目次
はじめに
こんにちは!データ推進室 2025年度新卒の門倉・萩原です。 新人研修の様子を紹介するブログシリーズ、今回は「DevOps-hands-on Dev編」についてお伝えします。
こちらの研修は、研修用アプリケーションに対してデータを活用した追加機能の開発を行うという実践的な内容でした。
この研修では以下のスキルが求められました:
- データサイエンティストとしての検索アルゴリズムの理解
- 検索体験を向上させるアイデアを出す力
- 3日間という短い期間での実装力
研修の概要
研修の目的
この研修のテーマは有名な偉人の名言でした。
何かを学ぶためには、自分で体験する以上に、いい方法はない — Albert Einstein
この言葉にあるように、今回はクラウド環境でのDev(開発)を擬似体験することが狙いでした。 配属後に開発タスクをいきなりアサインされても、やればできるというマインドセットを獲得することを目指しました。
研修の内容とスケジュール
今回の研修では、既存の研修用アプリケーションに対して検索機能を追加実装するという課題が与えられました。 3人ずつでチームを組み、3日間という短い期間の中で開発・エンハンス(機能拡張)を繰り返す経験をしました。
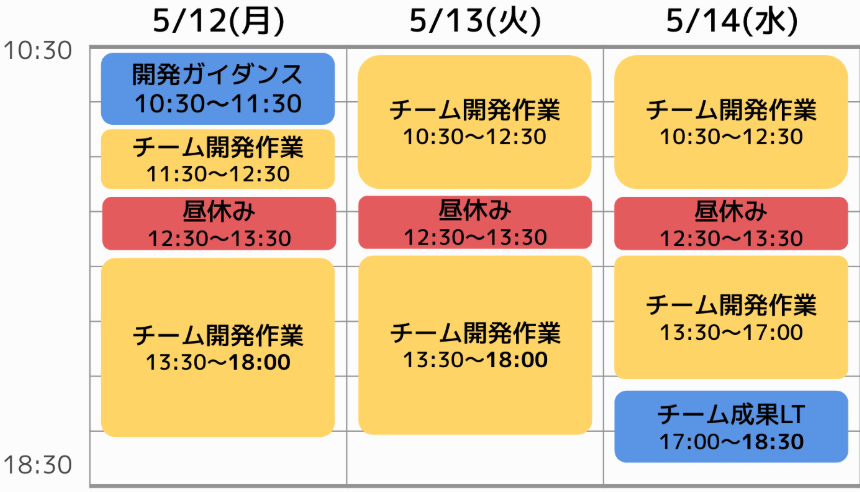
今回の研修では、課題として「既存アプリケーションへ2つの検索機能の追加」が与えられました。
- ベクトル検索を使った自由文検索機能
- LLMを用いたチャット検索機能
各チーム様々な工夫を凝らしており、最終日の発表(チーム成果LT)では同期から学ぶことがたくさんありました。 今回の記事では2つの検索機能について実装内容や工夫点をお伝えします。
提供されたアプリケーション
今回、研修の対象となったのは検索サイトです。
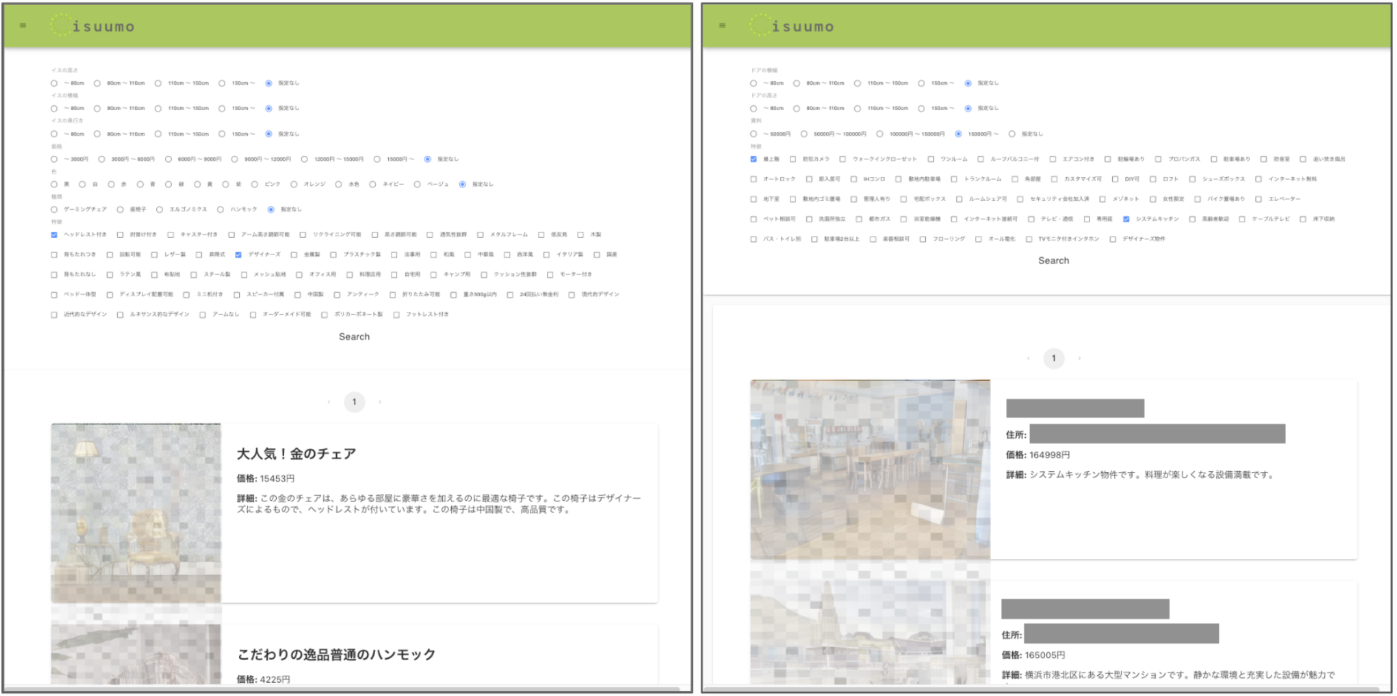
検索対象が「物件」と「椅子」の2つあり、それぞれ別のページで検索します。 物件から椅子への誘導や、椅子から物件への誘導を含んだ検索サイトになっています。 検索自体の動作はシンプルで、検索条件を指定すると、検索結果が出てくるというものです。 ただし、その検索条件の指定が、多数のチェックボックスから自分が興味あるものを見つけ出してクリックしないといけないというもので、ユーザーにとって不便なものになっています。
これを、自然言語での検索やAIチャットでのレコメンド機能を作ることで、改善するのが今回の研修の目的でした。
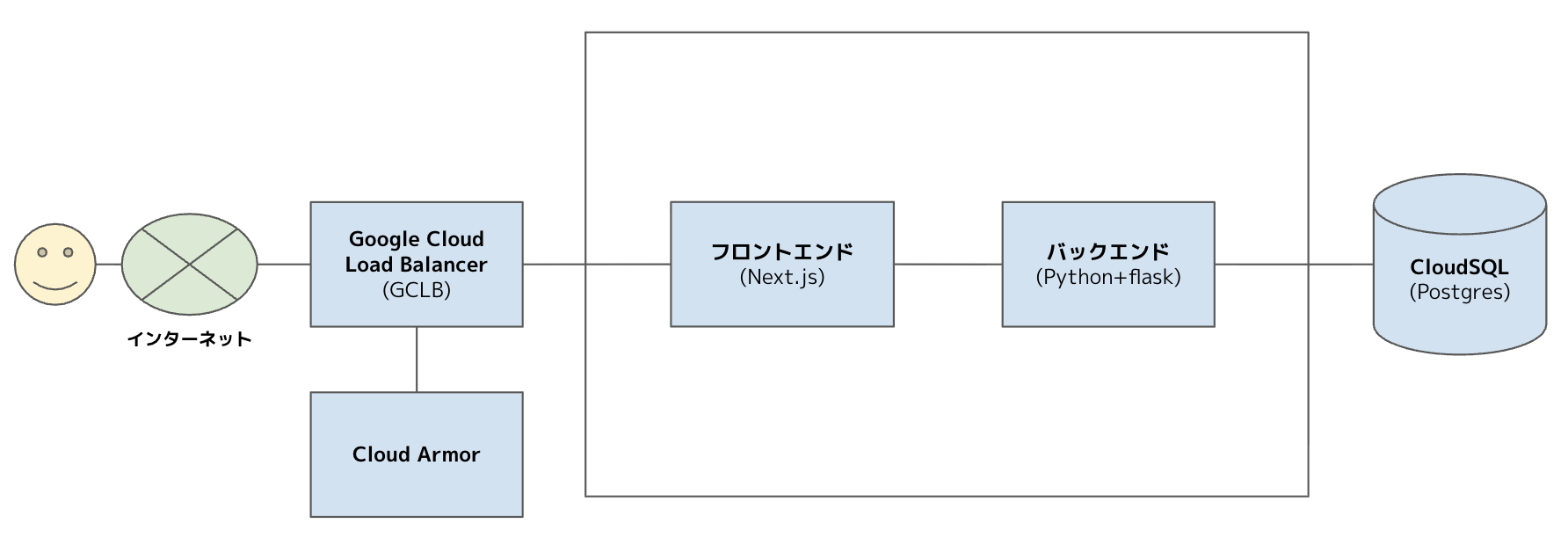
システム構成
