目次
ビューティ事業ユニットでエンジニアをしている索手です。 1月まではAndroidを担当していましたが、今ではバックエンドを担当しAPI開発を行っています。
今回は昨年行ったホットペッパービューティーのアプリリプレイスについて、Androidチームで採用した技術や実装方針についてお話ししたいと思います。
プロジェクトの背景
ホットペッパービューティーのネイティブアプリは、約6年間、様々な機能追加・変更を経る中で多くの技術的負債が溜まっていました。一方で、事業におけるアプリの重要度は高まっており、今後の更なる成長を見据えると、当時の状態で開発を続けることは困難でした。
そのような背景があり、アプリリプレイスがスタートしました。
プロジェクトの概要
本プロジェクトは、「安定かつ高速な開発」を目指し、仕様はそのままにネイティブアプリのコードを全て書き換えるというものでした。ドキュメントや既存のコードから仕様を読み取り、各機能を一から実装します。
仕様を変えられないため、技術スタックにはある程度の制約が存在します。UI周りのライブラリであったり、ログ計測ツールなどのライブラリはなかなか変えられません。逆に言えばそれ以外の技術選定は0ベースで進められます。
以降ではAndroidチームが採用した技術や実装方針のうち、開発言語、アーキテクチャ、テストについてお話しします。
開発言語
開発言語としてKotlinを採用しています。採用当時(2017/02)はまだGoogle非公認の言語でしたが、言語としての優位性、Javaとの互換性の高さ、Androidサポートの充実度等を理由に採用を決めました。
Kotlinの言語機能の中でもインパクトが大きかったのはNull安全性とDelegated Propertyだと思います。それぞれどのような効果があったのか簡単にご紹介します。
Null安全性
私はNull安全性のある言語でコードを書くのは初めての経験でした。採用前は「NPEを減らすことができる」程度にしか考えていませんでしたが、今では可読性への影響も大きい性質だと考えています。例えば以下のような形で可読性に影響しています。
- 値のNullabilityが明示されることで、考慮すべきケースを瞬時に判断できる
- NonNull状態を維持するために引数で値を渡すようになり、メンバ変数などを安易に経由しないようになる
Delegated Property
Delegated Propertyはプロパティの取得、更新処理を委譲するための仕組みです。Androidはこの機能が活きる場面が多く、私たちのチームでは以下の場面で活用しています。
- Activity Extra, Fragment Argumentsの取得
- Instance Stateの取得・更新
- SharedPreferencesの取得・更新
- Firebase RemoteConfigからのABテストケースの取得
例えば、Activity Extraで言うと以下のようなPropertyクラスを作って、利用しています。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
private object UNINITIALIZED_EXTRA
fun <T> extra(key: String? = null) = object : ReadWriteProperty<Activity, T> {
var extra: Any? = UNINITIALIZED_EXTRA
override fun getValue(thisRef: Activity, property: KProperty<*>): T {
if (extra == UNINITIALIZED_EXTRA) {
extra = getExtra(thisRef, key = key ?: property.name)
}
return extra as T
}
override fun setValue(thisRef: Activity, property: KProperty<*>, value: T) {
extra = value
}
}
class SampleActivity : AppCompatActivity() {
val sampleString: String by extra(key = "sample")
// ...
