目次
はじめに
こんにちは。社内横断で利用されるデータ基盤 Crois の開発を担当している、茅原です。
本記事では、Croisと呼ばれる内製データ基盤の運用にAIOpsを導入し、AIエージェントの導入によってプロダクト運用タスクを自動化した事例を紹介します。
目次
背景
Croisとは
Croisは、リクルートで開発されている横断データ基盤であり、ワークフローエンジン・ジョブスケジューラ機能を提供するプロダクトです。
機械学習・推論パイプラインやETLなど、リクルートのデータ施策を支える様々なジョブが大量に実行されています。
2025年11月時点での稼働規模は以下の通りです。
- ジョブ実行数: 22,000ジョブ/日
- コンテナ実行数: 74,000コンテナ/日
- アクティブユーザー数: 300MAU
- ピークCPUコア数: 30,000vCPU
SRE文化の醸成とAIOps導入の機運
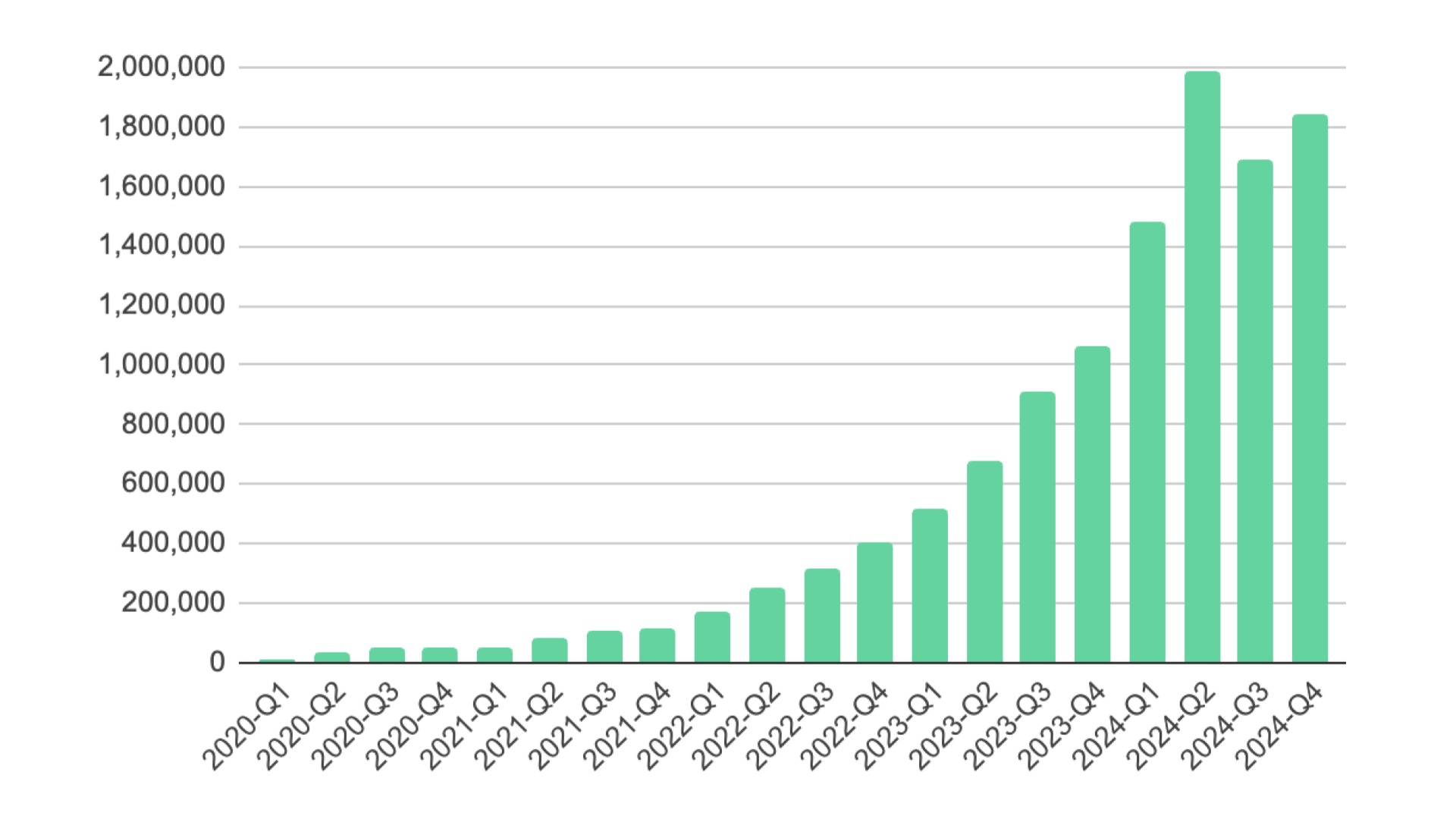
2022年ごろから会社統合や内部プロダクトとの機能統合により、Croisの利用量が大幅に増加しました。これに伴い、Croisの運用業務の負荷が増大していました。
これらの負荷に対応するため、Croisとしては以下のような取り組みを地道に行ってきました。
- プラットフォームエンジニアリングの実践
- ドキュメント文化の醸成
- 不要なアラート(オオカミ少年アラート)の削減
- 問い合わせフローの整備
- 運用チームの発足・育成
結果的に、たくさんのドキュメントが整備され、運用業務の属人性が低減し、Toilとなる業務の削減・自動化を行う文化が醸成されていきました。このような地道なSRE活動により、Croisの運用効率化はある程度達成できていました。
しかし、そうは言っても、運用チームが担っているタスクの中には、人間がやるには冗長で時間がかかるものの、スクリプトで自動化するには抽象的かつ難しいタスクが残っていました。具体的には、利用者からの問い合わせ対応やアラート対応など、時々のインフラの状況を踏まえた判断が必要なタスクなどです(詳細は 自動化対象の選定 で説明します)。
一方で、Croisではこれまでの取り組みにより、型化された運用ドキュメント(= ランブック1)が豊富に蓄積されていました。これらのドキュメントとAIを組み合わせれば、これまで自動化しきれていなかった範囲の自動化を達成できるのではないかと考え、AIエージェントを用いたプロダクト運用業務の自動化(= AIOps 2)の可能性に期待し、検討を始めました。
CroisへのAIOpsの導入
自動化対象の選定
前述の通り、運用チームが担っているタスクの中には、人間がやるには冗長で時間がかかるものの、スクリプトで自動化するには抽象的かつ難しいタスクがありました。これらのタスクから、AIエージェントによる自動化ができそうなものを以下のように選定しました。
- 利用者からの問い合わせ対応
- Croisの利用者からの、技術的な質問への回答。インフラ調査を伴うものも含む。
- アラート対応
- インフラ調査を伴うアラートの原因特定/対応の必要有無の判断。
- 簡単な開発作業
- バリデーション追加やパラメータ変更など。
- 定型依頼対応
