目次
こんにちは、Androidエンジニアの釘宮 (@kgmyshin) です。
2017年8月、スタディサプリ ENGLISHから『TOEIC® L&R テスト対策コース』がリリースされました。既に運用されている既存プロダクトに新サービスを追加した形となったため、非常に大規模な改修を行いました。
私はこのプロダクトのマネージャー兼Androidエンジニアをしているのですが、この時期はサーバーサイドエンジニアとして開発に参加しました。今回はそこで得た様々な技術的知見をご紹介します。
そもそもスタディサプリ ENGLISH ってどんなサービス?

スタディサプリ ENGLISHは、『オンライン英語学習サービス』です。『読む』『聞く』『話す』『書く』という英語の4技能を、ドラマ仕立てなストーリーを読み進めながら学べるのが特徴です(『日常英会話コース』といいます)。
2015年10月にiOS版アプリをリリース。その後Android版、webブラウザ版 ( PCのみ ) と続けてリリース。運用開始から2年ほど経つサービスです。
そして、2017年8月にTOEICの学習に特化した『TOEIC® L&R テスト対策コース』 ( 以下TOEIC対策コース ) を新設しました。
技術的観点からの スタディサプリ ENGLISH 概要
各プラットフォームの使用言語とフレームワークは下記の通り。
| プラットフォーム | 言語 | フレームワーク |
|---|---|---|
| web | TypeScript / Stylus / Pug | Angular / Cycle.js |
| Android | Java + Kotlin | - |
| iOS | Swift | - |
| Server | Scala | Play Framework |
ここからはサーバーサイドにフォーカスした大規模改修の詳細についてご紹介します。
大規模改修前のサーバーサイドの構成
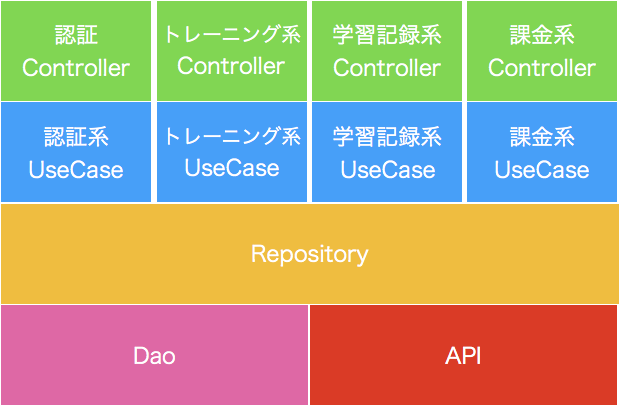
当時はこのようなレイヤードアーキテクチャを採用していました。縦はController、UseCase、Repository、データ層で区切り、横はコンテキスト毎にパッケージで区切られています。当初から複雑な仕様・要件でしたが、それぞれの影響範囲は明確となっているので、新規に参画するエンジニアにとっても十分に見通しの良いものとみなしていました。
事実、この設計で2年ほどエンハンスを続けてきましたが、大きな問題が発生することはありませんでした。
なぜ大規模改修が求められるようになったのか
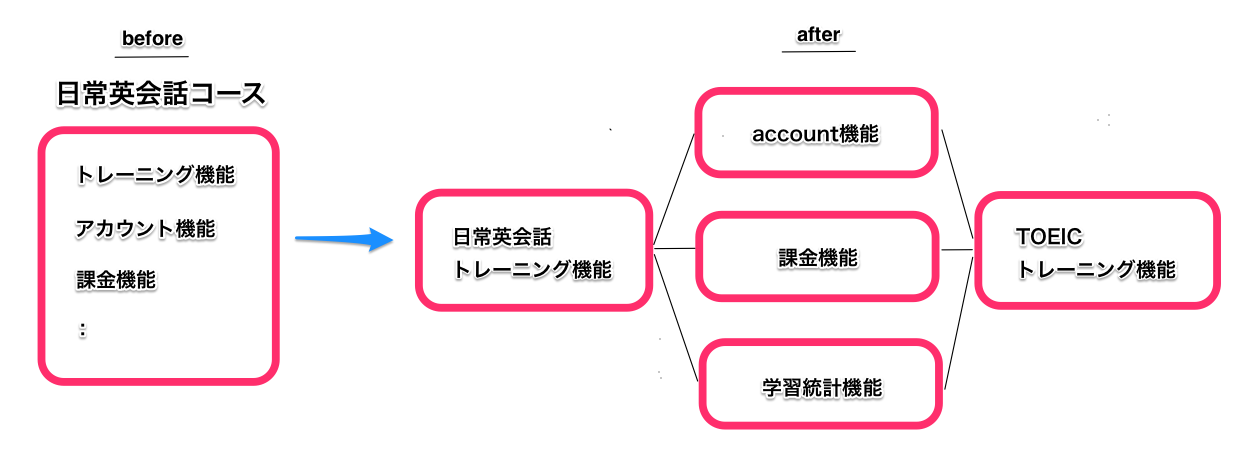
『TOEIC対策コース』の新設が決まり、その仕様を詰めていくうちに次のことが浮き彫りとなってきました。
- TOEIC対策コースと日常英会話コースとでは『レッスン』と『トレーニング』のツリー構造が根本的に異なる1)日常英会話コースでは1レッスンにつき毎回種類固定の5トレーニング。TOEIC対策コースは日常英会話コースとは別種類のトレーニングを1レッスンにつき幾つでも設定可能。
- 学習統計情報は日常英会話コースとTOEICコースを合算する必要がある
TOEIC対策コースは、既存の日常英会話コースと仕様・要件が大きく異なります。加えて、下記の理由から現状の設計のままでは実現が難しいことが判明しました。
- DBのテーブル構造が日常英会話コースのトレーニングのツリー構造でロックインされている
- 学習統計情報の持ち方が日常英会話コースの行うトレーニングありきとなっていた
これらをふまえ、サーバーサイドとインフラの大規模改修に踏み切ることとなりました。
大規模改修後のサーバーサイドの構成
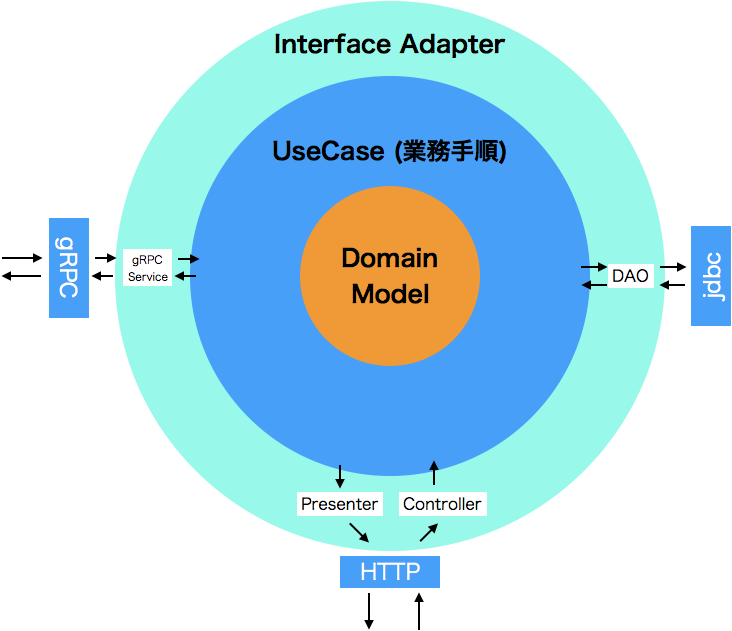
上記のようにモノリシックだったものをコンテキストごとに分割し、それぞれでサーバーを建てるようにしました2)もともとサービス毎にサーバーを立ててはいたのですが、一部大きな単位でまとめてしまっていました。。各コンテキストはエンドポイントを持っており、クライアントサイドは欲しい情報を各エンドポイントから取得します。