}
このようなPropertyを作ることで以下の恩恵を受けています。
onCreateでのextra.getStringExtra("sample")という記述を省略できる- プロパティがExtraから取得される値で初期化されることがひと目でわかる
- プロパティを
valで宣言できる(lateinit varを使わなくて済む)
以前 shibuya.apk でも同様の内容を発表しましたので、興味がありましたらご覧ください。
Kotlin’s Delegated Properties × Android by Ippei Nawate
アーキテクチャ
「安定かつ高速な開発」を実現するためには、自動テストと見通しの良いコードが必要だと考えました。自動テストを書くためには、モジュールのテスタビリティを確保する必要があります。見通しの良いコードを実現するためには、モジュールごとの適切な責務分割が必要です。そして、それらを一貫して実現するためには、アーキテクチャの設計が重要になります。
私たちのチームでは、アーキテクチャは以下の観点を持って設計を行いました。
- 責務ごとにモジュールを分割し、コードの見通しとテスタビリティを改善すること
- ビジネスドメイン関わる実装を他の実装から独立させ、ビジネスドメインを明確にすること
- データソースとそれを扱うコードの間に腐敗防止層を敷き、ドメインをクリーンな状態にすること
結果、このような3層構造のアーキテクチャを採用しています。
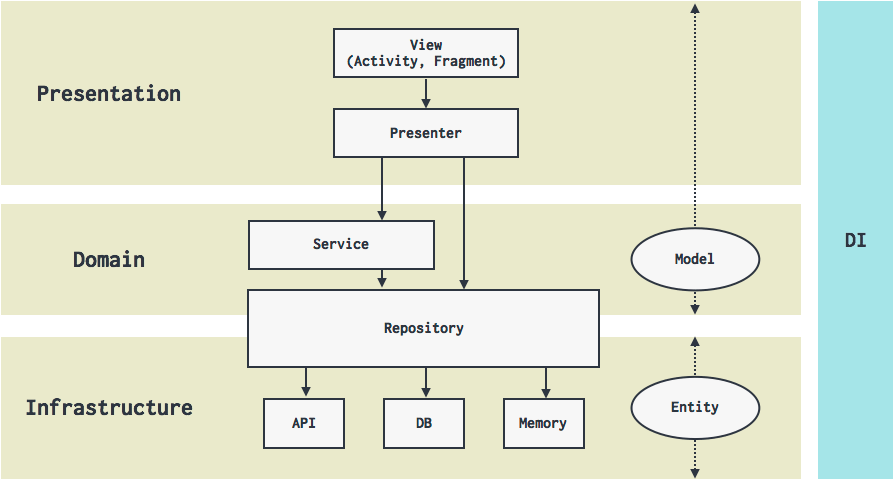
各層、各モジュールの概要を以下にまとめます。
| 層 | 概要 |
|---|---|
| Presentation | ・UIの描画、画面遷移、ユーザインタラクション制御 ・ログの計測・ABテストケースの取得 |
| Domain | ・ドメインオブジェクトやサービスを通じた、ビジネスルールの定義 ・ドメインオブジェクトの永続化インターフェースの定義 ・Android SDKへの依存を持たない |
| Infrastructure | ・ドメインオブジェクトの永続化 ・実データからドメインオブジェクトへのマッピング(腐敗防止層) |
| モジュール | 概要 |
|---|---|
| View | ・いわゆるActivity, Fragment ・MVPのViewとは異なり、プレゼンテーションロジックも持つ ・Domain層へのアクセスはPresenter経由で行う |
| Presenter | ・ドメイン層へのアクセス ・Viewの持つロジックの委譲先 |
| Model | ・ドメインオブジェクト |
| Service | ・複数のModel、Repositoryを横断するビジネスロジックの提供 |
| Repository | ・永続化されたModelに対するCRUDの提供 ・EntityからModelへのマッピング |
| Entity | ・実データ(RDBのレコード、JSON)構造を表すPOJO(※ 紛らわしいですが、ドメインオブジェクトのEntityとは異なります) |
ViewとPresenterの責務が一般的なMVPとは異なりますが、この経緯については後述します。
アーキテクチャの評価
よかった点
DIコンテナ
今ではAndroid界隈で当たり前になっているDIコンテナ(Dagger)の採用ですが、改めて効果的だったと感じています。DIPの実現はもちろんのこと、依存関係解決を一手に担ってくれることから、心置きなくモジュール分割を進めていくことができました。
また、dagger.Component、dagger.Moduleを差し替えるだけで依存ツリーの書き換えがでるようになったため、プロダクションコードと開発用のコードを分離することができ、コードの見通し改善にも大きく寄与しています。
腐敗防止層
アプリが利用しているAPIは、アプリ同様長い期間を経てレガシーになっていました。例えば以下のようなケースがありました。
- 文脈の異なる複数のモデルが同時に返却される
- 1つのModelを構成するために複数のAPIを呼び出す必要がある
- レスポンス構造が複雑で、パーサーによる変換が困難
そうはいっても、アプリと同時にAPIを作り直すわけにはいきません。このような経緯があったため、腐敗防止層の設置を決めました。
先程のアーキテクチャ図上ではRepositoryが腐敗防止層としての役割を果たしており、内部は以下のような構造になっています。
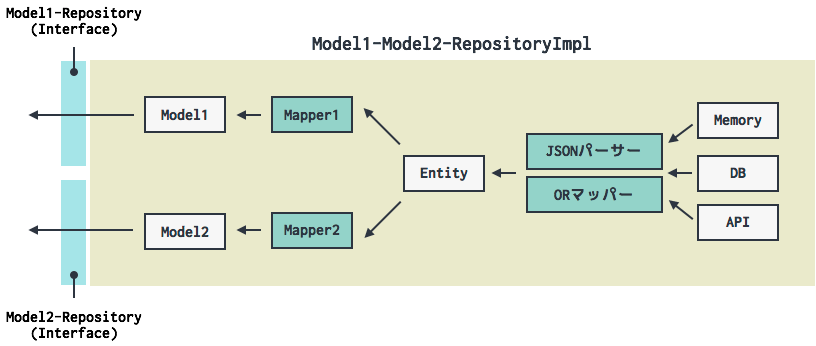
