アドバンスドテクノロジーラボの塩澤繁です。
今回は、ビルの高層階やドローン飛行中の撮影映像から、人間や自動車を、リアルタイムにAIで自動検知させる手法をご紹介させて頂きます。
※本取り組みは、1年以上前の取り組みですが、本件の特許出願の関係で記事化が遅くなりました
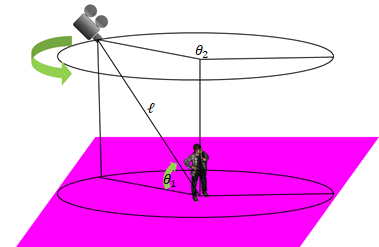
本取り組み当初、上空20~40m程度上空から人を見下ろしたイメージ収集に非常に苦戦をしました。
そこで、3DCG技術と深層学習技術を用い、教師データを大量に人工的に生成しています。
大まかな仕組みは下記の通りです。
1.3DCG利用による元教師データ生成
モデリングデータとカメラパラメータ設定により、自動で、角度と人種、服装、ポーズを変えながらレンダリングした1万枚の人間イメージを生成
2.深層学習による教師データ増殖
GAN(Generative Adversarial Network)により、1のイメージのバリエーションを46倍に増殖
3.深層学習による人、乗り物検知
YOLO(You Look Only Once)を用い、2.データの学習ならびに映像解析
それでは、1つ1つ解説をさせて頂きます。
1.3DCG利用による元教師データ生成
教師データとして「現実世界」の写真を一切使用せず、教師データを生成するため、三次元コンピュータグラフィックスを利用して、人型ポリゴンをレンダリングする。今回は、素材屋さんから入手可能だった、外国人風のモデリングデータを利用しました。上空40m程度という距離感と後続処理の関係で、日本人も外国人も大して差は無くなるので、問題ないと思い採用しました。

あたかもドローン(上空)から撮影したようにカメラ位置や角度(θ1の範囲を20度~80度)に制限を設け、ランダムで変化させながら、各ポーズをレンダリングしていく。
【人型ポリゴンレンダリング結果画像】
上空から撮影した人を模して、3DGCでレンダリングした画像。
GANの入力データとして使用する。後処理の効率化のため背景は単一色としました。

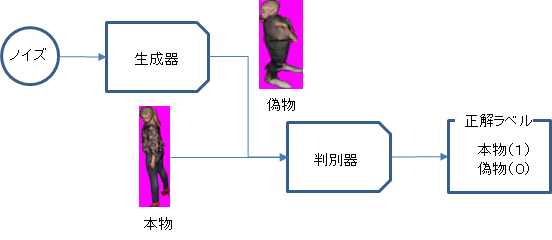
2.深層学習による教師データ増殖
ここでは、ポーズ、衣服、肌や髪の色にも多様性を持たせるべく、敵対的生成ネットワーク(GAN)を利用した教師データを46万件生成します。 ご存じの方も多いとは思いますが、GANは2018年暮れにイギリスのオークション、サザビーにてAIが描いた絵画の高額落札価格で話題になった技術です。
GANの概要
今回は、以下の2つのモデルの訓練を同時に進め、自動で互いに競わせました。
・生成器(Generator):ランダムノイズを入力として、識別機が誤ってサンプル(OpenGLのレンダリング画像)であると認識する率を高めることを目指して、学習しながら画像を生成する。
・識別機(Discriminator):生成したいサンプルと生成器の出力画像を正しく鑑別できることを目指して、学習しながら識別する。
【生成教師データ】
人型ポリゴンのレンダリング結果をGANへ入力して得られた画像。
これをCNNの学習用教師データとして利用します。

3.深層学習による人、乗り物検知
畳み込みニューラルネットワーク学習済みモデル。
既存の画像認識のアルゴリズムの「DPM」や「R-CNN」は、画像の領域推定と分類が独立しており、処理が複雑で、かつ処理時間も長くなりがちでした。本研究では、画像認識を回帰問題に落とし込み、「画像の領域推定」と「分類」を同時に行うことができる「YOLO」で実現しました。詳細についてはYOLOサイトを参照してください。
今回のプロセスを経て、最終的に上空からの人を検知できる様になったサンプル動画です。
個人情報保護や機密情報保護の関係で、実際のドローン映像ではなく、たまたま手元にあったビル上空からの映像を利用し、人よりも車が多い映像になっています事を、ご了承下さい。
今回のスキームを利用する事で、入手しづらい教師データイメージや、この世に存在しないイメージの大量生成が可能になりますので、例えば、海で溺れている人のデータを3DCGで製作し、AIモデルを開発する事によって、救難救助AIに利用する等も可能になります。
教師データが少ないから諦めていた方には、本スキームがお奨めです!