はじめに
初めまして、株式会社リクルート ICT統括室の加瀬です。
本記事では、昨年の記事に続いて、私のチームで管理運用するvSphereで仮想化されたハイブリッドクラウド環境内で、L2延伸を構成した場合の活用例と、ちょっとした落とし穴について紹介します。
前回のおさらい
昨年の記事で、私のチームで管理運用するvSphereで仮想化されたシステムが、HWの保守契約満了の接近をきっかけとして、HCXによるL2延伸をつかってオンプレ環境からOracle Cloud VMware Solution(以下OCVS)へ移行するための環境を構築したことと、その際にハマったトラブルについてご紹介しました。
その後、オンプレに存在する本番稼働中の仮想マシン(以下VM)を、実際にクラウド側へ移行していくことになりました。
L2延伸によるVMの移行方法
HCXによるL2延伸を構成することで、HCXの機能として当時、以下4つの移行手段が利用できるようになりました。
|
移行手段 |
特徴 |
IPアドレス |
移行時のVM影響 |
同時移行VM数 |
スケジュール |
|
Cold Migration |
VMをオフラインにして移行する。最も平易。 |
不変 |
移行完了までパワーオフ |
1 |
非対応 |
|
Bulk Migration |
多数のVMを同時並行で移行可能。 |
不変 |
移行時に再起動発生 |
多数可 |
可能 |
|
vMotion Migration |
VMがオンラインのまま移行可能 |
不変 |
オンライン |
1 |
非対応 |
|
Replication Assisted vMotion Migration |
多数のVMをオンラインのまま同時並行で移行可能 |
不変 |
オンライン |
多数可 |
可能 |
今回の移行対応では、以下の理由でBulk Migration(以下Bulk移行)とReplication Assisted vMotion Migration(以下RAV移行)の2つを採用しました。
- 移行に関する検証の負荷軽減および仮想環境上で開発を行うシステム管理者向けの移行案内を簡略化する目的で、移行手段は最小限に絞りたい。
- VM複数台の移行に対応したBulk移行とRAV移行は、当然ながらVM1台だけの移行にも対応しており、VM複数台の移行に対応していない移行手段の上位互換となる。
