目次
はじめに
こんにちは!リクルートで検索エンジニアをしている中野 ( @y_nak6 ) です。 私は 2025 年 7 月にイタリア北部のパドヴァで開催された SIGIR 2025 に現地参加しました。 本記事では、会議の概要と、特に興味深かったセッションや論文を中心に紹介します。
SIGIR 2025 とは
SIGIR(Special Interest Group on Information Retrieval)は情報検索(Information Retrieval, IR)分野におけるトップ国際会議の 1 つです。 メインのトピックは検索モデルやランキング、その評価などですが、近年は推薦システムの比重も高まってきています。
今年の SIGIR は、2025 年 7 月 13 日から 17 日までの 5 日間にわたり、イタリアのパドヴァで開催されました。 パドヴァはヴェネチアからバスで 50 分ほどの距離にある歴史的な都市で、落ち着いた雰囲気の中で会議が行われました。

参加統計とトレンド
カンファレンスで発表された主要な統計情報を以下で紹介します。
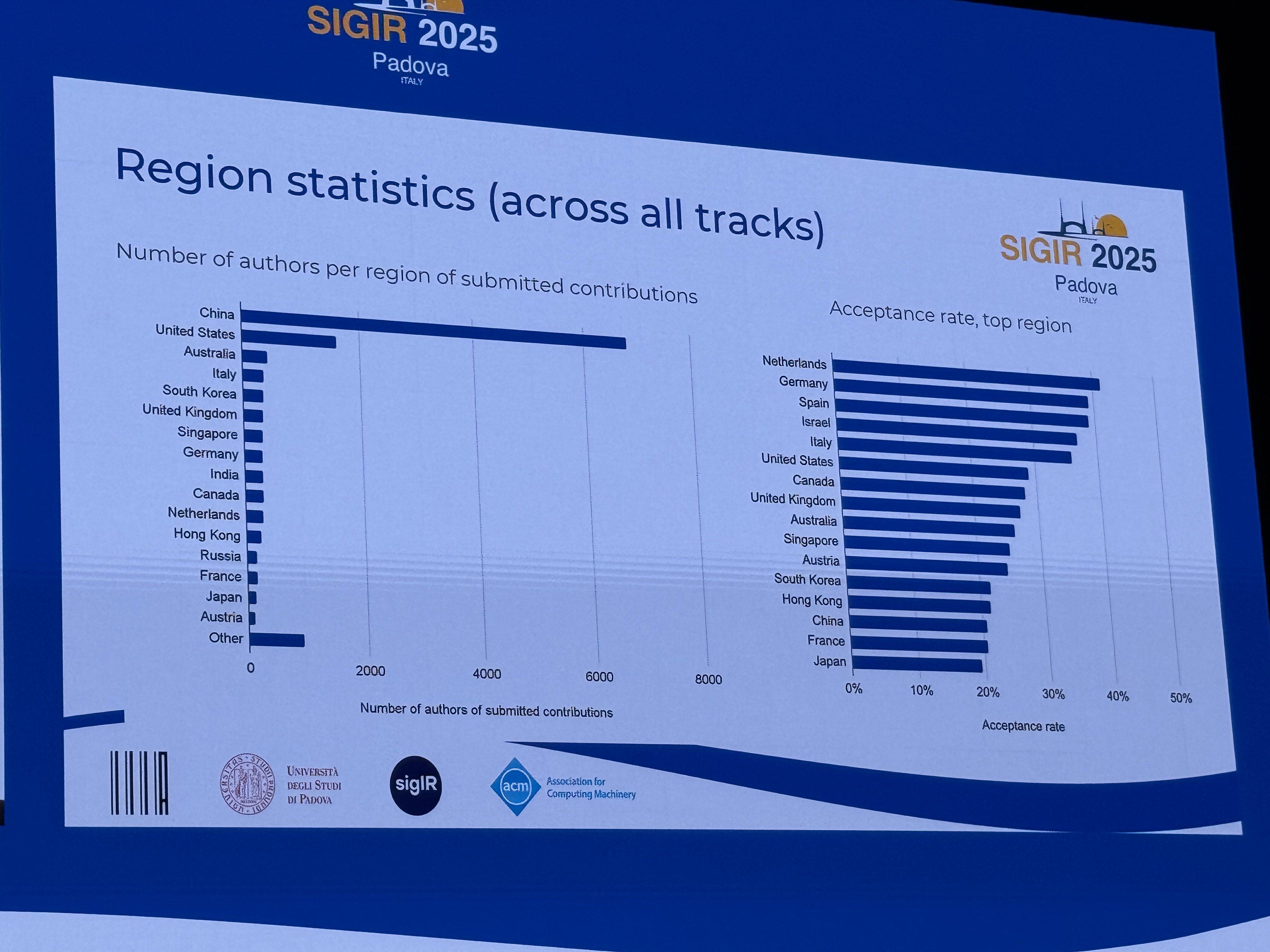
日本は参加者数では 9 番目、論文投稿数では 15 番目、採択率は 16 番目という結果でした。 リクルートからも、リクルートグループの研究所である Megagon Labs の以下の論文が採択されています。
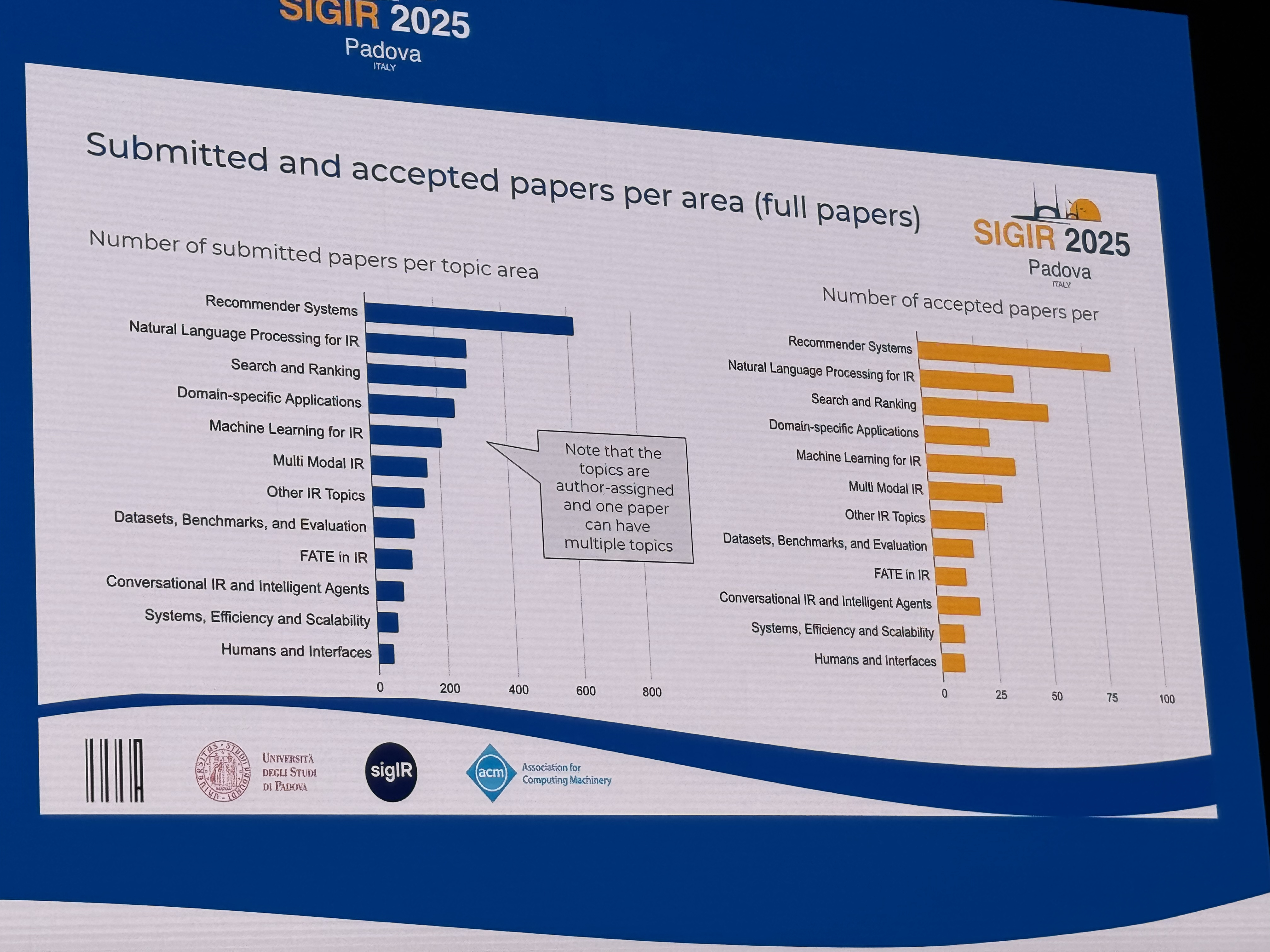
論文の採択トレンドを見ると、以下のトピックが投稿数の上位を占めていました。
- Recommender Systems
- Natural Language Processing for IR
- Search and Ranking
- Domain-specific Applications
- Machine Learning for IR
