目次
本記事は リクルートライフスタイル Advent Calendar 2019 の11日目の記事です。
11月の7,8日に松江で開催された RubyWorld Conference 2019 にて登壇させてもらいました。この記事では発表した内容について書きたいと思います。
自己紹介
新卒4年目の @bya (Twitter: @byambaa_swiss) です。現在は、CET チームでストリーム基盤のプロダクトマネージャーを、じゃらん価値開発チームで SRE をやっています。
本記事は、価値開発チームとして登壇した内容について書いています。
RubyWorld Conference 2019
RubyWorld Conference は Ruby のさらなる普及・発展とビジネス利用の促進を目的とした会議で、今年で11回目の開催でした。国内外の18名が講演し、来場者数は2日間で1,053名にのぼりました。

Ruby のカンファレンスとしては、RubyKaigi、RailsConf、RubyConf が有名です。それらと比べ、今回のカンファレンスはビジネス利用の促進などの視点も含まれているのが特色です。なお、これら以外も含めた Ruby のカンファレンスの一覧としては rubyconferences.org が便利です。
発表した内容
弊社からは2人(前半:坂東塁・後半:@byam)で登壇し、大規模サービスにおけるRailsを活用した大胆な検証サイクルへのチャレンジ というテーマで発表してきました。


背景と取り組み
前半は、ユーザへ価値を届けるために必要なこと・大事にしたことについて、紹介させて頂きました。
弊社ではじゃらん net などの大規模なサービスを20年近く開発・運用しています。その開発の多くはウォーターフォール的ですが、一部では、既存の基盤アーキテクチャそのままにアジャイル/リーンアプローチでの開発にもチャレンジしてきました。それらのチャレンジはうまくいった部分もあります。
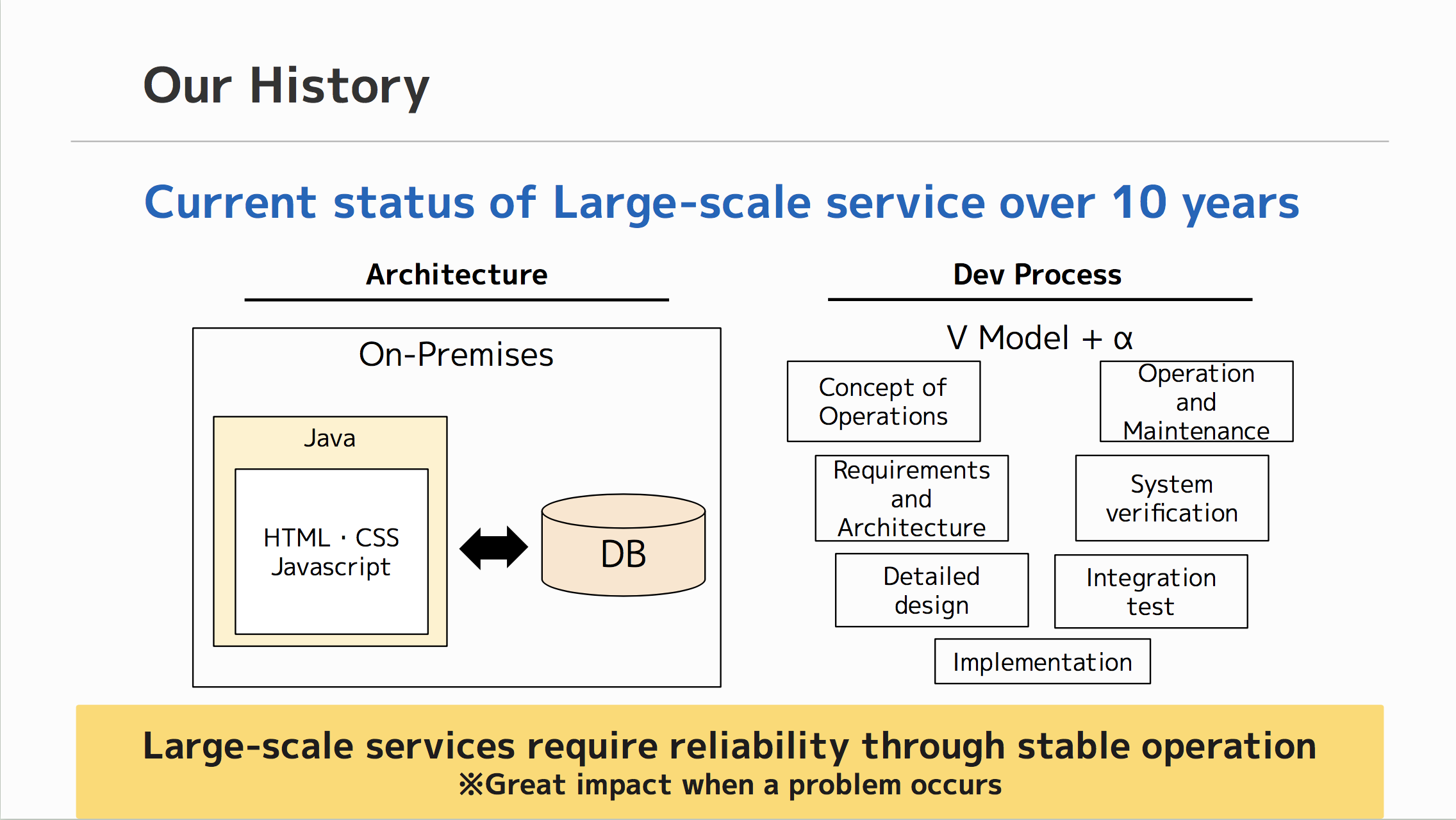
しかし既存の基盤アーキテクチャに沿ったままのアプローチでは、もう一歩進んだチャレンジをするには壁が存在していました。