- 通信の穴あけや権限設定など。
これらのうち、3,4についてはCursorやGitHub Copilotに対応ドキュメント(ランブック)を与えるだけでほとんどの自動化が達成できることが早い段階でわかりました。
一方で、自動化できた場合の恩恵が大きいのは1,2です。 1,2は3,4よりも定型化することが困難で、その時々のインフラの状況に応じた柔軟な判断が必要です。
そのため、単にドキュメントを与えるだけでは対応できず、AIエージェントがクラウドインフラのログやソースコードの適切な部分を参照して、自律的に調査を進めていく必要があります。
AIエージェントによる運用タスク自動化がどこまでのタスクを解けるのか?という点が気になっていたこともあり、この1,2のタスクを自動化するAIエージェントを開発することに決めました。
Crois運用エージェント “クロサイ”
選定されたアラート対応・問い合わせ対応という運用タスクを自動化するため、AIエージェント「クロサイ」3 を開発しました。
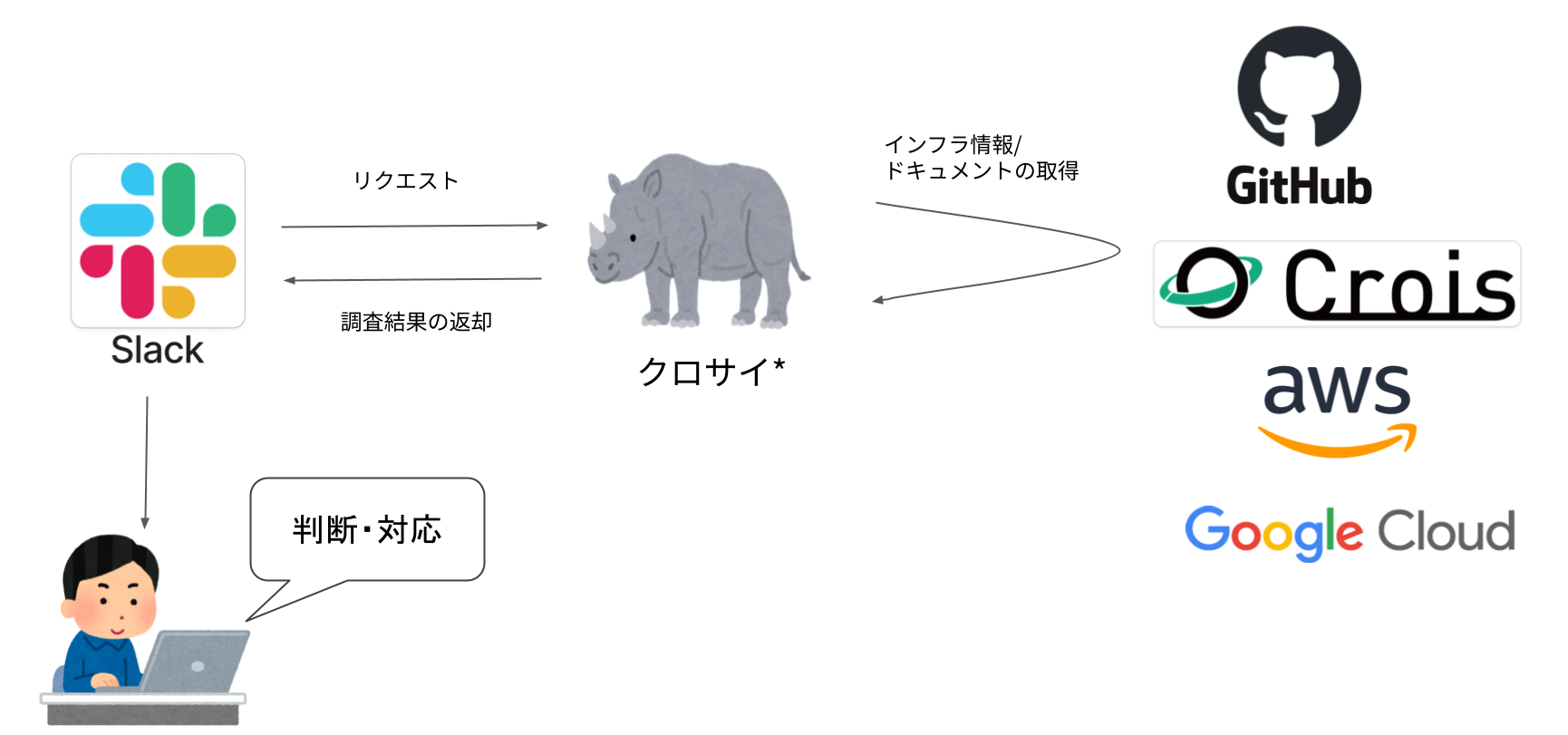
クロサイは以下の流れで動作します:
- リクエスト受信 - 利用者からの問い合わせやアラートを受信
- インフラ情報・ドキュメントの取得 - 関連するインフラリソースや関連ドキュメントを調査
- 判断・対応 - 取得した情報を基に適切な対応を判断
- 調査結果の返却 - 利用者に結果を報告
クロサイによるアラート対応
CroisにおけるアラートはSlack上に連携されるようになっています。 クロサイはこのSlack上のアラートに即座に反応し、対応を自動的に開始します。
Croisでは、ほとんどすべての個別アラートに対応するランブックが整備されており、そこには
- アラートの内容
- アラートに関連するクラウドリソース
- 調査に使うコマンド
- 調査結果の判断
などが記載されています。
実際のランブックの記述例(クリックで展開)
»> 以下はランブックの引用です
004:Crois Jobは正常終了したがstarted_atの値が入っていない
GKEヘルスチェックで、タスクのstarted_atの値が取得できずworkergroupのチェックに失敗した場合の対応手順。
原因・背景
started_atに値がない状況は想定外の挙動で調査が必要となるため、発生した場合はアラートを出力する。
フローチャート
flowchart TD
E4[004:Crois Jobは正常終了したがstarted_atの値が入っていない] --> G4[started_atの値を確認]
G4 --> H4{値が設定済み?}
H4 -- はい --> I4[次回正常なら対応不要]
H4 -- いいえ --> J4{連続発生?}
J4 -- はい --> K4[チーム共有し対応検討]
J4 -- いいえ --> I4
対応手順
-
以下のいずれかの手順で各タスクのstarted_atの値を確認する。
- 手順A(WebUI) : UIから確認する場合はジョブ詳細画面(
/jobs/<Job ID>/)のワークフローダイアグラム内の該当タスクをホバーして確認 - 手順B(API) : APIから確認する場合は