これらのトピックに関する投稿数や採択数が多い傾向自体は、以前から大きくは変わっていません。 一方で、「Natural Language Processing for IR」の採択率が比較的低かった点が印象的でした。 この傾向は、LLM(Large Language Model、大規模言語モデル)がホットトピックであり、投稿数も増えている一方で、情報検索コミュニティがその応用に対して高い新規性を求めていることを示唆していると考えています。 その結果、多くの論文が採択のハードルを超えられなかったのではないかと推測しています。
印象に残ったセッションと論文
ここでは、私が聴講した中で特に興味深く、参考になったセッションと論文を紹介します。
チュートリアル: R2LLMs: Retrieval and Ranking with LLMs
検索システムは、大量のアイテムの中から検索条件に合致する数件のアイテムを短時間で返す必要があります。 そのため、検索システムは以下の 2 段構成になることが一般的です。
- Retriever: 大量のアイテムからざっくり絞り込む
- Ranker: 絞り込まれた数少ないアイテムを、より精緻に並び替える
このチュートリアルでは、LLM の登場によって Retriever と Ranker がどのように変化したかを、基礎から最先端まで網羅的に解説しています。 具体的な変化としては主に以下の 2 つが挙げられていました。
- 利用されるモデルが BERT1 系のモデルから LLM に変わったこと
- より大規模な事前学習から得られる膨大な知識の恩恵を受けられることで、Fine-tuning した際だけでなく、Zero-shot での検索精度も向上
- 学習データを容易に作成できるようになったこと
- 以前より安価に高品質な学習データを作成できるようになり、これを利用してモデルを学習することで検索精度が向上
加えてこのチュートリアルで個人的に面白かった点としては、推論タスクや推論モデルなど、LLM の最先端と情報検索分野との関連にも触れられていたことが挙げられます。 推論モデル(reasoning model)である OpenAI o1 が登場して以降、様々な推論モデルが公開されました。 その流行に伴い、情報検索においても BRIGHT2 などの推論が必要とされるデータセットが登場してきています。
