules": [ { "path": [ "root" ], "outputs": { "sample-bucket-arn": { "sensitive": false, "type": "string", "value": "arn:aws:s3:::sample-bucket-terraform" } }, "resources": { "aws_s3_bucket.sample-bucket-terraform": { "type": "aws_s3_bucket", "depends_on": [], "primary": { "id": "sample-bucket-terraform", "attributes": { "acceleration_status": "", "acl": "private", "arn": "arn:aws:s3:::sample-bucket-terraform", "bucket": "sample-bucket-terraform", "bucket_domain_name": "sample-bucket-terraform.s3.amazonaws.com", "bucket_regional_domain_name": "sample-bucket-terraform.s3.ap-northeast-1.amazonaws.com", "cors_rule.#": "0", "force_destroy": "true", "hosted_zone_id": "********************", "id": "sample-bucket-terraform", "lifecycle_rule.#": "0", "logging.#": "0", "region": "ap-northeast-1", "replication_configuration.#": "0", "request_payer": "BucketOwner", "server_side_encryption_configuration.#": "0", "tags.%": "0", "versioning.#": "1", "versioning.0.enabled": "false", "versioning.0.mfa_delete": "false", "website.#": "0" }, "meta": {}, "tainted": false }, "deposed": [], "provider": "provider.aws" } }, "depends_on": [] } ] } |
上の例の s3.tfではS3バケットのリソースを定義しており、これをapplyすると下の terraform.tfstateが生成されてリソースがAWS上にデプロイされます。既存リソースからTerraform設定ファイルを生成するにはこのようなtfstateファイルをHCLの文法として読み替えた上で、不必要な値を削除し必要な値を足す必要があります。有志によって既存リソースをimportした上でTerraform設定ファイルまで生成するツールも一時期開発されていましたが、現在は更新が止まっているので基本的には人力でパースする必要があり、今回の分離作業においても大部分のリソースでtfstateファイルの人力パースを行いました。
tfstateファイルには変数や使っている関数などの情報は含まれないため、tfstateファイルは全てのArgumentとAttributeを実際の値が文字列としてハードコードされた状態で保持します。これをHCLの文法に合致するようにTerraform設定ファイルとして書き直すときには、
- ARNのようなArgumentとして必要のない値が含まれていないか
- Argumentとして必要な値が含まれているか
- Argumentの型が設定値の型と一致しているか
- ユニークになるべき値がユニークになるように変数や関数を通して設定されているか
などの点に注意をして作業を進めました。既存リソースのTerraform設定ファイル化機能についてはTerraformの公式リポジトリでもissueとして上がっていて、将来的には実装する方針ではあるようです。
静的なリソースの管理方法における工夫
Terraformが最も管理しやすいのは、VPCやサブネットなどネットワーク周りのリソースを含む全てのリソースをTerraform設定ファイルとして定義できてそれらを自由にデプロイ・変更・破棄できるまっさらな状態のインフラです。しかし、部分的なリソース、特にネットワークやセキュリティに関連するリソースは個人が自由に触ることができない範囲で中央集権的に管理されていることが往々にしてあります。
