目次
こんにちは。Androidエンジニアの@kgmyshinです。
日本時間2016年5月19日から5月21日の3日間 Google が開催するクリエイティブ・カンファレンス『Google IO 2016』。今回はMachine learning & artという機械学習と美術作品の組み合わせをテーマにしたセッションをレポートします。
今や機械学習は単に情報を解析するためのテクノロジーだけではなく、画像、音楽、そして動画までもを操作して全く新しいものを生成するツールとして扱われるようになり始めています。
このプレゼンでは『芸術的価値のような定量化や言語化のできない価値を機械が理解するアプローチ』として機械学習を用いるようです。
今から約18ヶ月前、Cultural Institute Labは芸術文化に対して機械学習を適用するために多くの芸術家や技術者を招待しました。このセッションではデモを交えつつその18ヶ月の成果が発表されました。
まずは研究所の紹介
はじめに The Google Cultural Institute の紹介が始まりました。
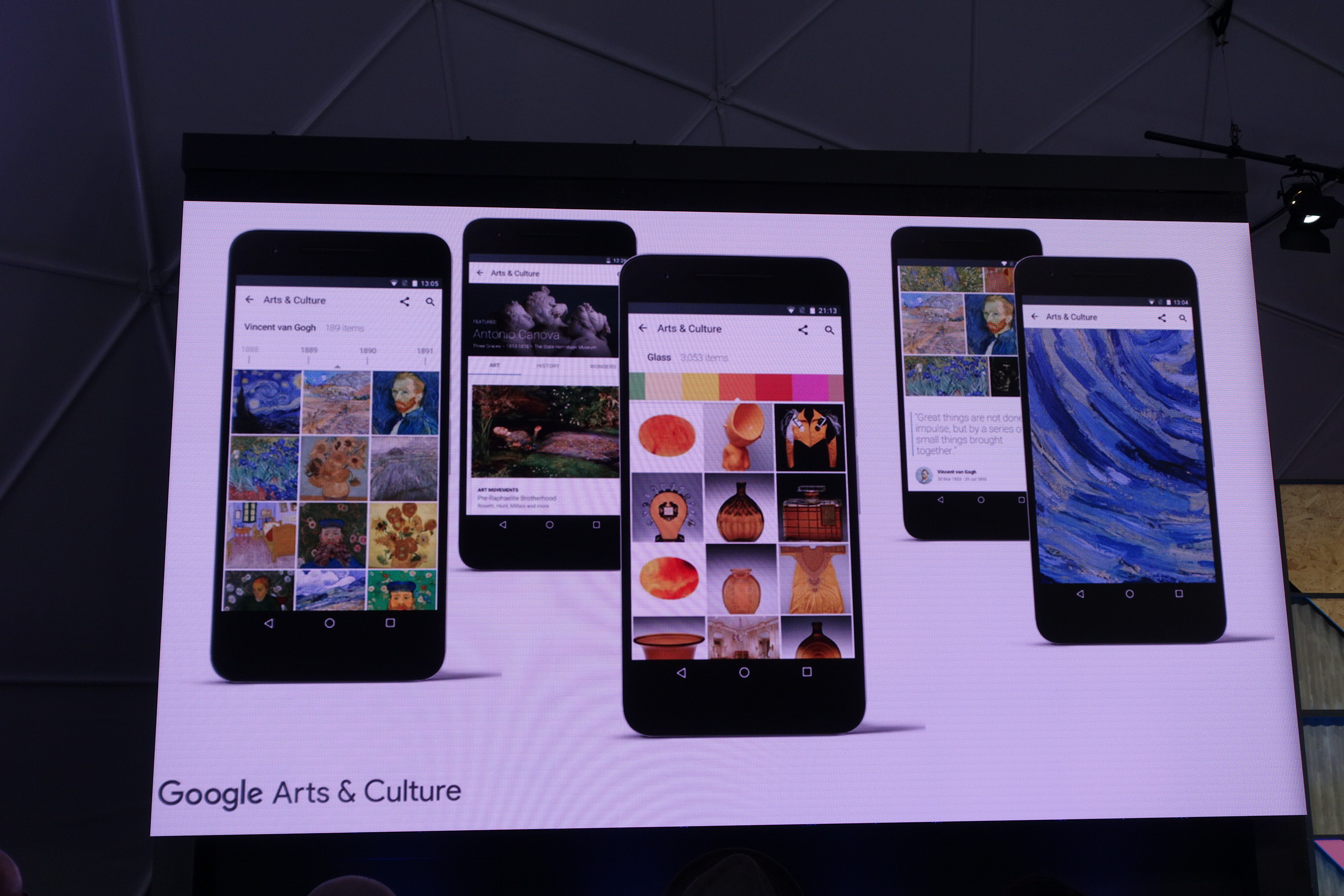

