目次
はじめに
こんにちは、スタディサプリENGLISH SREグループの yucky です。
リクルートに入社して 8 ヶ月が過ぎました。
私のリクルートにおける最初のミッションは、スタディサプリENGLISHが稼働している Kubernetes (以下、k8s) のバージョンを上げることで、今回 v1.17 から v1.21 に上げることが出来ました。
その際に、サービス停止も DNS 切り替えもせずにクラスタ移行ができるように、AWS Load Balancer Controller の TargetGroupBinding というカスタムリソースを利用した構成に変更しましたので、それについて説明します。
現在スタディサプリENGLISHは AWS EKS (以下、EKS) 上で稼働しています。
背景
1年ほど前、スタディサプリENGLISHは ECS から EKS へ移行をしました。
移行当時は、k8s のアップグレードをどの様に行っていくかの方針は決まっていませんでした。
私はまだ入社前で、採用面接中にその話を聞きました。
当時の私は社内向け k8s サービスで開発や k8s のアップグレードなどをしており、k8s に関する知識や経験を持っていたので、リクルートでの最初のミッションとしてこの件を担うことになりました。
AWS に関しては S3, Route 53 くらいしか触ったことがなかったため、EKS における k8s の運用やその他 AWS サービスのことについて調べつつ進めました。
想定していた移行方法
当初考えていた移行方法は、新しいクラスタを建てて DNS 切り替えでブルーグリーンデプロイのように移行していく方法です。
前職で移行作業を行った際も似たような方法を取りましたし、今回もこの方法で k8s バージョンアップが実現できるのではと考えていました。
構成
移行の際に重要な部分だけを抜き出した簡略的な図になりますがこのような形になります。
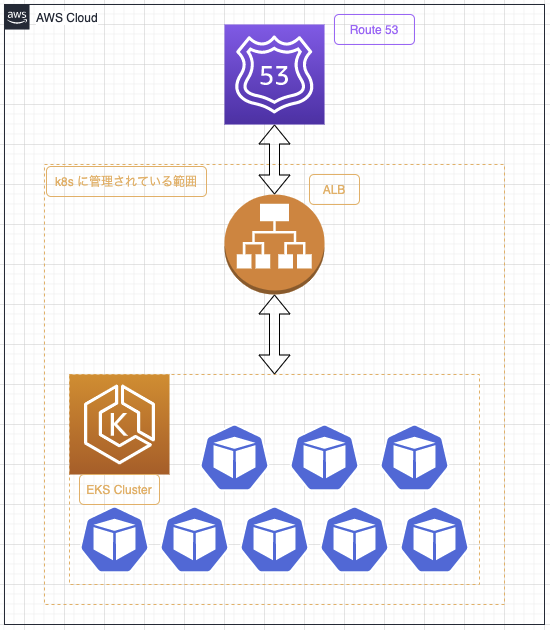
AWS Load Balancer Controller を使って k8s のリソースの一部のような形で Application Load Balancer (以下、ALB) を作成してその ALB を route53 でドメインと紐付けるといった構成です。
AWS Load Balancer Controller とは k8s クラスタ用の Elastic Load Balancer を管理するためのコントローラです。
ALB は本来 EKS とは別のサービスですが、これにより EKS クラスタだけでなく ALB までセットで管理されている状態です。
k8s バージョンアップ(クラスタ移行)
上記の構成で移行を行おうとする場合、図のように新しいバージョンの EKS Cluster を作成して Route53 で DNS 切り替えをしてリクエストを旧クラスタの ALB から新クラスタへ移行するといった形になります。
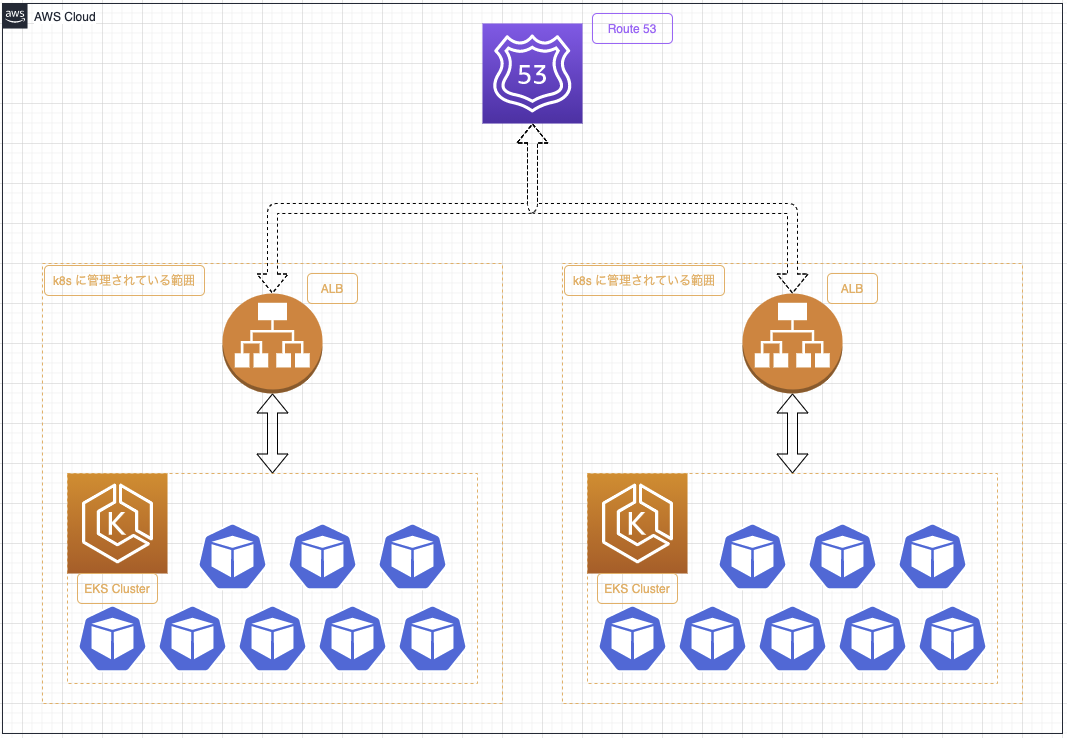
DSN 切り替えによるクラスタ移行における課題
当初はこれで問題ないと思っていたのですが、この方法では DNS 切り替え時に新クラスタへリクエストが切り替わらない可能性があるとのことでした。
というのも以前 ECS から EKS へ移行を行った際にこの方法を取り、すべてのリクエストが切り替わるのに1ヶ月ほどかかってしまったという問題があったそうです。
切り替わるのに時間がかかったのは一部の端末のみとのことでしたが、もし今回の移行でもそうなってしまった場合、移行期間中は EKS Cluster 2台分の料金がかかってしまう上に何よりその期間中のコード管理の負荷がものすごく上がってしまうということで別の方法を取ることになりました。
