目次

1. はじめに
こんにちは!データ推進室2025年度新卒の椎名・杉山・町塚です。 新人研修の様子を紹介するブログシリーズ、今回は「DevOps研修」についてお伝えします。本研修は2日間の構成で、1日目がDev編、2日目がOps編でした。今回は、Ops編をご紹介します。
研修の目的
研修全体で、「クラウド環境におけるDev(開発)とOps(運用)を擬似体験することで、配属後に開発/運用タスクをいきなりアサインされても戸惑わない(やればできる)マインドセットを獲得すること」が目的でした。
研修の概要
Ops編は、パフォーマンスチューニング演習と障害訓練の二部構成で実施されました。
午前のパフォーマンスチューニング演習では、負荷試験ツールを使ってサーバーに負荷をかけた上で、ボトルネックを特定し、性能改善のための取り組みを行いました。午後の障害訓練では、運営側が故意に発生させたさまざまな障害に対し、原因究明から復旧までの一連の流れを体験しました。詳細は各パートをご覧ください。
2. パフォーマンスチューニング演習
午前のパートでは、負荷試験(性能試験)と呼ばれる試験を実施しました。
座学パート:パフォーマンスのボトルネックと解決策
講義を通じて、ロードバランサー、VM、データベースなど、システムを構成する多くの箇所がボトルネックになる可能性があることを学びました。
また、ボトルネックの原因に対し、性能の良いマシンに変える「スケールアップ」、ノード数を増やす「スケールアウト」、効率の良い処理に変える「チューニング」といった解決策があることを学びました。
なお、スケールアップやスケールアウトは基本的にコスト増を伴うため、ボトルネックでない場所を増強しないよう、費用対効果を慎重に判断する必要があることも知りました。
演習パート:データベース(PostgreSQL)の性能改善