世界中にある約1000ほどの美術館と協力してこれらの美術品をデジタル化しています。

ここで機械学習の説明に入ります。機械学習とは、全てを正確にプログラミングするのではなく、コンピュータが学習する能力を持つようにする領域のことであると定義されております。

[本題] 機械学習と芸術について

偶発的に価値あるものを生み出す機械をつくるにはどうすればよいのでしょうか。

これらの5つのものをランダムで足し合わせると何ができるでしょうか。

こういうものができました。なかなかこれは良いものです。


しかし、そのランダムに組み合わせたものから何が良いのかというのを発見するのは非常に難しいです。
その生成物に「芸術的価値」があるとは何なのか、つまりはその生成物の何が芸術的価値を表現しているのか、それを判断するにはどうしたらいいのか。そこで「芸術的価値とは何なのか」を「芸術的価値があるとされてきたもの、つまり今までの文化」(実際には1500年から1899年の本の画像)からデータマイニングしてみます。

その後Mechanical Curatorを使用することで画像そのものから様々な分類を行うことに成功しました。


そこから話題は『どうやってカテゴライズするモデルを作っていくのか』という方向へ。

これは手で画像を振り分けている様子。

その後これらを〈A〉を認識できるようになりました。

例えば上記のようなアルファベットでないものでさえ、アルファベットとして認識できるようになります。
似ている顔の人を自動でフィルタリングする ( ? )
ここでまた話が『機械学習とは何か?』という問いに話が戻ります。『7百万の文化的なモノを用いて何ができるか?』という問いを投げかけた後にデモが始まりました。それら大量の画像をカテゴライズしたものがこちらです。

この中から〈Horse〉を選択すると馬の画像が表示されました。中には〈Calm ( 静寂 ) 〉などの動物や物体ではないものカテゴリもあり、〈Bling Bling〉には上記のような宝石の類が表示されました。