これらの変更により、下記が実現できました。
- ユーザー基盤を汎用的にした
- 課金基盤を汎用的にした
- 新しい課金体系や『複数のコースを組み合わせる』という課金方法も可能となった
- 今後、TOEIC対策以外の新しいコースの追加が容易となった
さらに細かく解説すると、コンテキスト間の情報のやりとりにはgRPCを使用してます。各コンテキストでは以前より厳密なクリーンアーキテクチャを採用しました。
改修前の設計では、技術的関心事と業務知識の分離がしきれていなかったこと、またUseCaseと名のつくものはあったものの、引数にHTTP Requestを取ってしまっていたことから内部通信の導入が難しい設計となってました。それがクリーンアーキテクチャの導入により、ドメインモデルが他のレイヤーに漏洩しなくなり、またHTTPやgRPC関係なくUseCaseの再利用が可能となりました。
実際に大規模改修を通じて得た知見
コンテキストを跨った情報をインフラ層から返すような状態だと変更に弱い
改修前は、『コンテキストに分ける』という考えが乏しい状態でした。とは言え少なからず意識はしていたのでパッケージ毎に分けていたのですが、何も知らない人がインフラ層でコンテキストに跨った情報をまとめてしまうことがありました ( それが可能な状態だった ) 。
今回のように意味ある情報のまとまりに分けねばならない際に、インフラ層レベルからコンテキストの統合のようなものが発生している際、業務手順のレベルから変更せねばならず大変修正に苦労しました。
可能であれば〈コンテキストごとモジュールに分ける〉か、もしくはせめて〈インフラ層レベルから変換する情報は意味あるまとまりにする〉べきということを学びました。
gRPCのメリット・デメリット
メリット
インタフェースを定義するだけで、通信の実装処理などを書かなくても呼ぶ側呼び出し側双方でただの関数呼び出しのように使えます。
例えば、下記のような protoファイルを用意します。
message UserResponse {
string id = 1;
string name = 2;
string bio = 2;
}
message FindUserByIdRequest {
string id = 1;
}
service ApiService {
rpc findUserById (FindUserByIdRequest) returns (FindUserByIdRequest) {}
}基本的にはこれで呼び出す方で clientから findUserById を呼び出すだけ、呼び出される方は findUserById を実装するだけです。実際の通信処理などを自分で書く必要性はありません。さらに内部でprotocol bufferを使用しているため、jsonでやり取りするよりも通信量が少なくなるので早く処理できます。
デメリット
現在はprotoファイル群をライブラリとして外出ししています。
開発中は生成されるバイナリのバージョンがコロコロ変わるため、そことの同期漏れなどで時間を食われることがよくありました。3)これはgRPCというよりマイクロサービスで開発しているのが原因ですが。バージョンが変わる度にIDEを落としてsbt gen-idea コマンドを打たねばならず、頻繁に変更を加えたい時には辛かったです。当初はIDEのsyncボタンを押せば事足りると思っていたのですが、滅多に機能しませんでした。
また上記のコマンドを打っても動かない場合があり、その時は .idea の中に潜ってそれらしきファイルのバージョンの文字列を手動で変えてました4)新しいバージョンのダウンロード自体は上記コマンドで完了しているので、設定ファイルを変更することで動きます。
今後さらに取り組みたいこと
今後はサービス間を跨いだテスト、さらにデバッグしやすいログ環境の整備、CQRS、ユースケース層にフリーモナドの導入などを計画しています。