既存の変更不可な静的リソースのIDやARNなどをTerraform管理下のインフラで使うには以下の2つの方法があります。
- 値を定数リストのファイルにハードコードして各モジュールに変数で渡す
- データソースを利用して静的なモジュールとして扱う
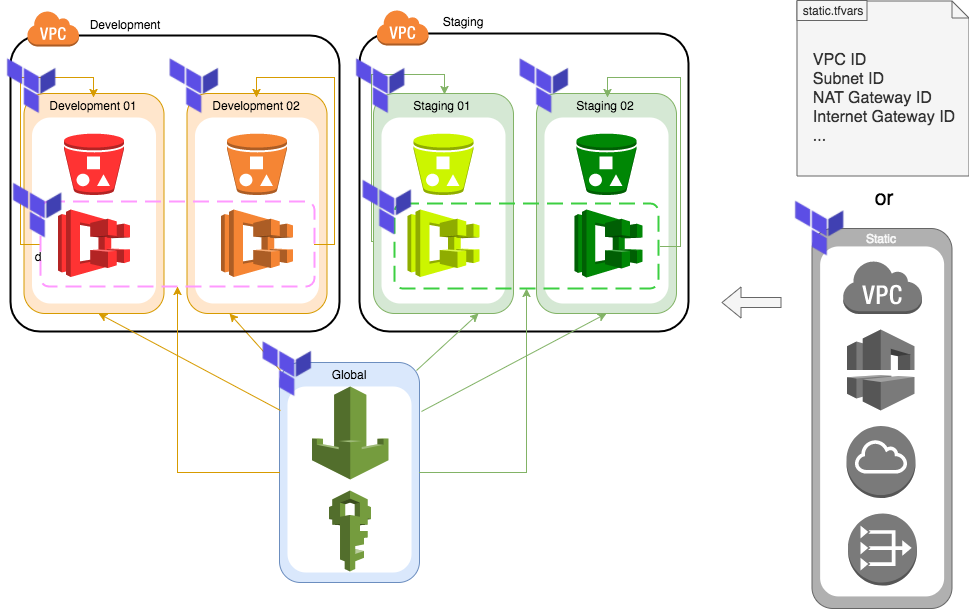
図. 静的リソースを扱う方法のイメージ
いずれの方法もどこかしらに定数をハードコードする必要がある点は変わりませんが、大きく違うのは「静的リソースを値として扱うか、モジュールとして扱うか」という点です。データソースとして定義すると静的なリソースを他のリソースと同じ抽象度で扱うことができて、同様にAttributeをoutputとして定義することで他のモジュールからの参照も可能になります。静的リソースを全てデータソースとして定義して一つのtfstateファイルで管理するようにすれば、先述のようにリモートで参照することができるので「この値はどこかでハードコードされているのか?」という無駄な思考プロセスも不要です。
サブドメインの自動切り出し・認証
Terraformによるインフラのコード化はインフラの構築をCLIで完結させてくれるようになります。インフラを構築・破棄するというフローをCI/CDのパイプラインに組み込むこともできるようになるので「PullRequestで検証環境をサクッと立ち上げて、レビューと動作検証が終わってマージされたら環境を破棄」のようなことも簡単に実現できますし、この例以外にも単純に面を増やして環境をスケールさせることも可能です。
新規に環境を立ち上げるときにはその環境専用のユニークなドメインを切り出す必要があり、多くのケースではそのプロジェクトに割り当てられたルートドメインから切り出されたサブドメイン上に環境が構築されることになると思います。AWSマネジメントコンソールから手動でサブドメインを切り出すときには、
- Route53にサブドメインのHosted Zoneを作成する
- Route53のルートドメインのHosted ZoneにサブドメインのNSレコードのレコードセットを作成する
という2つのステップが必要になりますが、Terraformの場合は先述のtfstateファイルの分割管理を利用することでこれらのステップを完全に自動化することができます。

図. サブドメインを切り出す手順のイメージ
ルートドメイン(example.com)のHosted ZoneはGlobalのtfstateで管理し、それ以外のサブドメイン(dev.example.com, stg.example.com)のHosted ZoneとルートドメインのHosted Zoneに追加するNSレコードはそれぞれの面のtfstateで管理します。多面化とCI/CDパイプラインでの運用を前提にする場合はこの方法を用いるのが安全かつシンプルです。今回のTerraform化においては、AWS Certificate Managerによるサブドメインごとの証明書取得も含めて面ごとに自動化をしました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# Global.tfstateで管理する resource "aws_route53_zone" "root" { name = "example.com" force_destroy = false comment = "Root domain (Managed by Terraform)" } output "root_zone_id" { value = "${aws_route53_zone.root.id}" } output "root_zone_name" { value = "${aws_route53_zone.root.name}" } output "root_zone_ns" { value = "${aws_route53_zone.root.name_servers}" } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 各面のtfstateで管理する resource "aws_route53_zone" "sub" { name = "dev.${var.root_zone_name}" comment = "Sub domain (Managed by Terraform)" } resource "aws_route53_record" "a_record" { zone_id = "${aws_route53_zone.sub.id}" name = "" type = "A" } resource "aws_route53_record" "ns_record" { zone_id = "${var.root_zone_id}" name = "dev.${var.root_zone_name}" type = "NS" ttl = "300" records = ["${var.root_zone_ns}"] } variable "root_zone_id" { ... |