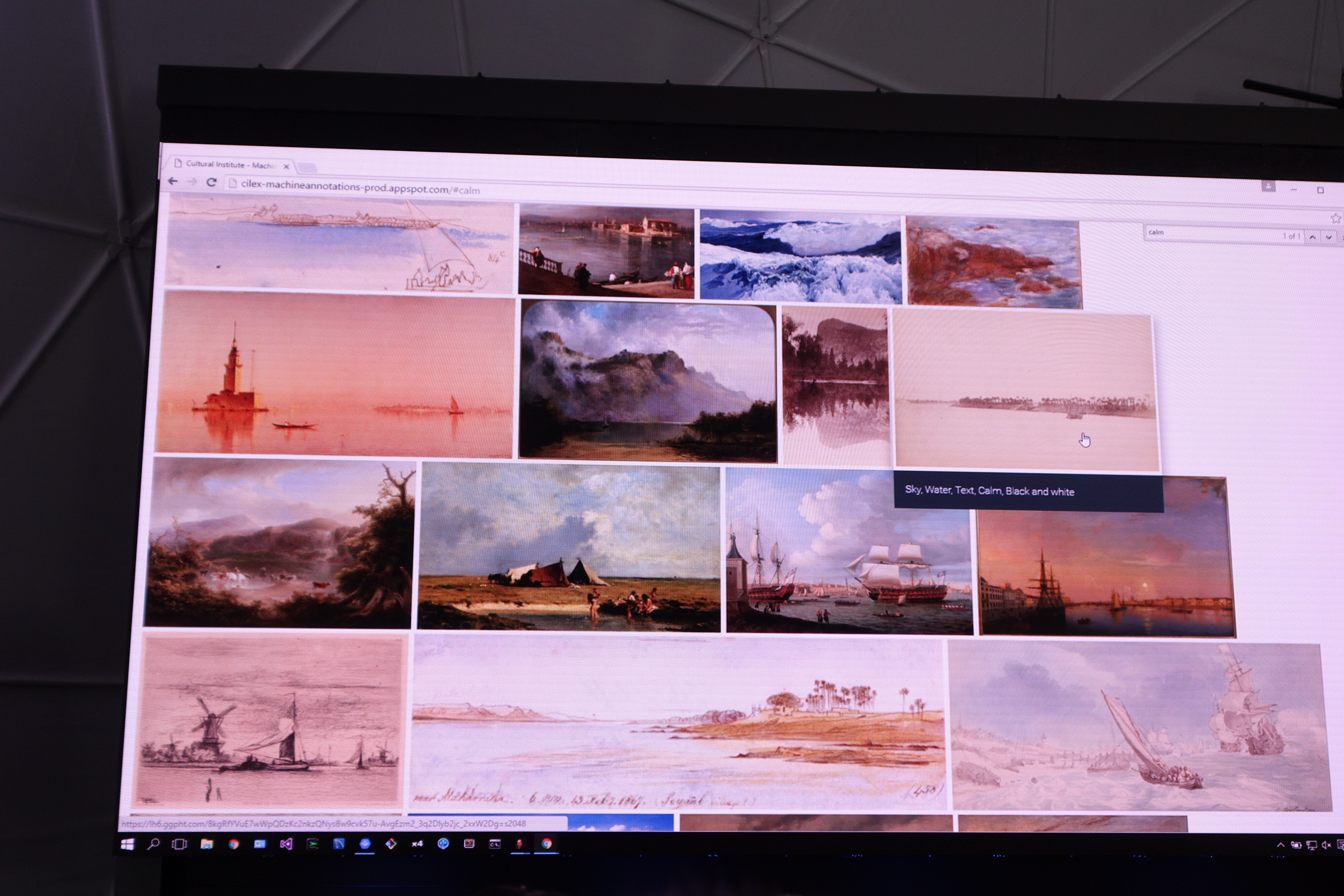