GET /v1/jobs/<Job ID>/のtasksの各要素のstarted_atから確認する。# Crois APIトークンを指定する。 CROIS_API_TOKEN="<Crois APIトークン>" # 各環境に合わせてAPIのURLを設定する if [ "$CROIS_ENV" = "prd" ]; then API_BASE_URL="https://api.v2.r-crois.jp" else API_BASE_URL="https://api.v2-${CROIS_ENV}.r-crois.jp" fi curl -s -X 'GET' \ ${API_BASE_URL}'/v1/jobs/'${JOB_ID}'/' \ -H 'accept: application/json' \ -H 'Authorization: Token '${CROIS_API_TOKEN} \ | jq -r '.tasks | to_entries[] | "\(.key): \(.value.started_at)"'
- 手順A(WebUI) : UIから確認する場合はジョブ詳細画面(
-
タスクのstarted_atの値の有無によって、以下の手順を実施する。
- started_atに値が設定されている場合
- started_atの書き込みが遅延していたと考えられる。 次回のヘルスチェックがエラーなく終了することを確認した上で対応不要としてクローズする。
- started_atに値が設定されていない場合
- 同様にstarted_atが書き込まれていないことによるヘルスチェックのエラーが二回以上連続して発生している場合はチームに共有し対応を検討する。
- アラートが連続して発生していない場合は対応不要としてクローズする。
- started_atに値が設定されている場合
エラーログのサンプル
このエラーの種類のエラーログのサンプルは以下の通り。
[ERROR] 2025-06-18T02:34:38.052Z 39fad1bd-4d81-47e7-ad18-fbdb93b57860 [healthcheck] error: started_at has no value tasks:normal-4
[ERROR] AssertionError: started_at has no value tasks:normal-4
Traceback (most recent call last):
File "/var/task/main.py", line 300, in handler
healthcheck(context, normal_workflow_name)
File "/var/task/main.py", line 193, in healthcheck
raise ex
File "/var/task/main.py", line 189, in healthcheck
job = check_job_detail_api(client, job_id, timeout_sec=int(context.get_remaining_time_in_millis() / 1000) - 60)