- Bulk移行ではVM移行の切り戻し作業が容易なため(詳細後述)、移行作業時のVMへの影響よりも切り戻しの容易性を重視するシステムの移行時に使う。
- RAV移行ではVMをオンラインにしたまま移行が可能なため、移行作業時のVMへの影響を避けたいシステムの移行時に使う。
採用したBulk移行とRAV移行について移行時の動作を簡単にご説明したいとおもいます。
Bulk移行
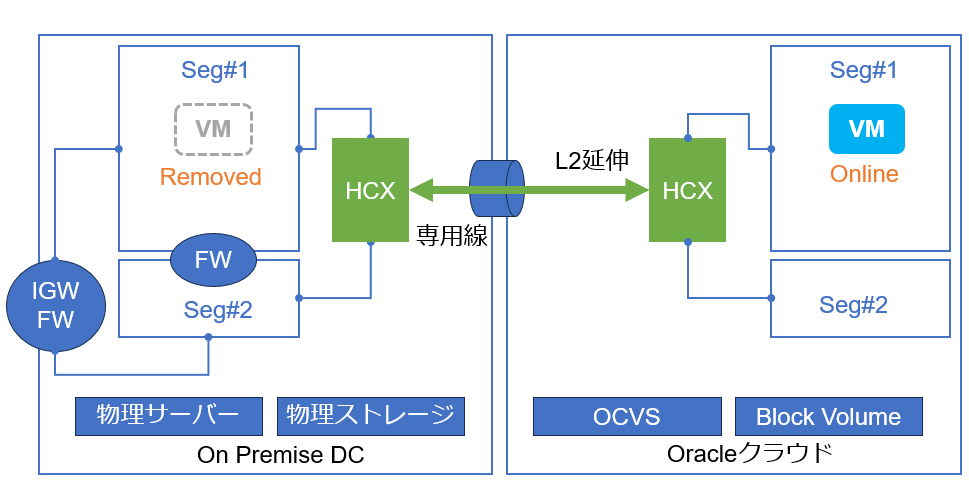
Bulk移行を開始すると、移行対象となるオンプレ側のVMのクローンが、OCVS上に作成され始めます。この時、移行対象となるオンプレ側のVMはオンラインのままで動作に影響はありません。
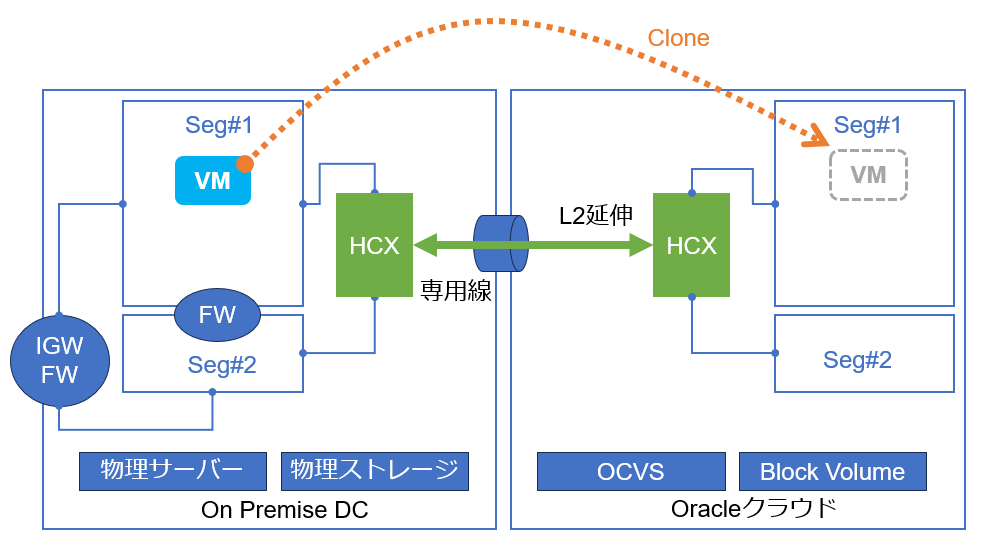
OCVS上のクローンの作成が完了すると、移行対象となるオンプレ側のVMはパワーオフされ、OCVS側のクローンがパワーオンされます。OCVS側のクローンがパワーオンすることで移行が完了したことになります。その後、OCVS側のクローン上で各種サービスが動作開始することでサービス復旧となるため、VM移行時にはVMの再起動と同程度のサービス影響が発生します。
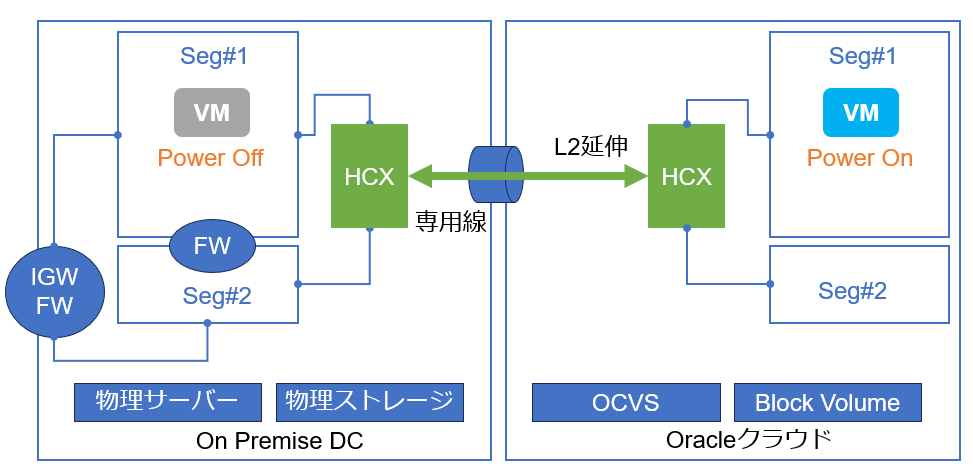
一方、オンプレ側にVMのオリジナルがパワーオフの状態で残存していますので、移行によって何らかのトラブルが発生した場合は、OCVS側のクローンをパワーオフし、オンプレ側のオリジナルのVMをパワーオンするだけで切り戻しが完了します。
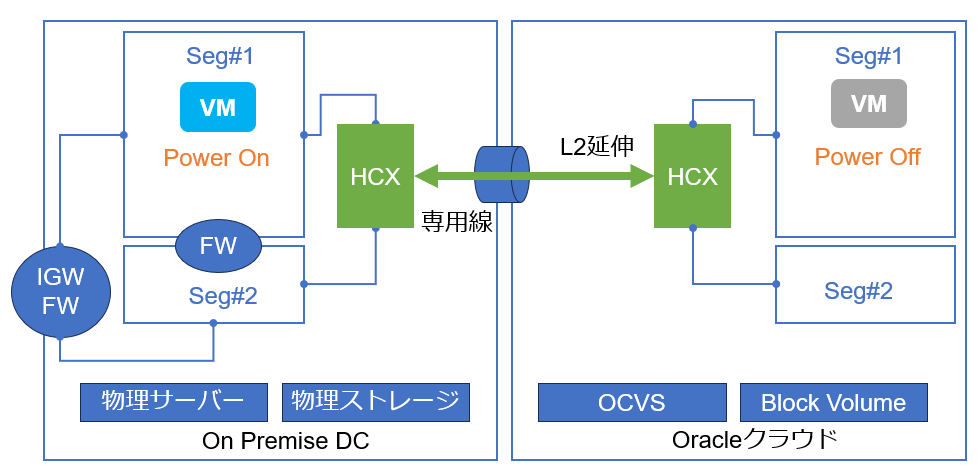
実際の移行では、静的な情報を公開しているWebサーバーなどのように、再起動程度の短時間のダウンタイムを許容できる場合はBulk移行を採用するケースが多く見られました。後述のRAV移行は原則オンラインですが、移行時に想定外事象が発生した場合の切り戻しに時間を要するため、作業時間や想定外発生時の影響が長期化するリスクが伴います。
RAV移行
