目次
こんにちは、CET チームの田村です。データ基盤を構築・運用したり、チャットボット(スマホ用です)を開発したりしているエンジニアです。
皆さん、実サービスで機械学習、活用できていますか?
正直、難しいですよね。高精度なモデルを作ること自体も難しいですが、実際のサービスにそれを組み込むには、そこからさらに数々の難所が待ち構えているからです。
でも、そのほとんどはエンジニアリングで解消できます。
私たちのチームでは、数年にわたる経験をもとに難所とその対処法を整理し、すばやく成果をあげられる機械学習基盤を開発しはじめました。
本記事では、この基盤の設計とその背後にあるアイデアをご紹介します(機械学習工学研究会の勉強会での発表資料がベースです)。
イテレーションを何度も回せ
基盤そのものの前に、まず機械学習を成果につなげるためのポイントを説明させてください。
私たちは、機械学習の活用において必要な業務を、次の3つに分類しました。
- データ開発 (今回はスコープ外のため深入りしません)
- 継続的なデータの収集、蓄積そして整備
- 分析・モデル開発・検証
- ステップ 1. データ探索・基礎調査
- ステップ 2. モデル作成・パラメータチューニング
- ステップ 3. 学習バッチ/API の開発・デプロイ
- ステップ 4. 実サービスでの検証(AB テストなど)
- 運用
- 継続的な学習バッチと API の運用
データ開発と運用は継続的に行うものです。いっぽう「分析・モデル開発・検証」業務はステップ1〜4を1つのライフサイクルとし、これを企画ごとに実施していく形になります。
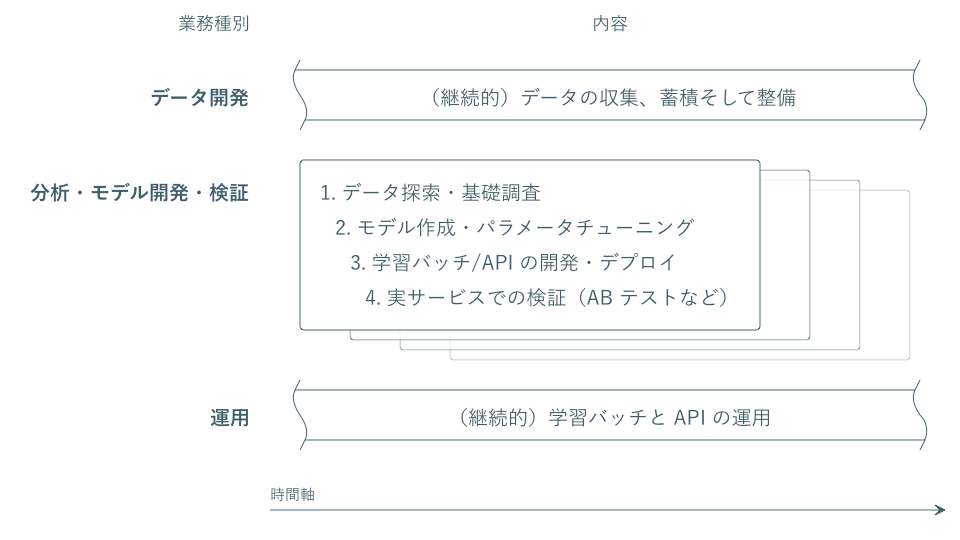
大事なポイント。このステップを1回実施したきりでは、大きな成果や学びが得られることは多くありません。螺旋階段をあがるように何度も何度も何度も何度もこのイテレーションを回し、実サービスから生きた知見を貯めていくことが不可欠なのです。
そのためには、イテレーションの1回1回をすばやく(=アジャイルに)実施できることが鍵になります。
ソフトウェアエンジニアリングと機械学習の関心を分離できるか
では、機械学習を活用する取り組みにおいて、何がすばやさを阻害しているのでしょうか。
私たちはこれまでの経験から、その原因はソフトウェアエンジニアリングと機械学習の関心の違いにあると考えています。
- ソフトウェアエンジニアリング :作ったものが現実の世界に対してどう振る舞うかに関心があります
- 例)変更に強いソフトウェアか? 大量のリクエストをさばけるのか? 単一障害点はないか?……など
- 機械学習 :ソフトウェアエンジニアリングに比べ、現実の世界そのものがどう振る舞うかにより強い関心があります
- 例)ユーザは何を見ているのか? どんなレコメンドだとクリックしたくなるのか? どんな特徴量が効くのか?……など
もちろん、この二者の間にギャップがあるのは当然なことです。しかしそれが業務フローの中で絡まったままでは、下記のような問題が生じやすくなります。
- 学習バッチ・API の開発に工数がかかる
- 「良いコード」を書くことは、分析やモデリング時点では不要ですが、実際のシステムにデプロイする際には必要になります。データ処理やアルゴリズムの複雑さもあり、この修正作業は楽々とはできません。さらに、別のメンバーが作業する場合はコミュニケーションコストも生じます。エラー処理しなきゃ! 大量の
print関数! この正規化なんでバラバラにやってるんだっけ?……etc