File "/var/task/main.py", line 103, in check_job_detail_api
raise AssertionError(f'started_at has no value tasks:{", ".join(none_started_at)}')
«< ランブックの引用終わり
クロサイはこのようなランブックを参照しながら、アラートに関連するクラウドリソースを調査し、調査結果と対応方法を提案します。 以下、実際にクロサイがアラート対応を行った例を示します。
# crois-v2:prd:lambda core-v2-crois-gke-health-checker
## アラートの原因
**004:Crois Jobは正常終了したがstarted_atの値が入っていない**
ジョブID:16852935の`normal-1`タスクの`started_at`フィールドに値が設定されていないため、ヘルスチェック処理でエラーが発生しました。ジョブ自体は`SUCCEEDED`ステータスで正常に終了していますが、`started_at`の書き込みが遅延もしくは欠損したことが原因と考えられます。
## 調査内容
### 1. ログの収集
- **期間**: 2025-11-04T18:01:00.000Z ~ 2025-11-04T18:31:00.000Z(アラート発生時刻±15分)
- **エラーログ**:
[ERROR] 2025-11-04T18:14:40.914Z 2291eeee-6a4e-4d2f-ac8b-1d6437bc4b97 [healthcheck] error: started_at has no value tasks:normal-1
- **リクエストID**: 2291eeee-6a4e-4d2f-ac8b-1d6437bc4b97
- **ジョブID**: 16852935
### 2. ジョブ詳細の確認
- **ジョブステータス**: SUCCEEDED (正常終了)
- **ワークフロー**: GKEヘルスチェック(正常系) (ID: 13723)
- **実行時間**: 2025-11-05 03:00:37 ~ 2025-11-05 03:03:54
- **問題のタスク**: normal-1のstarted_atが`null`
- **他タスク**: normal-2, normal-3, normal-4, module-error-retryは全て正常にstarted_atが設定されている
### 3. 連続発生の確認
- **前後12時間の調査**: 2025-11-04T18:00:00.000Z ~ 2025-11-05T06:00:00.000Z
- **結果**: 今回のエラー以外に同様のエラーは発生していない(単発エラー)
## 推奨される対応
**対応不要 - クローズ**
ランブック手順004に基づく判断:
- started_atに値が設定されていない状況を確認
- 同様のエラーが連続して発生していない(単発エラー)
- 次回のヘルスチェックでエラーが発生していない
このため、started_atの書き込み遅延による一時的な問題と判断し、対応不要としてクローズします。今後、同様のエラーが連続して発生した場合は、チームに共有して対応を検討する必要があります。