RAV移行を開始すると、移行対象となるオンプレ側のVMのクローンが、OCVS上に作成され始めます。Bulk移行と異なり、OCVS側のクローンはReplication機能をつかってディスクデータを完全同期しながら作成されます。この時、移行対象となるオンプレ側のVMはオンラインのままで動作に影響はありません。
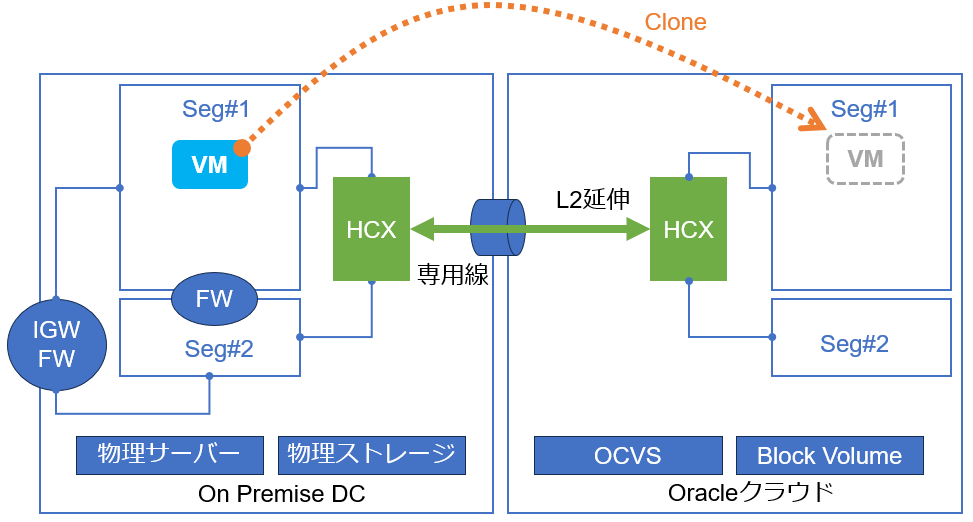
VMがオンラインの場合、データ同期中もデータの差分が生まれますので、差分容量によってはSnapshotを作成しながら複数回のデータ同期を行います。データ差分が小さくなると最後の同期を行ってから、vMotion機能をつかってCPUやMemory等の処理をオンプレ側からOCVS側へ切り替えます。切替時にオンプレ側のVMは自動で削除されます。こうしてVMがオンラインのままで移行が完了します。
RAV移行ではBulk移行と異なり、移行完了後にオンプレ側にオリジナルのVMが残りませんので、何らかの理由で移行作業の切り戻しが必要になった場合は、OCVSからオンプレに向けたVMの移行(以下、逆移行)が必要になります。逆移行の際は改めてデータ同期が行われますので、ディスク容量によっては相応の時間がかかります。
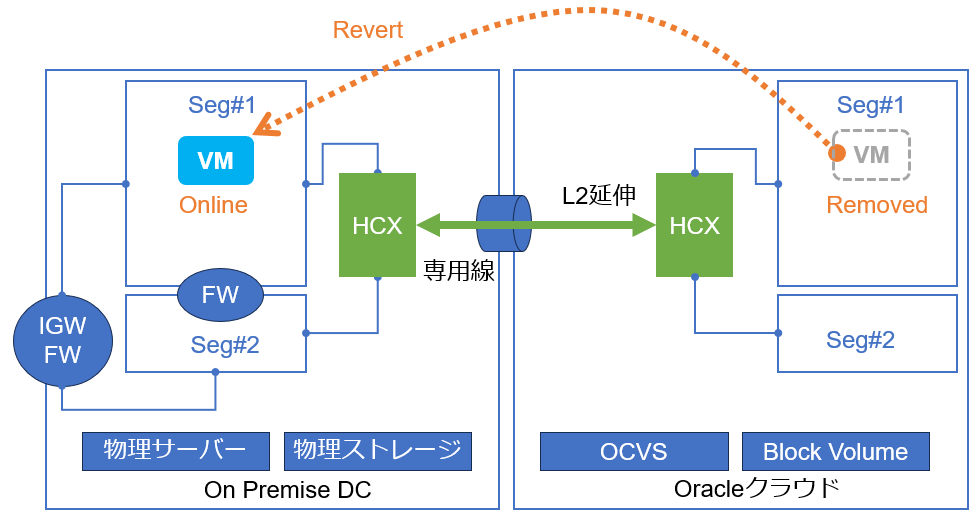
実際の移行では、複数のシステムから常にデータ連携を受けているDBやログなどが稼働している環境といった、再起動によるダウンタイムを避けたい場合にRAV移行を採用する傾向がありました。移行中はping落ちすら発生することはありませんでしたので、移行作業の影響を最小限に抑えられています。一方で、RAV移行によって想定外が発生すると、切り戻しには時間がかかりますので、再起動という予測可能な作業影響を受け入れるか、想定外発生時に何らかの影響が長時間発生する不確定なリスクを受け入れるかを慎重に検討する必要があります。
実際のVM移行結果の例
各移行方法によって、どのくらいのリソースが、どのくらいの時間で移行完了できたのか、例として実際に本番稼働していたVMの移行結果をご紹介します。移行速度は、利用できる物理リソースやクラウド環境までの専用線をふくめたネットワーク構成などによって大きく変動しますので、あくまで一つの例としてご参照ください。
Bulk移行