今回のシステムの簡易アーキテクチャを図でお見せします。 クラウドはGCPを使用しており、研修用なので比較的シンプルな構成でした。
1. ベクトル検索を使った自由文検索機能の開発
既存の検索機能での課題は、検索条件をたくさんのチェックボックスから選択するユーザーの手間でした。
そこで、自然言語での検索機能を実装することにしました。 それによってユーザーの手間が削減されます。
ガイドラインとして与えられた3つの開発工程を実装した後は、各チームが自由にエンハンスに取り組める時間となりました。
- 事前に物件の説明をエンベディングし、DBに保存
- ユーザーからのリクエストをエンベディング
- 類似度検索を行い、検索結果を表示
- 自由にエンハンス
エンベディングを用いたベクトル検索の実装
自然言語ベースの検索が、これまでの「チェックボックス型」検索と決定的に異なるのは、ユーザーがどんな形式・表現でも検索できてしまう「自由さ」にあります。 従来のチェックボックス検索では、あらかじめ用意された選択肢に沿ってユーザーが入力するため、定義された条件セットの中から結果を返すことができました。しかし自然言語検索では、「間取りも眺望も静かさも重視したい」「ワンちゃんと住める明るい部屋」など、データ形式にとらわれない自由なリクエストが寄せられます。ユーザーの表現の自由度が高い分、開発者側には意味を柔軟に理解し処理する難しさが生まれました。この課題を乗り越えるために、より意味理解に優れた仕組みが不可欠となりました。
この柔軟性を出すためにエンベディングによる類似度検索を採用しました。
エンベディングとは
エンベディング(Embedding)とは、単語や文章などの自然言語を、その意味的な情報や文脈を保ったまま、コンピュータが扱いやすい数値のベクトル(多次元の数値のリスト)に変換する技術です。
エンべディング空間では、意味の近さがベクトル間の距離として表現されます。
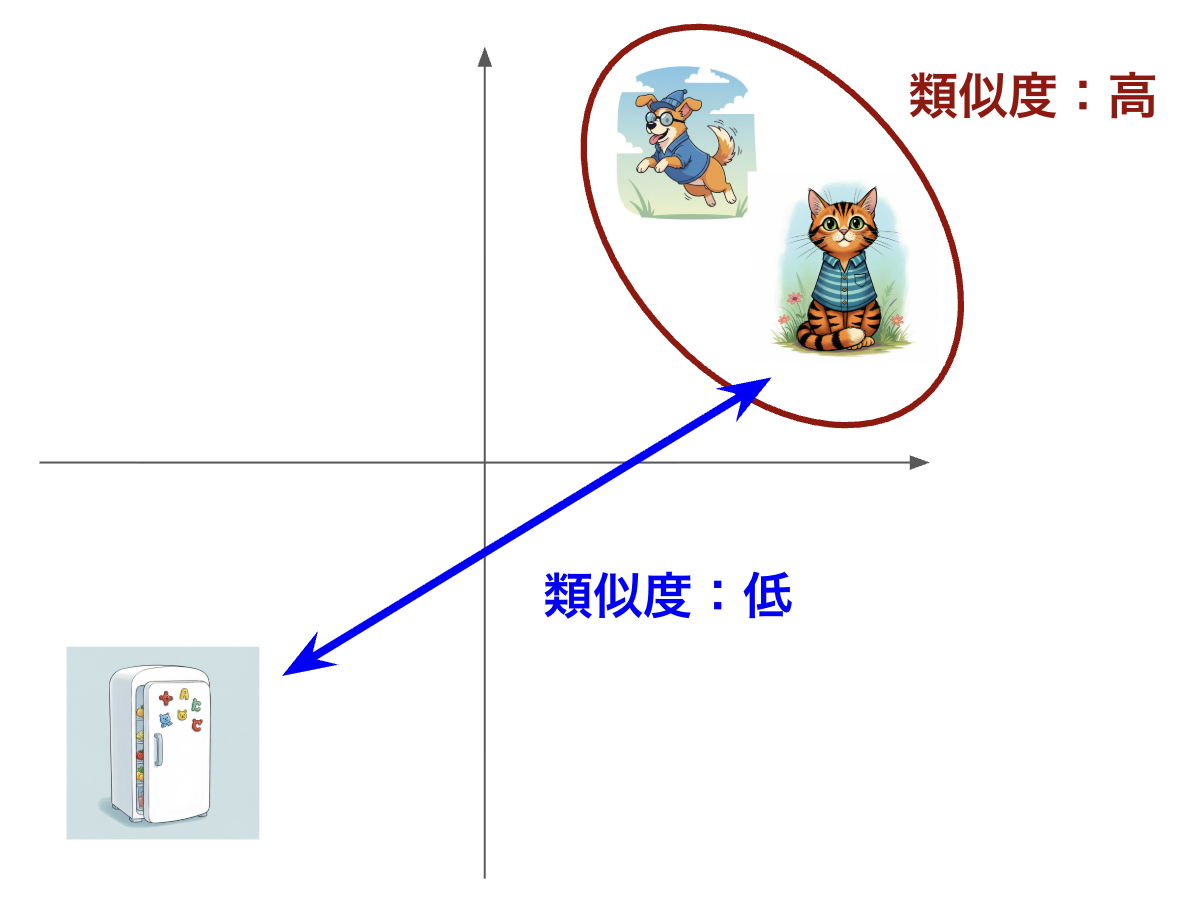
単語の例: 意味が近い「犬」と「猫」はベクトル空間内で近くに配置されますが、「犬」と「冷蔵庫」は遠くに配置されます。
文章の例: 使用する単語が異なっていても、以下の2つのように意味内容が似ている文章は、エンべディング化された後、ベクトル空間内で非常に近い位置にプロットされます。
文章A: 「広々としたリビングで、日当たりの良い南向きの部屋を探しています。」
文章B: 「明るくて広い居間のある、南側に窓がある物件が見たい。」
この性質を利用することで、キーワードが完全一致しなくても、ユーザーが意図する内容に合った情報を柔軟に検索できます。