Repositoryはインターフェースと実装クラスでわかれています。インターフェースは基本的にModelと1:1で対応し、実装クラスは複数のインターフェースを実装することがあります。これは先に述べた1.の問題を解決しています。データソースがModel1とModel2を同時に返却しても、Repository利用者はインターフェースに依存することで、片方のModelを返却するRepositoryとして透過的に扱うことができます。以下は簡単な実装サンプルです。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
interface Model1Repository {
fun fetchModel1(): Single<Model1>
}
interface Model2Repository {
fun fetchModel2(): Single<Model2>
}
class Model1_Model2RepositoryImpl: Model1Repository, Model2Repository {
// 使わないほうのModelは、取得時にキャッシュして返します
fun fetchModel1() = fetchModel1AndModel2().map { it.model1 }
fun fetchModel2() = fetchModel1AndModel2().map { it.model2 }
}
// 利用する側はインターフェースに依存する(Modelが同時に返却されることを意識しない)
class SamplePresenter(val model1Repository: Model1Repository) { ... }
Modelは実データから直接変換されるわけではなく、間にEntityとMapperを挟みます。これは2, 3の問題を解決しています。2.の問題は、複数のEntityを取得した後、マージして1 つのModelを作ることで解決しています。3.の問題は、変換処理をKotlinで記述し、より柔軟な変換処理を行うことで解決しています。そのほか、この機構は単一テーブル継承(STI)の実現にも一役買っています。以下はSTIを実現するMapperのサンプルです。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// Entity - ORマッパーでマッピングされる
class Entity(val id: Long, val name: String, val model2Category: String?, val type: Type) {
enum class Type { Model1, Model2 }
}
// Mapper
class Mapper {
// Entity#typeによって戻り値の型を切り替え、より意味的なコードを記述できるように
fun mapToModel(entity: Entity): Model = when(entity.type) {
Type.Model1 -> Model1(entity.id, entity.name)
Type.Model2 -> Model2(entity.id, entity.name, entity.model2Category)
}
}
// Model
sealed class Model(val id: Long)
class Model1(val id: Long, val name: String): Model(id)
class Model2(val id: Long, val name: String, val category: String): Model(id)
Domain層
この層を設けるにあたり、以下のことを意識しながら開発を進めてきました。
- ドメインオブジェクト(Model)の「振る舞い」をそのクラスのメソッドとして定義すること
- 可能な限り扱うデータをクラス化し、制約等をコードで表現すること
執筆時点でModelが約200個あるのですが、それらが1つのパッケージ配下にまとまっています。これによって、自分たちが扱うビジネスドメインを俯瞰しやすくなったように感じます。技術的な面でも、重複コードの排除、ビジネスロジックのテスタビリティ向上、コードの可読性増などの恩恵を受けています。
アプリの特性上、ビジネスロジックの多くがAPI側にあり、層そのものは薄いのですが、それでも意義は大きかったと感じています。
難しかった点
Presentation層のアーキテクチャ選定
プロジェクト開始当初はPassive View型のMVPを採用していたのですが、プロジェクト途中でアーキテクチャの転換を行いました。これはプロジェクトのリソースや期限的制約、アプリのプレゼンテーションロジックが少ないなどの理由から、アーキテクチャの冗長性を許容できなかったことが要因です。そのような経緯もあり、現在は上図・表のような形に落ち着いています。
