目次
はじめに
こんにちは、アナリティクスエンジニアの森田です。
2025年3月10日、データ推進室データマネジメント部では、情報共有とコミュニケーション活性化を目的としたライトニングトーク会(以下「LT会」)の第2回を開催しました。
今回は、さらに実践的なスキルアップを目指し、LT会とワークショップの二部構成で実施。約45名の参加者がオフラインで集まり、日頃の研究成果や業務で培った知見を共有し、実践的なスキルを磨く場となりました。
本記事では、その熱気あふれる当日の様子を詳しくレポートします。
第1回開催の記事は こちら
開催方式
今回も交流のしやすさを考慮し、オフライン参加をメインとして開催。参加できない方へはオンラインで参加してもらい、ハイブリッド形式での開催となりました。 また、当社オフィスのオフライン会場には、寿司やオードブルなどの飲食物も準備し、参加者同士が交流しやすいカジュアルな会にしました。



今回のLT会では、多岐にわたるテーマで3名の登壇者が日頃の業務における課題解決や新しい技術への挑戦について発表しました。どの発表も、アナリティクスエンジニアならではの視点と深い洞察に満ちており、参加者は熱心に耳を傾けていました。
LT①:LLMでのSQL生成プロセスと住まいユースケースとの対応
発表者:阿部さん、前田さん
最初のLTでは、LLM(大規模言語モデル)を活用したSQL生成プロセスが紹介されました。
SQL作成の効率化という誰もが関心を持つテーマに対し、具体的にLLMをどのように導入し、特に「住まい」に関するユースケースでどのように役立てているかが語られました。参加者からは、LLMの可能性と共に、実務適用における工夫や課題に関する質問が飛び交い、活発な議論が展開されました。
内容
住まいではデータマートユーザーのSQL作成を支援、効率化するLLMを用いたQAツールの開発を行なっています。しかし、LLMが自然言語から完璧なSQLを一度で生成するのは、まだ技術的に困難です。
そこで注目したのが、SQL生成を複数ステップに分割するマルチエージェントというアプローチです。 このプロセスは人間がSQLを組み立てる手順と似ているため、各ステップを支援する機能を提供すれば、ユーザーのSQL作成を効率化できると考えました。
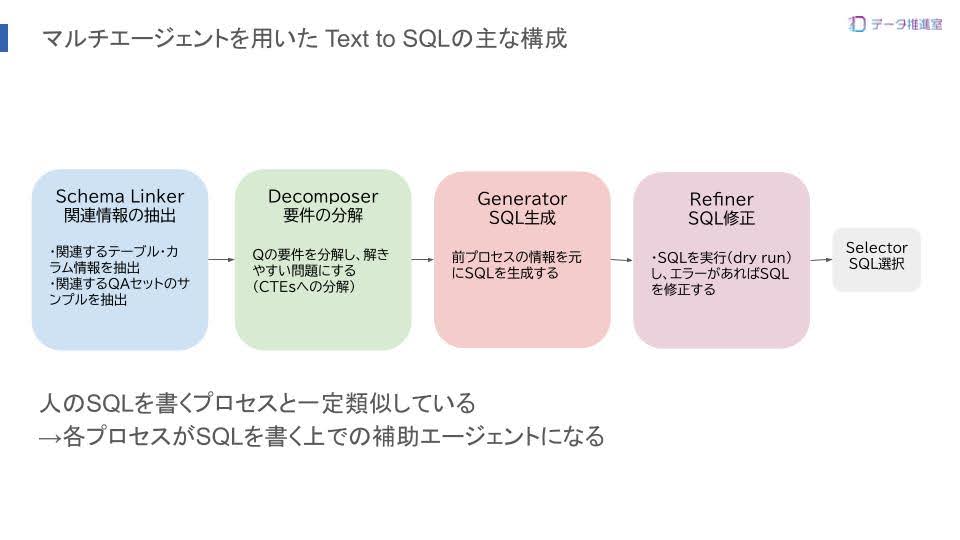
今回はこのアプローチの基盤となるText-to-SQLの主要プロセスと、その技術要素をご紹介しました。 具体的にプロセスを次の4つに分けて紹介しています。
- Schema Linker: 質問に関連するスキーマ・情報を特定
- Decomposer: 複雑な質問を単純なサブクエリに分解
- Generator: 分解された要件からSQLを生成
- Refiner: 生成されたSQLを検証・修正
Schema Linkerは、質問内容から関連性の高いテーブル・カラム情報、あるいは類似のQA事例といったメタデータを取得するプロセスです。自然言語を元に必要な情報を特定するこの技術は、ユーザーがどのテーブルを見ればよいか分からない、類似したSQLを参考にしたいといった課題を解決する重要な要素です。
DecomposerとGeneratorは、複雑な質問をより扱いやすいサブタスクに分解し、SQLを生成するプロセスです。
例えば、以下のような技術が用いられます。
- 質問を「取得したい項目(Targets)」と「条件(Conditions)」に分解する
- 曖昧な箇所を明確にするため、ユーザーと対話(マルチターン)を行う
今回のツールにおけるSQL生成ではまだ取り入れられていませんが、特に複雑な分析依頼における「要件整理」は多くのユーザーが抱える課題です。
Refinerは、生成されたSQLを事前に実行(Dry Run)し、エラーを検知・修正するプロセスです。この技術は、LLMが生成したSQLの精度を高めるだけでなく、ユーザーが書いたSQLのエラー修正を支援するというユースケースにも活用できます。これは今回のツールの要望としても多く上がった機能でした。
今後は各プロセスにおける技術要素をさらに取り入れたツールの強化を考えていますが、一方でこれらを取り込む上で必要なメタデータ整備も重要な観点です。
LLM関連技術は今後も発展・進化が予想されますが、必要なメタデータが未整備であることはボトルネックとなる可能性があります。そのため、技術の進展と並行してメタデータの整備も進めることが重要と考えています。