たとえばサービス改善の一つとして、障害時の自動復旧を考えてみます。これはインフラレベルの改善が必要なので、これまでの基盤では高速な PDCA を回せず、基盤そのものをクラウドネイティブに近づけていく必要があります。かと言って、大規模サービスを動かしたままクラウドにマイグレーションするのは容易ではありません。
そのような状況の中、ユーザへの価値提供を最優先に考え、何を優先すべきか、どのようなアプローチを取るべきかの整理を行いました。結果、大胆なPDCAをより高速に回し、大きな改善にも容易に取り組むために、攻めと守りを両立する体制と、それに合わせたアーキテクチャの再構築を実施しました。
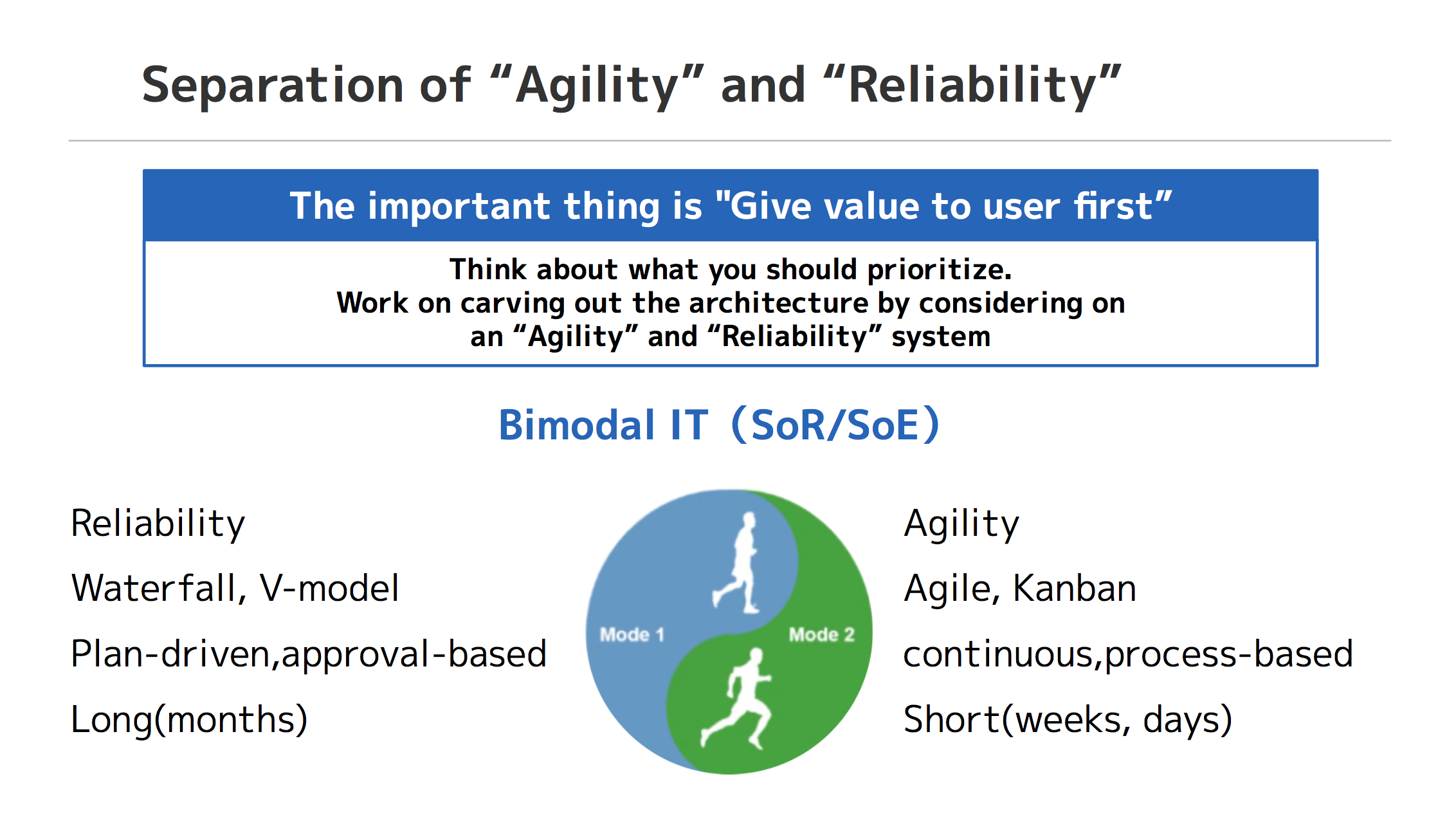
今回、旅行サービスの一部の動線を完全分離して、 UX の検証スピードを上げることに取り組んだ事例となります。
目指した方向
後半部分では、開発側の視点で我々の取り組みを紹介させて頂きました。
我々はユーザへの価値提供を最優先に考えてアーキテクチャを選択することを目指しました。どうしてもクラウドというワードが近年では取り上げられることが多い中で、私達が選択したのはハイブリッドな取り組みでした。