BRIGHT データセットの特徴を下図の具体例で説明します。 従来の情報検索のデータセットにおいて、例えば「Yellowstone 国立公園の名前の由来は?」というクエリがあったとします。 このとき検索結果としては、Yellowstone 国立公園や Yellowstone 川に関する文書を検索できれば正解となります。 つまり従来のデータセットでは、クエリに含まれる単語と完全に、もしくは意味的に一致する文書が検索できれば正解となります。
一方で BRIGHT データセットには、例えば「100 人いるときに同じ誕生日の人は少なくとも何人?」というクエリがあります。 このとき検索結果としては、例えば「鳩の巣原理」に関する文書を検索できれば正解となります。 このように BRIGHT データセットでは、問題解決の糸口になりそうな文書など、従来とは違った観点で文書を検索できる能力が求められているという特徴があります。
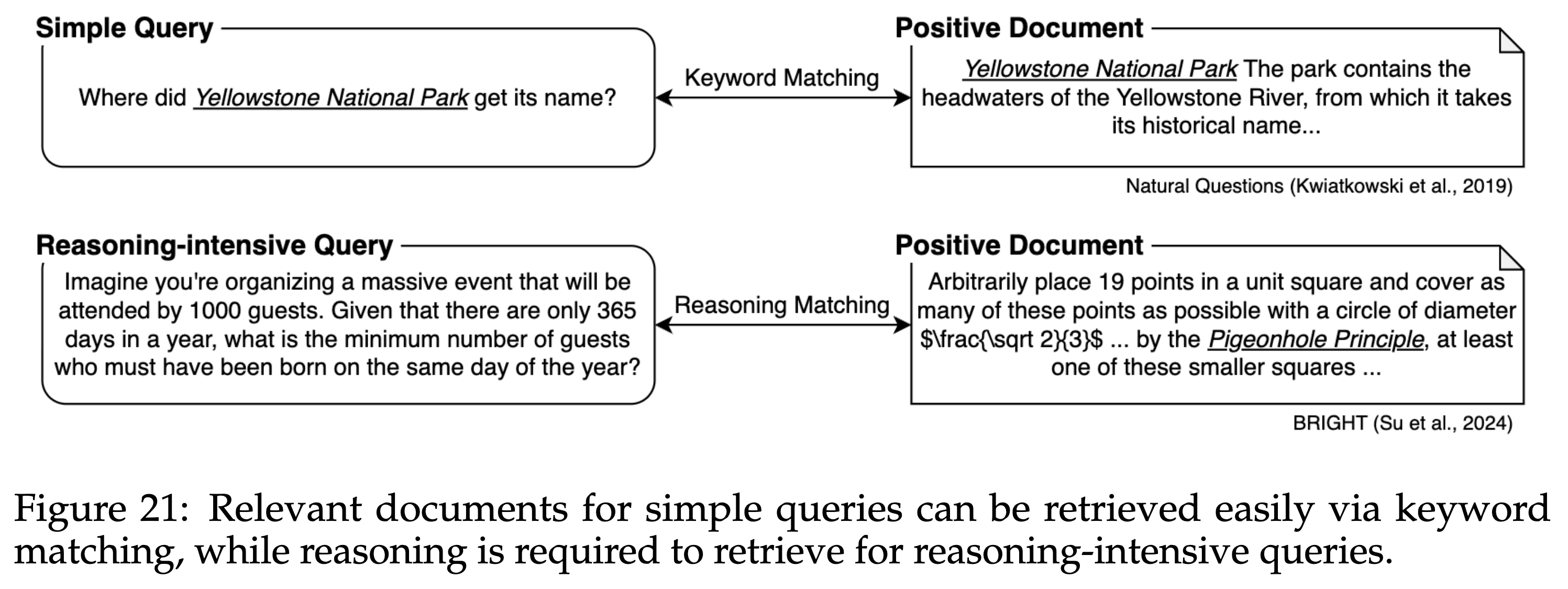
引用: Shao et al., ReasonIR: Training Retrievers for Reasoning Tasks (COLM 2024)
このようなデータセットにおける課題を解くために、Retriever と Ranker のそれぞれで手法が提案されています。 こちらに関しては外部の論文読み会でも発表したスライドがあります。もしご興味があればご覧ください。 https://speakerdeck.com/ynakano/irreadings2025fall-information-retrieval-and-reasoning-tasks
感想
このチュートリアルは LLM 登場以降に Retriever と Ranker がどのように発展していったかを網羅的に解説してくれており、非常に勉強になりました。 その後の論文発表などを聞いていても、LLM を実際の検索システムで利用するのは当然になってきていると感じており、その点でもこのチュートリアルは参考になりました。