ALB を EKS から切り離して TargetGroupBinding を使った方法
いくつか案があった中で最終的に選んだのは AWS Load Balancer Controller で ALB を作成するのをやめるといった方法でした。
AWS Load Balancer Controller の TargetGroupBinding というカスタムリソースを利用することでそれが可能になりました。
TargetGroupBinding とは AWS Load Balancer Controller 中でも既存の TargetGroup などを使って pod を公開するためのカスタムリソースです。
今までの構成だとコントローラで EKS Cluster ごとに ALB を作ってしまっていたから Route53 で DNS 切り替えをしなくてはならなかったわけですが、TargetGroupBinding リソースを使うことによってそもそも ALB をクラスタごとに作る必要はないということでコントローラで作るのをやめて terraform で管理することにしました。
これまでは ALB の作成から ALB に紐付ける TargetGroup の作成、TargetGroup に対してクラスタの node IP を紐付けるといった設定をコントローラが一貫してやっていましたが、TargetGroupBinding リソースを利用して TargetGroup に対してクラスタの node IP を紐付ける部分だけをコントローラに任せ、ALB と TargetGroup の作成と管理を terraform で行うことによってALB でリクエストを流す先の TargetGroup を制御してクラスタを切り替えます。
Route53 と同じ様に重み付けをして少しずつリクエストを流していくといったことも可能です。
新構成
こちらが現在の構成です。

この図を見ると TargetGroup が新たに追加されたように見えますが、これまでは Controller が ALB まで一貫して作成していたため、TargetGroup を意識する必要がなかったので図には載せていなかっただけで、TargetGroup も以前から利用していました。
そうするとこの図では以前の構成とあまり変わっていないように見えますが、ここで重要なのは以前のように ALB, TargetGroup が Controller でクラスタごとに作成されているのではなく terraform で作成、管理ができるようになったという点です。
新構成での k8s バージョンアップ(クラスタ移行)
現在の構成では k8s バージョンアップの際に ALB は新たに作成せず新クラスタ用の TargetGroup を作り、新クラスタはその TargetGroup に対して TargetGroupBinding リソースで node IP を紐付ければ、Route53 での DNS 切り替えを行わずに ALB でリクエストを振り分けることによってクラスタ移行ができるようになりました。

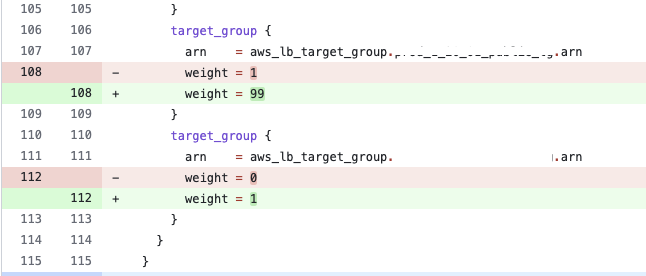
リクエストの割り振りも以下のように terraform で ALB のルールとして制御できるため、Github で管理できてその点も非常に良いです。
resource "aws_lb_listener_rule" "public_listener_rule" {
listener_arn = aws_lb_listener.public_listener.arn
priority = 1
action {
type = "forward"
forward {
stickiness {
enabled = false
duration = 1
