目次
はじめに
はじめまして。私は東京科学大学修士課程に所属している石田茂樹と申します。普段は横田研究室でLLMの医療応用に関する研究を行っています。
今回、1ヶ月間、リクルートのデータスペシャリストコースのインターンに参加させていただきました。参加のきっかけは、自然言語処理で培った機械学習の知識を実際のプロダクトでどのように活用できるかを実践的に学びたいと考えていたところ、推薦システムという異なる領域での応用に興味を持ったことでした。
バックグラウンド
私は普段、言語モデルの研究、特に医療分野への応用に取り組んでいます。これまでにも複数の言語モデル開発に関わるインターンシップに参加し、実装経験を積んできました。また、個人的な取り組みとして競馬予測AIモデルの開発も行っており、この経験を通じて特徴量エンジニアリングやモデルの性能改善手法について実践的な知見を蓄積してきました。
インターンシップの経緯
今回のタスク決定プロセスは、選考通過後から始まりました。人事メンターとの面談で「言語モデルの構築技術を活用した開発、もしくは自然言語処理技術の実プロダクトへの応用がしたい」という希望をお伝えしたところ、推薦システムの改善というテーマをご提案いただきました。
配属決定に向けて、メンターと面談を実施し、具体的な取り組み内容を詳細に検討しました。この面談では、私の研究背景や技術的な経験を踏まえつつ、実際のプロダクトで直面している課題とのマッチングを丁寧に行っていただきました。その結果、言語モデルで培った知見と、個人開発で得た機械学習の実装経験を組み合わせて推薦システムの改善に取り組むという、非常に魅力的なテーマに決定しました。
取り組み内容の概要
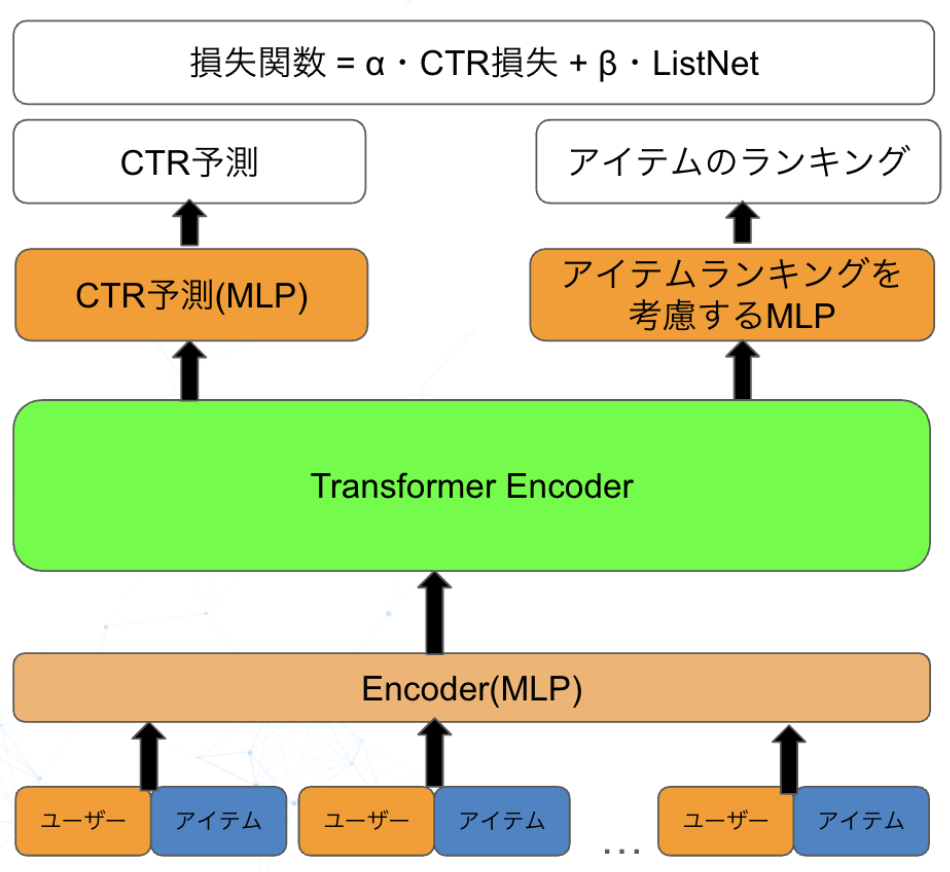
本インターンシップでは、アイテムの相互影響を考慮した推薦リスト作成手法の改善に焦点を当てました。リクルートが学会等で公開した研究(以下、研究用ベースラインモデルと呼びます)では、学習の安定性に改善余地があり、過学習傾向が見られるケースも確認されました。この問題に対して、マルチタスク学習の導入による解決アプローチを提案し、実装・検証を行いました。
具体的には、メインタスクである推薦精度向上に加えて、Triplet LossとListNet Lossを用いた補助タスクを設計し、モデルの汎化性能向上を目指しました。これらの補助タスクは、アイテム間の相対的な関係性やランキング情報を学習することで、学習を安定化させる効果も狙っています。
本アプローチによる改善のポイントは以下の通りです。
- 過学習に悩まされていたベースラインモデルに対し、Triplet LossとListNet Lossを導入したマルチタスク学習により、RecallやAUCなどの評価指標で性能向上を達成
関連研究
アイテム間相互影響を考慮した推薦システム
近年、推薦リスト全体を考慮した推薦システムの研究が活発に行われています。従来の個別アイテムにのみ焦点を当てた推論・推薦とは異なり、同時に推薦されるアイテム同士の相互影響を考慮する「バンドル推薦」という概念が提案されています。
従来手法の課題と相互影響の重要性
同時に推薦されるアイテム同士は、相互に影響を与えると考えるのが自然です。ユーザーは推薦されたアイテム同士を比較しながら行動するため、同一のアイテムを推薦する場合でも、同時に推薦するアイテムによって購買意欲等が変化すると考えられます。
例えば、飲食店のドリンクを推薦する場合を考えてみます。