また、こちらのチュートリアルに関しては、スライドも以下で公開されています。 ご興味のある方はぜひこちらもご覧ください。 https://ielab.io/tutorials/r2llms.html
LLM-based Query Expansion Fails for Unfamiliar and Ambiguous Queries
ユーザが検索システムを利用する際には、自分が検索したいことをうまく言葉にできず、意図が不明確になることがあります。 このような場合に、入力されたクエリをシステム側で書き換えることで、検索の精度を向上させることが考えられます。 これはクエリ拡張(Query Expansion)と呼ばれており、近年は LLM の言語知識を活用したクエリ拡張の研究が盛んに行われています。
このような状況において、LLM ベースのクエリ拡張が失敗するのはどんなときかを幅広く調査したのがこの研究です。 この研究では、以下の 2 つの場合において、LLM ベースのクエリ拡張がうまくいかないことを明らかにしました。
- クエリに関する知識を LLM が持っていない場合
- 特に what/who など事実を問うクエリにおいて、クエリ拡張手法によっては誤った固有名詞を拡張しやすく、検索精度が下がりやすい傾向
- クエリ自体に複数の解釈があり曖昧な場合
- 複数の解釈のうち、人気のある解釈に寄せてしまい、そうでない解釈の文書を漏らしてしまう傾向
感想
本研究は LLM ベースのクエリ拡張がどのようなときに失敗するのかを徹底的に調査しており、検索エンジニアとして非常にありがたいと思いました。 1 つ目の知識不足という課題に関しては実応用においてもかなり重要だと感じており、LLM をそのまま使うのではなく、企業が持つ独自のデータを活用する必要性を強く感じました。
2 つ目の曖昧性については、プロンプトや学習データなどモデル側の改善で解決する方法もありそうです。 一方で、曖昧な場合はユーザにその意図を聞き返したり、クエリの解釈を関連クエリとして推薦したりするなど、UI/UX 側の改善で解決する方法もありそうです。 これらの点において、本論文は検索エンジニアとして様々なアイデアが湧いてくる良い論文だと思いました。