このようにランブックの該当箇所を参照し、クラウドインフラの適切な箇所を調査した上で、結論を出していることがわかります。
ランブックが整備されていたとしても、ランブックとインフラを交互に確認しながら、アラートの度に原因や対応方法を調べるのは人間にとっては煩雑な作業です。
特にCroisのように多くのクラウドリソースで構成されているプロダクトにおいては、該当するエラーログにたどり着くまでにも一定の知見と労力が必要です。
その点クロサイは、ランブックを参照し、時には手順を適宜補完しながら、自律的に調査を進めていくことができます。人間がやるには煩わしい作業をAIが代替してくれており、負担が減っています。
また、クロサイの出力は運用担当者により手動で評価しており、回答の正確さ・分かりやすさ・網羅性の観点を四段階で評価しています。 以下が評価結果のグラフです。
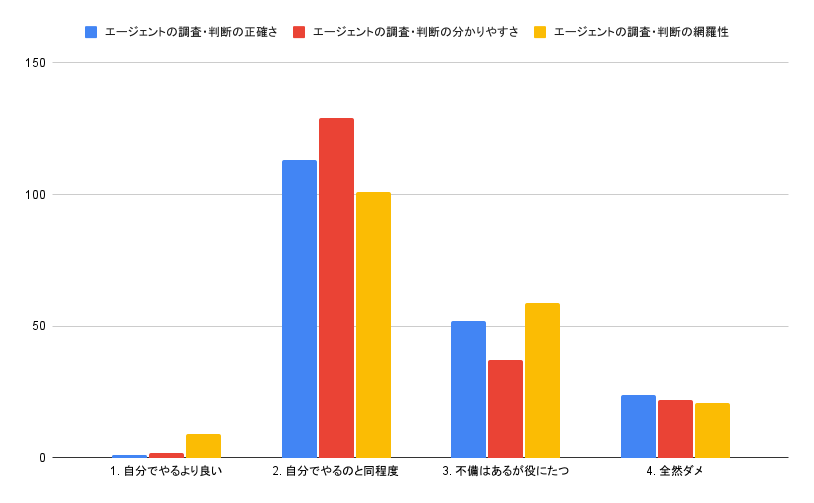
半分以上のアラートについては、クロサイの出力が運用担当者が自分で対応する場合以上の評価を得ていることがわかります。
また、少数ですが「自分でやるよりも良い」という評価があります。そのような評価を得た出力を吟味すると、これは実際の運用担当者であっても対応に苦労するケース(ex. ランブックが未整備/初めて遭遇するエラー)でも、クロサイが適切に対応できていたことを示していました。
次に、アラート対応以外の活用例として、利用者からの問い合わせ対応について紹介します。
問い合わせ対応の実例
Croisでは社内の利用者から日々様々な問い合わせがあります。
Croisでは利用者向け公式ドキュメントも公開していますが、それらに記載がないような細かい仕様や、開発側が想定していないようなジョブ失敗・不具合等についての問い合わせが多くあります。
これらの問い合わせについても、クロサイがソースコードやインフラの情報を参照し、以下のように問い合わせに回答することができています。
問い合わせ例:
job id xxxxx のジョブが失敗しているがUI上にログが出力せずに原因がわからない
問い合わせ対応出力例:
ジョブID xxxxx の失敗原因は**コンテナイメージの問題**です。
## 問題の詳細
**エラーメッセージ:**
- CannotPullContainerError: no matching manifest for linux/amd64 in the manifest list entries
- Task failed to start
## 根本原因
run-my-module タスクで使用している tutorial_20250910 モジュールのコンテナイメージに、**linux/amd64 アーキテクチャ用のマニフェストが存在しない**ことが原因です。
これは以下のいずれかの状況を示しています:
1. **コンテナイメージが異なるアーキテクチャ(例:linux/arm64)でのみビルドされている**
2. **マルチアーキテクチャ対応のマニフェストリストが正しく作成されていない**
3. **コンテナイメージのタグが間違っているか、存在しない**