アーキテクチャや開発プロセス・運用において、攻めと守りを分けて考え、すべて新しい言語やアーキテクチャを採用することを目指すのではなく、あくまでユーザ価値とビジネス価値を最大化するために、どのような技術を採用するのかを第一に考えました。
そこで Ruby on Rails を Google Kubernetes Engine 上で動かすというアーキテクチャを採用しました。
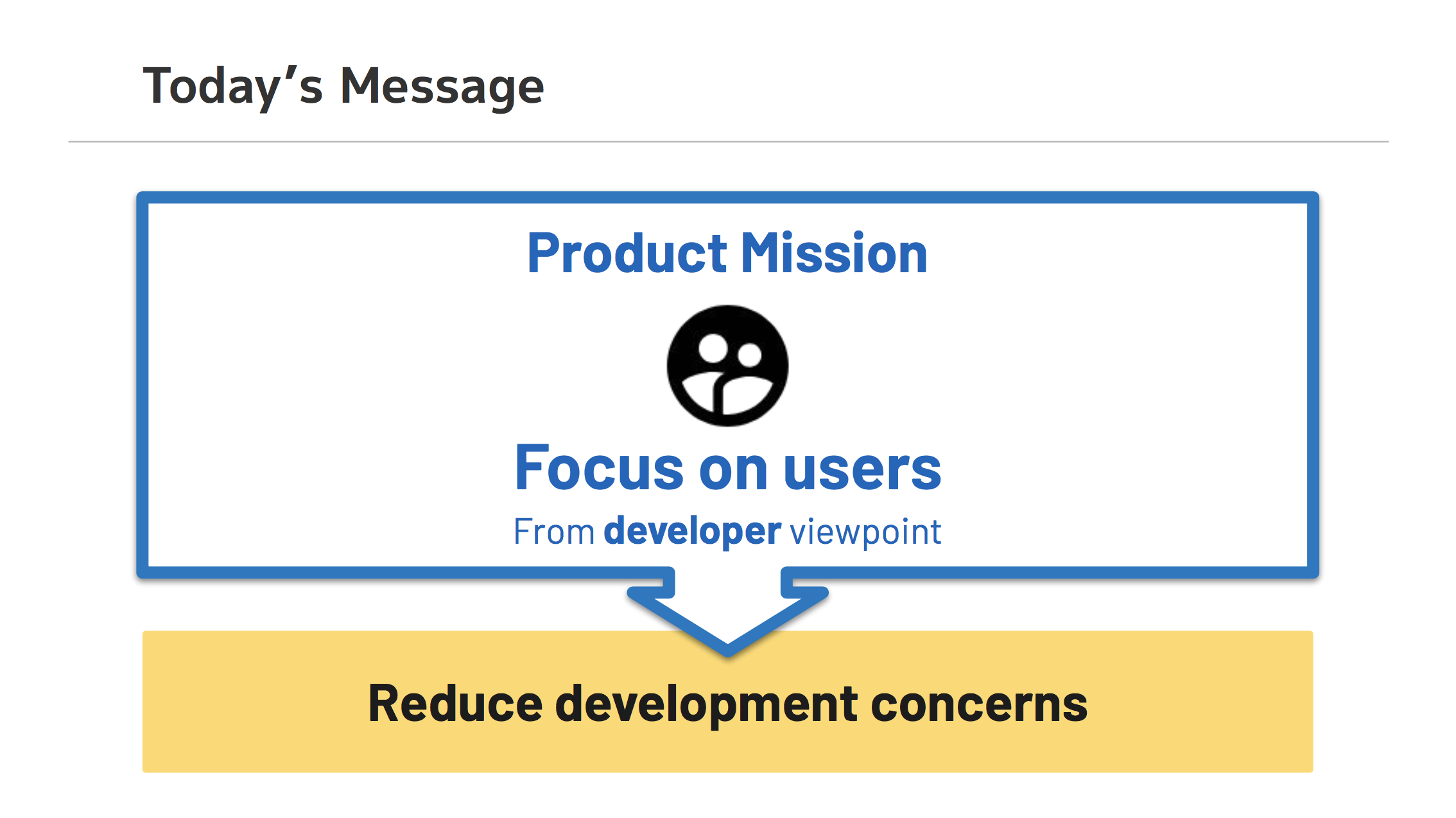
開発ミッション
どれだけユーザに集中できるかが我々のミッションで、
開発チームとしての視点に立つと、開発メンバーが Focus on Users 以外の関心事に時間や工数を取られないことがとても大切です。
価値開発の難しさと戦略
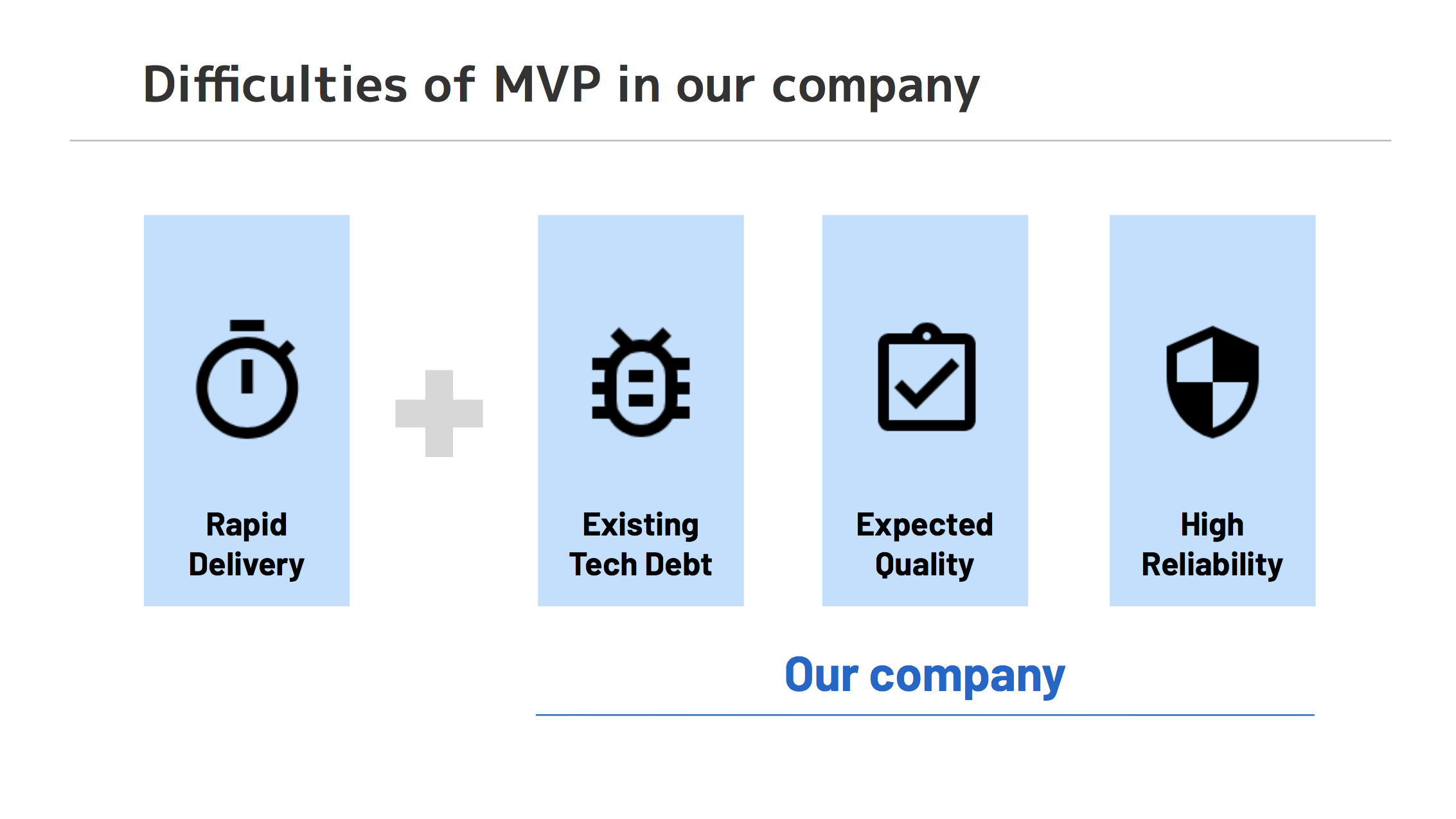
今回の取り組みは、従来の MVP 同様の
- 仮説検証を実現する高速な納品
に加え、要求水準の高い既存プロダクトの一部として開発する以上
- 既存の技術的負債の影響を受けない
- ブランドを毀損しないクオリティ
- 大規模トラフィックに耐える信頼性
といった点も求められます。