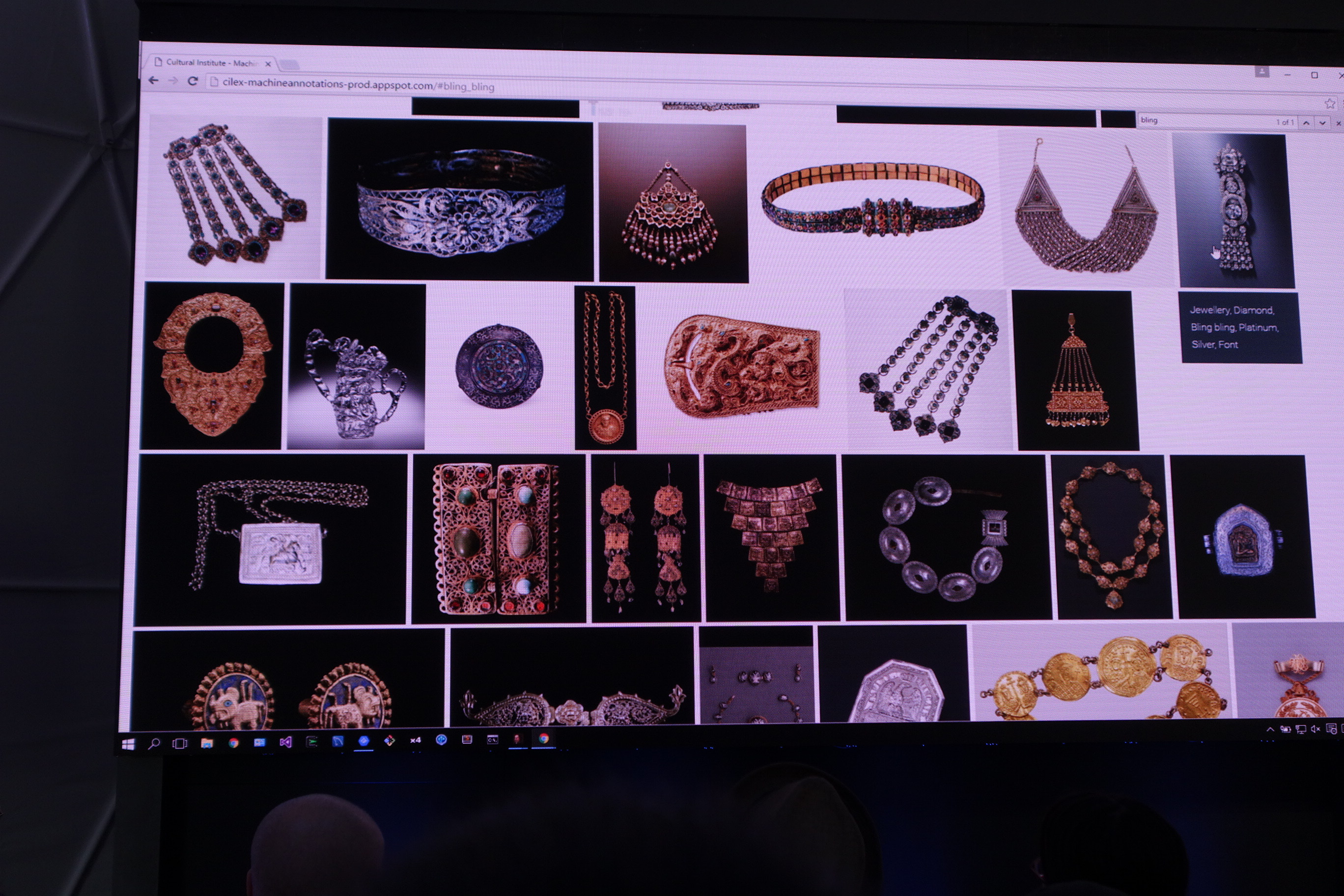
それらすべての画像を2次元でマッピングしたものがこちら。壮観ですね。