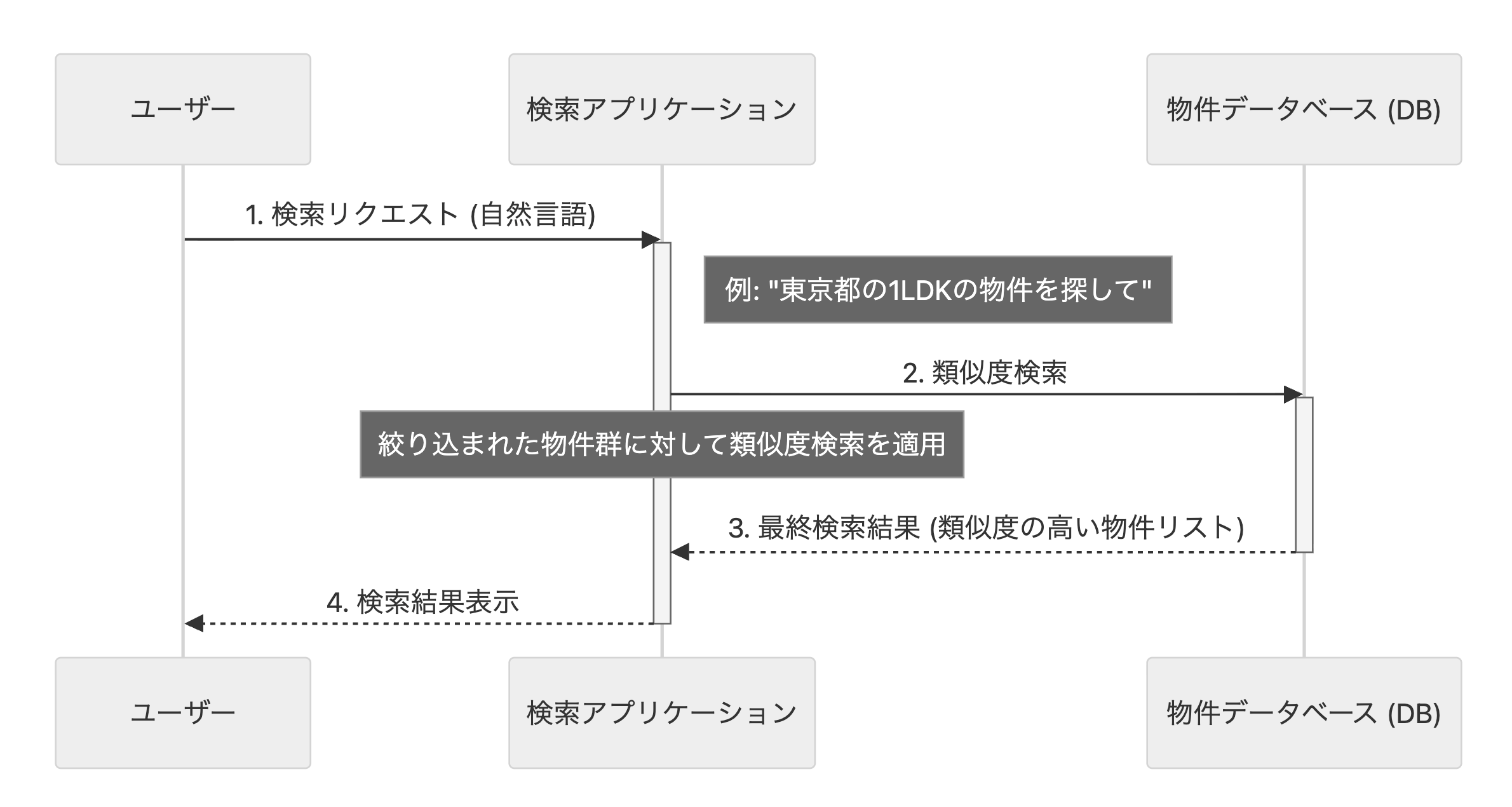
エンベディングを用いた類似度検索のフロー
このベクトルを使うことで、意味的に近い単語や文章は、ベクトル空間内でも近い位置に配置されるようになります。 今回の開発では以下のフローで実装を行いました。
-
データのベクトル化
検索対象のすべてのデータ(今回の場合は物件の説明文)を、事前にエンベディングモデルを使ってベクトルに変換し、データベースに保存しておきます。 今回はVertexAIでエンベディングを行い、PostgreSQLのプラグインであるpgvector機能を用いてベクトルデータを保存しました。
-
クエリのベクトル化
ユーザーからの検索リクエスト(自由文のクエリ)が来たら、同じエンべディングモデルを使ってそのクエリをベクトルに変換します。
-
類似度の計算
クエリのベクトルと、データベースに保存されているすべてのデータベクトルとの類似度を計算します。この類似度の計算には、コサイン類似度を使用しました。
-
結果の表示
類似度の高い順にデータを抽出し、それを検索結果としてユーザーに表示することで、「意味的に近い」物件を柔軟に返すことができるようになります。
このアプローチにより、キーワードが完全に一致しなくても、ユーザーが意図する内容に合った情報を素早く見つけ出すことが可能になりました。
類似度検索の課題とエンハンス内容
類似度検索の実装が完了すると、残りの時間はエンハンス作業に充てることになります。 3日間の開発期間のうち、班ごとに多少の差はありますが、多くの場合1〜2日が類似度検索の実装に費やされるため、エンハンスに使える時間は限られていました。
さらに、類似度検索には依然として課題が残っていたため、その課題の発見から解決策の検討、実装までを残りの1日でやりきる必要があり、最後まで気を抜くことはできませんでした。
私(門倉)の班でのエンハンスを今回は紹介します。
類似度検索の課題
類似度検索で見つかった最も大きな課題は、エリアの限定が弱いということです。 具体例を出すと、東京都の物件を調べたはずが京都の物件が混じっていることがありました。 他にも東京都中央区で調べたにも関わらず、他の都道府県の中央区の物件が出てくることもありました。
これらの課題を受けて、「クエリ検索」、すなわち物件データベースの特定の項目(都道府県や間取りなど)に対して直接的に絞り込む検索機能もやはり必要だと感じました。 具体的には、「東京都の物件」や「1LDKの間取り」のように、ユーザーの要望に含まれる明確な条件を元に、データベースの該当カラムで事前に絞り込みを行う手法を指します。エンハンスとしてこのクエリ検索を取り入れることで、キーワードベースだけでなく、自然言語による検索でも十分に絞り込みが機能することを目指しました。