推薦パターンA(単純な比較)
- Sサイズのドリンク(100円)
- Lサイズのドリンク(150円)
推薦パターンB(行動経済学で知られる選択肢提示の効果の一例を踏まえた構成)
- Sサイズのドリンク(100円)
- Mサイズのドリンク(140円)← 中間価格
- Lサイズのドリンク(150円)
パターンBでは、Mサイズのドリンクが比較基準として機能し、ユーザーの選択行動が変化する可能性があります。行動経済学で知られる選択肢提示の効果の一例で、利用者が比較しやすい構成として理解されています。 推薦システムにおいても、今回例に挙げた選択肢提示の他にも様々なアイテム同士の相互影響が発生して、ユーザーが行動することが考えられます。 しかし、従来のアイテム個別のスコアリングでは、このような相互影響を考慮できないという課題があります。
関連研究の動向
この課題に対して、以下のような研究が提案されています:
Shalom et al. (2016) [1]
- 提案:リスト内のアイテム同士の類似度を特徴量として活用する二段階学習法
- 利点:候補アイテム間の相互影響が一定考慮可能
- 課題:考慮する相互影響が「類似度」という単一の尺度に依存
Gong et al. (2019) [2]
- 提案:Graph Attention Network(GAT)とRecurrent Neural Network(RNN)を組み合わせた手法
- 利点:推薦候補の全アイテムで捉えた関係性を考慮したリスト生成が可能
- 課題:リスト内で同時に推薦するアイテムに限定した相互影響はRNNの潜在表現に依存し、選択肢提示の効果に伴う比較の影響のような、同時表出による相互影響を捉えきれているとは限らない
リクルートが学会等で公開した研究(研究用ベースラインモデル)
手法の概観
この研究ではアイテム間の相互影響を明示的に考慮するため、推薦スコア予測モデルと推薦リスト生成モデルの2つのモデルを組み合わせたアプローチを採用しています。
-
相互影響を考慮した推薦スコア予測モデル
- 入力:予測対象の推薦リスト、ユーザ情報、アイテム情報
- 出力:リストの推薦スコア
-
スコア予測に基づく推薦リスト生成モデル
- 入力:ユーザ、推薦候補アイテムの集合
- 出力:推薦リスト
相互影響を考慮した推薦スコア予測モデル
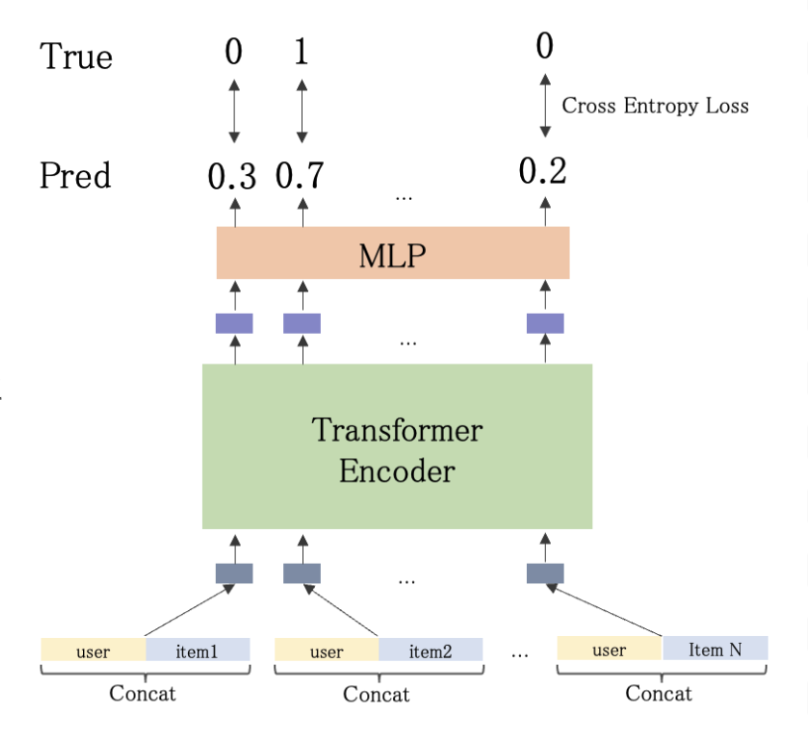
Transformerの自己注意機構(Self-Attention)を活用して、同時表出したアイテム間の相互影響を明示的に考慮してスコア予測を行うことで推薦リスト内の各アイテムが他のアイテムとどのような関係性を持つかを動的に学習し、単独では捉えきれない相互影響を明示的にモデル化することが可能になります。例えば、あるアイテムが他のアイテムの存在によってより魅力的に見える(または逆に魅力が減る)といった複雑な関係性を、アテンション重みとして表現できます。
Self-Attentionの推薦システムへの応用:
- 自然言語処理では:入力文中のトークン(単語)間の類似度や重要度等の関係性を獲得
- ベースラインモデルでは:自然言語での「単語」に当たるものを「アイテム」に置き換えて活用
インターンシップでの取り組み内容
本インターンシップでは、リクルート社内で行われていた「類似度だけでなく、選択肢提示の効果に基づく比較の影響のような潜在的なアイテム相互影響を捉えつつ、同時に推薦されるリスト内のアイテム相互影響を明示的に考慮する必要がある」という仮説により沿いつつ、課題として挙げられていた過学習の問題に対処すべく、マルチタスク学習を導入して手法を拡張しました。