黒塗りつぶしはホスト名で、そこから右に向かって順に移行方法(Bulk)、移行対象VMのディスク容量/メモリー容量/CPUコア数、移行ステータス、移行開始時間、移行完了時間、完了ステータス。
ディスク容量328GBのVMを2台同時に移行開始し、35分ほどで2台とも移行完了。ディスク容量で見た移行速度は約18.2GB/分。Bulk移行ですので、移行の最終段階で移行対象の仮想マシンは再起動しています。
RAV移行

ディスク容量2.5TBの大きなVMに対してRAV移行を日中帯に堂々と実施。ディスク容量でみた移行速度は約6.5GB/分。Bulk移行より速度が落ちていますが、RAV移行では移行中もVMは終始オンラインのままで、ping落ちも発生しませんでした。一方、オンラインで移行するのでRAV移行の最中にデータ差分が発生するとその同期もおこなわれます。従って、RAV移行の対象となるディスク容量が大きいと移行時間が長くなり、移行時間が長くなることでデータ差分が発生しやすくなってさらに移行時間が長くなる、という悪循環が発生します。ディスク容量が大きい場合やデータ差分が発生しやすい環境でRAV移行を採用する場合は、移行時間が長期化する可能性を踏まえて作業計画を立てる必要があります。
基盤としての移行結果
Bulk移行とRAV移行を併用することで、当仮想基盤は2023年10月頃から2024年9月頃までの約1年間でVM数で約250台、システム数で約50システムを移行し、この間、一度も移行の切り戻しを発生させることなく、すべての移行作業が完了しました。移行時にはiSCSI接続でマウントしているストレージ領域の対応も一緒に解決しています。
製品のサポート期間に落とし穴
移行は安定しておりましたが、一つだけ落とし穴がありました。L2延伸や移行の機能を提供しているHCXは、なぜかやたらとサポート期間が短いのです。General Supportが受けられる期間をサポート期間として考えると、vSphere ESXiやvCenterなどは過去実績(※1)として、メジャーバージョンがリリースされるとその日から約5年間はGeneral Supportが提供されてきましたが、HCXだけは約1年(※2)しかサポートを受けることができません。
※1 vSphereのEOLSについては下記を参照
Announcing Extension of VMware vSphere 7.x and VMware vSAN 7.x General Support Period