厳しい要求に答えるため、取った方針は環境の完全分離です。環境を分離することで、技術負債からの独立と既存プロダクトのデプロイライフサイクルからの独立をし、検証回数を増やすことができました。
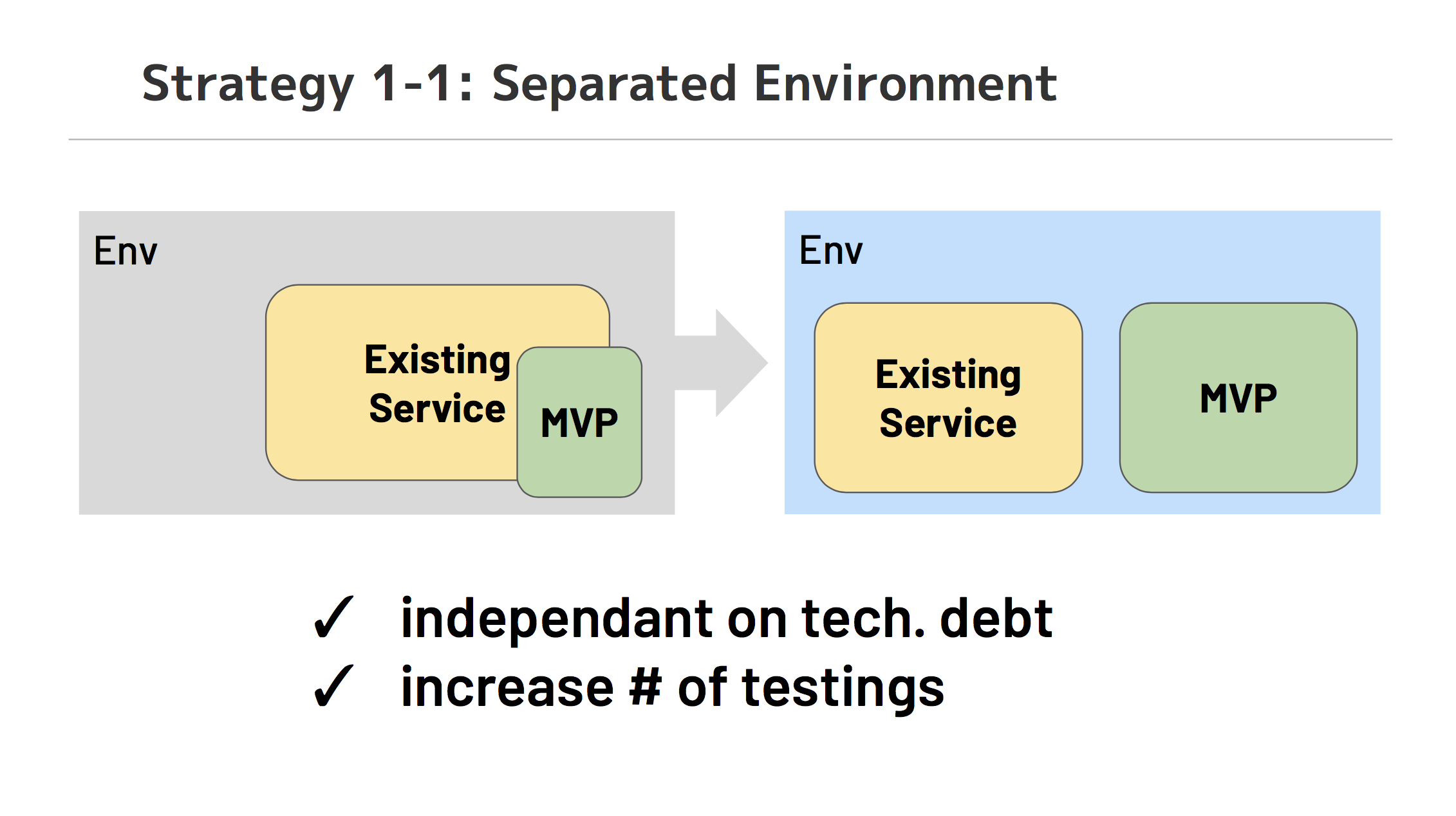
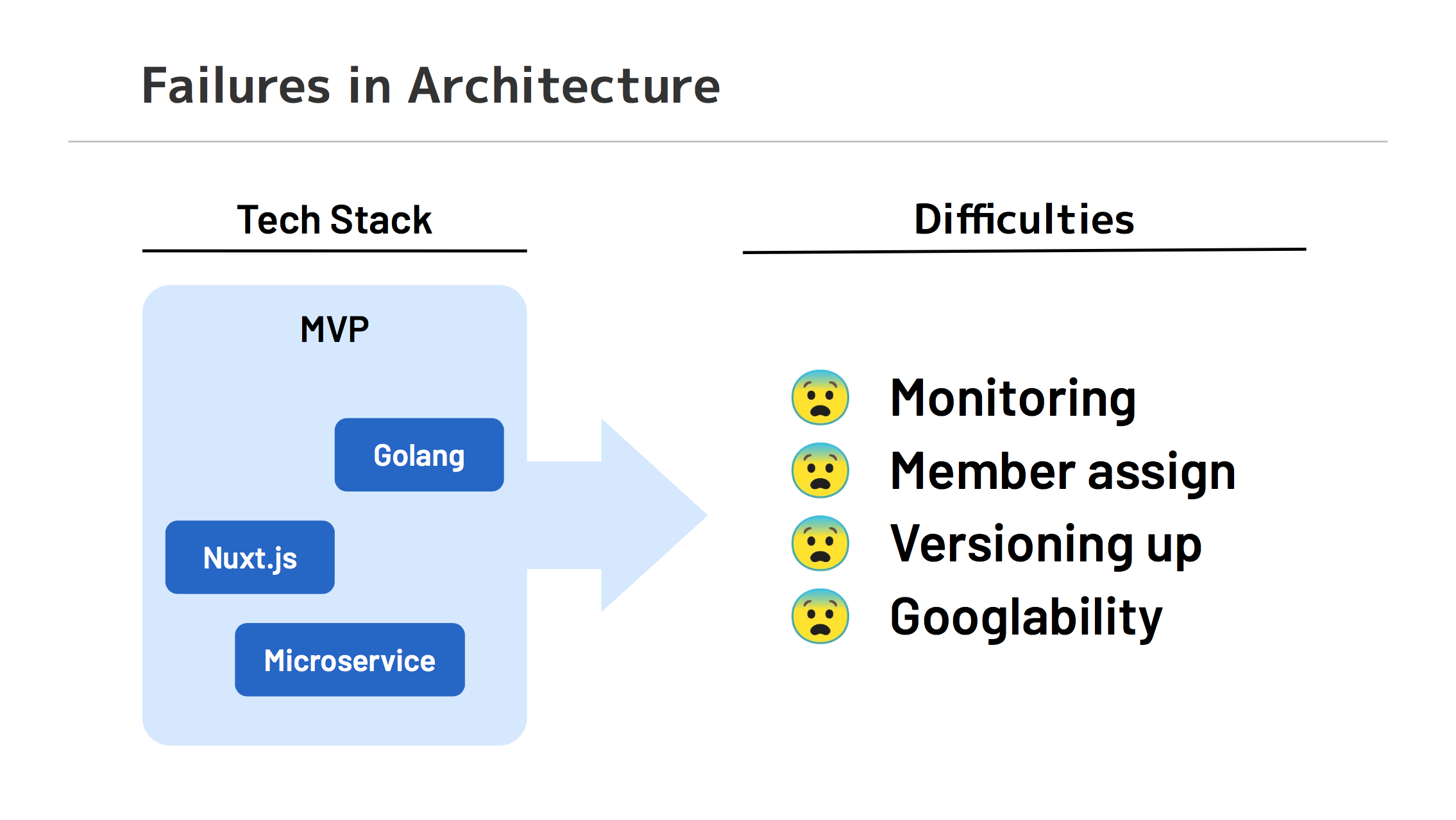
技術選定の失敗
MVP の検証の新環境を作る過程で失敗もありました。
SSR (Nuxt.js) × BFF (Express) × Microservices (一部 Go) on GKE という、技術的に攻めたモダンなアーキテクチャでのプロダクト開発もしていました。しかしそれらはチームのスキルセットに合わなかったため、以下のような反省点が出てきたのです。
- 開発速度の低下と採用難易度の上昇
- 新しい技術を採用して初期開発は完遂できていたものの、多くの開発者にとって馴染みの少ない言語であったため、機能追加が難しい、採用難易度が上がるなどの弊害が出ていました。
- 知見の少なさによる運用工数の増加
- ベストプラクティスがまだ定まっていないことから、問題が起きたときの調査対応に時間がかかり、また後方互換のないバージョンアップの追従は保守工数を増大させていました。