- 「良いコード」を書くことは、分析やモデリング時点では不要ですが、実際のシステムにデプロイする際には必要になります。データ処理やアルゴリズムの複雑さもあり、この修正作業は楽々とはできません。さらに、別のメンバーが作業する場合はコミュニケーションコストも生じます。エラー処理しなきゃ! 大量の
- 再現性が担保されない
- モデル作成時点では動いていたコードが、バッチや API の環境で同じように動くとは限りません。
pickle.loadでAttributeErrorの悪夢! - データがある時期から変わることがあるかもしれません(上流でのスキーマ変更やテーブルの洗い替えなど)。一昨日から
logテーブルのevent_typeカラムがぜんぶNULLなんですが?……etc
- モデル作成時点では動いていたコードが、バッチや API の環境で同じように動くとは限りません。
- 分析・モデル作成時に十分な計算リソースが使えない
- 基盤チームがバッチや API のインフラしか用意せず、分析はローカル PC 上でやらざるを得ないという状況も起きえます。うなる MacBook の冷却ファン!
- 作りっぱなしになりがち
- AB テストで仮設が検証でき本番導入したものは、悲しいかな、往々にしてそれっきり忘れられがちです。季節が巡り、学習データの傾向が変わり、あなたのモデルは人知れず精度低下しているかも……
これらこそが機械学習を実サービスで活用する上での難所であり、その解消なくしては、すばやく施策のイテレーションを回していくことはできません。
機械学習をアジャイルに実践できる基盤
私たちは、ソフトウェアエンジニアリングと機械学習の関心をうまく分離して、それぞれが集中すべきことに集中できるような業務フローと基盤を設計することにしました。 設計にあたっては Google の TensorFlow Extended (TFX) も参考にしています。
- 個々の施策では、小難しいエンジニアリングの話を忘れて分析・モデリング・仮説検証に集中できること
- バッチや API が安全・安定的・スケーラブルに稼働し、モデルの開発経緯などが振り返れ、なおかつ各種メトリクスを継続的にモニタリングできること
- 実施する施策数がいくら増えても、この基盤自体を運用する人数は増やさず対応できること(=運用がスケールすること)
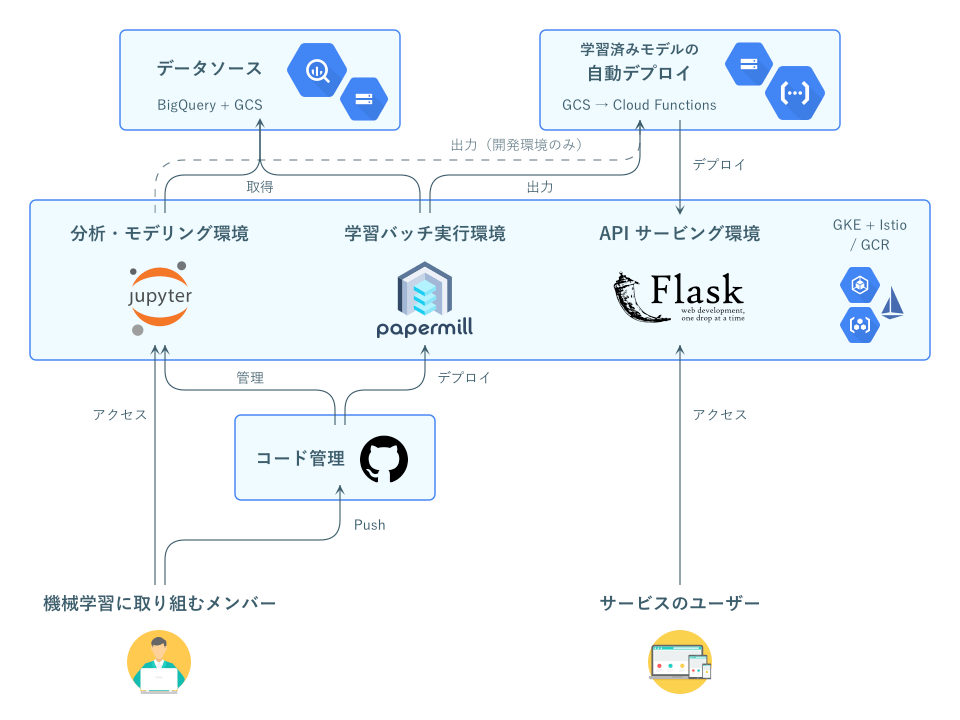
この3点を実現するため、分析・モデリング環境、学習バッチ実行環境、そして API サービング環境の3つを統一的な基盤で提供することにしました。
Icons made by Icon Pond from flaticon
なお図にあるとおり、この基盤は Google Cloud Platform (GCP) 上に構築しています。
以下、この基盤の特徴をひとつずつ見ていきましょう。
その 1. Notebook を中心に
Jupyter Notebook を業務フローの中心に据えました。分析やモデル作成時だけでなく、学習バッチでも papermill を用いて .ipynb をそのまま実行します。
これは、Netflix が “Beyond Interactive: Notebook Innovation at Netflix” という記事で紹介していた手法です。
これにより
- 分析の初期からバッチ化まで一貫したフォーマットで完遂できるようになります
- バッチコード作成の手間が極限まで減り、スピードアップ
- 分析初期から git に残すことで、企画の経緯なども一元的に記録