## 解決方法
1. **コンテナイメージの再ビルド**: tutorial_20250910 モジュールのコンテナイメージを linux/amd64 アーキテクチャで再ビルドしてください
2. **マルチアーキテクチャ対応**: 複数のアーキテクチャをサポートするマルチアーキテクチャイメージを作成してください
3. **イメージタグの確認**: 使用しているイメージタグが正しく存在することを確認してください
このエラーのため、タスクは開始すらできず、約44分後にタイムアウトで失敗しています。
一見すると典型的なエラーメッセージに対応しているように見えますが、このエラーメッセージにたどり着くには、以下のような知識が必要です。
- ジョブに対応するインフラリソースは何か
- ジョブ関連リソースはECS, Lambda, Stepfunctions, SQS…等多岐にわたる
- インフラリソース名はどのように決まるか
- 対応するインフラリソースはどこにログを出力するか
これらを一つ一つ調べていくのは人間にとって煩雑な作業です。一方で、クロサイはソースコードやインフラの情報、既存のドキュメントを参照することで、網羅的にインフラの状況を調査することで、上記のようなエラーログに素早くたどり着き原因を特定することができます。
ただ、アラート対応よりも問い合わせ対応の場合の方が問題が多様であり、クロサイではうまく解けないケースがあるのも事実です。 しかし、インフラの状況を網羅的に調査した結果がログとして残るため、調査を引き継いだ運用担当者は、最初から自分で調査するよりも調査範囲を狭めることができるのです。
技術詳細
技術選定
プロダクト運用を自動化するAIエージェントを実装するにあたり、以下の選択肢を検討しました:
- LLM APIの直接利用 - e.g. Gemini/ChatGPT
- マネージドAgent - e.g. Claude/Cursor
- Agentフレームワーク - e.g. Strands Agents/ADK
これらの選択肢の違いを特徴付けるのは、ユーザー・プロバイダーの責任範囲の違いであると考えました。
LLM APIの直接利用の場合、ユーザーはプロンプトの調整しかできず、LLMが外部通信に使うツールやエージェントとして利用する場合の制御はプロバイダーに任せる必要があります。
マネージドAgentの場合、ユーザーはプロンプトの調整や外部通信に使うツールを指定することができますが、エージェント自体の振る舞い(計画立案・ツール/モデル選択・実行・監視・再試行・ルーティング等)はユーザー側では制御できず、プロバイダーに任せる必要があります。
Agentフレームワークの場合が選択肢の中では最もユーザーの自由度が高く、ユーザーはツールの指定や独自ツールの開発、エージェント自体の振る舞いを指定のプログラミング言語によって制御することができます。
それらの特徴を踏まえた上で、それぞれのpros/consを以下のように整理しました
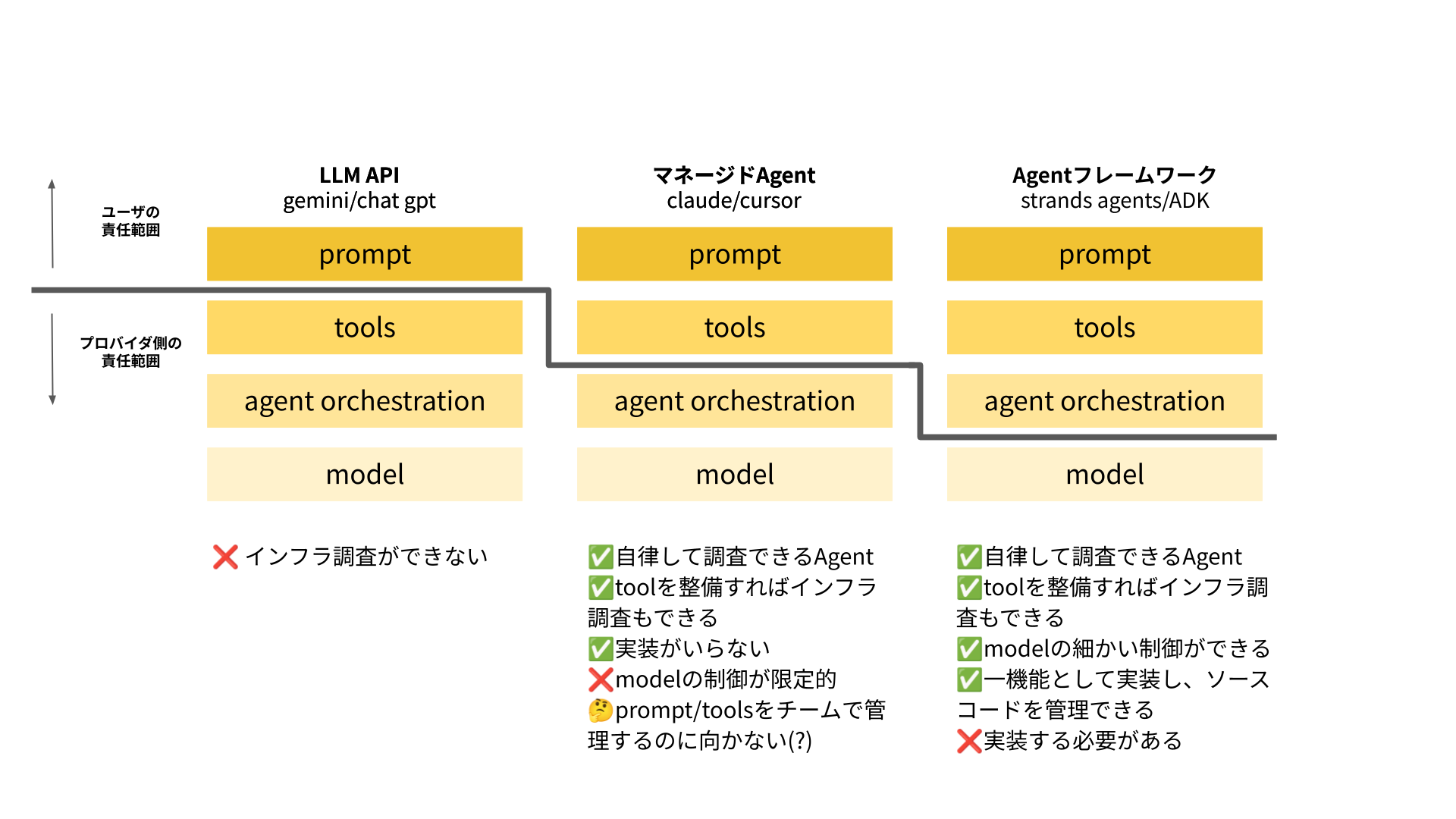
結果的に、ユーザー側の自由度が高いことによる、将来的な拡張性の高さを重視して、Agentフレームワークによる独自の運用エージェントの実装を採用しました。