LT②:まなびのLLM活用事例
発表者:近藤さん
次に登壇した発表者は、「まなび」の領域におけるLLMの活用事例について共有してくれました。
複雑な情報の整理や学習支援といった、従来のデータ分析とは異なる視点でのLLMの応用例は、参加者にとって新たな気づきとなったことでしょう。
LLMが持つ多様な可能性と、それをいかにビジネスや日々の業務に落とし込むかというヒントが詰まったセッションでした。
内容
データ活用が企業の意思決定においてますます重要になる中、まなび領域データマネジメントグループ(以下「DMG」)では、データ分析業務のセルフ化を推進しています。これは、データ提供を「データの自動販売機」のようにし、意思決定に必要なデータの入手を誰でも自分でできるようにすることを目標にしています。
これまでAE(Analytics Engineering)施策を通じてセルフ化を進めてきました。しかし、サービスの拡充に伴い、ユーザーの「will(意欲)」「skill(スキル)」「stance(姿勢)」のばらつきが課題の中心となっていました。
このような背景の中、まなびDMGでは LLM を活用し、データ活用の新たな可能性を模索しています。なお、ここから先は、この記事の元となる発表時点ではLLMを取り巻く環境が今ほど進んでいなかったことを考慮し、読んでいただけたらと思います。
▼ LLMを活用したデータ分析業務の効率化への取り組み
まなびDMGではLLMを活用したデータ分析業務の効率化について様々な検証を進めていました。以下は当時検討・検証していた内容です。
テーブル情報・ダッシュボード情報・案件Issueの横断検索
LLMを用いた横断検索の可能性を検証。膨大なデータの中から必要なテーブル情報やダッシュボード、関連Issueを検索、要約して伝えるツールの開発を実験的に試行していました。
ダッシュボードの説明生成
Lookerのメタデータを活用したダッシュボード説明文の自動生成を検討。レポート内容の理解を助ける可能性を探っていましたが、簡易的な説明に留まり、ユーザーの知識に依存する面も多く、実用化には課題がありました。
ダッシュボードの生成(LookML)
Dashboard LookMLを用い、ダッシュボードの自動生成を検討。開発者のYAML記述や読み込みの負担を軽減し、標準化された量産型の解決策の可能性を模索していました。
SQLの生成
アナリストの思考プロセスに基づくSQL自動生成のプロセスを検討。要求のみからの生成よりも、要件定義書を一度作成することにより、高精度でSQLを生成できそうという気づきを得ました。これにより、SQLの書き方のばらつきの解消の可能性を探っていました。
SQLのチームレビュー
SQLのチーム内での作成プロセスにおいて、人が作ったクエリをレビューすることの負荷は以前より気づいていました。そこで、LLMにより、SQLが要件定義書通り作成できることを確認。レビューの効率化と標準化を模索しました。
依頼や要件定義のレビュー
LLMが依頼を受けて要件定義自体を生成するプロトタイプの検討。ルールの多様さやユーザーによる品質検証の必要性など、実用化にはさらなる実験と課題解決が必要であることを認識しました。
▼ 検証結果と今後の展望
これらの検証を通じて、LLMがデータ分析業務の効率化とセルフ化に一定の可能性を持つことが確認できました。特にサービス提供側としては「データ自動販売機」の整備に向けた技術的な解決策が見えてきたことは非常に好ましい結果でした。
一方で、当時のLLM技術の限界や、LLMそのものへのユーザー側の「will × skill × stance」のばらつきが既存のBI,SQL同様、もしくはより強い課題として浮上してくると考えていました。今後はこれらの課題への取り組みが重要となると考えています。
本記事執筆時点では、LLM技術のさらなる進化とともに、世の中の流れも大きく変わっており、LLMを用いたデータ活用の世界がより便利になってきていると感じています。今後もこれらの動向をキャッチアップし、アップデートしていきたいと考えています。