Amazon ECS用ECRリポジトリの統合とイメージのクロスアカウントpullの採用
ECSにデプロイするためのイメージを保管するECRリポジトリについては、リポジトリ間のイメージの整合を図るために今回のアカウント分離に伴い全環境で統合されることになりました。今回の分離作業でECSのデプロイ先アカウントが2つになるため、どちらかのアカウントにECRリポジトリを配置した上でもう一方のアカウントからそのリポジトリのイメージを参照する必要があります。
ECRリポジトリはポリシーの設定によって、IAMユーザーからのアクセスを制御することができます。これは同じアカウント内だけではなく、アカウントをまたいだIAMユーザーに対してもアクセス制御を設定することができるので、今回は新アカウント上に配置されたECRリポジトリにポリシーをセットし、既存アカウント上のIAMユーザーに対してイメージの取得を許可するように設定しました。
ECRリポジトリのポリシーとIAMユーザーのポリシーの両方に
- ecr:GetDownloadUrlForLayer
- ecr:BatchGetImage
- ecr:BatchCheckLayerAvailability
の3つの操作をAllowとして設定した上で、IAMユーザーのポリシーに ecr:GetAuthorizationToken を追加するとIAMユーザー側からECRリポジトリに対するイメージの取得操作が可能になります。
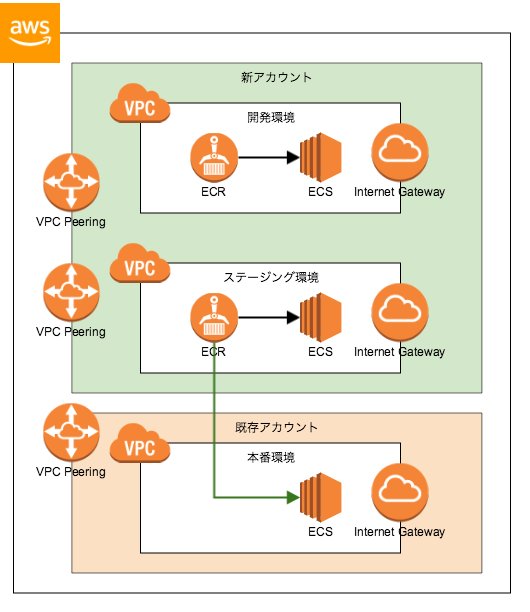
図. 本番環境からのクロスアカウントpull
AWS Lambdaのデプロイフロー管理
実はTerraformでLambdaを管理するのはあまり良い方法とは言えません。Apexをはじめとする様々なデプロイ管理ツールがある現在、特別な要求が無い限りはTerraformで管理をする必要は無いでしょう。
今回のケースでは特定の条件で発火してSlackにメッセージを送信するLambda関数を各面ごとにTerraformで管理するために、どのようにデプロイフローを整理して実装したかを説明します。
前提として、
- ランタイムがPython, Node.jsのケースでは拡張ライブラリを同梱してアップロードする必要がある
- Lambda関数本体には環境の面を表す情報(Development, Staging, 01, 02など)を含める必要がある
- Lambda関数本体はGitで変更履歴を追跡したいが、拡張ライブラリは追跡したくない
という条件がありました。ライブラリの同梱と情報の埋め込みのそれぞれについては、Terraformが提供する機能によって解決可能です。しかし、これらを全て同時に実現するにはどうすればいいのか前例が全く存在しないため、最適な方法をはじめから考える必要があります。
最初に考えたのは、ライブラリだけを内包するディレクトリとLambda関数本体を別で管理して template_file データソースによって埋め込んだ変数がレンダリングされた関数本体をライブラリと一緒にzipファイルとしてアップロードする方法でしたが、Terraformの archive_file データソースはArgumentとして source と source_file / source_dirを混在させることができません。ライブラリもzipに同梱するためには、どうにかして情報の埋め込まれたLambda関数本体を含む静的なディレクトリを用意する必要がありました。
そこで、Lambdaをデプロイする一連の流れをワークフローのようにしてTerraformで再現することにしました。
- テンプレートとなるLambda関数本体と依存ライブラリを記述したファイルを用意する。
- ディレクトリを複製し、Lambda関数に情報を埋め込む。
- installコマンドでライブラリをインストールする。
- ディレクトリをzipアーカイブにする。
- Lambdaにアップロードする。
|
1 2 3 4 5 6 7 |
lambda/ ├── main.tf ├── outputs.tf ├── src/ │ ├── handler.py │ └── requirements.txt └── variables.tf |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