これらは以下のような仕組みで二次元ベクトルで表しています。
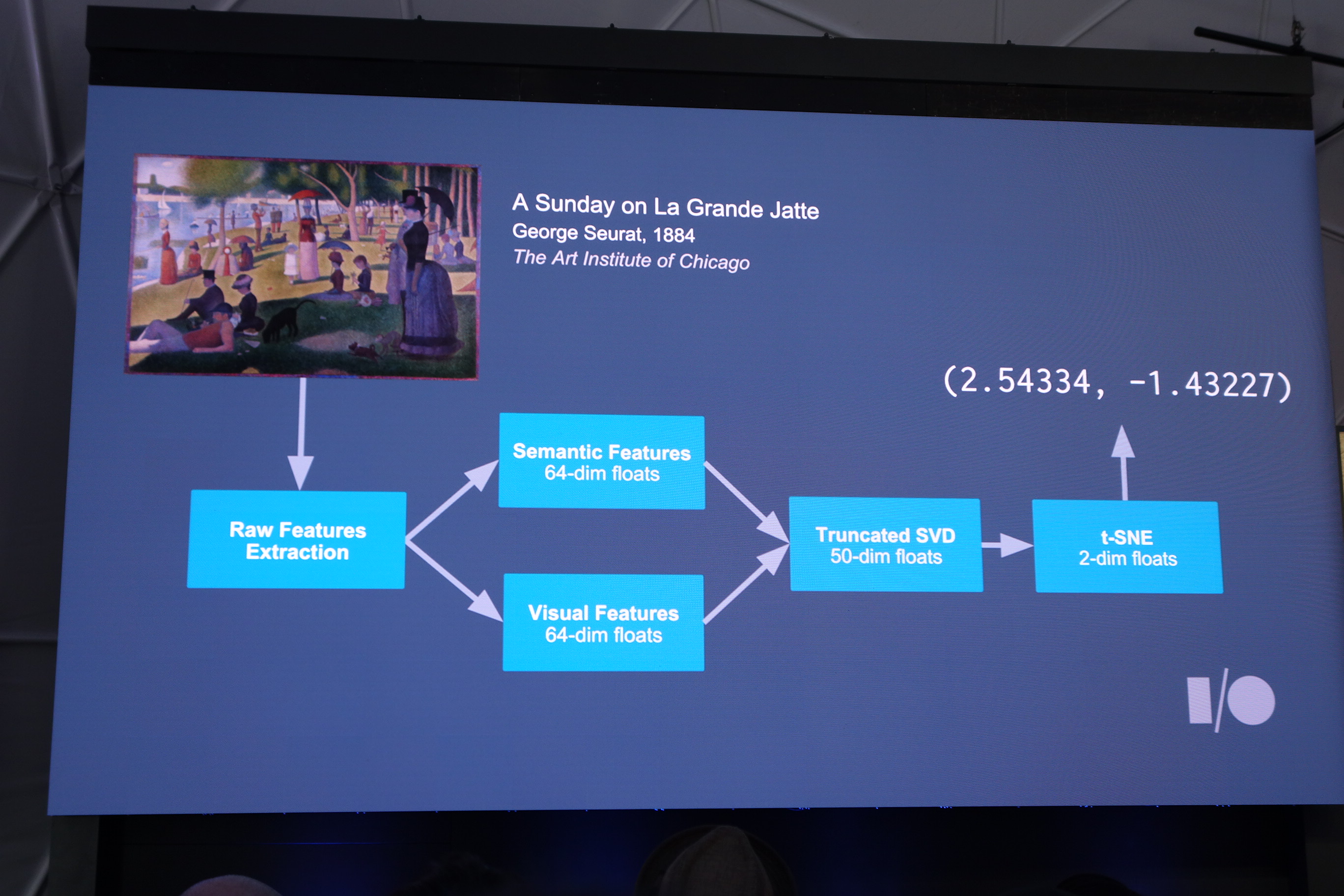
似たような仕組みを用いて、自分の顔をすでに様々な顔画像が登録されているDBの中から一番近いものを示すというデモが披露されました。なかなか興味深い結果が出ていますね。


まとめ
人間の言語化できていないようなものをプログラミングで表現するというのは難しく、そのために必死でモデリングしてプログラムに落とし込んでいます。今回の場合に当てはめると、芸術的価値とは「○○であること」「XXであること」などといったいくつかの条件を人が見つけだすことになります。一流の評論家同士でも答えの違うような真理をプログラマーが見つけることは難しく、現実的ではありません。
しかし、今回のように機械学習が入ることで曖昧で言語化不可能な芸術的価値を言語化しないままに人間の感覚を再現しうる可能性があるんだ、ということが伝わって来ました。本イベントのGoogle IOとは関係ないですが、私が最近聞いたものに『単語間の距離(うどんとそばは近い、うどんとマンションは遠いといったようなもの)を機械学習で得て応用する』という事例がありました。この分野ではこういった興味深い事例が今後も数多く出てきそうだなと思えたセッションでした。