目次
昨年のre:Inventで発表されたRDSの新エンジンAuroraのプレビューが通ってやっと試せる状態になりました!
(AuroraのセッションでURLが公開されて速攻でプレビューの申し込みをしたけど、4ヶ月待ちましたw)
RDS for Auroraを起動する
お知らせのメールに書かれてる専用のリンクを開くとAuroraのダッシュボードが表示されます。
さっそく、Auroraのインスタンスを立ちあげましょう。
もちろんAuroraエンジンを選択します。
プレビューではdb.r3.large、db.r3.xlargeだけが選べました。
MySQLの場合はココでストレージサイズを指定しましたが、Auroraではそれが無い。
ネットワーク周りと、DBのオプションを指定していきます。
これでついにAuroraを試せます!!
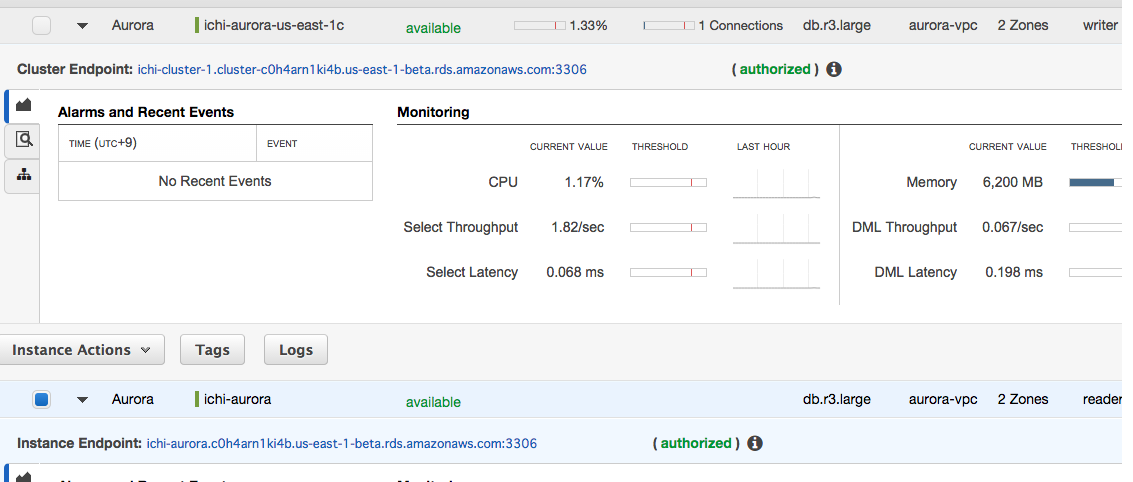
Multi-AZで立ちあげたから、2つのインスタンス(writer、reader)が一覧に表示されてる。