From Keywords to Concepts: A Late Interaction Approach to Semantic Product Search on IKEA.com
この論文は SIRIP (The SIGIR Symposium on IR in Practice) という企業向けセッションで採択された、IKEA による複数ベクトル検索の導入事例です。 ベクトル検索自体は既に世の中で広く用いられており、リクルートグループにおいても活用されています。
導入例: Two-Tower モデルと近似最近傍探索による候補生成ロジックの導入
一方で本事例の特徴的な点として、通常のベクトル検索ではなく、複数ベクトル検索を導入したことが挙げられます。 通常のベクトル検索では下図左のように、ユーザが入力したクエリと検索対象のアイテムをそれぞれ 1 つのベクトルにし、その類似度を計算します。 これに対して複数ベクトル検索では下図右のように、クエリとアイテムを複数のベクトルにし、それらを組み合わせて類似度を計算します。
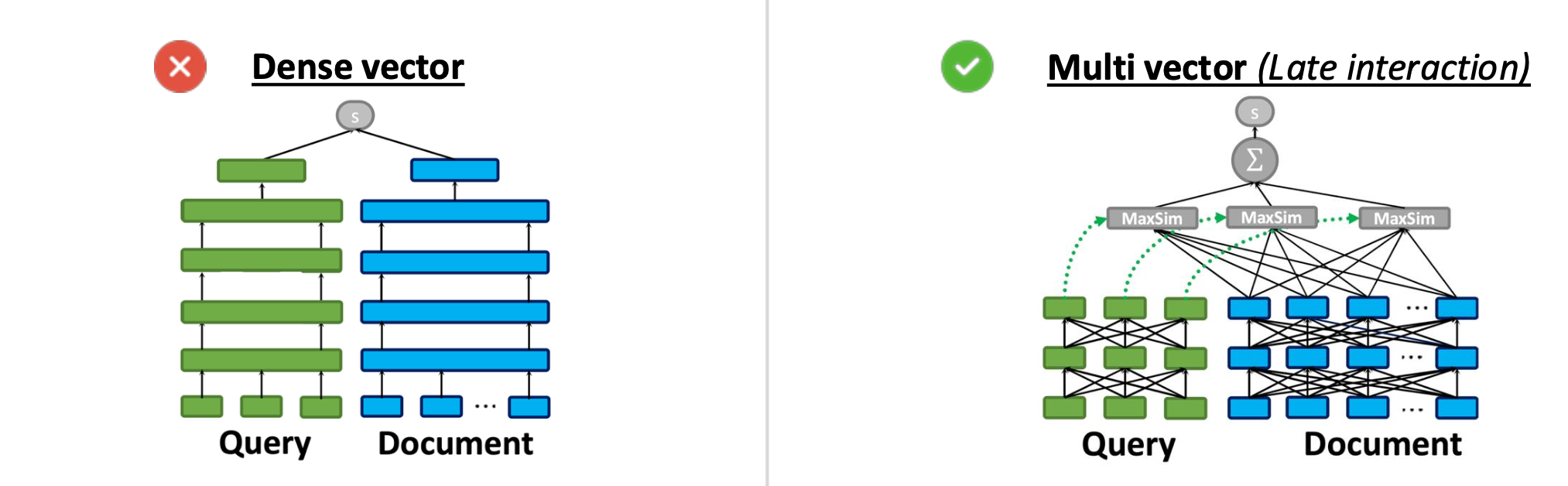
引用: 本事例の発表スライドより
1 つのベクトルに集約する通常のベクトル検索とは違って、複数ベクトル検索ではクエリとアイテム間のより細かい違いを区別することができ、検索精度が高いと言われています。 本事例においても、例えば “200 cm tall wardrobe” と “230 cm tall wardrobe” を区別することは、通常のベクトル検索では難しく、複数ベクトル検索を導入する動機として語られていました。
一方で複数ベクトル検索は通常のベクトル検索より遅く、この課題を解決するために様々な研究が行われてきました。 本事例では、PLAID3 という既存の高速化手法を活用することで、3 万件以上の商品に対する複数ベクトル検索を 30 ms 以内に抑えることに成功したと報告されています。
その他にも本事例には、複数ベクトル検索の有効性を高めるために、以下の工夫が実施されていました。
- LLM を用いた多様な学習データの作成