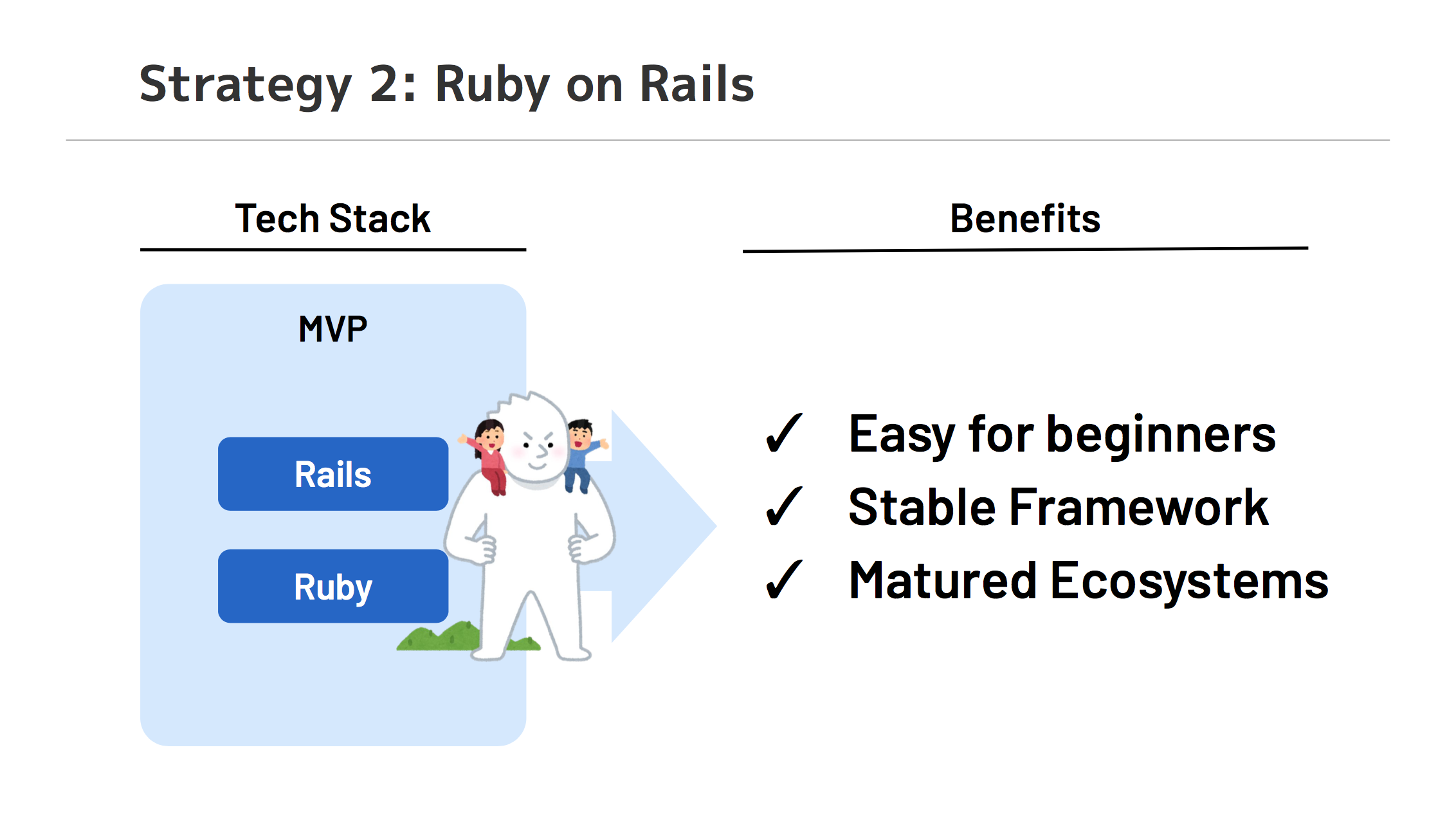
Ruby 採用での成果
信頼性を高める一方で、信頼性向上に割くパワーを最小限にするという相反する要求の落とし所が必要でしたが、 Ruby のフレームワーク Ruby on Rails はこれまで多くのサービスで取り入れられていることもあり、技術としてとても枯れているため、余計な心配がないことが大きなメリットでした。
具体的には
- ドキュメントとトラブルシューティング系の記事が多い
- ミドルウェアとの接続やその運用におけるプラクティスなど、ネット上に膨大な知見があり、初心者でも習得しやすいです。
- エコシステムが整っている
- Gem による各種パッケージが整っており、言語もフレームワークも頻繁に大きなアップデートは発生せず、EOLも長いのである程度保守工数を削減できます。
Cloud 採用での成果
AWS と GCP を使って、マルチクラウドで可用性を担保できました。
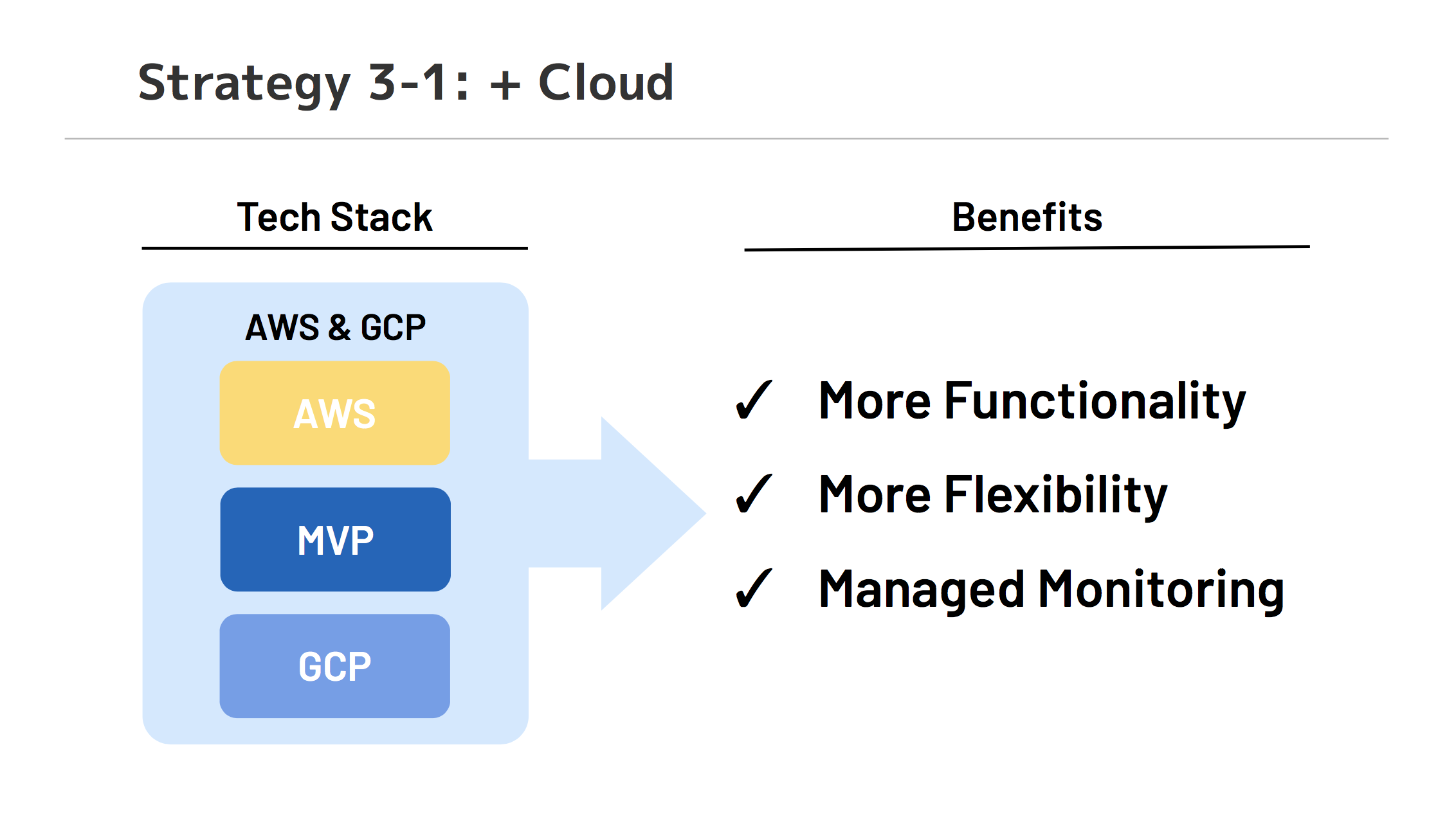