演習パートでは、座学パートで学んだことをもとに、パフォーマンスチューニングによってサーバー負荷を軽減させる取り組みを行いました。
今回は研修用のサービスサイトに対し、Webブラウザから操作できる負荷試験ツール Locust を使用して、システムに大量のリクエストを送りました。
対策のため、まず、遅いクエリをCloud SQLの"Query Insights"で特定しました。
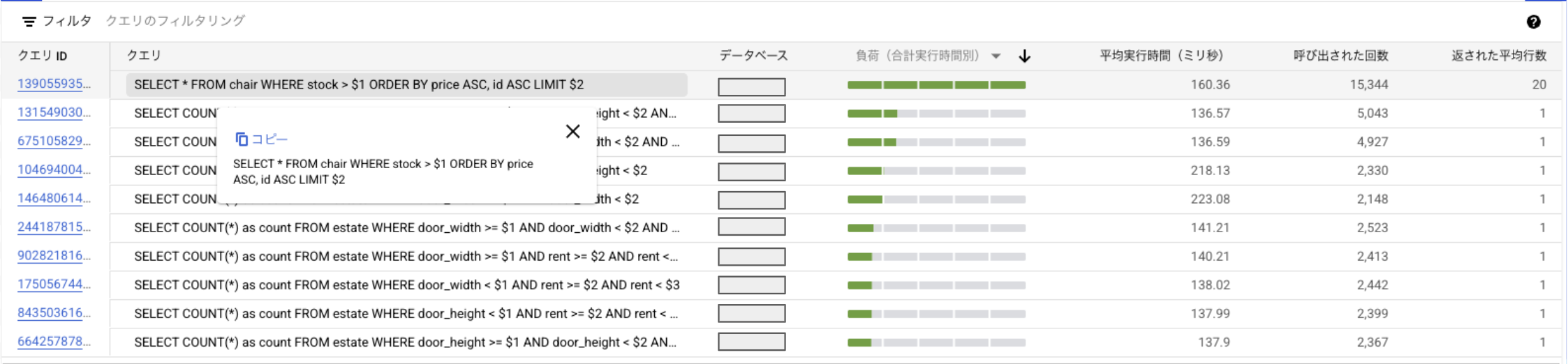
Query Insightsの結果から、平均実行時間が比較的長く、呼び出し回数も最多のクエリを特定できました。私たちはこのクエリが最大のボトルネックであると仮説を立てて調査を行いました。
まず、PostgreSQLの EXPLAIN コマンドを使用して、このクエリの実行計画(クエリがどのように処理されるかの設計図)を確認しました。すると、テーブルの全行を読み込む “Seq Scan”(全件走査) が発生していることが分かりました。
次に、この結果をもとに以下の3つのアプローチを考えました。
- アプリケーション側の改修: 呼び出し回数が非常に多いため、「N+1問題」の解消やキャッシュの導入などで、クエリの発行回数自体を減らす。
- インフラ(DB)側の改修: データベースのスペック向上(スケールアップ)やノード数増加(スケールアウト)を行う。
- クエリのチューニング: インデックスを張り、検索効率を上げる。
今回は座学で学んだ 「インデックスを張る」 という手法を試すことにしました。1. のアプリケーションコードを修正してデプロイし直す方法は、抜本的な解決になる可能性がありますが、今回の演習時間内での実装コストには見合いません。また、2. のスケールアップはコスト増につながるため、本演習ではスコープ外とされていました。