Strands Agents
AgentフレームワークとしてはGoogle Cloudが開発している ADK や Langchain などがありますが、今回はAWSがOSSとして開発している Strands Agents を採用しました4。
Strands Agentsにおいて、エージェントは与えられたタスクを完了するまで、LLMとツールとのループを繰り返します。
そして、各ループではエージェントはプロンプトとエージェントのコンテキスト、およびエージェントのツールの説明とともに LLM を呼び出し、一連の手順を計画したり、エージェントの以前の手順を反映したり、ツールを実行したりします。
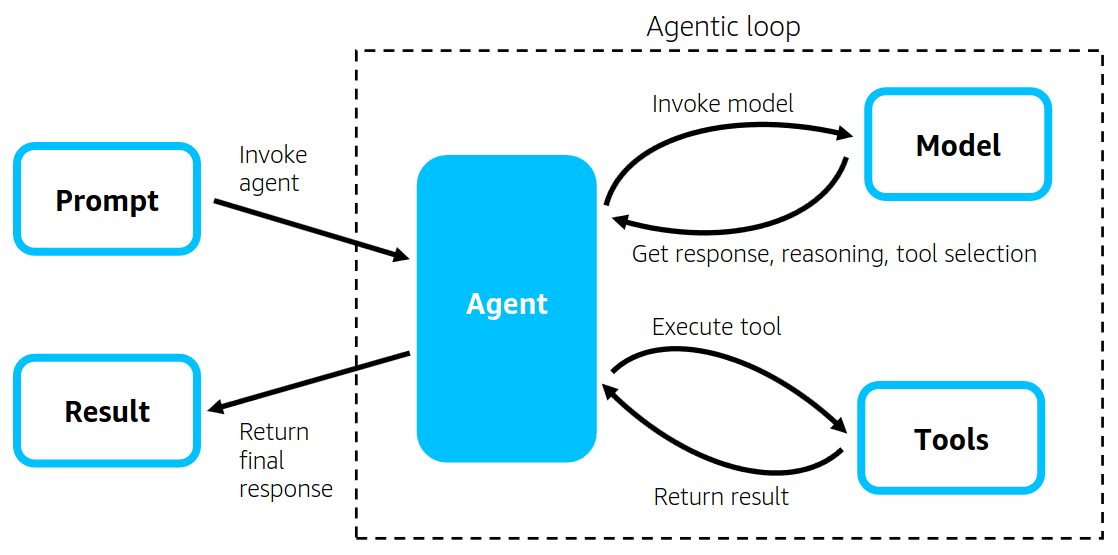
実装も簡易であり、以下のように使用するモデルとツールを指定するだけでエージェントを実装することができます。
from strands import Agent
from strands.models import BedrockModel
agent_model = BedrockModel(...) # Bedrock以外もOK
tools = [...] # 公式mcpや独自定義toolなど
agent = Agent(
model=agent_model,
tools=tools
)
アーキテクチャ
クロサイのアーキテクチャは以下の通りです:
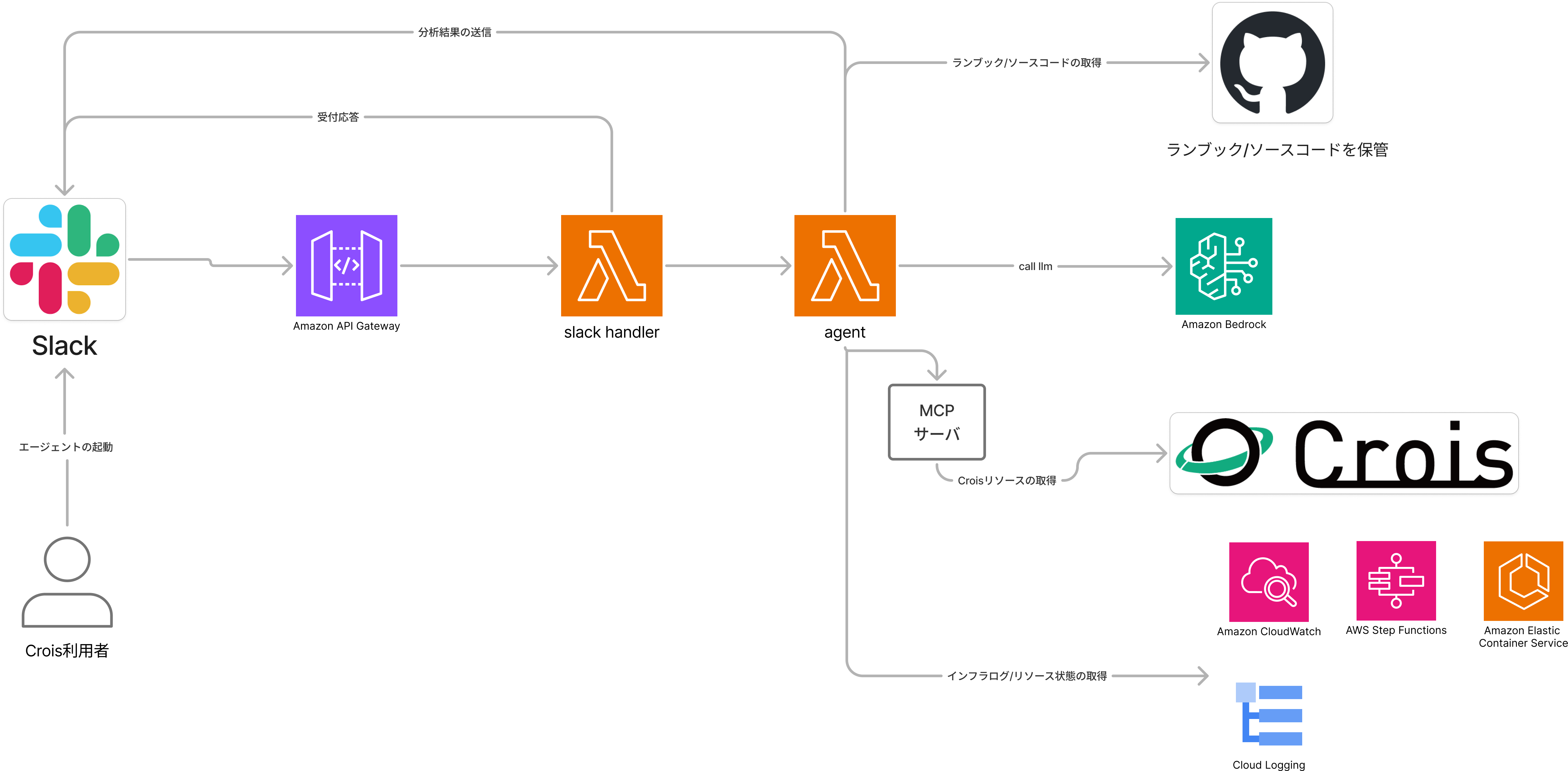
主には AWS側で提供しているサンプル を参考にした構成です。
Lambda間での呼び出しが発生しているのはSlack Appのタイムアウト回避のためです。
エージェントには外部とのやり取りを行うためのツールを実装しており、以下のようなツールを利用しています:
- use_aws: 任意のAWS APIを叩くことができるツールであり、Strands Agentsの community tools として公開されている。
- Crois mcp(独自実装): Crois APIを叩くための独自MCPサーバ。 FastMCP の OpenAPI Integration 機能 で簡易に実装。
- google cloud logging(独自実装): Google Cloud Loggingからログを取得するツール
- github enterprise server(独自実装): GitHub Enterprise Serverと連携し、ランブックやソースコードを参照するためのツール
学びと知見
ドキュメント + tools 整備のパワー
LangChain の調査 によると、特定のドメインに特化した AI エージェントのコーディングにおいて、以下が揃った時に最高の結果が得られるとされています。
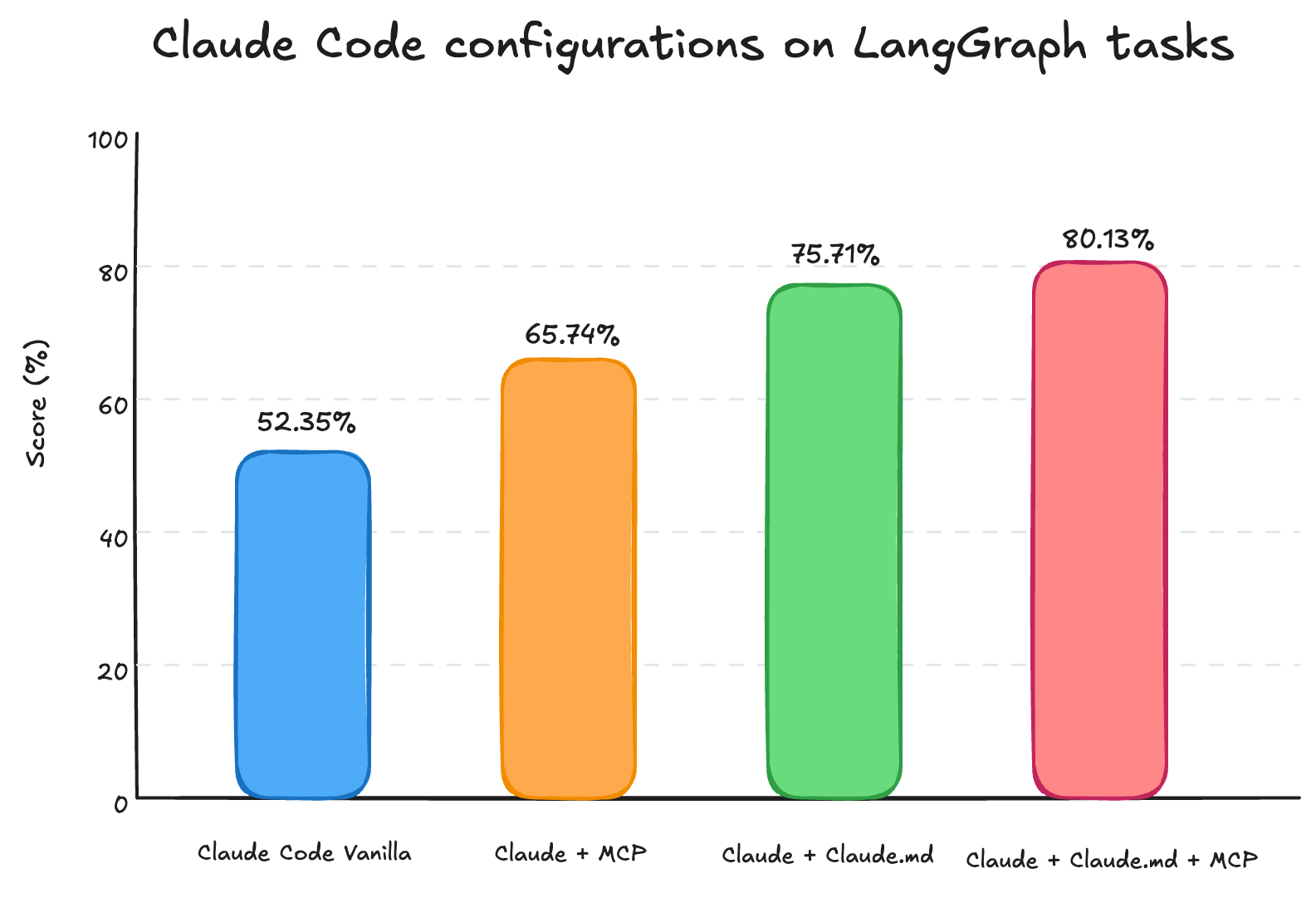
- Tool でアクセスできる詳細情報
- 集約されたガイドライン
CroisではこれまでのSRE活動により、ログ・メトリクス・アラートなどシステム監視が整備されていたため簡単なtools導入によって、AIエージェントがインフラの詳細情報を取得でき、システムを理解できるようになりました。