過学習の原因分析
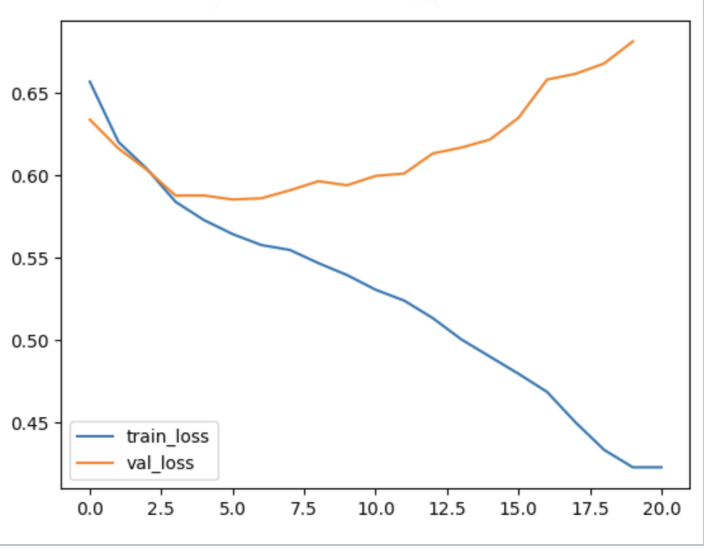
研究用ベースラインモデルでは、訓練損失は減少する一方で検証損失がすぐ上昇してしまう傾向であることから、過学習によって性能が安定しにくいと考えられました。
一般に、過学習の原因は以下の三つが考えられます。
- 学習データの不足
- 学習データの偏り
- タスク設計が不適切(例:損失関数の選択、学習目標の設定、モデルアーキテクチャとタスクの不整合など)
適切に処理・匿名化された社内データセットを用いた検証の結果、学習データ量は一定水準を満たしていると判断しました。そのため、過学習の主因はデータ量ではなく、データの偏りやタスク設計(損失関数や学習目標の設定など)にあると仮説を立てました。
この仮説に基づき、本インターンシップでは主に2と3について検証を行いました。
本インターンシップで主に取り組んだこと
マルチタスク学習の導入背景
ベースラインモデルではTransformerの自己注意機構を用いてアイテム間の関係性をモデリングしていましたが、単一のCTR予測タスクだけでは、これらの重みが推薦に適切に学習されない課題がありました。そこで本インターンシップでは、学習目的を明示的に分割し、アイテム間の関係性を直接的な学習目標として組み込むマルチタスク学習アプローチを採用しました。これにより、正則化効果による過学習抑制と、モデルの潜在能力を引き出した性能向上を目指しました。
マルチタスク学習
手法の概要
マルチタスク学習(Multi-Task Learning)は、複数のタスクを同時に学習してモデルを訓練する手法です。
従来のアプローチでは、個々のタスクごとに専用のモデルを訓練することが一般的でした。しかし、マルチタスク学習では、異なるタスク間の共通性や相互影響を活用して、複数のタスクを同時に処理することが可能です。
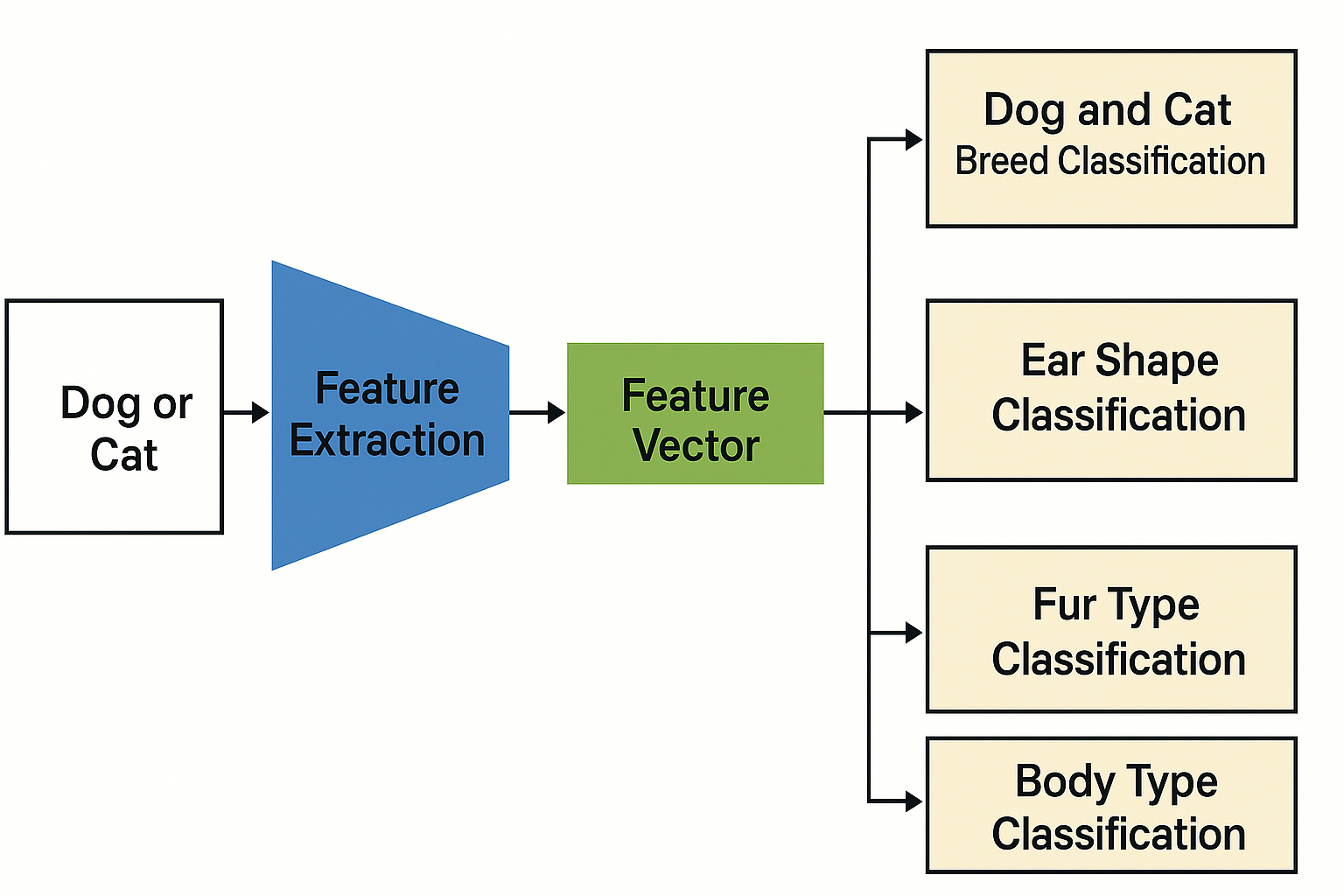
マルチタスク学習の最大の特徴は、タスク間の情報共有です。上図のように、入力画像から抽出された特徴ベクトルを複数のタスクで共有することで、各タスクが互いに役立つ情報を活用でき、それにより個々のタスクの性能向上が期待されます。
例えば、犬と猫の画像分類モデルを構築する場合、主タスクである「犬種・猫種の分類」に加えて、補助タスクとして「耳の形状分類」「毛質分類」「体型分類」を同時に学習します。これらの補助タスクは主タスクと密接な関連性があり、共有される特徴表現を通じて相互に有益な情報をもたらします。特に、耳の形や毛質、体型といった特徴は品種の判別に重要な要素であり、これらを明示的に学習することで、より robust な特徴表現の獲得が期待できます。
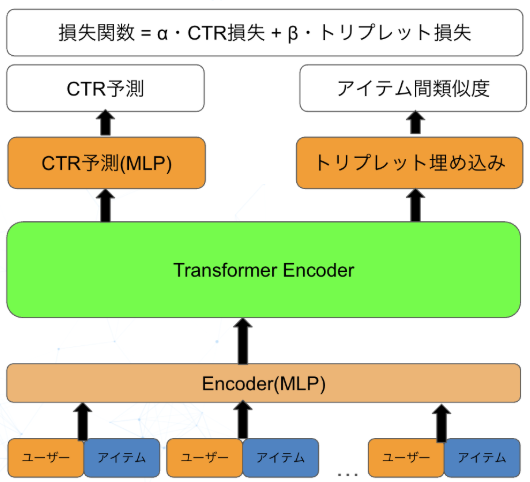
モデルの構造としては、入力画像から特徴抽出を行う共有層があり、その後にタスクごとに専用の全結合層が分岐します。各タスクには独自の損失関数があり、それらを重み付けして総合的な損失として最適化します($Loss_{total} = \lambda_1 Loss_1 + \lambda_2 Loss_2 + \lambda_3 Loss_3 + \lambda_4 Loss_4$)。この方法により、複数のタスクを同時に学習しながら、全体としての性能を向上させることができます。