追加実装の内容としては、類似度検索の前にLLMを用いてクエリの検索条件となる部分を抽出し、事前にクエリ検索をかけた物件群に対してベクトル検索を行うようにするというものでした。
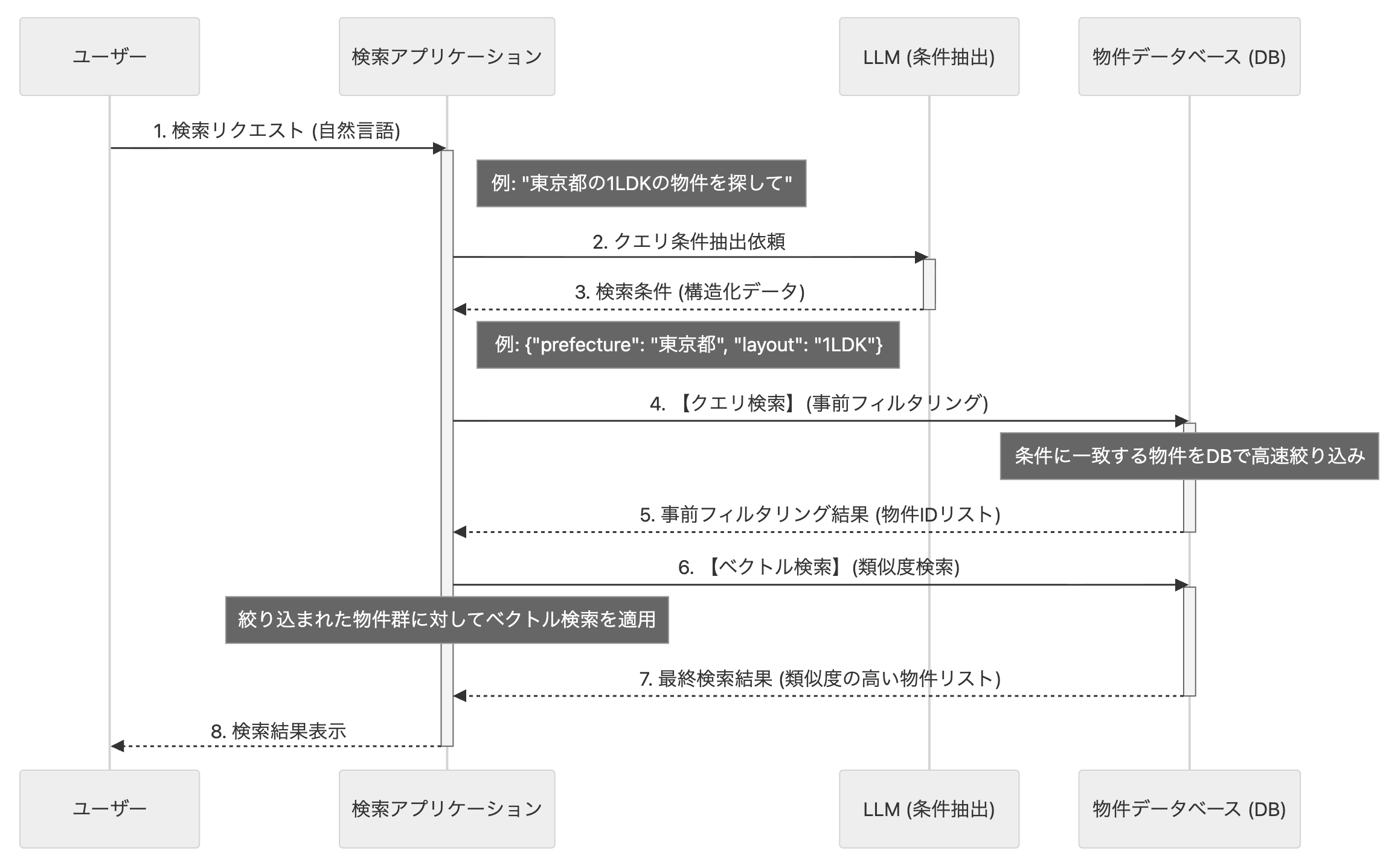
この図の例では、ユーザーの検索文「東京都の1LDKで日当たりの良い物件」に対して、既存の類似度検索のみでは京都の物件や2LDKの物件等も紛れ込んでいました。 今回の追加実装では、この検索文に対してまずLLMを用いて検索クエリとなりうるポイントを抽出しました。 この例で言うと、LLMのアウトプットとしては以下のように抽出できます。
{
"prefecture" : "東京都",
"room_type" : "1LDK"
}
ここでは LLM に対して structured_outputを利用することで、「都道府県」「間取り」など、求める出力形式をスキーマとして明示的に指定し、型を固定する工夫を行いました。ただし LLM は柔軟に出力を生成してしまうため、スキーマで指定していないキー(例:誤って “city” や “floor” など不要な項目)が返る・フォーマット自体が崩れる・JSON にならない、といった事象も発生する恐れがありました。そこで、想定外のデータや予期しない出力が混入した際もアプリケーション側で補足・修正できるよう、エラーハンドリングやバリデーション処理を丁寧に実装しています。
なお、この structured_output の仕組みは後述する「LLM を用いたチャット検索機能」でも活用しており、RAG 構成時の情報抽出や整形にも応用される重要な基盤となっています。
次に、このクエリを用いて物件DBからクエリベースで検索を行います。 これは先ほどのjsonをもとに事前作成されたベースのクエリにwhere句を追加する形で作成しました。 今回のケースでは以下のようなクエリが出来上がります。
select
*
from property_table
-- これ以降をjsonをもとに追加
where
prefecture = "東京都"
and room_type = "1LDK"
このクエリで絞り込まれた物件リストに対して、類似度検索を行うことで、最低限守るべき条件は守られつつ、ユーザーの自由な要望に合わせた物件リストを検索することができるようになりました。
自由文検索機能まとめ
