目次
こんにちは、スタディサプリ ENGLISH SRE グループの巻田です。
現在リクルートの夏アルバイトとしてこのチームに所属しています。
この記事では EKS クラスタにおいて Fargate 上で実行される CronJob に対して DataDog 及び CloudWatch を使用した監視を行う方法を紹介します。
背景
以前の記事にも書いた通り、スタディサプリ ENGLISH では CronJob の実行に Fargate を使用することを検討しています。1)/assets/rmp/techblog_bucket/infrastructure/post-20631/
従来から CronJob が実行されている Pod の監視には DataDog 及び CloudWatch を使用してきました。
これらのサービスを使用する際は Fluentd や DataDog Agent などのプログラムを DaemonSet として動作させる場合が多いと思います。 DaemonSet は各ノードごとに決められた Pod を配置するという機能ですが、ノードの存在が隠蔽されている Fargate においてはこの機能は使用できません。また、 Volume としてマウントできるのは EmptyDir のみとなります。これらの制約により、通常 DaemonSet として動作させることの多い DataDog Agent や Fluentd はそのままでは動かすことができず、 Sidecar コンテナとして Pod の中で動作させる必要があります。
システムの全体像
今回設計したのは以下のようなシステムです。
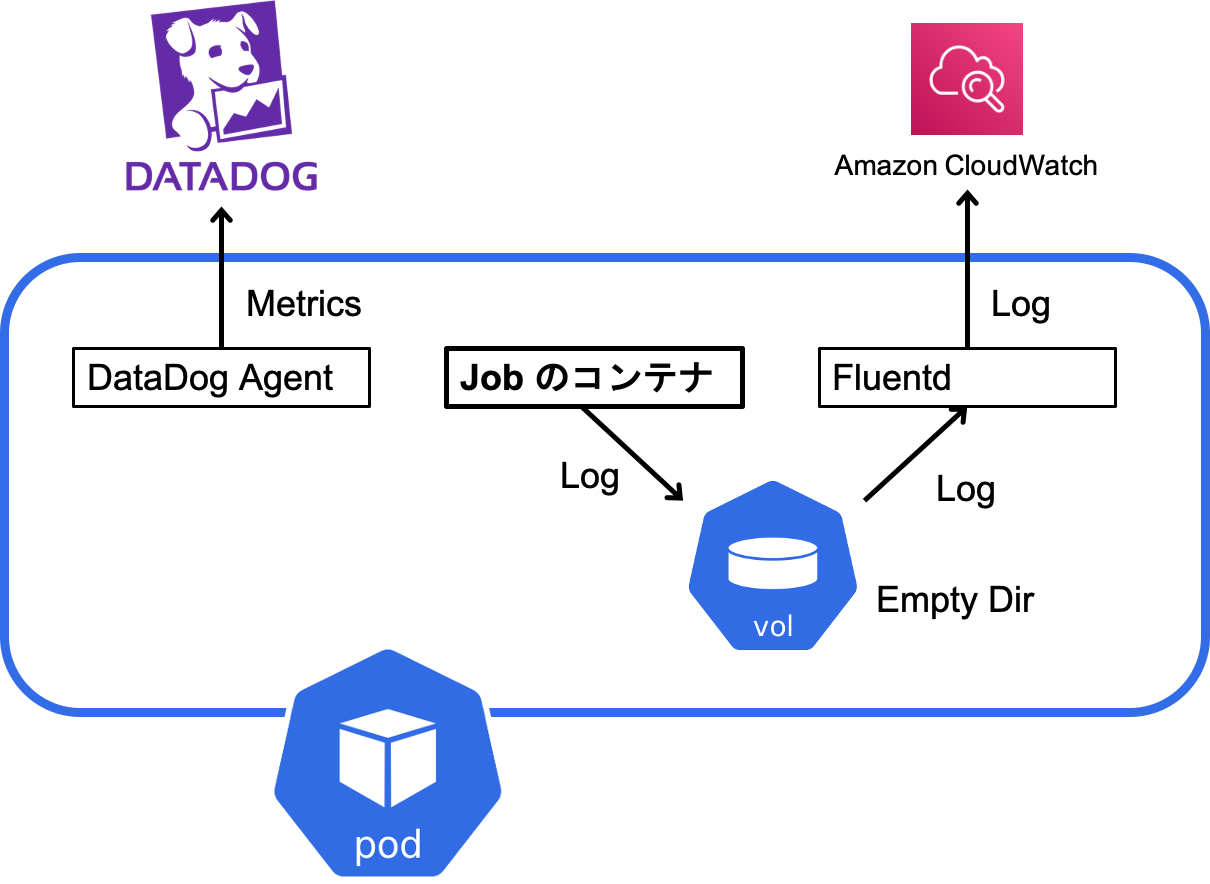
Fargate 関連のメトリクスは DataDog Agent によって収集され、DataDog に送られます。また、ログは Job が実行されるコンテナと、 Fluentd のコンテナの両方にマウントされる EmptyDir のボリュームに対して書き込まれ、それを Fluentd が CloudWatch に送信します。
DataDog を使用する
DataDog とはアプリケーションの監視を行うための SaaS です。今回は Fargate 上で実行するため DaemonSet ではなく Sidecar コンテナとして動作させます。
この方法は公式ドキュメント2)https://docs.datadoghq.com/ja/integrations/eks_fargate/ においても紹介されており、その方法でそのまま動きます。
ちなみに、自分は ClusterRole や ClusterRoleBinding を作るべきところを Role や RoleBinding を作ってしまい、見事にハマりました。これでは kubelet の API を使用するときにエラーになるので注意してください。
CloudWatch を使用する
CloudWatch とは様々なアプリケーションから様々なログやメトリクスを収集できる AWS のサービスです。今回はログ収集の機能を使用します。CloudWatch にログを送信する際には Fluentd を使用しています。
通常、 Pod 内のコンテナで動いているアプリケーションは標準出力やエラー出力にログを出力するのが一般的です。通常の EC2 ノードではコンテナの標準出力、エラー出力はサーバーホストの /var/log/containers ディレクトリ内に保存されます。EC2 上で DaemonSet として稼働する Fluentd に関してはこのディレクトリを Volume としてマウントし、このディレクトリ内のログを CloudWatch に転送しています。
しかし Fargate 上では先述の通り DaemonSet が使用できないため、この方法は使えません。そのため、 Pod 内のコンテナ間で共有できる場所にログをファイルとして出力し、そのファイルに書かれたログを Fluentd を使って CloudWatch に転送する必要があります。
具体的な手順
ここから紹介する方法は大まかには AWS の記事3)https://aws.amazon.com/jp/blogs/news/how-to-capture-application-logs-when-using-amazon-eks-on-aws-fargate/ に沿った設定を Terraform を用いて構築する方法です。手順としては大まかに Pod を実行するための ServiceAccount の設定、 Fluentd の設定があります。また、ログを標準出力やエラー出力ではなくファイルに出力する必要もあります。