本インターンシップでの適用
ベースラインモデルでは単なるCTR予測に留まっていましたが、インターンシップでは以下の2つのタスクを同時に最適化することを目指しました。
-
タスク1: CTR予測の最適化
- ユーザーがアイテムをクリックするかどうかの予測
- 従来の推薦システムの主要タスク
-
タスク2: アイテム間関係性の最適化
- アイテム同士の類似度や相関関係の学習
これらのタスクを同時に学習することで、モデルはより豊かな特徴表現を獲得することが期待されます。特に推薦システムのコンテキストでは、アイテム間の関係性を明示的に学習することで、より関連性の高い推薦が可能になると考えられます。
ベースラインモデルの限界と改善アプローチ
ベースラインモデルでは、単純にクロスエントロピー損失を用いてCTR予測(クリック率予測)の二値分類のみを行っていました。本インターンシップではマルチタスク学習を導入し、以下のような複数の学習目標を同時に最適化することで、より豊かな特徴表現の獲得を目指しました。
ベースラインモデルの限界
-
単一タスク(CTR予測のみ)
- ユーザーがアイテムをクリックするかどうかの予測のみに特化
- アイテム間の関係性や順序情報を明示的に学習しない
マルチタスク学習による改善
マルチタスク学習では、主タスク(CTR予測)に加えて補助タスクを導入することで、アイテムの相互影響を明示的に学習します。
-
アイテム間類似度の最適化
- Triplet Lossを用いて、ユーザーが興味を示すアイテム同士の類似度を高め、興味のないアイテムとの類似度を低くする
- これにより、アイテム間の意味的な関係性を特徴空間に埋め込み、類似したアイテムが近い位置に配置される
-
アイテム間順序関係の最適化
- ListNet Lossを用いて、ユーザーの選好に基づくアイテムの順序関係を学習
- 単一のアイテムペアだけでなく、リスト全体の構造を考慮した相関関係を捉える
相互影響学習の効果 この手法により、単純なクリック予測だけでなく、アイテム間の複雑な相互影響(類似度、相関、順序性)を同時に学習することで、モデルがより豊かで構造化された特徴表現を獲得できるようになると考えられます。特に、従来の手法では捉えきれなかったアイテム間の潜在的な関係性を明示的にモデル化することで、推薦精度の向上を目指します。
サブタスクとしての複数損失関数の検証
マルチタスク学習の枠組みを活用するにあたり、どのようなサブタスクを設定するかが重要な検討課題となります。今回は、主タスクであるCTR予測に加えて、アイテム間の関係性を効果的に学習するための2つの異なる損失関数を検証しました。
1. Triplet lossの導入
Triplet lossは、表現学習において非常に効果的な手法です[3]。この手法では、「アンカー」「ポジティブ」「ネガティブ」の3つの要素(Triplet)を用いて学習を行います。
具体的には、ユーザーが興味を示したアイテム間の距離を近く、興味を示さなかったアイテムとの距離を遠くするように特徴空間を構築します。
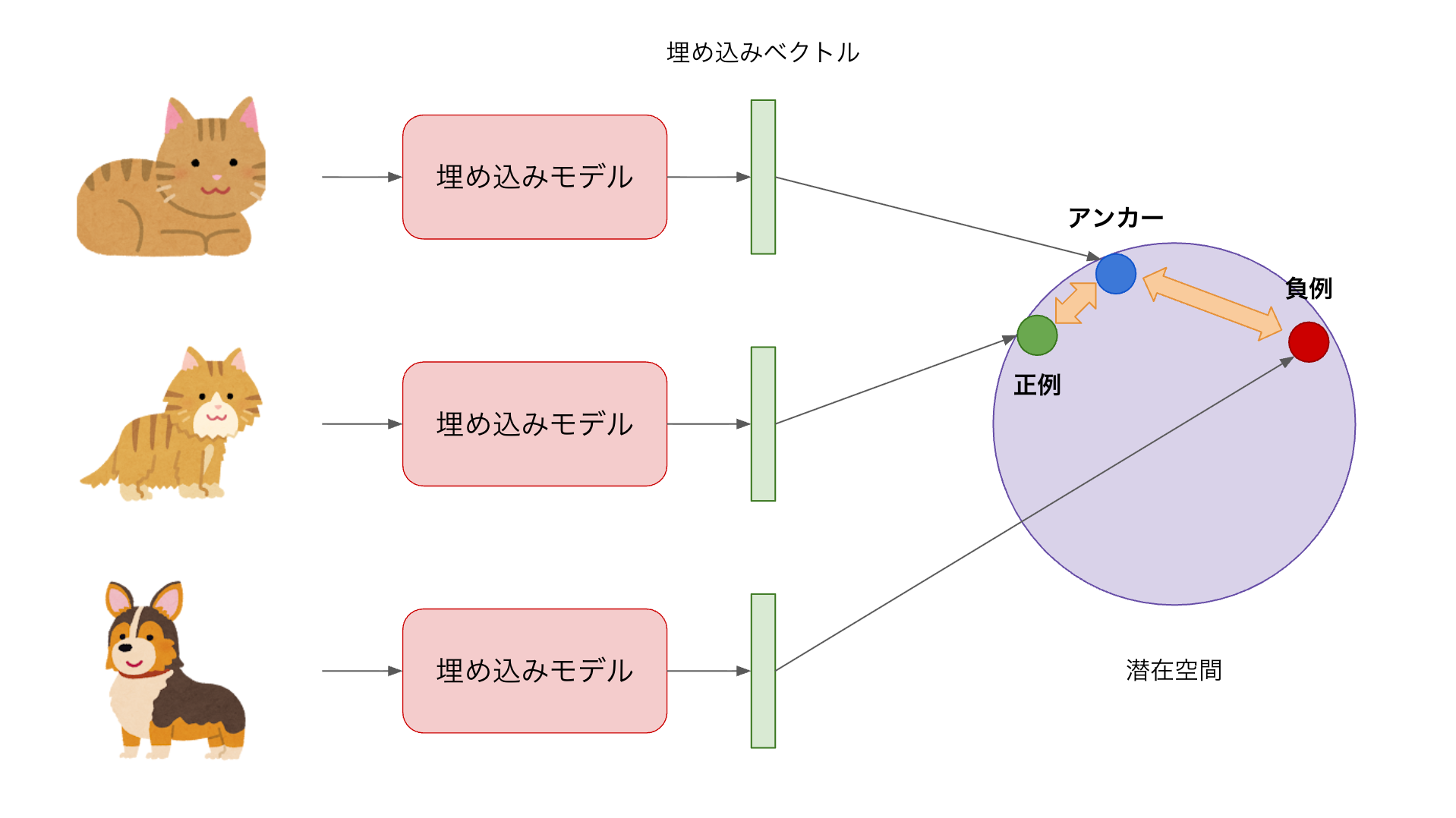