MVP自体は素晴らしいアーキテクチャですが、ホットペッパービューティーのアプリとは相性が良くありませんでした。今思い返すと、ただ流行りのアーキテクチャ採用するというミーハー的考えに囚われ、コード以外の要因(人、時間、システム特性 etc…)を考慮できていなかったのだと感じます。
ドメイン理解
DDDで言う戦略的設計を省略してしまい、ドメイン理解には苦労しました。まず、ドメインエキスパートを確保しなかったため、アドホックに有識者に当たらざるを得ず、個々の開発者が独自の解釈でコードを書いては手戻るということが起きていました。ユビキタス言語も構築しなかったため、開発者間で用いる命名が異なっていたり、元のコードにある不可解な命名をそのまま用いてしまい、それを都度レビューで議論するということが起きていました。
問題が起こるごとに話し合いながら進めはしたものの、効率は悪く、準備不足を痛感しました。ドメインは徐々に明らかにしていくものと言いますが、最低限の事前準備は必要だと学びました。
テスト
ユニットテスト
テスト対象の選定
安定したアプリを高速に改善していくためには、自動テストが不可欠です。 一方で、テストはいかに効率よく、重要な機能を網羅するかが重要になります。 私たちはモジュール毎の優先度を定め、優先度の高いものからテストを書いていきました。 優先度は、将来的な変更頻度、内包するロジックの複雑度、インターフェースのテスタビリティを元に判断しています。
| 対象 | 変更頻度 | 複雑度 | テスタビリティ | 優先度 |
|---|---|---|---|---|
| Presenter | 高 | 高 | 低 | 低 |
| Service | 低 | 高 | 高 | 高 |
| Model | 低 | 中 | 高 | 高 |
| Repository | 中 | 中 | 中 | 中 |
※ 先述のとおり、Presenterは独自形式でありテスタビリティは低いです。
テストフレームワーク
テストフレームワークはSpekと、JUnitの2つを使い分けています。基本的にはSpekを使い、DBアクセスを要するテストのみJUnitをRobolectricと組み合わせて使用します。Spekのv1.1.x時点ではRobolectricと組み合わせることができないため、このような方針を採用しています。2つのフレームワークが混在することはわかりにくいように思えますが、後者を利用したテストは全体の20%程度であり、今のところ影響は少ないです。
Spekはまだ新興のフレームワークであり、採用は少しチャレンジングでしたが、テストの可読性やパラメタライズドテストの容易さが魅力で採用を決めました。あくまでテストであり、プロダクトへの影響も小さいというのも背景です(同様の背景で、Kotlinの導入もテストから…という方は多いと思います)。Spekの知見を以前発表していますので、もし興味がありましたらご覧ください。
UIテスト
私たちのチームでは「"ゆるい"UIテスト」というものを実施しています。Spoonを利用してActivityのスクリーンショットを取るだけのテストですが、PRがマージされる毎にUIの変化を検知・閲覧できるため非常に便利です。実現にはDIコンテナを利用したAPI等のモックが必要であり、これもリプレイスの成果だと言えます。
弊社の中里がこのテストについての記事を書いていますので、もし興味がありましたらご覧ください。
AndroidアプリのゆるいUIテストをSpoonで実現する
まとめ
本記事ではホットペッパービューティーのAndroidチームにおける、Kotlin、アーキテクチャ、テスト事情について紹介しました。
この中でもKotlinの早期採用はプロダクトへの影響にとどまらず、R.ktという勉強会の開催であったり、DroidKaigiを始めとした外部での発表へも繋がっており、ブランディング面でも効果を発揮しています。
リプレイス以後の開発状況を説明すると、目に見えて開発速度・安定性が向上しました。開発速度については、むしろ案件創出が追いつかないという嬉しい悲鳴が出てきています(空いた時間はリファクタリングに当てています)。安定性についても、QAチームから「QAフェーズで報告するバグ数が明らかに減った」という意見が出ており、定性的ではあるものの大きな効果を実感しています。
Android界隈の技術の進化は早く、トレンドに追いついたと思ったら置いていかれているということも日常茶飯事です。リプレイスしている間にもAndroid Architecture Component、android-ktx、Coroutineといった技術が台頭してきています。ホットペッパービューティーのAndroidチームでは、こういった技術も積極的に取り入れながらプロダクトの改善に取り組んでいきます。
最後になりますが、リクルートライフスタイルでは一緒に働ける仲間を募集しています(´◔౪◔)۶