目次
背景: LambdaのソースコードをTerraformで管理するのが辛くなってきた
これまでAWS Lambdaのソースコードは、Terraformのarchive_fileを使ってzip化してS3にuploadする、という方式で管理していました。はじめのうちはこれで問題なかったのですが、Lambdaのソースコードに差分は無いのに、zipとしてはなぜか差分が発生しており、terraform applyするたびに差分が発生して辛いといったことが起きるようになってきました。
Terraformで管理してLambdaが実行されるまでを図で説明すると下図のようになります。
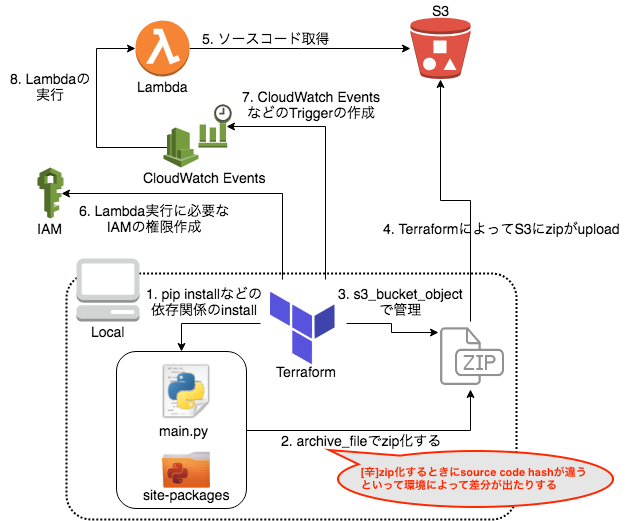
ローカル環境でLambdaのコードをS3にuploadするためにTerraformでzip化するところで意図せぬ差分が発生するという状況です。これによって、「なぜか毎回微妙な差分が出るんだけど、ほんとにこれapplyして大丈夫なんだろうか・・?」みたいな疑問を抱えつつapplyしていました。
何事もTerraformでやれば良いってものじゃなかったと反省。
前提: Terraformはインフラを管理するツールである
弊社エンジニアのma2k8が、TerraformでLambda管理することの何が辛いのかについて社内Wikiにまとめていたので、これを引用します。
- Terraformはインフラの状態を定義するツールとして最高
- 一方でLambda関数の状態を定義するのには以下4つの要素が必要
- AWSのオブジェクト管理(Lambda Function、IAM、triggerのためのCloudWatch Eventsなど)
- Lambda関数のソースコード
- Lambda関数のソースコードに依存するライブラリたち
- ソースコードとライブラリを固めたzip
- インフラの状態を定義するツールであるTerraformで上記4点を管理すると、applyのたびに
npm installなりを実行せなばならず、意図せぬ差分が発生しやすい。
- これはequal意図して変更していないコードのデプロイとなり、applyするのが恐ろしい状況になってしまう。
- それを回避するためにライブラリ(node_modulesやgem等)とzipをgit上にあげて差分が発生しない状況をつくっていたが数千ファイルを超える依存ライブラリや、バイナリであるzipをガンガン突っ込んでいくとFileChangesが6000とかになってかなり辛い・・
つまり、今まで辛かったのは、上記でいう1️⃣と2️⃣、3️⃣、4️⃣の分離ができていなかったということになります。
解決策: Apexを導入するとAWSのリソースとLambdaのコードとデプロイの分離ができる
ApexはAWSのLambdaのビルドからデプロイまでをやってくれるツールです。
今回は図を書いてみたのでそれを元に説明します。
先ほどのTerraformで管理していた頃と比べると、大きく違うのはS3にzipをuploadしないで直接Lambdaにuploadしている点です。これによってarchiveしたzipを入れるS3の管理や、zipファイルをterraformで管理する必要がなくなります。

つまり、この時点で先ほどの1️⃣、2️⃣、3️⃣、4️⃣でいうところの2️⃣、3️⃣、4️⃣をやってくれるということです。もう分離できました。最高ですね。
気付き: ちょっと待って! AWSのオブジェクト管理はどうするの?
ここがapexの優れているところです。上記の1️⃣、2️⃣、3️⃣、4️⃣でいうところの1️⃣も良い感じに管理してくれるコマンドが用意されています。その名はapex infraというサブコマンド。実はこれ、なんとみんな大好きTerraformのただのラッパーなのです!