resource "template_dir" "main" { source_dir = "${path.module}/src" destination_dir = "${path.module}/prepare" provisioner "local-exec" { command = "pip3 install --target=${template_dir.main.destination_dir} -r ${template_dir.main.destination_dir}/requirements.txt" } } data "archive_file" "zip_lambda" { depends_on = ["template_dir.main"] type = "zip" source_dir = "${template_dir.main.destination_dir}" output_path = "${template_dir.main.destination_dir}.zip" } resource "aws_lambda_function" "main" { depends_on = ["data.archive_file.zip_lambda"] runtime = "python3.6" filename = "${data.archive_file.zip_lambda.output_path}" source_code_hash = "${data.archive_file.zip_lambda.output_base64sha256}" function_name = "sample_function" handler = "handler.main" timeout = "60" memory_size = "128" reserved_concurrent_executions = "0" description = "Lambda function (Managed by Terraform)" role = "${var.iam_role_lambda}" } resource "null_resource" "main" { depends_on = ["aws_lambda_function.main"] triggers { uuid = "${uuid()}" } provisioner "local-exec" { command = "rm -rf ${template_dir.main.destination_dir} ${template_dir.main.destination_dir}.zip" } } |
今回Terraformで実行するのは2〜5のフローになります。2を実現するための template_dir リソースは、HCLのinterpolation syntaxを含んだファイルをレンダリングしながら、指定されたパスにディレクトリを複製してくれます。面を表す情報をレンダリングした上で、複製先のディレクトリで local-exec provisionerを使用すればinstallコマンドを発行することができるので3のライブラリインストールまで完了します。4でディレクトリをzipアーカイブにする時には3までのフローが終了しているのが必要条件なので、3のフローに対して depends_on で依存関係を明示することでフローの逆転が発生しないように強制しました。4の情報を使って5のデプロイが完了したあと、更に local-exec provisionerを使って2と4で作成されたディレクトリとzipアーカイブを削除することで一連のデプロイフローは完了です。
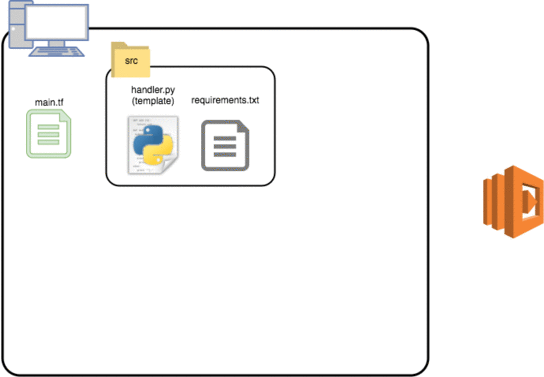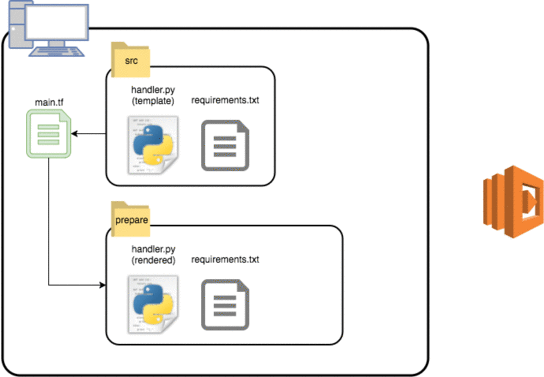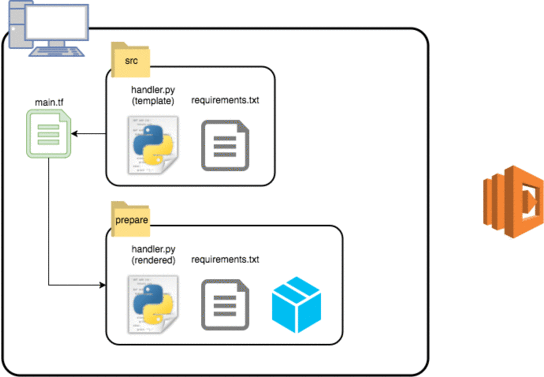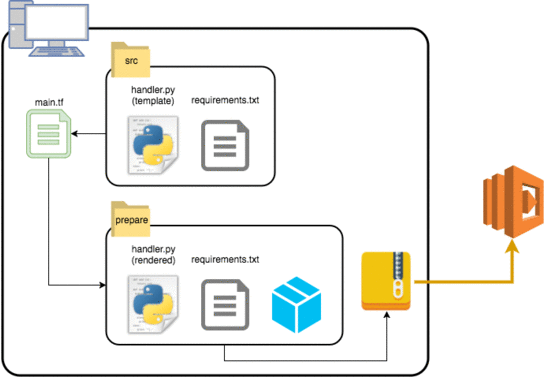
図. Terraformを使ったLambdaのデプロイフローのイメージ
最後にディレクトリとzipアーカイブを削除するのはLambda関数本体や依存ライブラリの変更時にその変更が正しくデプロイされるようにするためですが、これによって terraform apply コマンドはLambdaの関連リソースを新規リソースとして検知してしまうため毎回installコマンドとデプロイが走るようになってしまっています。 lifecycle などを活用することで無駄な再デプロイを回避することは可能なので、うまく組み合わせて運用することが重要です。
管理下に置かなかったリソース
TerraformやAWSの制約によって管理対象から外したリソースもいくつかありました。
ECRライフサイクルポリシー