上図は距離学習の基本的な考え方を示したイメージ図です。Deep Architectureによって入力データを特徴空間に写像し、似ているもの同士は近く、似ていないものは遠くなるように学習を行います。推薦システムにおいては、現在ユーザーが見ているアイテム(Anchor)と、そのユーザーが好むアイテム(Positive)との距離を近づけ、興味のないアイテム(Negative)との距離を遠ざけることで、ユーザーの嗜好を反映した特徴空間を学習することができます。この特徴空間上での距離関係を利用することで、新しいアイテムに対しても適切な推薦が可能となります。
数学的には以下のように表現できます。
$$ L_{triplet} = \max(0, d(a,p) - d(a,n) + \text{margin}) $$
ここで、
- $d(a,p)$はアンカーとポジティブサンプル間の距離
- $d(a,n)$はアンカーとネガティブサンプル間の距離
- marginは最小距離差を示すハイパーパラメータ
2. ListNet lossの導入
ListNet学習は、複数アイテム間の順序関係を確率分布として学習し、ユーザーの選好順序を予測するための手法です。従来のポイントワイズやペアワイズのアプローチとは異なり、リストワイズのアプローチを取ることで、アイテム間の相対的な関係性をより効果的に捉えることができます。
ListNetでは、予測されたスコアのリストと実際の選好順序のリストの間の確率分布の差異を最小化することを目指します。具体的には、以下のように損失を計算します。
$$ L_{listnet} = -\sum P(\pi|y) \log P(\pi|z) $$
ここで、
- P(π|y)は実際のランキングに基づく順列の確率
- P(π|z)は予測スコアに基づく順列の確率
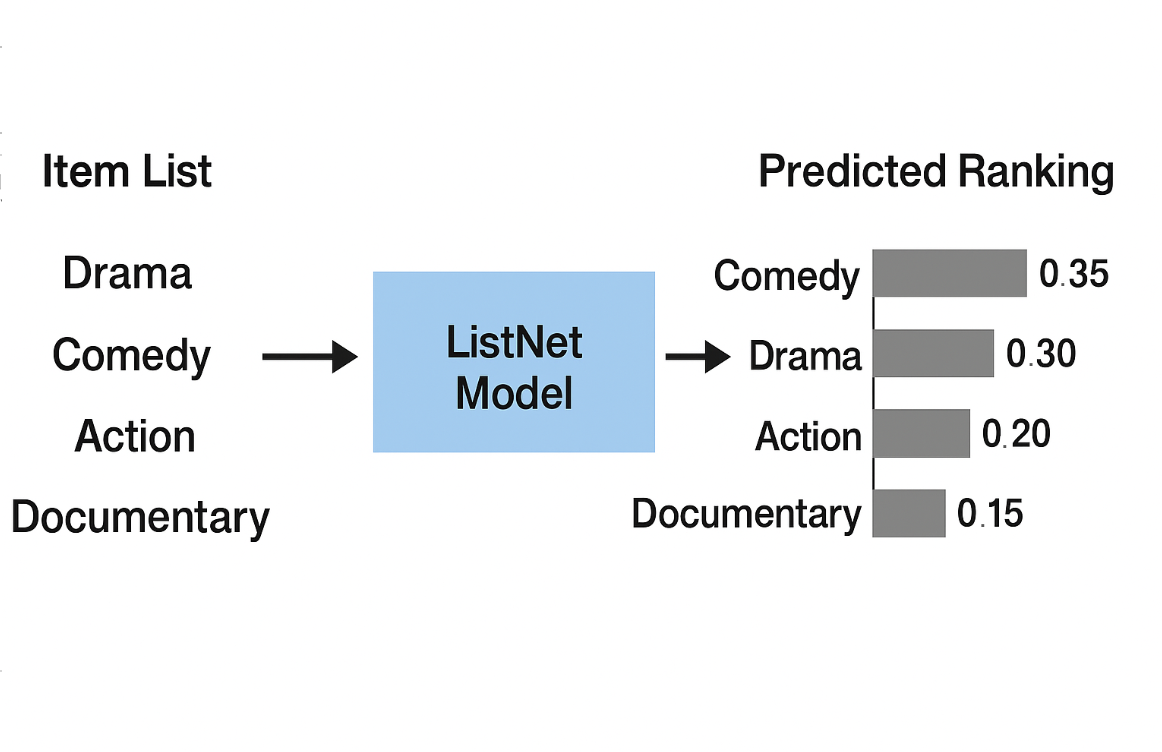
この手法の利点は、単一のアイテムやアイテムペアだけでなく、リスト全体の構造を考慮して学習できることです。上図に示すように、ListNetでは実際のランキングと予測スコアの両方から順列の確率分布を求め、これらの分布間のKL divergenceを最小化することで学習を行います。これにより、コンテキスト情報をより豊かに取り込んだ推薦が可能になります。
損失関数の組み合わせ効果
上記の2つの損失関数を主タスクの損失関数と組み合わせることで、モデルはより多角的な視点からアイテム間の関係性を学習できるようになります。
損失関数の設計
パターン1:Triplet Lossとの組み合わせ $$ L_{total} = \alpha L_{main} + \beta L_{triplet} $$
パターン2:ListNet Lossとの組み合わせ $$ L_{total} = \alpha L_{main} + \beta L_{listnet} $$
パラメータの意味
- α:メインタスク(CTR予測)の重み
- β:補助タスク(関係性学習)の重み
この複合的なアプローチにより、単一の損失関数では捉えきれなかった複雑なアイテム間関係性を学習することが可能になります。
検証結果
Triplet lossによる改善効果
Triplet lossを導入したモデルの検証結果は非常に興味深いものでした。主要な評価指標について、ベースラインモデルと比較した結果を以下に示します。
学習曲線の改善
Triplet lossを追加したモデルでは、ベースラインモデルと比較して検証損失(validation loss)の挙動に改善が見られました。
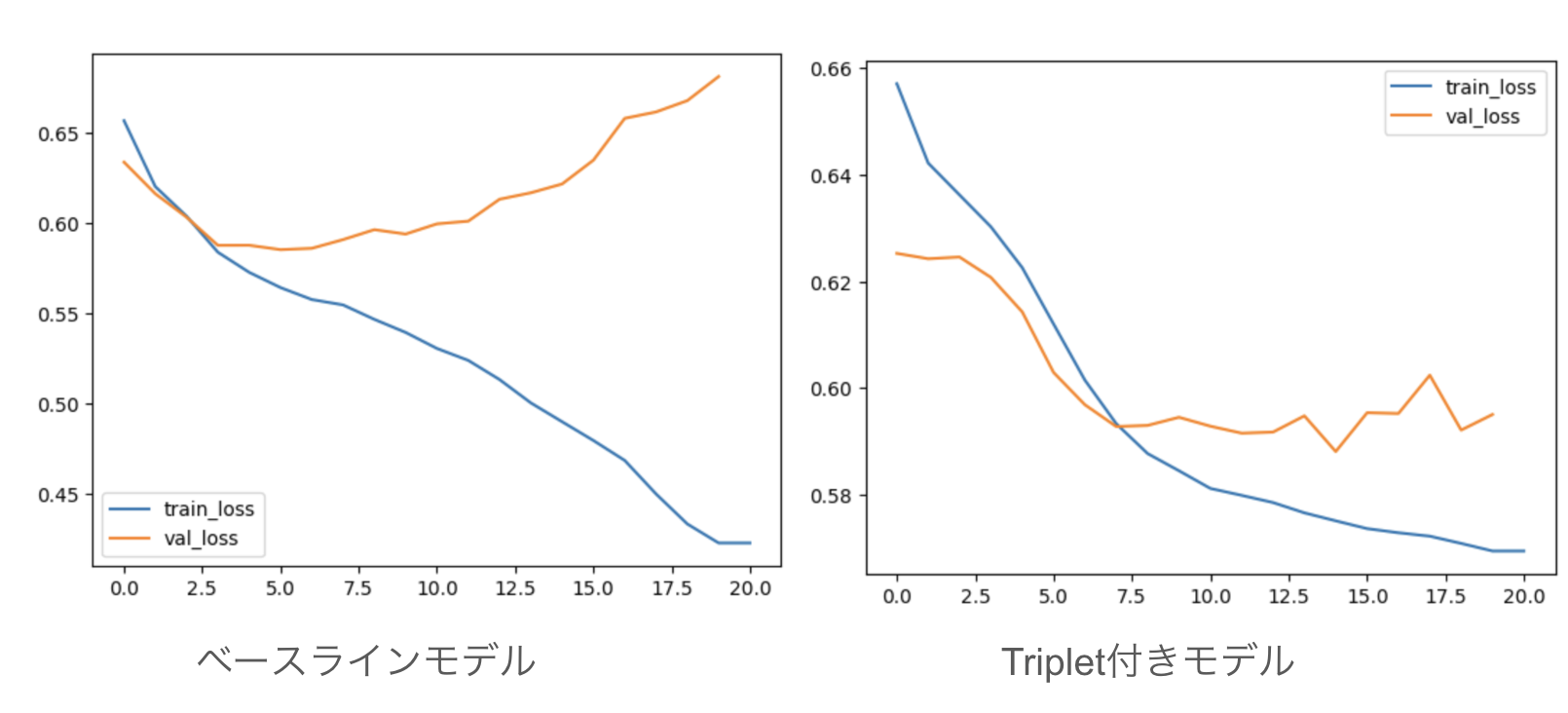