Pod 実行用の ServiceAccount の設定
まず始めに ServiceAccount の設定をします。 EKS には OpenID Connect (OIDC)4)https://openid.net/connect/ プロバイダーの機能があり、この機能を使って特定の ServiceAccount を IAM Role に結びつけることができます。ここでは CloudWatch に書き込むための IAM ロールを作成し、それを Pod を実行するための ServiceAccount と紐づけます。
AWS における OIDC プロバイダーの設定に必要な項目として OIDC Provider の URL や Provider のサーバー証明書のサムプリント、 Client ID がありますが、そのうち OIDC Provider のサーバー証明書のサムプリントは AWS の機能のみで直接取得することができません。そこで、 TLS Provider にある Data Source である tls_certificate5)https://registry.terraform.io/providers/hashicorp/tls/latest/docs/data-sources/tls_certificate を使ってサーバー証明書の情報を取得するようにしています。
IAM ロール及び OpenID Provider の設定を行う Terraform のコードはこちらです。
data "tls_certificate" "provider_cert" {
url = data.aws_eks_cluster.eks-cluster.identity[0].oidc[0].issuer
}
resource "aws_iam_openid_connect_provider" "eks_oidc_provider" {
client_id_list = ["sts.amazonaws.com"]
thumbprint_list = [data.tls_certificate.provider_cert.certificates[0].sha1_fingerprint]
url = data.aws_eks_cluster.eks-cluster.identity[0].oidc[0].issuer
}
resource "aws_iam_role" "eks_cloudwatch_role" {
name = "eks-cloudwatch-role"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "${aws_iam_openid_connect_provider.eks_oidc_provider.arn}"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"${aws_iam_openid_connect_provider.eks_oidc_provider.url}:sub": "system:serviceaccount:sa-namespace:sa-name"
}
}
}
]
}
EOF
}
resource "aws_iam_role_policy_attachment" "eks_log_role_policy" {
policy_arn = "arn:aws:iam::aws:policy/CloudWatchFullAccess"
role = aws_iam_role.eks_cloudwatch_role.name
}
また、 ServiceAccount の設定を行う yaml ファイルはこちらです。ここでは先述の Terraform コードによって作成された IAM ロールの ARN が指定されています。
metadata:
name: sa-name
namespace: sa-namespace
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::***********:role/eks-cloudwatch-role