※2 HCXのサポート情報の詳細はBroadcom社の公式情報を参照ください
従ってL2延伸を構成する期間が1年を超える場合は、たとえ移行期間中であっても実質的にほぼ毎年、HCXをバージョンアップする必要があります。実際に私の環境でも移行期間中に一度バージョンアップをすることになりました。
バージョンアップは簡単かつ影響は軽微
やっと構築が終わって安定して移行できるようになった環境にわざわざバージョンアップをしかけるなんて、私は全く気が進みませんでした。とはいえ、サポート期間の終了日は待ってくれませんのでやるしかないと腹を括って挑みました。
しかし、いざやってみるとHCXのバージョンアップ作業はとてもシンプルで、作業影響も小さなもの(ping数回落ち程度)でした。簡単ですが、v4.6.3からv4.8.2にバージョンアップする際の流れをご紹介します。
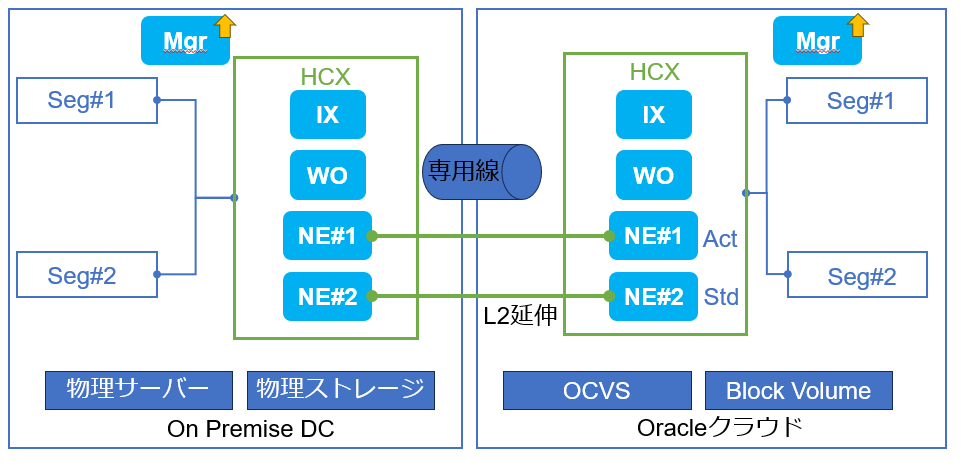
HCXのバージョンアップで意識する必要がある構成要素は大きく2種類に分類でき、HCX ManagerとHCXコンポーネントです。
HCX Managerのバージョンアップ
HCX Managerのバージョンアップ作業は、L2延伸を構成しているNWの動作に影響ありません。作業は単純で、予めイメージをダウンロードしておき、必要であればバックアップを取った上で、”Upgrade”の実行を押すのみです。オンプレ側とクラウド側それぞれのHCX Managerでバージョンアップ作業を行う必要があります。
イメージのダウンロード
HCX Managerにログイン後、「Menu」 > 「HCX」 > 「Administration」 > 「System updates」 > 「SELECT SERVICE UPDATE」 > 「4.8.2.0」 > 「Download」の順に選択し、モジュールをダウンロードする。
イメージの適用(バージョンアップ)
HCX Managerにログイン後、「Menu」 > 「HCX」 > 「Administration」 > 「System updates」 > 「SELECT SERVICE UPDATE」 > 「4.8.2.0」 > 「Upgrade」の順に選択し、モジュールをバージョンアップする。