ベースラインモデルでは訓練が進むにつれて訓練損失(training loss)は減少するものの、検証損失が上昇する過学習の傾向が見られました。一方、Triplet loss付きモデルでは、訓練損失と検証損失がともに減少し、両者のギャップも小さくなっています。これは、Triplet lossが正則化効果をもたらし、モデルの汎化性能を向上させたことを示唆しています。
分類性能の向上
分類モデルとしての評価指標においても、Triplet lossの追加は明確な改善をもたらしました:
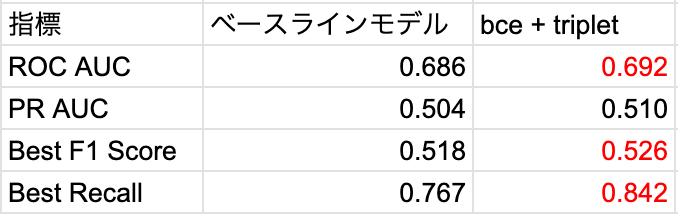
オフライン評価結果(社内検証環境)
匿名化済みデータを時系列で分割し、オフライン評価を実施しました。その結果、以下のような改善が確認されました。
-
ROC AUC:約+0.6pt
- モデルの全体的な分類能力に改善が見られました。
-
F1 スコア(最適閾値): 約+1.5pt
- Precision(適合率)とRecall(再現率)のバランスが改善しました。
-
Recall:約+9.7pt
- 真のポジティブサンプルを見逃さずに捉える能力が向上しました。
※いずれも社内検証環境での結果であり、実運用における効果は今後の評価が必要です。
考察
Triplet lossを導入することで、従来のベースラインモデルでは見逃していたポジティブサンプルをより適切に捉えられるようになったと考えられます。これは、アイテム間の関係性を明示的に学習させることで、特徴空間内により意味のある構造が形成されたためと推測されます。
補助的な損失関数として Triplet lossを追加することの効果は明確であり、特にRecallを重視するユースケースにおいて有効なアプローチであると考えられます。
ListNet lossによる検証結果
ListNet lossを導入したモデルの検証結果も、Triplet lossと同様に改善を示しました。さらに、いくつかの指標においてはTriplet lossを上回る効果が確認されました。
学習曲線の特性
ListNet loss付きモデルの学習曲線を観察すると、ベースラインモデルと比較して検証損失(validation loss)の挙動に改善が見られました。
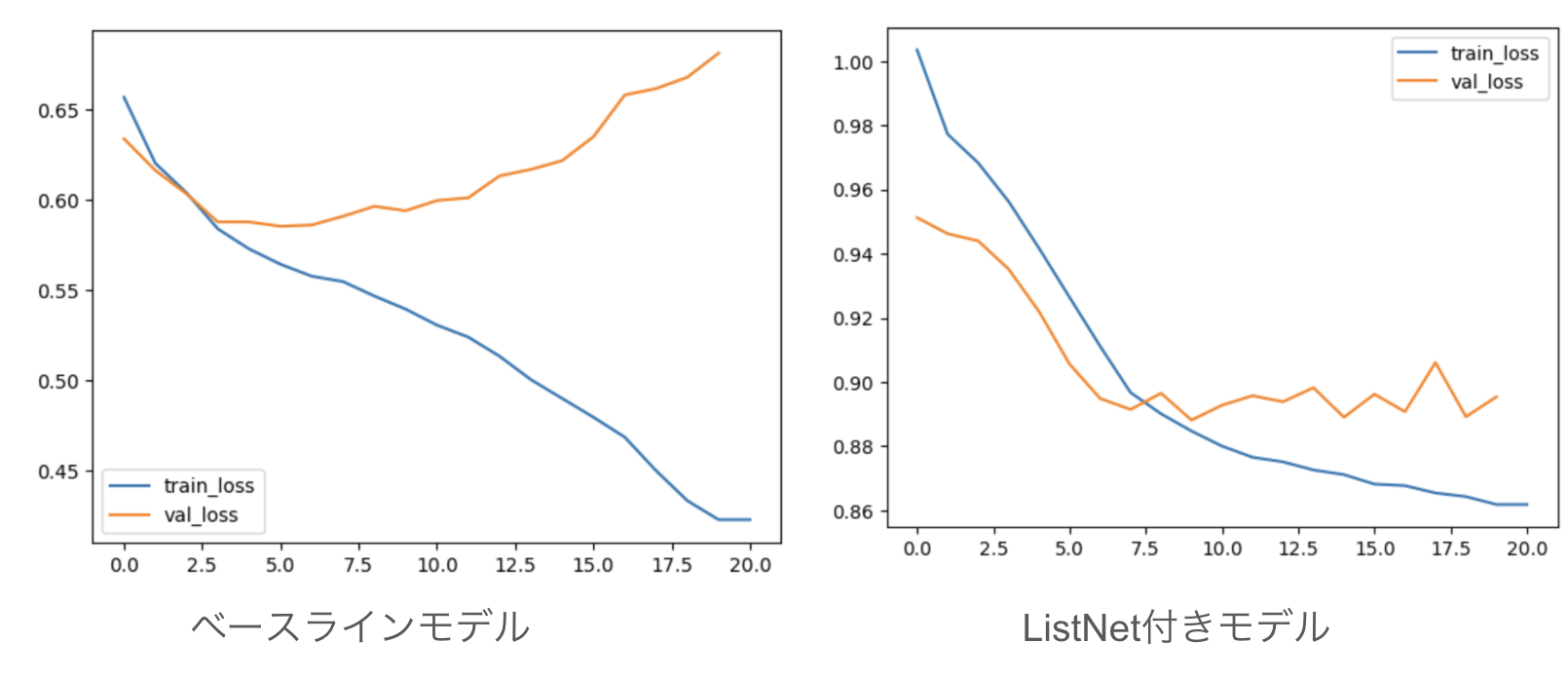
ListNet lossを導入したモデルでは、訓練の後半においても検証損失が安定しており、過学習の抑制効果がTriplet lossよりもさらに強いことが示唆されました。
分類性能の向上
ListNet lossを導入したモデルの評価指標は、ベースラインモデルと比較して以下のような改善を示しました:

オフライン評価結果(社内検証環境)
匿名化済みデータを時系列で分割し、オフライン評価を実施しました。その結果、以下のような改善が確認されました。
-
ROC AUC: 約 +1.0pt
- Triplet loss を上回る改善が見られ、分類能力が向上しました。
-
PR AUC: 約 +1.0pt
- Precision と Recall のバランスが全体的に改善しました。
-
F1 スコア(最適閾値): 約 +2.0pt
- Triplet loss をわずかに上回る結果となり、適合率と再現率のバランスがさらに改善しました。
-
Recall: 約 +8.0pt
- ポジティブサンプルを捉える能力が大きく改善しました。
※いずれも社内検証環境でのオフライン評価の結果であり、実運用における効果は今後の検証が必要です。
検証結果と考察