}
target_group {
arn = aws_lb_target_group.1_20_public_tg.arn
weight = 99
}
target_group {
arn = aws_lb_target_group.1_21_public_tg.arn
weight = 1
}
}
}
condition {
path_pattern {
values = ["/*"]
}
}
}
このようなプルリクを出し、approve をもらったら terraform apply をするといったような手順で徐々にリクエストを移していきます。
k8s クラスタ移行に付随する AppMesh と CloudMap の対応
上記のように構成を変更することで DNS 切り替えなしでの k8s クラスタ移行は可能になりましたが、クラスタ移行にあたって他にも工夫した点やちょっとした躓きがあったので紹介します。
以前の記事にもあるようにスタディサプリENGLISHでは AWS App Mesh (以下、AppMesh) や AWS Cloud Map (以下、CloudMap) を使って gRPC サーバーを運用しています。
AppMesh, CloudMap は App Mesh Controller にてクラスタごとに作成されます。
本来であればコード上でクラスタ名と k8s のバージョンだけ書き換えてクラスタが作成できれば簡単なので望ましいことですが、これらは EKS とは別のサービスなので AppMesh の Mesh 名や CloudMap の namespace なども既存のものと被らないように書き換えなくてはなりません。
AWS なのでそのあたりは良い感じにしてくれるかもと淡い期待のもと書き換えずにクラスタを作成したところ、新クラスタが旧クラスタで使っていた AppMesh や CloudMap を乗っ取ってしまうといった状態になりました。
それぞれのサービスについてどう対処したかを説明します。
AppMesh
AppMesh に関しては Mesh 名をクラスタごとに変えるということですぐに決まりました。
というのも AppMesh は Mesh 名を変えずに新旧クラスタで共有しようとした場合、 Mesh 内の多数ある virtualNode, virtualService, virtualRouter の名前をすべてクラスタごとに変える必要があるため、それらは変えずに Mesh 名だけを変えて別にするほうが圧倒的に楽だったからです。
CloudMap
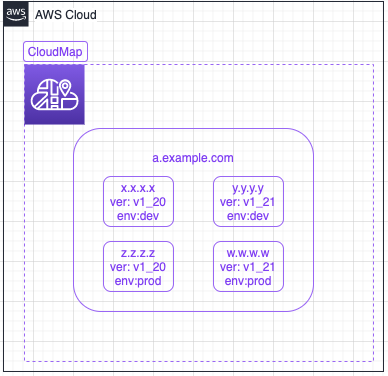
CloudMap は namespace を共有するにしてもクラスタごとに分けるにしてもコード修正がそれなりに発生しそうだったのでなにか良い方法がないか探した結果、カスタム属性を付けることで同じ namespace を共有してもリクエストをクラスタごとに分けることができるということがわかりました。
簡単に説明すると以下の図のように CloudMap の同じサービスに対してカスタム属性を付与した複数のサービスインスタンスを紐付けることによって、例えば env:dev のタグを持つ2つのサービスインスタンスに対してリクエストを流したり ver:v1_20 かつ env:prod のタグを持つサービスインスタンスへリクエストを流すといったような制御が出来ます。
App Mesh Controller で作成する場合、AppMesh の virtuelNode の設定に以下のように serviceDiscovery の設定を追加することで CloudMap のサービスに対してサービスインスタンスを紐付ける際にカスタム属性を付与してくれ、リクエストを流す際はそのカスタム属性を参照してインスタンスへ振り分けてくれます。