- 出力を同時に保存できるので、学習時の各種評価関数の値などを構造化して保存しておけるようになります
もちろん、Notebook は本来インタラクティブに試行錯誤するためのフォーマットで、バッチでの利用に適しているわけではありません。 たとえば、コードがセルに分断され実行順も保証されない、出力もファイル内に含まれるなどの問題点をはらんでいます。 このあたりの議論は JupyterCon 2018 の “I Don’t Like Notebooks” に詳しいですね。
これに関しては、ソフトウェアとしての良さ(テストしやすさ、リファクタリングしやすさなど)は業務効率とのトレードオフで多少犠牲にしつつ、いくつかの対策を考えています。
- 独自の lint ルールや I/F テストを設け、Jupyter の拡張機能として定期的に実行したりコードレビュー時に自動実行したりする
- 最低限の品質を、最低限のコストで、なおかつ早い段階から担保できます(フェイルファスト)
- コードレビュー時は同等の Python コードを自動で出力し、そちらでも diff を確認する
- 共通化できる部分はエンジニアがライブラリとスニペットを作成・提供する
- スニペットは GUI から選んで挿入できるものです(Colaboratory をお使いの方はイメージできるでしょう)
- 毎回全部エンジニアが開発に関わらないのは、早すぎる最適化を避けるためです
その 2. ランタイム環境の均一化
分析・モデリング環境、学習バッチ実行環境、そして API サービング環境は、すべて共通の Kubernetes クラスター・Docker イメージを用いて構築します。
これにより、
- コードの再現性が確保され、実行環境の差異に起因するエラーは出なくなります
- 分析初期環境からクラウド上のスケーラブルで潤沢な計算資源を活用できるようになります
- ただし適宜ノードプールを分けるなどし、負荷が波及しないようにします
なお、現在は Anaconda の公式イメージをベースにイメージを作成しているのでかなり重たいですが、今後チューニングをしてスリムアップをしていく予定です。
また、モデルの保存に通常の pickle ではなく cloudpickle を使うことで、シリアライズ・デシリアライズ起因のエラーの低減も見込んでいます。
その 3. 継続的な再学習と自動デプロイ
モデルはすべてバッチによって継続的に再学習・自動デプロイされ続けます。
仕組みとしては、
- 登録された Notebook を実行し、データのバリデーションとモデルの学習を行う
- この際、学習に使ったデータのスナップショットをバージョンをつけてストレージ (GCS) に保存
- 学習済みモデルと papermill の出力 Notebook をストレージにアップロード
- GCP Cloud Functions がそれを検知し、自動的に API サービング環境にデプロイ
といった流れで行われます。
これにより
- 異常な精度低下など、学習結果に応じて柔軟に対応できます
- 開発者にアラート通知できます
- デプロイするかどうかを制御できます(過去のデプロイ履歴も含めて判断可能)
- メトリクスを継続的に記録でき、時系列変化をあとから振り替えられるようになります
- ノイズや季節トレンドに対するモデルの頑健性が可視化できます
- 特定のリビジョンのモデル・学習データが復元できるようになります
- 特定の入力に対する予測値を、過去のバージョンと現在のバージョンで比較したりできます