ListNet lossの導入は、Triplet lossと同等かそれ以上の効果を示しました。特に、RecallやAUCなど複数の指標でバランスの良い改善が確認され、リスト全体の順序関係を学習する効果が反映されたと考えられます。
この結果から、推薦システムにおいてはアイテム間の距離関係よりも順序関係を学習することが有効である可能性が示唆されました。ただし、これらは限定的な条件下での検証結果であり、実運用に向けてはさらなる評価が必要です。
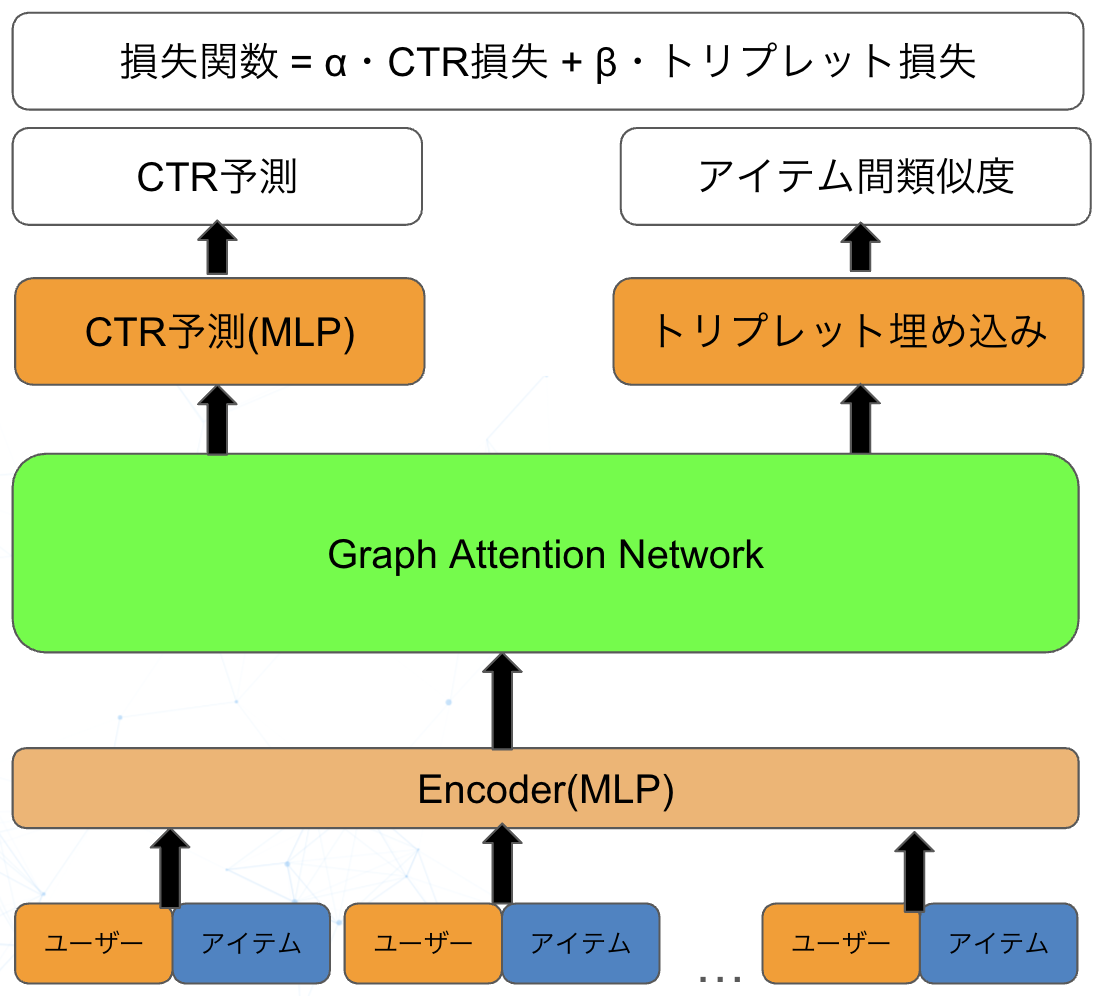
追加検証:Graph Attention Networkの導入
Graph Attention Networkの概要
Graph Attention Network(GAT)は、グラフ構造データに対してアテンション機構を適用したニューラルネットワークアーキテクチャです。従来のGraph Convolutional Network(GCN)とは異なり、GATは隣接ノード間の重要度を動的に学習することができ、より柔軟で表現力の高いグラフ表現学習を実現します。
GATの核となるアイデアは、各ノードがその近傍ノードからの情報を集約する際に、アテンション重みを用いて重要度を調整することです。これにより、グラフ構造の中で特に重要な関係性に焦点を当てた学習が可能になります。
推薦システムでの応用方法
推薦システムにおいて、GATは以下のような方法で活用できます:
-
ユーザー-アイテムグラフの構築
- ユーザーとアイテムを二部グラフとして表現
- ユーザーの行動履歴(クリック、購入など)をエッジとして定義
-
アテンション機構による関係性学習
- 各ユーザーに対して、関連するアイテム間の重要度を動的に学習
- アイテム間の潜在的な関係性をアテンション重みとして表現
-
マルチタスク学習との統合
- GATから得られたノード表現をListNet学習と組み合わせ
- グラフ構造の情報と順序関係学習を同時に活用
今回の実験でのモデルイメージは次の通りです。
実験結果と検証
ListNet + GATの統合モデルによる検証結果を以下に示します:

考察
興味深いことに、今回の実験結果ではGATを用いたモデルよりも、単純なAttention機構とListNetを組み合わせたモデルの方が高い性能を示しました。この結果から以下のような考察が得られます。
-
グラフ構造の複雑性による過学習
- GATはグラフ構造を明示的にモデル化するため、パラメータ数が増加し、限られたデータセットでは過学習を引き起こしやすい可能性がある
-
タスクに適した抽象化レベル
- 単純なAttention機構の方が、本タスクに必要な関係性を適切な抽象化レベルで捉えることができた
- GATの詳細なグラフ構造学習が、必ずしも推薦精度の向上に直結しない場合がある
-
マルチタスク学習の本質
- 今回の結果は、マルチタスク学習において「より複雑なモデル = より良い性能」ではないことを示している
- 適切なタスク設計と損失関数の組み合わせが、アーキテクチャの複雑さよりも重要である可能性がある
この知見は、推薦システムにおけるマルチタスク学習の設計において、必ずしも最新の複雑な手法を採用する必要がないことを示唆しており、実用性と性能のバランスを考慮した手法選択が重要なのかもしれません。
まとめ
本インターンシップでは、アイテムの相互影響を考慮した推薦リスト作成手法の改善に取り組み、マルチタスク学習の導入により成果を得ることができました。