インデックスとは、本の「索引」のようなもので、これを作成することで、データベースが全行をスキャンすることなく、目的のデータを効率的に探し出せるようになります。
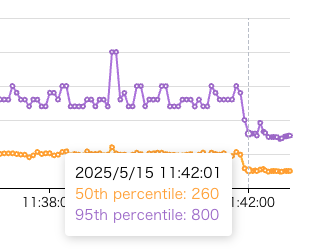
実際に、重いクエリが参照しているカラムにインデックスを張ることで、クエリ実行が高速化しました。以下のグラフはリクエストの応答時間を示していますが、インデックスを張ったタイミング(グレー点線の時刻)以後の応答時間が短くなっていることがわかります。
パフォーマンスチューニング まとめ
このパフォーマンスチューニング演習を通して、システムの「非機能要件」の重要性を実感しました。また性能が出ない状況に直面した際に「何がボトルネックになっているか」を特定し、解決する流れを理解することができました。
3. 障害対応
午後のパートでは障害対応を行いました。
事務局の方々が事前に準備してくださったシステムに対し、意図的に、かつ連続的に複数の障害を発生させる形式で演習は進行されました。これに対し、私たち参加者は、発生した障害の原因究明と迅速な復旧を繰り返す、いわゆる「わんこそば方式」で課題に取り組みました。

参加者は、疎通確認用Locustで障害発生の検知と機能的な復旧を確認した後、障害報告書の作成とメンターの承認をもって「復旧」と見なされました。この演習の目的は、「自分が作ったものではないシステム」の調査を通じて、実務さながらの緊張感の中で問題特定と対処を行うスキル、そして監視といったシステムの周辺的な要件や、監視といった非機能要件やドキュメントの重要性を体感することにありました。
今回は3つの障害に対処しました。それぞれの障害は以下の箇所で発生しましたが、発生箇所のアナウンスはなく、自分たちで特定する必要がありました。
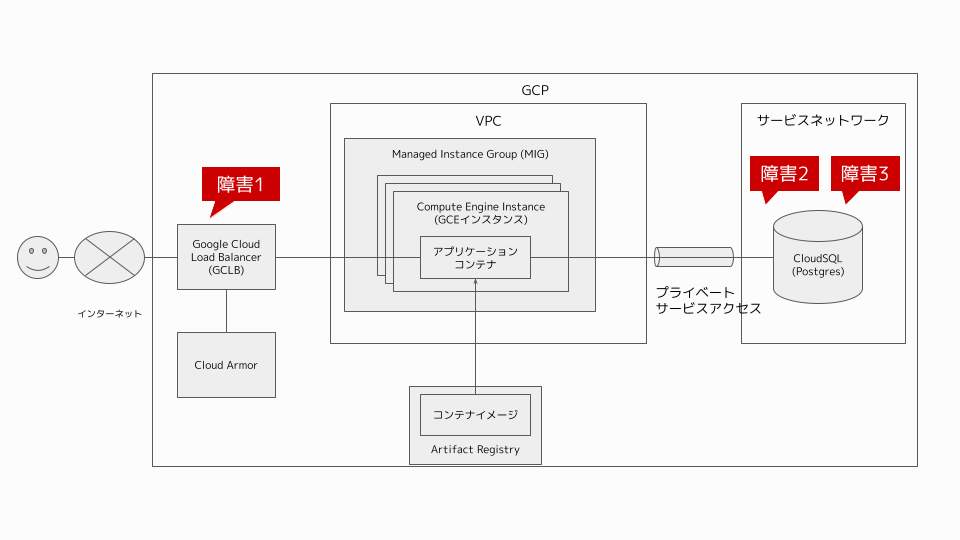