そのためTerraformを愛用している弊社にもぴったりということです。図で示すとこんな感じ。
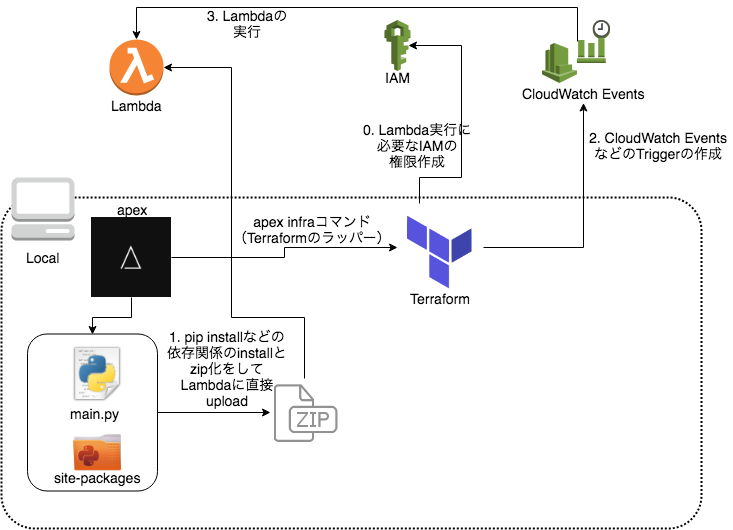
apexでLambdaをdeployする前に、必要なIAM RoleをいつものHCL形式でtfファイルに書いてあげるだけ。あとは、apex infraコマンドでIAM Roleが作成されるので、apexでLambdaをdeployするときにそのIAM Roleを指定すればLambdaが動かせる状態になります。
あとは、CloudWatch EventsなりS3のEventなり好きなTriggerをこれまたtfファイルに書いてapex infraコマンドで適用すれば完成です。
これで見事に1️⃣と2️⃣、3️⃣、4️⃣が分離できましたね。
実は1️⃣が分離出来ているため、別にapex infraコマンドで管理しなくても、素のTerraformで管理しても良いことになります。この辺はどちらでも構わないのですが、apex infraコマンドを利用すると、LambdaのARNやLambdaの関数名をバインドしてくれるので、そちらの方が楽になると言えます。
解説: apex化したときの具体的なソースコードの配置の仕方
ここまではざっくり概念を説明してきましたが、ここからは実際の運用イメージを軽く話します。
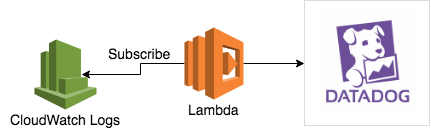
例としてDatadog logsにCloudWatch LogsのログをsubscribeしてDatadog Logsに送りつけるLambdaを実行する場合の構成です。
ディレクトリ構造は以下のようになります。
apex/event_driven_job/
├── functions
│ ├── datadog_logs
│ │ ├── function.json
│ │ ├── lambda_function.py
│ │ └── prod-test-event.json
├── infrastructure
│ └── prod
│ ├── datadog_logs.tf
│ ├── main.tf
│ └── variables.tf
├── project.json
└── project.prod.json
少々難解ですが、functionsというのがLambdaの関数が置かれる場所で、infrastructureというのは、Lambdaに関連するTerraformのコードがおいてある場所です。
infrastructureの下にprodっていうのがありますが、これは環境ごとにLambdaを作り分けられるというapexの機能です (envという考え方があります) 。なのであまり深く考えなくてOKです。
infrastructureのコードから説明
terraform {
backend "s3" {
bucket = "***********"
key = "apex/event_driven_job/terraform.tfstate"
region = "ap-northeast-1"
}
}
provider "aws" {
region = "ap-northeast-1"
version = "~> 1.39.0"
}
provider "template" {
version = "~> 1.0.0"
}いつものように、awsのproviderやremote_backendの設定を記述する箇所です。apex特有の書き方はありません。
datadog_logs.tf
###################################################
# IAM
# apexでLambdaをデプロイする際に必要となるiamを作成する
###################################################
resource "aws_iam_role" "datadog_logs_lambda_role" {
name = "datadog-logs-lambda-role"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}
EOF
}
data "aws_iam_policy_document" "datadog_logs_lambda_policy_doc" {
statement {
sid = "1"
actions = [
"s3:GetObject",
]
resources = [
"*",
]
}
statement {
actions = [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
]
resources = [
"arn:aws:logs:*:*:*",
]
}
}
resource "aws_iam_role_policy" "datadog_logs_lambda_policy" {
name = "datadog-logs-lambda-policy"
role = "${aws_iam_role.datadog_logs_lambda_role.name}"
policy = "${data.aws_iam_policy_document.datadog_logs_lambda_policy_doc.json}"