マルチタスク学習による改善効果
マルチタスク学習の導入により、検証損失と精度の両面で改善が確認されました。
- Binary CrossEntropy + Triplet:Recallを強化したい特化ケースには有効ですが、F1スコアやPrecisionとのトレードオフが存在する
- Binary CrossEntropy + ListNet:全体的に最もバランスが取れた改善を示しており、Recall・AUCいずれの面でも有望な結果を示す
マルチタスク学習の有効性
今回の検証を通じて、マルチタスク学習が以下の点で特に有効であることが明らかになりました。
- 複雑なタスクに対する効果:解いているタスクが複雑なケースに対して有効
- 学習の安定性向上:関連するサブタスクの学習過程を共有することで、モデル内での解釈性が向上し、精度改善や学習の安定が期待できる
今回得られた教訓
本インターンシップを通じて次のような教訓が得られました。
→ 困難は分割せよ
デカルトの有名な言葉「困難は分割せよ」が、まさに今回の取り組みにも当てはまりました。複雑な推薦システムの問題を、CTR予測とアイテム間関係性学習という2つのサブタスクに分けることで、単一タスクでは達成できなかった性能向上を実現できました。
インターンシップを終えて
インターンシップ全体の感想
あっという間の期間でしたが、非常に充実した時間を過ごすことができました。振り返ってみると、もう少し早い段階で現在の成果に到達できていれば、さらに発展的な内容に取り組めたかもしれません。この経験を通じて、限られた時間の中で効率的に課題に取り組み、成果を出すためのスキルを身につけることができました。 また、私自身はCTRやCVの意味も分からないレベルで、協調フィルタリングという言葉も初めて聞く推薦システムの初心者でしたが、推薦システムの基本的な仕組みから、実際の実装における課題まで、幅広く学ぶことができました。特に、単純なアルゴリズムの組み合わせだけでなく、ユーザー行動の複雑さやビジネス要件との兼ね合いなど、実用的な観点での理解が深まりました。
参考文献
[1] Shalom, O.S., Koenigstein, N., Paquet, U. and Vanchinathan, H.P.: Beyond Collaborative Filtering: The List Recommendation Problem. In proceedings of the 25th International Conference on World Wide Web, 63–72 (2016).
[2] Gong, Y., Zhu, Y., Duan, L., Liu, Q., Guan, Z., Sun, F., Ou, W. and Zhu, K.Q.: Exact-k recommendation via maximal clique optimization. In proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 617–626 (2019).
[3]: Chandhok, S. “Triplet Loss with Keras and TensorFlow,” PyImageSearch, 2023, https://pyimagesearch.com/2023/03/06/triplet-loss-with-keras-and-tensorflow/