LT③:煩雑な障害広報をチョットダケ改善した話
発表者:荒木さん
最後のLTでは、日々の業務で誰もが直面しうる「煩雑な障害広報」という課題に焦点を当てた発表がありました。 「チョットダケ」という謙虚なタイトルとは裏腹に、具体的な改善策とそれによって得られた効果が示されました。 大規模なシステム改修ではなく、身近なツールや少しの工夫で業務効率が格段に向上するという内容は、多くの参加者に共感と実践への意欲を与えました。
内容
カーセンサーでは、データドリブンな意思決定を支えるため、900人以上にTableau Cloud上でワークブックやデータソースを公開しています。この規模の基盤を運用するにあたり、どのワークブックやデータソースで障害が発生しているか?をユーザーに把握してもらうことが重要になってきます。
従来の障害広報では、SlackやTeamsでの通知、シェアポイントへの情報記載を行っていましたが、実際の閲覧者数が非常に少ないという課題がありました。例えば、800人以上のチャンネルで障害広報を出しても、閲覧者は181人、まとめに至っては12人しかいませんでした。
この課題を解決するため、「見られてない」状態から「目に留まる」状態へ改善する施策として、Tableauワークブックを開いた際に、そのステータスをヘッダーに表示する仕組みを導入しました。
この改善の実装方法としては、以下のステップで行いました。
- ステータスデータとTableauの連携:
- BigQueryにステータスメッセージを管理するスプレッドシートをGASで連携させ、誰でも気軽にステータスを更新できるようにしました。これにより、ツールごとにステータスを出し分けられるようになっています。
- 管理用ワークブックの作成
- サンプルとなるステータス管理用のワークブックを作成し、モジュール化しました。このワークシートは、ステータス(SUCCESS、WARNING、ERROR)に応じて背景色が変わるように設定されています(白、オレンジ、赤)。
- 設定先のワークブックでの設定
- 管理用ワークブックから目的のワークブックへワークシートをコピーし、ワークブック名でフィルターすることで、各ワークブックが独立してステータスを管理できるようにしました。また、ダッシュボードのヘッダーとして追加する際に、アクション設定によりシェアポイントへのリンクを設けています。
今後は、Tableauワークブックだけでなく、データソースを利用しているユーザーにも、障害発生時に「このデータソースは使えない」とすぐにわかるような仕組みを検討していく予定です。

ワークショップ:dbt CoreのSemantic modelsを活用したモニタリング資材開発を始めよう
担当:山家さん
「見る」だけでなく「手を動かす」ことで、より深い学びが得られるよう企画された今回のワークショップでは、dbt CoreのSemantic modelsを活用したモニタリング資材開発に挑戦しました。
内容
このワークショップの目的は、アナリティクスエンジニアにとって強力なツールであるdbt CoreのSemantic modelsを実際に操作し、データモニタリングのための資材開発を体験することでした。 参加者は、講師の丁寧なレクチャーのもと、Semantic modelsの概念理解から、実際のデータモデル構築、そしてモニタリング環境のセットアップまでをハンズオン形式で実践。 データの一貫性と信頼性を確保するための具体的な手法を学ぶことができました。 多くの参加者が、集中して手を動かし、疑問点をその場で解消しながらスキルを習得する貴重な機会となりました。


最後に
学びと交流が加速した一日
第2回LT会と初のワークショップは、参加者全員にとって実り多い一日となりました。
LT会では多様なテーマから新しい知見や業務改善のヒントを得て、ワークショップでは最先端のツールであるdbt CoreのSemantic modelsを使った実践的なスキルを習得できました。
知識のインプットと実践的なアウトプットを組み合わせた今回の形式は、参加者間の活発なコミュニケーションとネットワーキングの機会も生み出し、アナリティクスエンジニアコミュニティの活性化に大きく貢献できたと感じています。
今後も、データ推進室データマネジメント部では、このような学びと交流の場を継続的に提供していく予定です。次回のイベントレポートもぜひご期待ください。

ご興味のある方は、ぜひ以下ページもご覧ください。