一つのECRリポジトリには一つのECRライフサイクルポリシーのリソースしかアタッチできません。もし複数の面から一つのECRリポジトリを参照してECRライフサイクルポリシーをアタッチしようとした場合、一つのECRライフサイクルポリシーを互いに上書きしようとして意図しない値がセットされます。
今回は面ごとのイメージを一つのECRリポジトリで統合管理する方針だったのでECRライフサイクルポリシーの管理は手動に切り替えました。
プロトコルがemailの場合のSNSサブスクリプション
AWSの仕様上サブスクリプションの作成後にメールアドレス認証の操作を手動で行う必要があり、認証されるまでARNが生成されません。これがTerraformの設計思想に反するため、そもそもTerraformのSNSサブスクリプションリソースがemailのプロトコルに対応していませんでした。
今後の話
本番環境へのTerraformの適用
今回の分離作業でTerraformの管理下に移行したのは、新アカウントに再構築されたステージング環境と開発環境だけでした。今後新機能の追加などによって管理対象となるリソースが増えた場合に、本番環境に対しては手動によるリソースの追加を行う必要があります。片方を自動管理、もう片方を手動管理としたことによってアカウント間での整合性が担保されなくなる危険性があるのは懸念材料の一つとなるでしょう。
理想とするのは、本番環境が稼働している既存アカウントのリソースも新アカウントと同じTerraformのソースコードで管理できている状態です。
同じTerraformのソースコードを別々のアカウントにデプロイするための仕組みを整備する、本番環境へのデプロイで事故が起きないようなしくみを整理する、環境によるリソース差分を細かく洗い出すなど事前に解決すべき課題はまだありますが、最終的な目標を本番環境を含めたTerraformでのインフラ管理として開発と保守に注力したいです。
他サービスへの横展開
最初に設定していた目的に「リソースの抽象化によって他のサービスなどにも容易に流用できるようにする」とありました。Terraformを利用して高度に抽象化されたインフラは、特定のサービスやシステムだけではなくテンプレートのような形でその構造をそのまま他のサービスなどにも容易に流用することができます。
サービスに特化した構造でコード化されている現状では細かいモジュールの流用や設定値の参考にするなどの形で他のサービスで活用することができますが、今後の開発の中で汎用モジュールの拡充やモジュールの抽象度を調整することで更に幅広く他のサービスやシステムでも流用ができる形に昇華させていくことを考えています。
所感
最終的に既存リソースからTerraform設定ファイルとしてコード化されたリソースの数は合計200以上、約5800行前後にもなります。メンターをしてくださっている先輩社員が作ったJSONをHCLにパースするツールを使ってある程度削減されたとはいえ単純な作業量だと相当膨大になり、元々クラウドを利用したインフラ開発の経験がなかった自分にとってはかなり長期間に及ぶ作業になりました。
既存のインフラをリバースエンジニアリングする形でTerraformのソースコードに落とし込む作業は非常に学びが多く、実際に運用されているプロダクトと同じ構造のインフラを解剖して中を読みながらリソースの依存関係やサービス同士の相関関係、利用方法などを勉強していると、ゼロからドキュメントなどを読んで勉強するのとはまた違った新鮮さがあります。
今回の作業を通して得たAWSやTerraformに関する知見・技術はインフラをエンジニアリングする上で要求される技術の氷山の一角にしか過ぎないと思っています。AWS以外にもGCPやMicrosoft Azureなど様々なクラウドプロバイダが実際のサービス開発で使われるようになり、ミドルウェアやCI/CD、IaCのように多種多様なツール・ソフトウェアに関する知識も要求されるシーンが多々あります。
常に技術の進歩にキャッチアップする心を忘れず、モダンな技術と知識を積極的に吸収できるように日々努力しようと思います。
まとめ
以上、この記事では「AWSアカウント分離とリソースのコード化」の事例について紹介させていただきました。
SRE, DevOps, IaCなどの概念を最近よく耳にするようになり、これまで触れたことのなかったツールに突然触れる機会がやってくることもあるでしょう。
もしTerraformを使うシーンがあって、良い設計と運用が思いつかないような時には、この記事を少し参考にしてみると良いアイディアを思いつくきっかけになるかもしれません。
今後もこのブログを通じてインフラに関する設計・開発・運用の事例を紹介できる機会があると嬉しいです。
ここまで読んでいただきありがとうございました。