sa-namespace 及び sa-name は適宜実際の値に書き換えてください。
この設定をすることにより、 Pod の実行時には各コンテナの環境変数 AWS_ROLE_ARN に IAM ロールの ARN が書き込まれ、 AWS_WEB_IDENTITY_TOKEN_FILE に、トークンの書き込まれるファイルのパスがセットされます。
Fluentd の設定
ここでは Fluentd を使ってファイルに出力されたログを CloudWatch に送信できるように設定します。
Fluentd には CloudWatch にログを送信するためのプラグインがありそれがすでにインストールされた状態の Docker イメージを使用します。Docker Hub にあるイメージの中から CloudWatch に対応したものを使用しました。また、 Fluentd の設定ファイルは ConfigMap を Volume としてマウント 6)/assets/rmp/techblog_bucket/infrastructure/post-20439/しています。
CloudWatch ログを送信する部分の設定を以下に示します。そのほかの部分に関しては公式ドキュメントなどを参考にすれば書けると思います。
<match **>
@type cloudwatch_logs
@id out_cloudwatch_logs_containers
region "#{ENV.fetch('AWS_REGION')}"
log_group_name "log-group-name"
log_stream_name "#{ENV.fetch('NAMESPACE')}-#{ENV.fetch('POD_NAME')}"
remove_log_stream_name_key true
auto_create_stream true
<buffer>
flush_interval 5
chunk_limit_size 2m
queued_chunks_limit_size 32
retry_forever true
</buffer>
</match>
ロググループ名やログストリーム名は適宜書き換えてください。
このプラグインは特に設定しなくてもコンテナの環境変数やファイルシステムにある認証情報を使って CloudWatch に書き込んでくれます。
ログをファイルに出力する設定
Fluentd では基本的にログファイルに出力されたものを読み取ってそれを CloudWatch に送信しています。そのため、標準出力やエラー出力にログを出力するアプリケーションの場合は出力されたものをファイルに書き込んでおく必要があります。 Linux の tee コマンドを使用することで標準入力で受け取った入力をそのまま標準出力に出力しながら指定したファイルにも同じ内容を書き込むことができます。
ここで、単純にパイプで繋ぐだけではコマンド自体の終了コードが処理全体の終了コードとならないことに注意してください。つまり command | tee /path/to/file とした場合には command の終了コードが 0 以外であっても tee コマンドの終了コードが 0 であれば処理全体の終了コードは 0 となってしまいます。それに対処するには set -o pipefail をコマンドの前に追加して、パイプよりも左のコマンドが失敗したときには確実に 0 以外の終了コードが返るようにします。
これらの説明を元に、以下のようなシェルスクリプトを書けば良いことが分かります。
set -o pipefail; job_command 2>&1 | tee /path/to/log
後は、 Fluentd のコンテナと CronJob が実行されるコンテナの両方に EmptyDir をマウントしてその中にログファイルを出力するようにすればアプリケーションのログを Fluentd が読み取ることができるようになります。
Sidecar コンテナを停止する方法
CronJob や Job には、必要な処理が終わればその Pod は終了する、という特徴があります。
つまり、Job の本体が動作するコンテナが終了したときには Pod に含まれるコンテナは Sidecar コンテナも含めて停止される必要があります。