この課題ではベクトル検索機能の実装を行いました。 ただ、それだけではユーザー体験を向上することができなかったため、エンハンスパートでクエリ検索とのハイブリッド検索機能を実装しました。 それによって、ユーザーの手間を省きつつ、欲しい物件が出てくる検索機能を作成することができました。
2. LLMを用いたチャット検索機能の開発
次は前章で開発したベクトル検索基盤とLLMを組み合わせて、簡易的なRAG(Retrieval-Augmented Generation)を実装します。 以下のように、ユーザーがLLMとチャットして物件を検索するチャットボットを実装していきます。
LLMの主な弱点として、最新の情報を知らない、間違った回答をする(ハルシネーション)といったものがあります。 しかしRAGの仕組みを用いることで、最新の情報、実際に登録されている情報から回答を生成させることができます。 それによって、回答の正確性、信頼性の向上が期待できます。
RAGとは
RAG(Retrieval-Augmented Generation)とは、大規模言語モデル(LLM)に外部データベースを組み合わせて、モデルが知らない情報にも基づいて正確な回答を生成しようとさせる仕組みです。
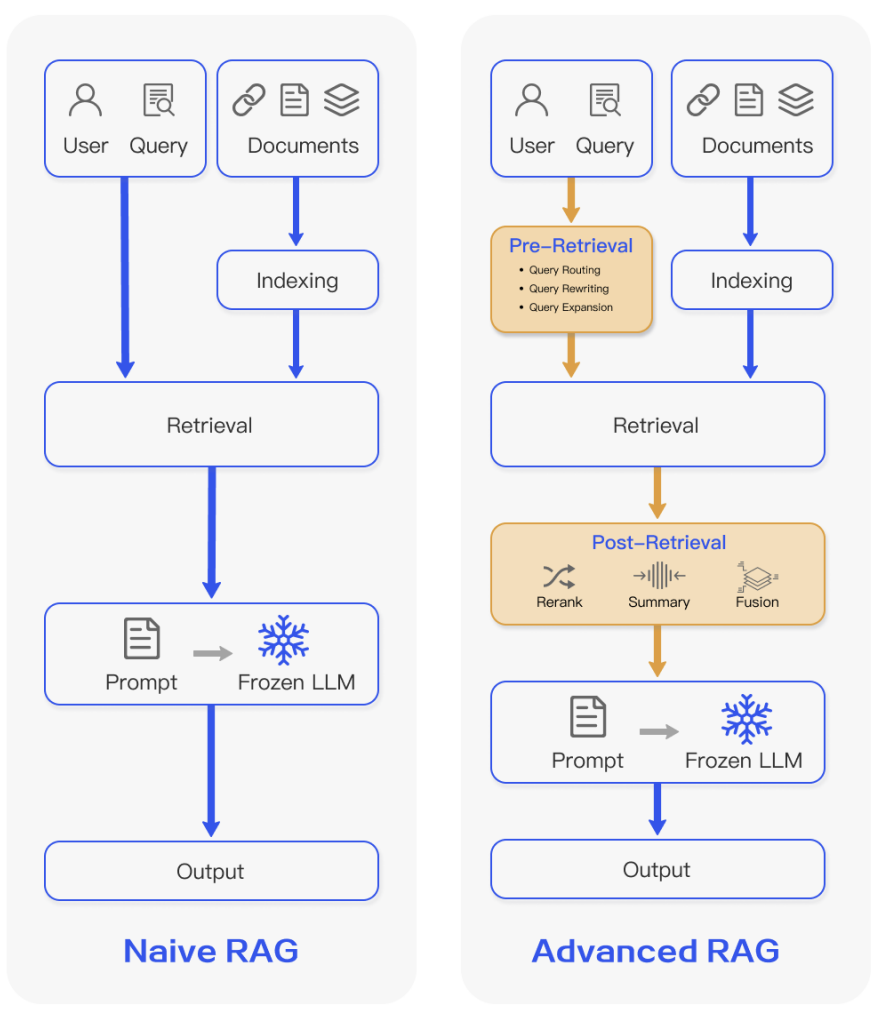
RAGは基本的には3ステップから成り立ちます。具体的にはIndexing(データ登録)、Retrieval(検索フェーズ)、Generation(回答生成フェーズ)です。
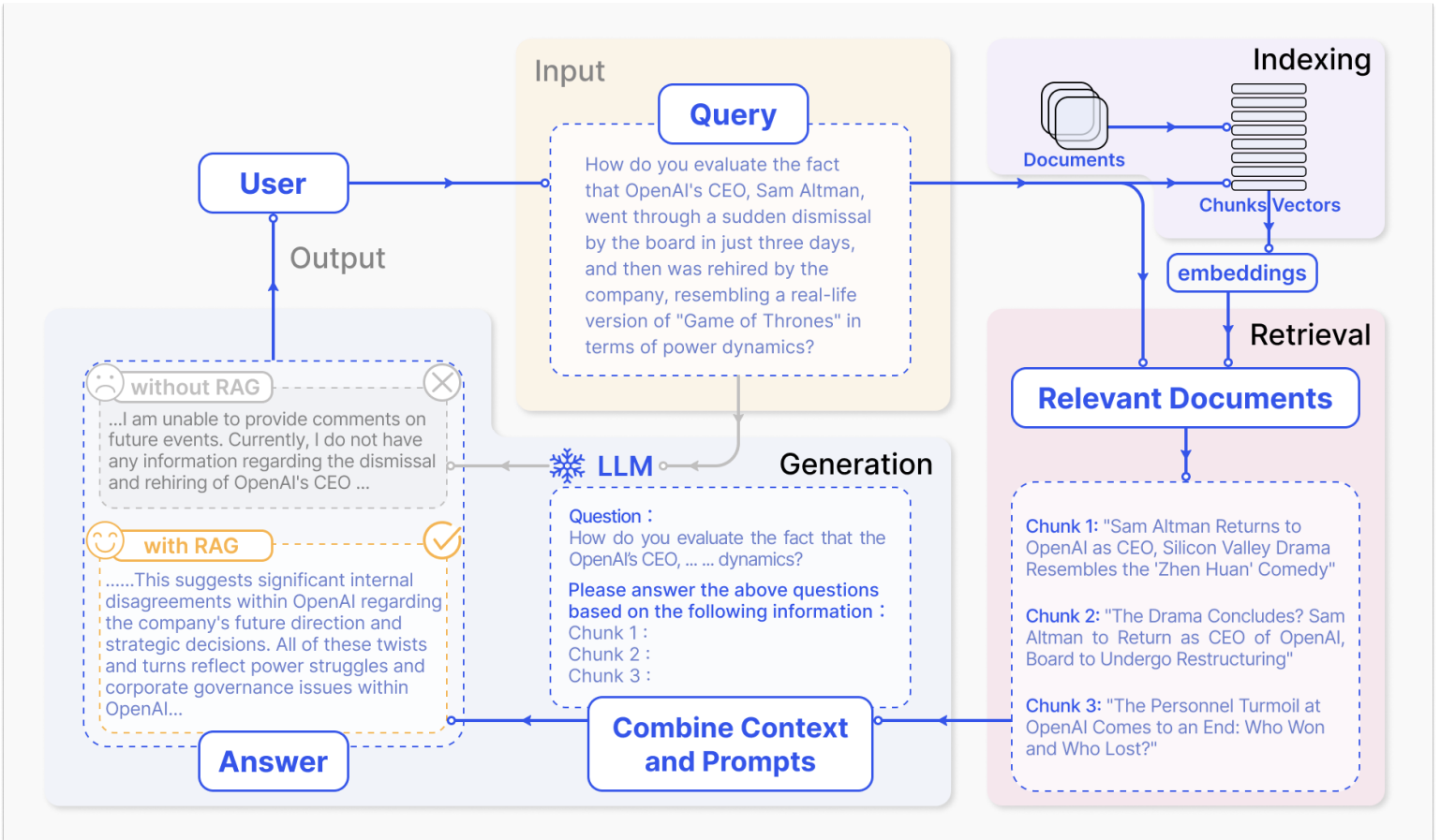
- Indexing(データ登録): 外部データ(PDF、テキスト、Webページなど)を 検索可能な形 に変換し、データベースに登録する工程。
- Retrieval(検索フェーズ): ユーザーの質問をベクトル化し、最も関連性の高いコンテンツを検索する工程。
- Generation(回答生成フェーズ): LLM が 検索結果を参照しながら 回答を生成するステップ
まず、入力されたドキュメントに対して埋め込みモデル(Embedding Model)を用いてベクトル化を行い、得られた特徴ベクトルをベクトルデータベースに格納する Indexing(インデキシング)工程 を実施します。 この段階では、テキスト内容をモデルが理解可能な数値表現へ変換し、それらを効率的に検索可能な構造へ組み込みます。 それによって、後続の類似度検索を高速に行えるようにします。
次に、ユーザーから自然言語で与えられたクエリに対しても同様に埋め込みベクトル化を行い、ベクトルデータベース内の文書群との類似度(コサイン類似度や内積など)を指標として検索を行います。 こうして取得された関連性の高い文書を、大規模言語モデル(LLM)に渡すことで、文脈に基づいた回答を生成します。