【障害1】 Firewall障害
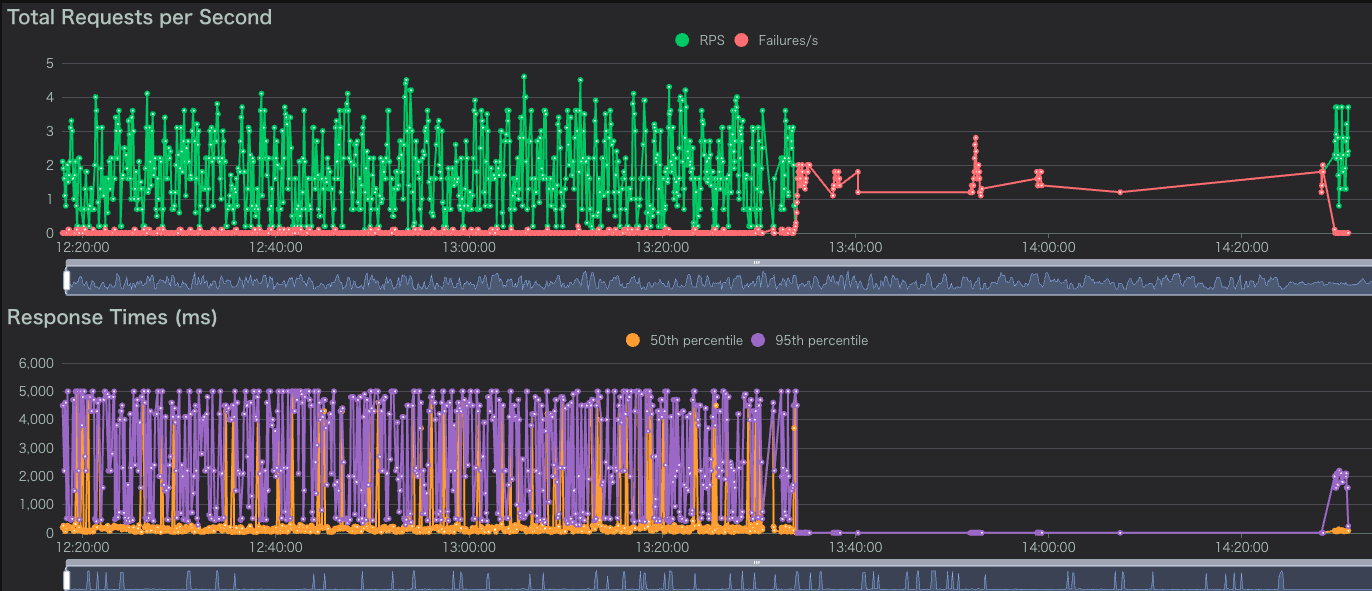
最初の演習は「サービスにアクセスできない」障害から始まりました。 ブラウザには「no healthy upstream」という、サービスが完全に停止していることを示すエラーが表示されています。
Locustを確認すると、エラー発生 (13:30) 後からFailures/sが急増していることが確認できました。
原因調査と対応:
- ログエクスプローラーを確認すると、
failed_to_pick_backendというエラーステータスを確認しました。 - エラーステータスを検索すると、 公式ドキュメント にエラーの言及がありました。
- ドキュメントから、ヘルスチェックの設定に誤りがあることを発見しました。
- 対応策として、ヘルスチェックに必要なFirewallルールを有効化し、無事サービスは復旧しました。
復旧後は実際に障害報告書を作成し、メンターに報告しました。なぜ障害が起きたのか、どう対応したのかをドキュメントにまとめるプロセスも、非常に学びが多かったです。本来、今後同様の障害が起こらないように対策するところまでが求められますが、今回の研修では学習目的で人為的に障害が発生させられていたため、そこまでは扱いませんでした。それでも、障害対応の一連の流れを経験できたことは、実務を想定した貴重な学びとなりました。
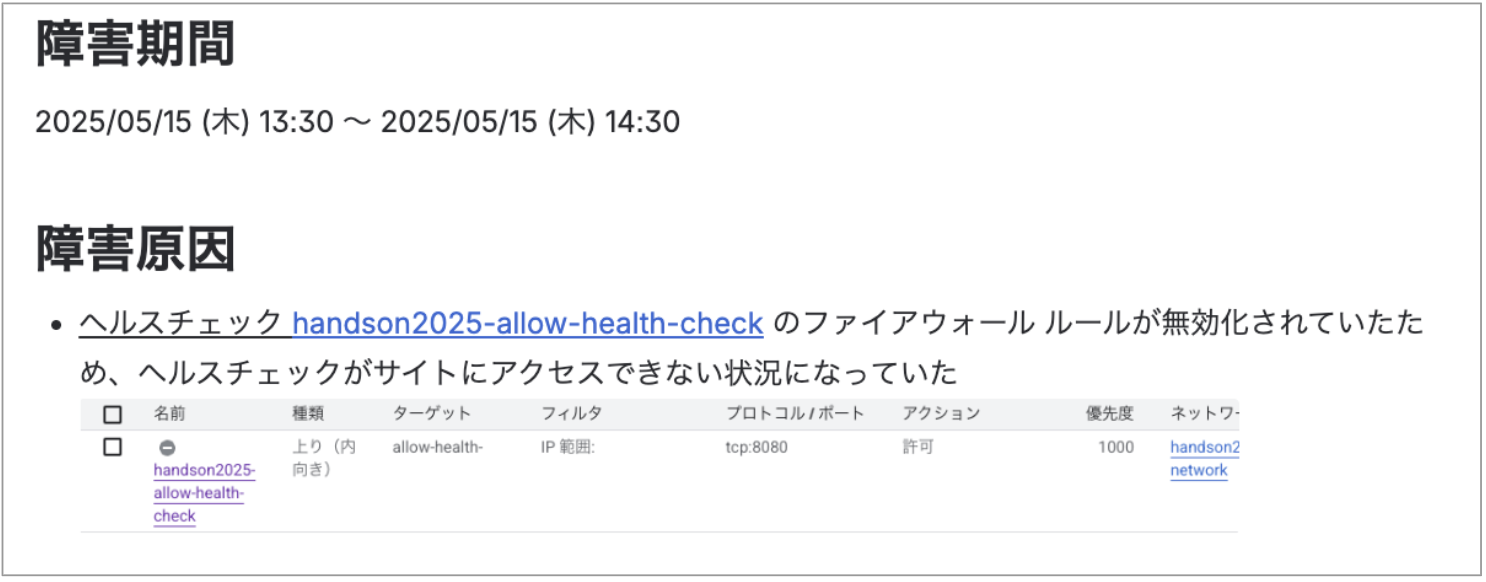
【障害2】 データベースの消失
しばらくすると、再びサービスにアクセスできない状態に陥りました。ログを確認すると、データベースが存在しないというエラーを確認しました。
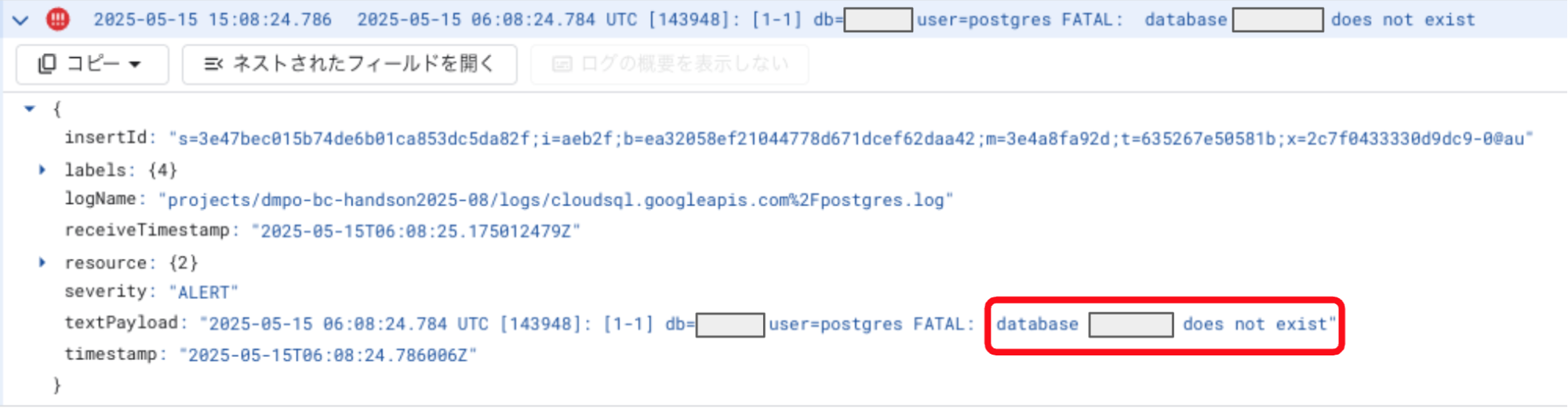
原因調査と対応:
- 「データベースが消えるわけがない」という先入観があり、最初はネットワーク構成の不良など、別の箇所を疑ってしまい、切り分けに時間を要しました。
- 調査に行き詰まったため、発想を転換し「エラーメッセージが文字通りの意味で、データベース自体が本当に存在しないのではないか」という仮説を立てて検証することにしました。
- 仮のデータベースを作成しクエリを再度投げたところ、テーブルが存在しないというエラーコードに変わったためデータベース自体が存在していないことを特定しました。
- あらかじめ取得されていたデータベースのバックアップを復元し、無事サービスは元通りになりました。
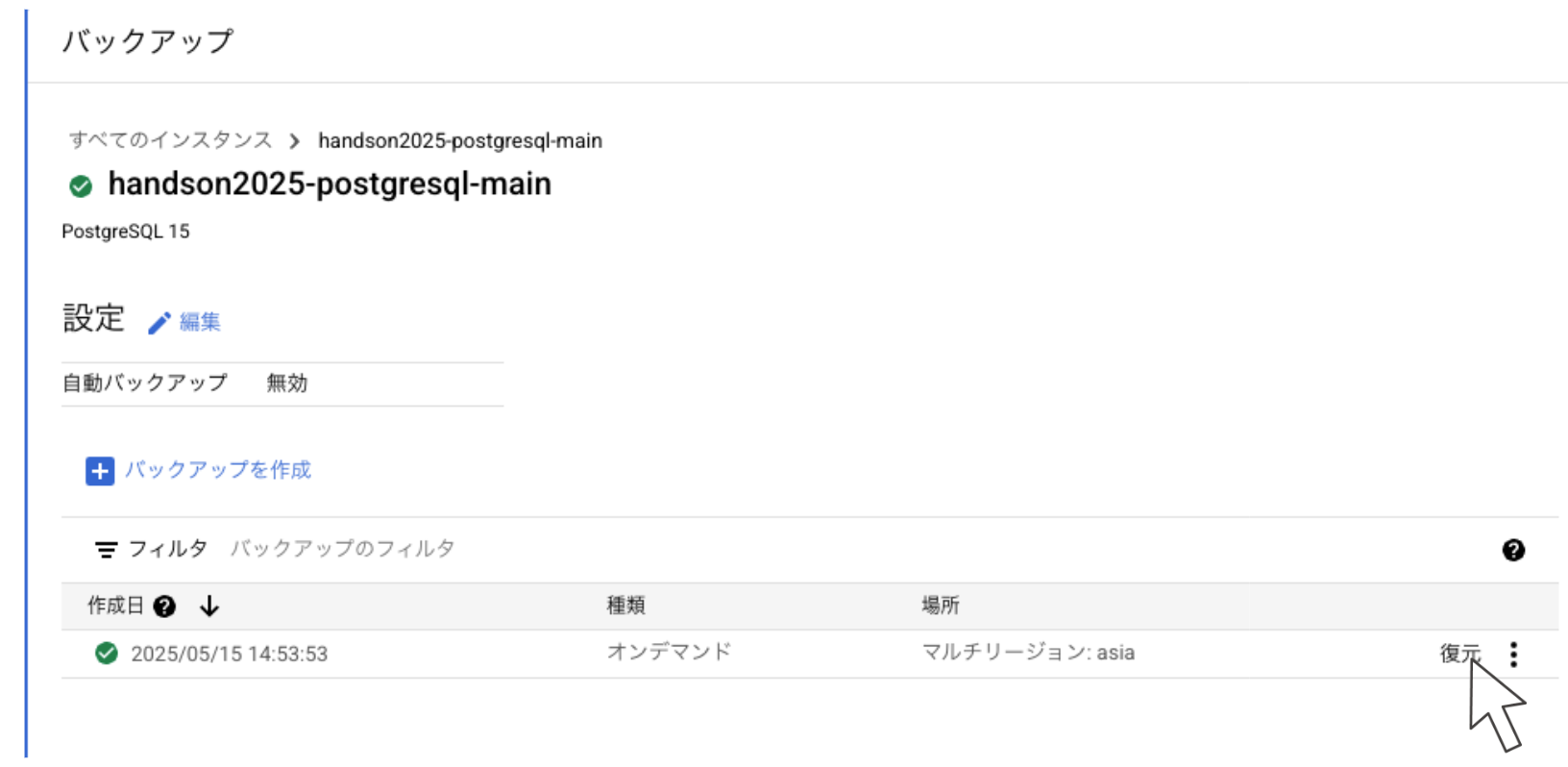
「まさか」という状況を疑う重要性と、仮説を立てて検証することの重要性を痛感しました。思い込みは調査を遅らせる最大の敵であると、身をもって体験した演習でした。
【障害3】地理情報検索機能の障害
シミュレーション終盤、今度は「なぞって検索」という機能が使えなくなるという現象の発生を確認しました。これまでの障害とは異なり、Locust上でのエラーは増えませんでした。これは、Locustの負荷試験シナリオにこの機能が含まれておらず、監視対象外だったためです。監視されていない機能の障害は自動では検知できないという、実運用における監視設計の重要性を実感しました。
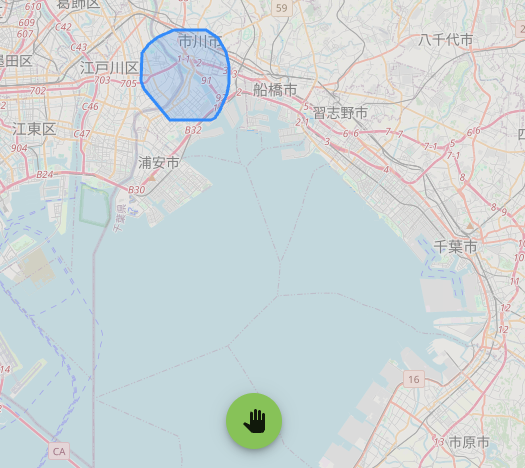
原因調査と対応:
- ログを確認すると、
st_polygonfromtext()という地理情報を扱う関数でエラーが発生していることが判明。 - この関数はPostGIS拡張機能で提供されているため、「PostGIS拡張機能がアンインストールされているのでは?」と仮説を立てて確認したところ、その通りでした。