- より難しい負例 (hard negative) をサンプリングするために(従来の)ベクトル検索を活用
- 無関係なアイテムを除外するために検索結果に適応的なスコアの閾値を設定
これらを導入した結果、A/B テストでは CVR (conversion rate) が +1.96% 向上するなど、大きなビジネス成果に繋がったことが報告されています。
感想
ColBERT や PLAID などの複数ベクトル検索の話題は、社内の検索勉強会でも度々取り上げられ関心も高いですが、実システムへの適用例自体は少ないという認識でした。 その点でこちらの IKEA の事例は、複数ベクトル検索を実システムに導入する上で大きなヒントになりそうであり、非常に興味深いと感じました。
こちらの研究論文は残念ながら一般公開されていませんが、発表スライドは以下で公開されています。 ご興味のある方はぜひこちらもご覧ください。 https://sigir2025.dei.unipd.it/detailed-program/paper?paper=2c6ae45a3e88aee548c0714fad7f8269
まとめと感想
今回 SIGIR に現地参加し、情報検索分野の最先端を学び、大学や企業の研究者・エンジニアと交流することで、非常に良い刺激となりました。 今後は今回得た知見をプロダクトに反映しつつ、そこで得た知見を情報検索コミュニティに還元する、といった良い循環を作れるように取り組んでいきたいと考えています。
-
Devlin et al., BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (NAACL 2019) ↩︎
-
Su et al., BRIGHT: A Realistic and Challenging Benchmark for Reasoning-Intensive Retrieval (ICLR 2025) ↩︎
-
Santhanam et al., PLAID: An Efficient Engine for Late Interaction Retrieval (CIKM 2022) ↩︎