ここで注目すべきポイントとして、前章「ベクトル検索を使った自由文検索機能の開発」で取り組んだ処理(=埋め込みによるデータのindexingと、クエリembeddingによるretrieval処理)が、そのままRAGの基本構成(Indexing+Retrieval)に直結していることが挙げられます。つまり、「Naive RAG」と呼ばれる最小構成のRAGシステムは、(ベクトル)埋め込み検索の実装をそのまま流用・発展させることで実現できます。
現在、RAGには多様な手法が提案されており、その設計は用途や精度要求に応じて大きく進化しています。 本研修では、クエリを埋め込みベクトル化し、ベクトルデータベースから関連文書を取得してLLMへ渡すという、もっとも基本的な Naive RAGをメインに行いました。 他にも取得した文書のリランキング(Re-ranking)、ユーザークエリを補正するクエリ拡張(Query Expansion)、複数段階で検索するマルチステージRAG、生成モデルによる検索支援を行う生成的検索(Generative Retrieval)など、より高度な手法を組み合わせたものも多数提案されており、それに取り組む班もありました。
ワークフロー構築
前章で構築したクエリのベクトル化→PostgreSQL(pgvector)でのベクトル検索の工程に、LLM APIとの通信処理を追加します。 今回はGCPのVertex AI経由でGeminiを呼び出します。 研修ではLangChainを用いてVertex AIを呼び出している班が多かったです。 以下サンプルコードになります。
サンプルコード
from langchain_google_vertexai import ChatVertexAI
PROJECT_ID = **********
LOCATION = "asia-northeast1"
Model_NAME = "gemini-2.5-flash"
#チャット、モデルの初期化
chat = ChatVertexAI(
model_name=Model_NAME,
project=PROJECT_ID,
location=LOCATION,
temperature=0.0,
)
# プロンプト
prompt = "Pythonについて簡単に説明してください。"
# Chat invoke
response = chat.invoke(prompt)
# 結果の表示
print("回答:")
print(response.content)
結果の例