- 対応策として、PostgreSQLにPostGIS拡張機能を再導入しました。
原因特定から解決までを最も短時間で成し遂げることができました。
4. 研修を通して学んだこと
このシミュレーションを通じて、私たちのチームが得た重要な教訓は以下の2点です。
- 公式ドキュメントを読み込む習慣: 見慣れないエラーこそ、公式情報が最も正確な道しるべとなること。
- 原因の列挙と切り分け: 一つの候補を深追いするのではなく、複数の可能性をリストアップして一つずつ潰していくアプローチが最短ルート。
障害発生時に求められる技術力と対応力の不足を痛感したシミュレーションでしたが、それ以上に仲間やメンターと助け合って取り組むことの重要性を深く理解しました。特に、各自の進捗状況を積極的に共有するWOL(Working Out Loud)を意識して行ったおかげで、進捗を素早く共有し、メンターから適切なサポートをいただくことができました。このような適切な役割分担と周囲のサポートのおかげで、自分の手で動かしながら研修に臨むことができました。
さらに、私たちのチームは後日3人で振り返り会を行いました。シミュレーション中のWOLによる情報共有があったことで、当時の状況を明確に思い出す助けとなり、学びを深めることができました。この会で我々は、今回の結果についての反省点だけでなく、次に繋げるためのさらなる改善点や挑戦したいアイデアを共有し合うことで、研修での学びを最大化することができたと思います。

最後に、総括の際に本研修の目的として講師の方が挙げられていたアルベルト・アインシュタインの言葉 「何かを学ぶためには、自分で体験する以上にいい方法はない」 この精神を忘れずに今後も積極的にチャレンジしていきます!

5. おわりに
本記事を最後まで読んでいただきありがとうございます! 25卒研修に関するブログは引き続き公開されます。楽しみにしていてください!