- 障害発生時に学習を再現し、原因究明に役立てられます
これらは AB テストも本番運用も区別なく行われるので、あなたがモデルのことを忘れてしまっても問題ありません。
その 4. 疎結合なアーキテクチャ
メインとなる3つの環境(分析・モデリング、学習バッチ実行、API サービング)は密に統合されていますが、それを取り巻くエコシステムは疎結合なアーキテクチャになっています。
たとえばモデリングフェーズで作った Notebook は直接バッチサーバにデプロイできるわけではなく、GitHub を起点にデプロイが行われます(ただし例外として、動作確認を簡単にするため開発環境のみでは直接デプロイできるようにしています)。同様に、バッチで学習したモデルは直接 API サーバにデプロイされるわけではなく、GCS を介して自動デプロイシステムがデプロイを行います。
これにより、
- 負荷の分離ができ、スケーラブルで障害に強くなります
- 個々のパーツを簡単に別のパーツに入れ替えることができます
想定される質問と回答
Q. この基盤では扱えない機械学習はあるの?
この基盤は下記2つのユースケースをカバーしていません。
- リアルタイムのストリームデータを用いた学習
- 現状では GCP の Cloud Dataflow(マネージド Apache Beam)を使ったシステムを都度開発しています
- 分散学習(1台のサーバでは乗り切らない・学習時間が許容できないレベルの学習)
- 現状では GCP の Cloud ML Engine (マネージド TensorFlow)を使ったシステムを都度開発しています
当面はこれらに対応する予定はありません。
Q. なぜ xxx を使わないの?(例:Kubeflow, Cloud ML など)
“xxx” に何が入るにせよ、だいたい以下のいずれかが答えになります。
- 独自のイメージを使いたいからです
- 環境の共通化のため
- 「〇〇ライブラリを使いたい」といった要望に答えるため
- Jupyter に共通の lint やスニペット提供のための拡張機能をインストールするため
- 私たちのチームでは TensorFlow よりも scikit-learn や XGBoost がよく使われているからです
- GitHub でコード管理し、それを起点に継続的インテグレーション・継続的デリバリーを行いたいからです
- オンライン予測で十分なリクエスト数をさばく必要があるからです
あてはまる答えがありませんでしたか? であれば、私たちがそのソリューションを見逃している可能性があります。ぜひ教えてください。
おわりに
以上、私たちが現在開発中の機械学習基盤のご紹介でした。
この基盤はまだまだ開発途上ですが、まずは MVP レベルのアルファ版がそろそろ稼働開始します。 きっと MLOps におけるひとつの答えになるのではないかと思います。
実際の企画での採用が増えないと分かりませんけどね。
この基盤がどれだけの効果をもたらすのか、自動デプロイなどの個々のパーツがどう実装されているかなどは今後のブログで公開していく予定です。 続報をご期待ください。 そして同業者の皆さま、意見・情報交換しましょう。
いっしょに開発しませんか?
私たちは、一緒に働く仲間を絶賛募集中です。
この記事を読んで、この基盤の開発に携わりたい、あるいはこの基盤を使って機械学習で成果を上げたいと思ったあなた。 下記の Wantedly、筆者の Twitter、フッターから飛べる中途採用ページのいずれかからご連絡ください。 お待ちしております。