Vertex AI経由でGeminiを使用すると、サンプルコードの通り明示的なAPIキーの発行やコードへの埋め込みが不要になるため、APIキーの漏洩リスクや管理コストを低減でき、セキュリティ面で非常に大きな利点があります。 ただし、APIキーが不要というだけで完全に認証無しで利用できるわけではなく、GCPプロジェクトやサービスアカウントなどGoogle CloudのIAM(認証・認可)の仕組みを通じてユーザーやプログラムの権限管理が行われています。 このため、「誰がどんな操作をしたか」の監査や権限制御も一元的に行うことができ、APIキーを個別に配布・保管するよりも安全かつ運用しやすくなります。
一方でGCP公式からも直接SDKが提供されており、私(萩原)の班では、LangChainではなくそちらを用いました。 LangChainは強力なフレームワークですが、公式のSDKの方が以下の点で優れていると判断しました:
- サポートが充実している
- 公式ドキュメントとの整合性がある(Googleの公式ドキュメントやサンプルコードは公式SDKを基準に作成されている)
- 最新機能を取り込んでくれる(Google公式SDKは新機能やモデルのアップデートに最速で対応する)
- 依存関係の軽量化
- コードがシンプルに書ける
複数のLLMプロバイダーを横断的に使用したい場合や、複雑なエージェントワークフローを構築したい場合には、LangChainの抽象化の恩恵が活きる場面もあります。 ただ、今回のように特定のGCPサービスに特化した開発では、公式SDKの方が適切だと判断しました。
Vertex AIを使うためのSDKとしてVertex AI SDK(vertexaiパッケージ)とGoogle Gen AI SDK(google-genaiパッケージ) の2種類がありますが、前者のVertex AI SDKは現在非推奨となっています。
そのため、今回の実装ではGoogle Gen AI SDKを採用しました。
以下サンプルコードになります。
from google import genai
PROJECT_ID = ***********
LOCATION = "asia-northeast1"
Model_NAME = "gemini-2.5-flash"
#クライアントの初期化
client = genai.Client(project=PROJECT_ID, location=LOCATION, vertexai=True)
# プロンプト
prompt = "Pythonについて簡単に説明してください。"
# コンテンツ生成
response = client.models.generate_content(