GCP ではロードバランサー全体の障害が発生すると回復の手立てがないため、 AWS の DNS フェイルオーバーを使って GCP を外形監視し、自動で障害を検知して1分以内のメンテナンスモードが発動するように実装しています。
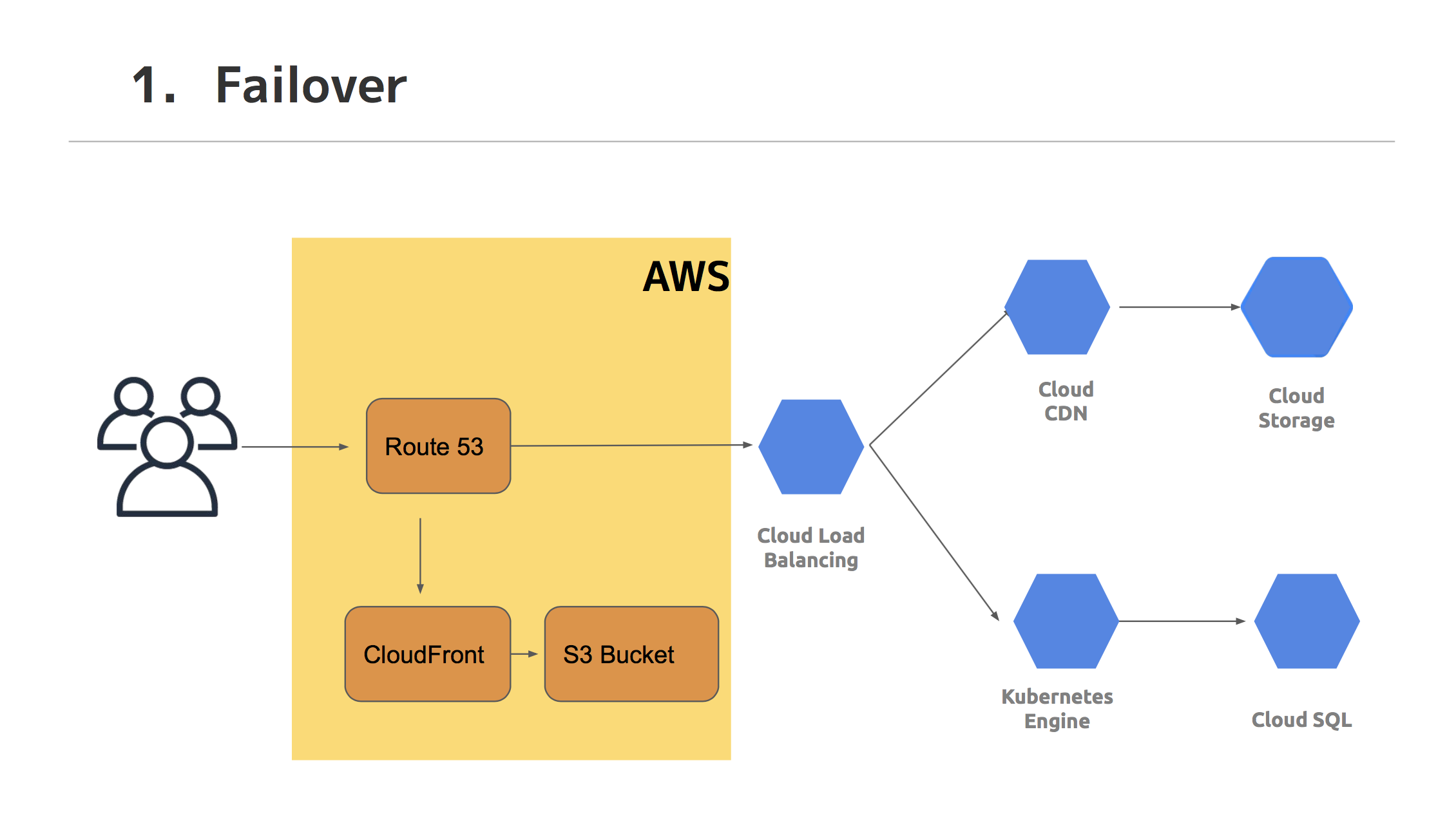
GKE オートスケーリングにより手間は大きく削減でき、予算に応じて柔軟に構成変更をすることもできています。
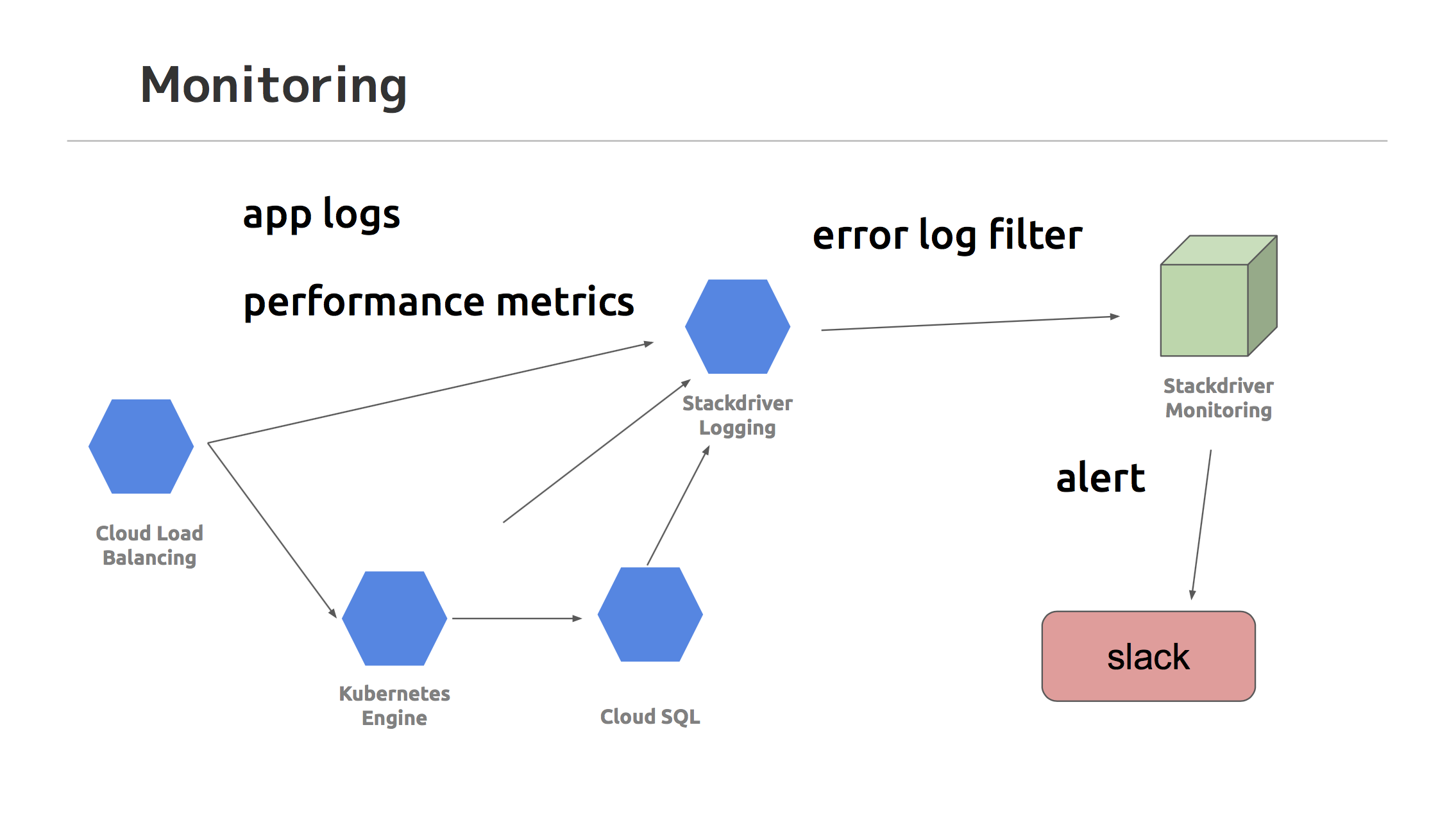
サービスのリアルタイムなアプリケーションログの検索が可能なこと、監視機能が豊富であることから、障害をすぐに検知する体制を構築できました。
デプロイ頻度が高いことから、監視系を自チームで管理することは安定運用に必須でしたが、監視系自体の保守がほとんど必要ないのは大きなメリットです。
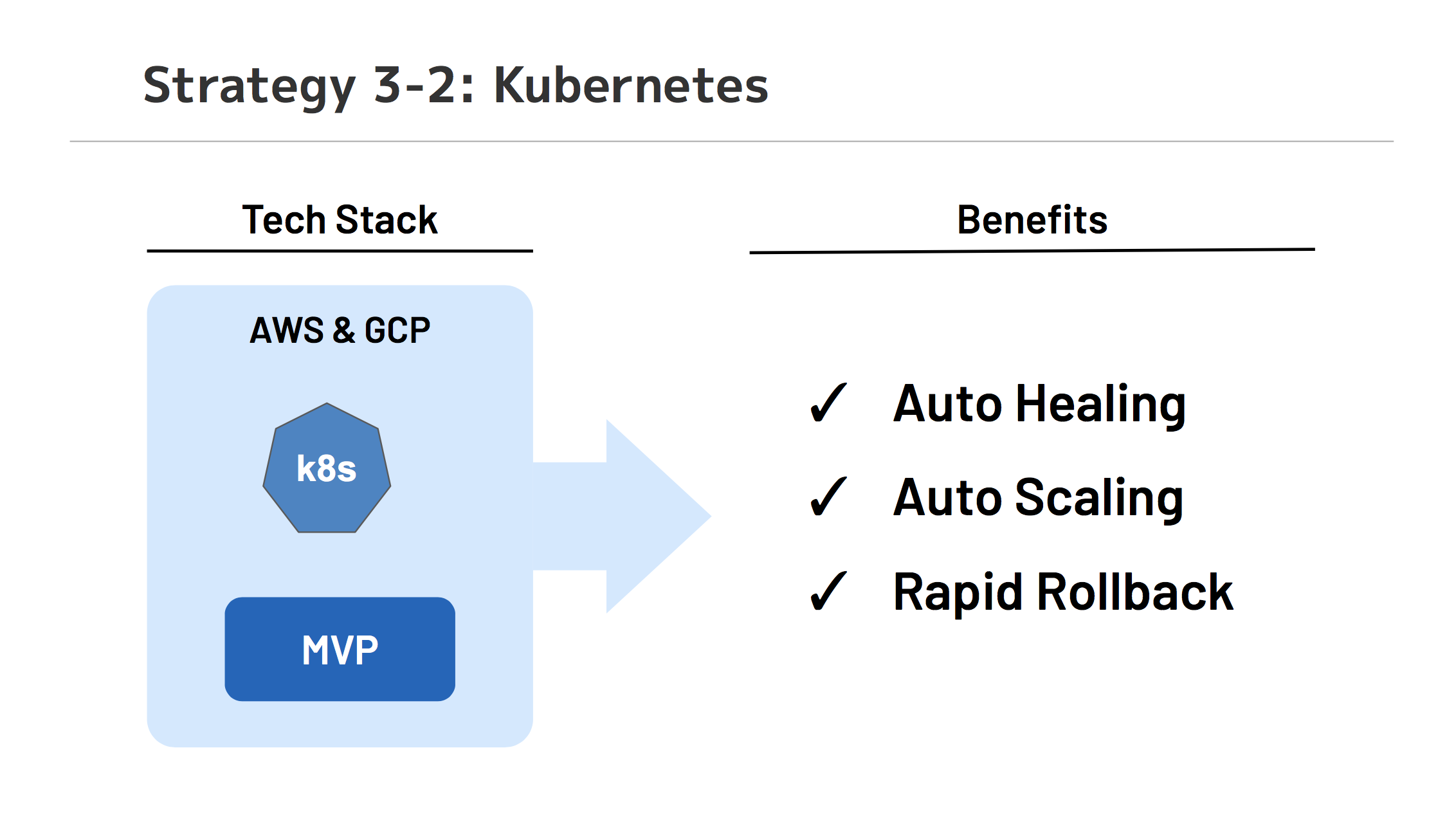
Kubernetes 採用での成果
規模の小さいプロダクトを複数作成し、さらにその構成変更が頻繁に発生する可能性を考慮すると、価値検証と Kubernetes(k8s) は相性がよいが、 Ruby on Rails on k8s の知見が少ない点でチャレンジと なりました(詳しくは、また別の記事で書こうと思っています)。
高速なスケーリングにより、負荷観点の心配が少なくなり、切り戻しもコマンド一つで行えるため、デプロイに慎重になりすぎなくてよいのも大きなメリットです。
バックアップバッチなども CronJob ですぐに開発できる、 Helm による柔軟なリソースデプロイが可能など、開発プロダクト以外で必要なものもすぐ揃えることができる点も価値検証向きであります。
まとめ
Ruby、Ruby on Rails という巨人の肩に乗ることで開発周りの懸念事項を大きく減らし、検証サイクルを高速に回せるようになりました。結果としてかなり大規模に利益貢献するような価値検証にも成功しました。
10年超のレガシーなコードベースでも、クラウドに全てを移行しようとするのではなく、ユーザへの価値提供を優先的に考え、必要な部分を最適なコンポーネント単位で切り出して少しずつ新しいことに取り組むことができるという示唆を、 Ruby on Rails ✕ Cloud ✕ Kubernetes によって得ることができました。