apiVersion: appmesh.k8s.aws/v1beta2
kind: VirtualNode
metadata:
name: grpc-api
spec:
serviceDiscovery:
awsCloudMap:
namespaceName: a.example.com
attributes:
- key: "ver"
value: "v1-21"
これにより付与するカスタム属性を変えるだけで、移行の際は同じ CloudMap の namespace を新旧クラスタで共有できるようになりました。
しかし、このカスタム属性の付与についてちょっとした躓きがありました。
カスタム属性のことを知りいざ試してみようと上記のように virtualNode の設定を書き換えて apply してみても VirtualNode update may not change these fields といったようなエラーで追加できず、ブラウザで AWS の console 上から追加しようにも出来ませんでした。
App Mesh Controller のコードも確認してみましたが追加方法がわからず、AWS の方に聞いても最初はわからず持ち帰って確認してもらった結果、後から追加する方法はないとのことでした。
開発の方に要望は出していただけるとのことでしたが、ひとまず virtualNode の設定を変えたい場合は AppMesh を作り直すしかないということで、全環境 AppMesh を作り直してカスタム属性を付与したら想定通りの動作になりました。
最終的な移行時クラスタの状態
クラスタ移行時の AppMesh, CloudMap を含めた状態は以下のようになりました
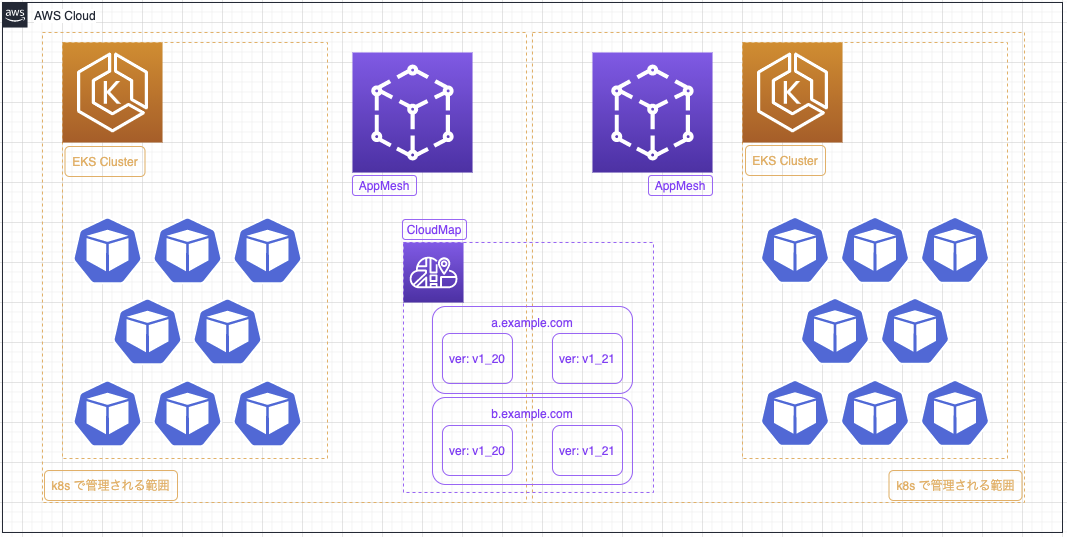
移行時には新クラスタとともに AppMesh が作成され、CloudMap にもカスタム属性が付与されたサービスインスタンスが紐付けられます。
これによりコード修正も最低限で新クラスタが AppMesh や CloudMap を乗っ取ってしまうなどの問題もなく k8s バージョンアップが行えるようになりました。
良かったこと
- 何よりもまず k8s バージョンアップによるクラスタ移行がサービスメンテナンス無しかつ社内でも他のチームとの調整なしに行えるようになったこと
- 課題であった 『DNS がキャッシュされており、リクエストが古いクラスタに向かってしまう』 という点が解消され、移行作業自体は 1 日もかからずに終わったこと
- 長期間になってしまうと AWS の料金が増えてしまったりコード管理が非常に面倒になってしまったりといった問題があったのでこれも非常に良かった
- 以前の記事にあった Ingress ごとに ALB が作成されてしまって効率が悪いといった点が改善されたこと
また今回のミッションを担当したことでスタディサプリENGLISHで利用している多くの AWS サービスについてある程度把握する必要があったので、それらに触れられ、学ぶことが出来たのが個人的にはとても良い機会でした。
まとめ
今回は k8s のバージョンアップを行うために改善したことや躓いたことなどを紹介しました。
TargetGroupBinding リソースを使うことによって DNS 切り替え無しでスムーズな移行が可能になり、今後 k8s の約3ヶ月という早いサイクルでのバージョンアップにもあまり工数をかけずに対応できるようになったと思います。
スタディサプリENGLISHの SRE グループでは、gRPC の運用について CloudMap を脱却して AppMesh に一本化したり、本番環境でクラスタのオートスケーリングを有効にできるように負荷試験やパフォーマンスチューニングを行うなど、今後も改善を進めていきます。