HCX コンポーネントのバージョンアップ
HCX コンポーネントとしてHCX Interconnect(以下、IX)とHCX WAN Optimizer(以下、WO)とHCX Network Edge(以下、NE)の3種が存在します。IXとWOのバージョンアップはL2延伸動作に影響ありません。NEをバージョンアップする際は、NEのActive/Standbyが切り替わるタイミングでL2延伸を構成しているNW上で、ping数回程度の通信断が発生します。オンプレ側もしくはクラウド側いずれかのHCX Managerを操作することで、オンプレ側とクラウド側両方のIX/WO/NEの全てに対してバージョンアップ作業を実施可能です。

バージョンアップ
HCX Managerにログイン後、「Menu」 > 「HCX」 > 「Interconnect」 > 「Service Mesh」 > 「UPDATE APPLIANCES」 > 「UPDATE」の順に選択する。
その後、アップグレードするアプライアンス(IX/WO/NE)にチェックを入れ、「UPDATE」をクリックする。
最後に
HCXによるVMの移行は動作がとても安定しており、トラブル無く移行対応を終えることができました。その裏側は長い歴史と実績のあるvSphereのクローンやReplication、vMotionなどの機能が支えており、結果として堅牢に動作したものと考えています。仮想環境の延命やスケールの柔軟性獲得に課題感を持たれている方は、HCXをつかったクラウド環境との接続やハイブリッド化をご検討してみてはいかがでしょうか?HCXを採用する際は、サポート期間が短いことを念頭に、しっかりと運用設計した上でご利用いただくことを推奨いたします。
このブログを読んでピンと来た方は、ぜひ一度採用サイトもご覧いただけるとうれしいです。まずはカジュアル面談から、という方も大歓迎です。
また、他にも色々な記事を投稿していきます!
過去の記事もご興味あれば、ぜひ他の記事もあわせてご参照ください。
・Recruit Tech Blog
・リクルート ICT統括室 Advent Calendar 2024
・リクルート ICT統括室 Advent Calendar 2023