model=Model_NAME,
contents=[prompt],
)
# 結果の表示
print("回答:")
print(response.text)
この実装をベースにLLMチャットの実装を行いました。 前章で開発したベクトル検索と連携し、検索結果をもとにLLMが適切な情報を参照できるようにプロンプトを設計したことで、正確な物件情報に基づく回答を得ることができました。
まとめ
今回の研修では、ベクトル検索とLLM APIを用いたRAGの開発を行い、ユーザー体験を向上させる検索機能を実装しました。
開発面だけでなく、GCPインフラに触れるというテーマもあり、各チームで様々な工夫が見られました。 私(萩原)の班では、インフラ構築においてブルーグリーンデプロイを実装しました。
ブルーグリーンデプロイとは、本番環境(Blue)と同じ構成の新環境(Green)を用意し、新バージョンをGreen環境にデプロイした後、ロードバランサーの向き先を切り替えることで、ダウンタイムなしでデプロイを実現する手法です。 問題が発生した場合も即座にBlue環境に戻せるため、安全性が高いのが特徴です。 機能追加や改善を行いながらも、サービスを止めることなく継続的にデプロイを実行できる環境を構築しました。
このように、Dev(開発)だけでなくOps(運用)の観点からもサービスの品質を考える良い機会となりました。
感想
門倉
この研修は3日間という短い期間で2つの機能実装とエンハンスまで取り組むという、非常にチャレンジングな内容でした。 しかし、リクルートのように多くの人がひとつの機能開発に関わる組織では、関係するそれぞれの担当領域(たとえば設計や実装、テストなど)での作業スピードをできるだけ上げていくことが、全体の開発のスピード感につながるのだと実感しました。 この研修を通して得た学びを活かし、実際の業務でもスピードと正確さの両方を意識して開発していきたいと思います。
萩原
同期とチーム開発できたのが非常に楽しかったです。 まずはじめにゴールを言語化して、ゴールのために必要な要件、それに対応する機能を洗い出し、各自が開発を進めるという、要件定義から実開発までの実務に近い内容を体験することができました。 また、ただ言われた要件を達成するだけでなく、「どうしたらプロダクトがより使いやすく・便利になるか」「より良い開発をするためにはどうすればいいか」を各自が主体的に考え、フロントエンドの改善やインフラ改善に取り組むチームもありました。 全体を通して、「課題はなにか?」「価値はなにか?」まで考えて実装するリクルートのエンジニア、データサイエンティストらしい姿を垣間見ました。