}
output "datadog_logs_lambda_role" {
value = "${aws_iam_role.datadog_logs_lambda_role.arn}"
}
data "aws_cloudwatch_log_group" "log_group" {
name = "your_log_group"
}
resource "aws_cloudwatch_log_subscription_filter" "datadog_logs_filter" {
name = "datadog_logs_filter"
log_group_name = "${data.aws_cloudwatch_log_group.log_group.name}"
filter_pattern = "ERROR"
destination_arn = "${var.apex_function_datadog_logs}"
}
resource "aws_lambda_permission" "datadog_logs_filter" {
statement_id = "datadog_logs_filter"
action = "lambda:InvokeFunction"
function_name = "${var.apex_function_datadog_logs}"
principal = "logs.ap-northeast-1.amazonaws.com"
source_arn = "${data.aws_cloudwatch_log_group.log_group.arn}"
}
IAM roleを作成したりCloudWatch Logsのsubscribeを書いたりしているのが見てお分かりかと思います。
functions側のコードの説明
apexは大きな枠としてprojectという概念があり、Lambdaの一つ一つがfunctionという概念があります1)さらにenvという概念でfunctionを環境ごとに作ることもできます。。
{
"name": "event_driven_job",
"description": "event driven job",
"nameTemplate": "{{.Project.Name}}_{{.Function.Name}}"
}ここには大枠のprojectの共通の概要みたいなことを書いておきます。今回はcloudwatch eventsでtriggerされるようなLambdaを一つのprojectとしてまとめると分かりやすいかなということで、このように分けています。nameTemplateにこのように書いておくと、Lambdaの関数名がこれに従って登録されるというものです。
{
"name": "datadog_logs",
"description": "AWS lambda function to ship ELB, S3, CloudTrail, VPC, CloudFront and CloudWatch logs to Datadog",
"runtime": "python2.7",
"role": "arn:aws:iam::xxxxxxxxxxx:role/datadog-logs-lambda-role",
"environment": {
"DD_API_KEY": "*****************************"
},
"memory": 1024,
"timeout": 120,
"handler": "lambda_function.lambda_handler"
}ここにはLambdaの詳細な情報を記述します。例えば、Pythonで実行するだとか、deploy時に走らせるコマンド(pip installなど)やメモリの量や環境変数などです。
ちなみに、ここで指定した値はproject.jsonで定義した値を上書きできるので、共通の値などはproject.jsonに書いておくというのもありです。
補足: 実際のコマンド
複雑にならないように最低限のものを紹介しますが、Lambdaをテストするのに必要なものは概ね揃っていると考えていただいて大丈夫です。
| コマンド | 概要 |
|---|---|
apex build <function_name> |
ローカル環境にzip化するところまでやってくれる |
apex deploy <function_name> |
Lambdaをzip化してLambdaにデプロイしてくれるところまでやってくれる |
apex logs <function_name> |
Lambdaの実行ログをターミナルの標準出力に出してくれる。便利!! |
apex infra <plan|apply> |
そう。Terraformのあれ。そのまま。 |
まとめ
長々と説明してきましたが、Terraformで管理しているLambdaをとりあえずapex化しておくのは良いアプローチです。従来のものが壊れるわけではないため、すぐにデプロイし直すことでdowntimeの発生も抑えられます。
はじめのうちは概念を理解するまで一苦労するかもしれませんが、一度慣れてしまえば一気に理解できることでしょう。
脚注
| ↑1 | さらにenvという概念でfunctionを環境ごとに作ることもできます。 |
|---|