→ 自動化のためにシステム監視を充実させよう!!
また、Croisでは地道に蓄積してきたランブックが高品質なプロンプトとして機能したので、ほとんどtoolsの実装のみで、自動化が実装できました。
→ 自動化のためにドキュメントを充実させよう!!
このように、ドキュメントとツールの整備がAIエージェントの自動化を実現する上で重要ですが、もう一つ重要な点として、AIエージェントがいる環境では継続的な改善がしやすくなるという側面があります。
継続的改善のしやすさ
ドキュメントやログ出力の整備などの運用改善業務は、一般には開発よりも優先度が低くなりがちな業務です。 なぜなら、ドキュメントの整備の効果が現れるのは書いてから、十分時間が経過した後であるためです。
しかし、AIエージェントがいる環境では、ドキュメントやログを整備するだけで、AIエージェントが参照する情報の質が向上し、自動化の範囲が増えます。
自分の体感ですが、このような環境ではこれまでよりもドキュメントを書くモチベーションが上がります。
まとめ
本記事では、CroisにおけるAIOpsの実践について紹介しました。
Croisでは、運用業務の増大に対応するため、これまでSRE活動を地道に続けてきました。ランブックやドキュメントの整備、システム監視の強化といった活動を通じて、運用基盤が整っていました。この環境があったからこそ、AIエージェント「クロサイ」による自動化を比較的簡単に実現できたと考えています。
具体的には、整備されたランブックが高品質なプロンプトとして機能し、システム監視によりエージェントがインフラの詳細情報を取得できるようになったことで、新しいツールを開発するだけで自動化を実現できました。クロサイの導入により、半分以上のアラート対応において、我々が求めていた質を安定的に担保できるようになりました。
今回の取り組みを通じて感じたのは、AI活用を成功させるためには、従来のSRE活動が基盤となるということです。AIエージェントは既存の運用基盤の上に成り立つものであり、ドキュメント整備やシステム監視の強化といった地道な活動が、そのままAI活用の土台になります。
ここまでお読みいただきありがとうございます、本記事がAIOpsを実践する際の参考になれば幸いです。
-
ランブック/プレイブックは、型化された運用ドキュメントのことです。Croisではアラートや個別の運用業務ごとにその対応手順を記載したランブックを整備しています。 ↩︎
-
AIOps (AI Operations) は、IT運用の効率を向上させるために人工知能を活用すること。ここでは特に「エージェント(自律型)型 IT運用への AI活用」に着目している。参考: https://aws.amazon.com/jp/what-is/aiops/ ↩︎
-
Crois AI を縮めて「クロサイ」となりました ↩︎
-
当初からエージェントを動かすインフラはAWSであることを想定していたため、相性の良さを期待してStrands Agentsを採用しました。しかし結果的にはStrands Agentsに依存する要件はあまりなかったため、他のAgentフレームワークでも同様の運用エージェントが実装可能であると考えています。 ↩︎