しかし、単に DataDog agent や Fluentd を sidecar として実行しただけでは Job 本体のコンテナの終了を検知して自分で停止するという機能はありません。
そのため、Job の終了時に sidecar コンテナを停止させるための処理を入れる必要があります。ちなみに、この終了処理は Pod 内のコンテナが実行する command に追加してください。 (preStop はコンテナが自動的に終了したことを検知するのには使えません。)
(執筆時点では Sidecar コンテナをそれ以外のコンテナが終了した際に自動的に終了させる機能が Kubernetes 1.19 から追加されることが検討されています。7)https://github.com/kubernetes/enhancements/issues/753)
DataDog
DataDog に関しては、コンテナ外部から停止させる方法は公式には見つかりませんでしたが、DataDog のコンテナ内から実行できるagentコマンドを使用し、agent stopを実行すると DataDog Agent が停止する、という機能があります。8)https://docs.datadoghq.com/ja/agent/guide/agent-commands/?tab=agentv6v7#agent-%E3%81%AE%E5%81%9C%E6%AD%A2
DataDog Agent のソースコードは GitHub で公開されているので誰でも読むことができ、それによってagent stopの内部的な動作を確認することができます。9)https://github.com/DataDog/datadog-agent
DataDog のプロセスはDD_CMD_PORTの環境変数で指定したポートにて HTTPS 接続を待ち受けており、そこに対して、DD_AUTH_TOKEN_FILE_PATHの環境変数で指定されたパスにあるファイルに格納されているセッショントークンをBearerトークンとして Authorization ヘッダーに格納してリクエストを送信することで、外部から
ちなみに、セッショントークンを格納するファイルにあらかじめセッショントークンの値を書き込んでおけば DataDog Agent は自動的にその値を使用します。
つまり、セッショントークンが格納されるディレクトリを Pod 間で共有できるようにしておけばコンテナの外から DataDog Agent を停止させることができることになります。
具体的には以下のようなコマンドで同じ Pod 内の別のコンテナにある DataDog agent を停止させることができます。
curl -X POST -H "Authorization: Bearer `cat /path/to/token`" -k https://localhost:[port]/agent/stop
その他、TLSで使用されるサーバ証明書の検証を無効化する必要があることに注意してください。
Fluentd
Fluentd に関しては、公式ドキュメント 10)https://docs.fluentd.org/deployment/rpc にも書かれている通りhttp://localhost:rpc_port/api/processes.flushBuffersAndKillWorkersに GET リクエストをすることでログを全て送信した後に Fluentd を停止させることができます。
また、rpc_port には設定ファイルで以下のように設定したポートを使用してください。
<system>
rpc_endpoint 0.0.0.0:12345
</system>
終わりに
この記事では EKS において Fargate 上で実行される CronJob に対して DataDog や CloudWatch を使って監視する方法を紹介しました。Fargate 上での CronJob というややレアな (?) 環境ではありますが、同じような環境を構築するときには是非参考にしてみてください!
冬アルバイトも募集中
現在僕が参加しているリクルートでのアルバイトですが、冬アルバイトも現在募集中です。興味のある方はぜひチェックしてみてください! https://engineers.recruit-jinji.jp/event/job-for-student-2021w/
脚注