(試しに、Multi-AZをNoで立ち上げたらwriterの方だけが表示されてました)

クラスタのイベントや簡易モニターが見れます。
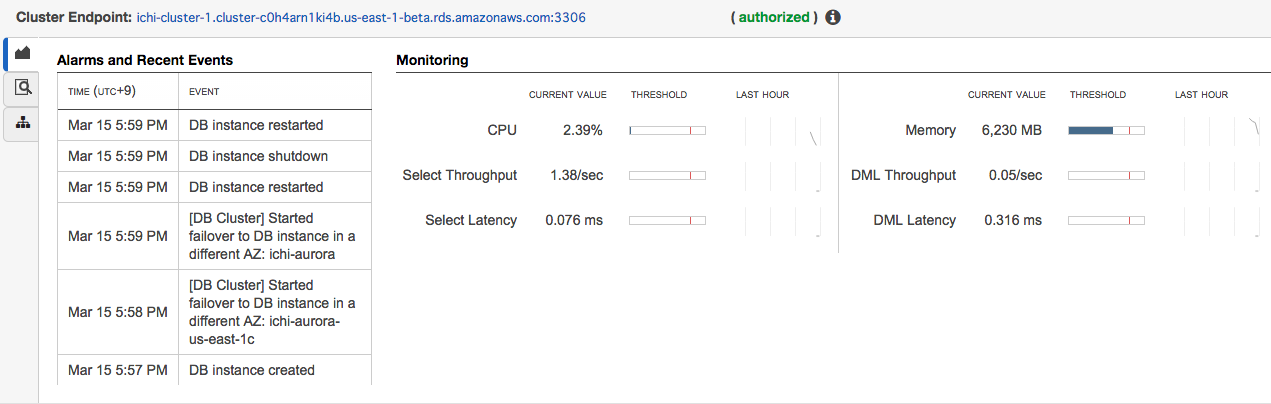
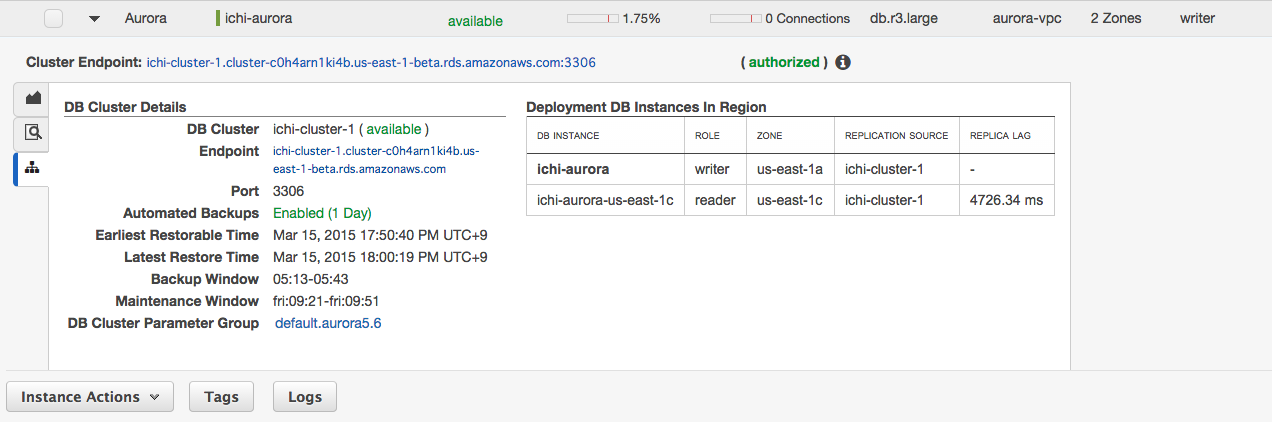
こちらはクラスタの設定画確認できる。
Logsボタンをクリックすると、ログの一覧が表示されます。
Logsの画面でDetailのタブをクリックすると、インスタンスの詳細が確認できます。
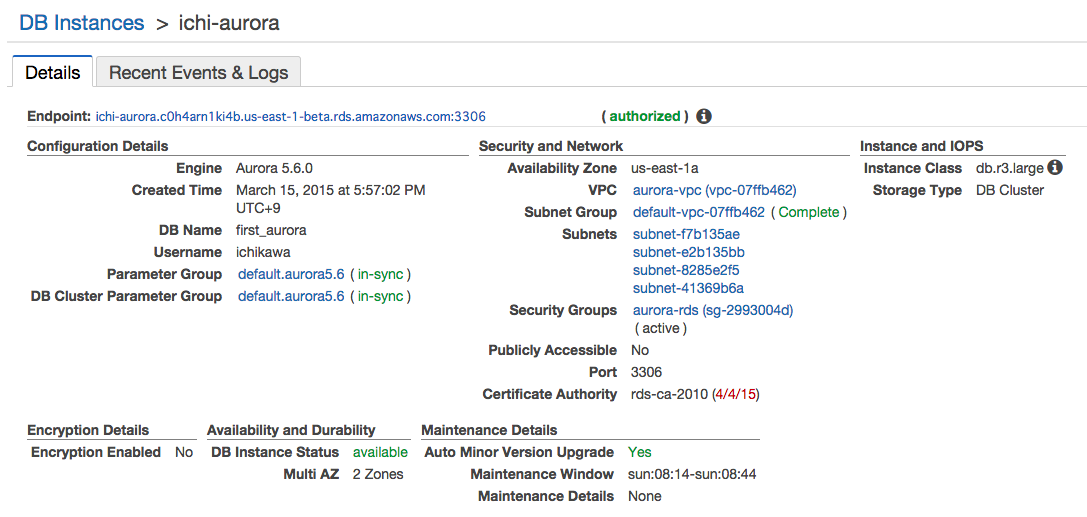
Show Monitoringをクリックして、Show Full Monitoring Viewを選択すると、Auroraの紹介でよく見かける各種の数値が確認できます。
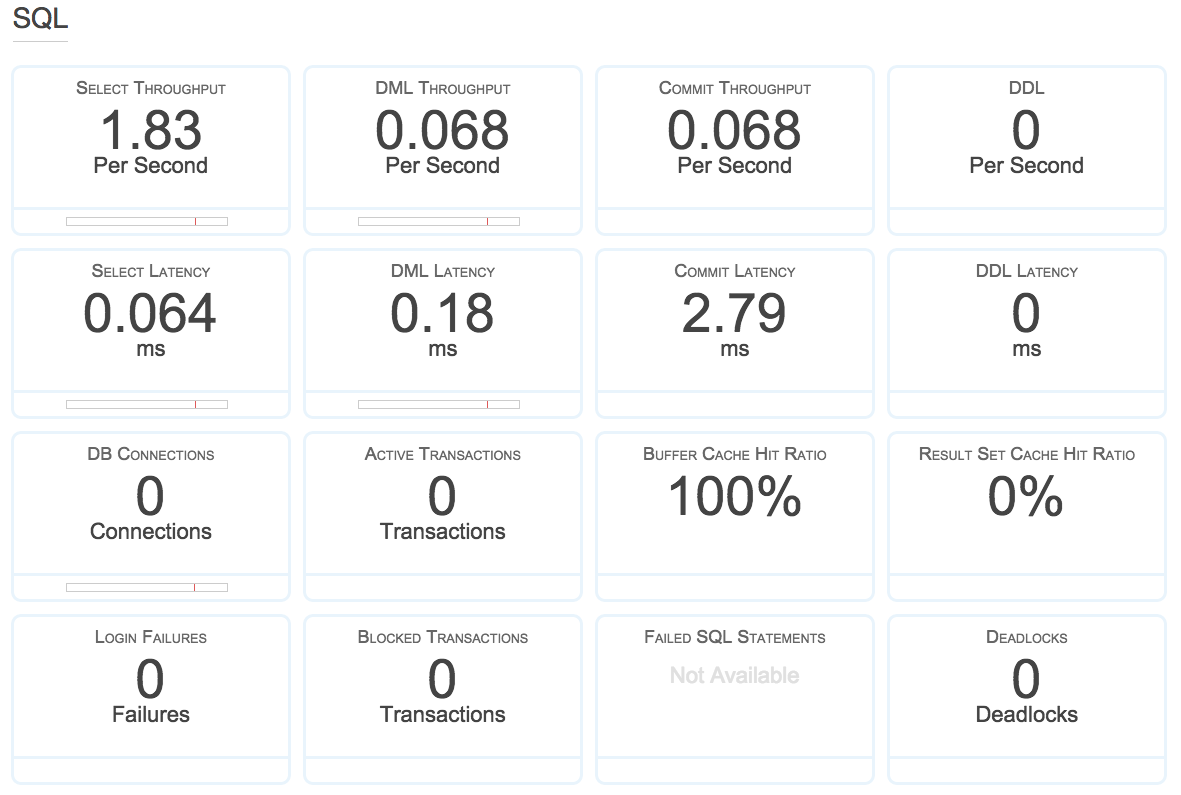
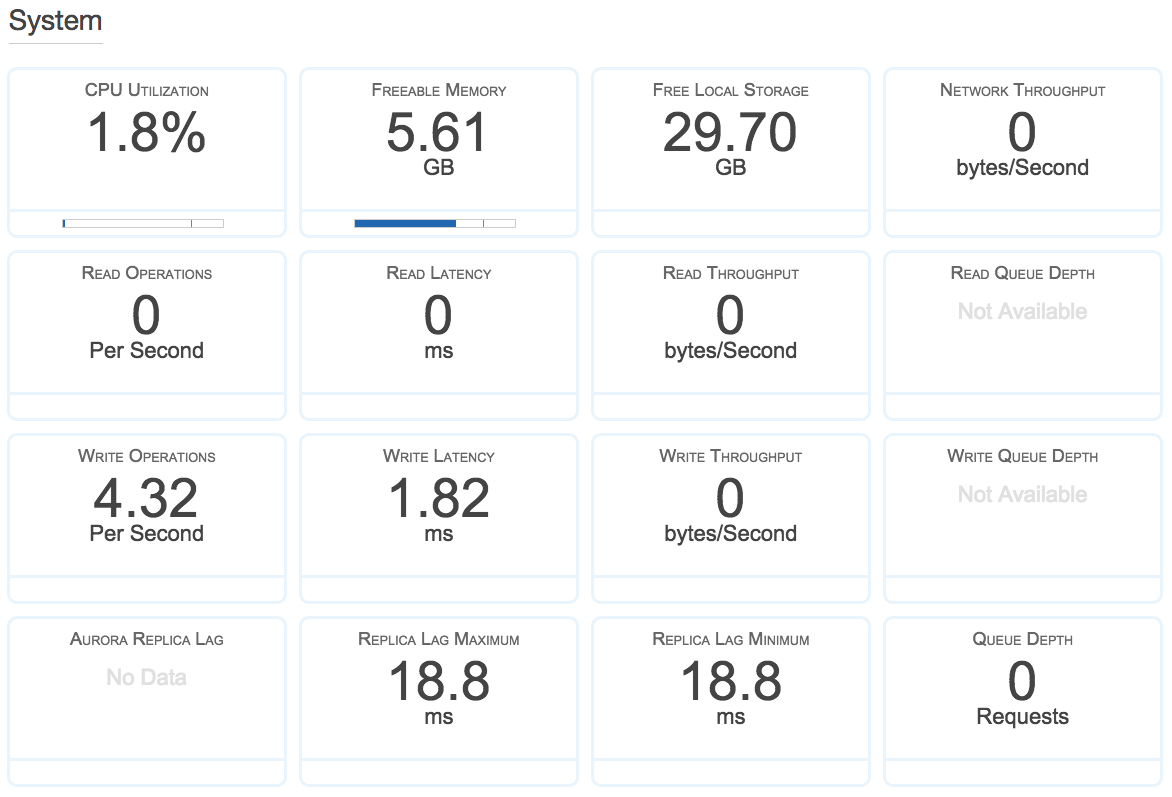
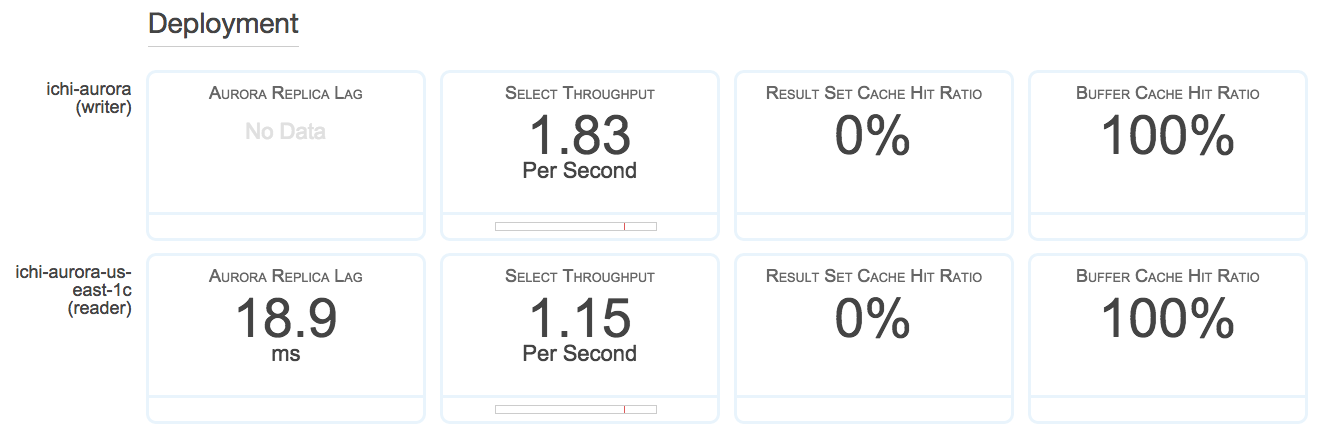
実際にSQLを実行してみる
管理画面周りはひと通り確認できたので、実際にいじってみたいと思います。
[ec2-user@ip-10-0-0-28 ~]$ mysql -uichikawa -p -h ichi-cluster-1.cluster-c0h4arn1ki4b.us-east-1-beta.rds.amazonaws.com
Enter password:
Welcome to the MySQL monitor. Commands end with ; or g.
Your MySQL connection id is 137
Server version: 5.6.10 MySQL Community Server (GPL)
Copyright (c) 2000, 2015, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or 'h' for help. Type 'c' to clear the current input statement.
mysql>MySQLって表示されるのは、MySQLのクライアントを使っているからなのか、なぜなのか。。
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| first_aurora |
| mysql |
| performance_schema |
+--------------------+
4 rows in set (0.00 sec)
mysql> SHOW ENGINES;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
9 rows in set (0.00 sec)RDSでMySQLを使った時と同じ感じ。
とりあえず、データを突っ込んでみることに。
サンプルデータは郵便番号のデータを使いました
CREATE TABLE zipcode_list (
zipcode varchar(10),
prefecture_kana varchar(255),
city_kana varchar(255),
street_kana varchar(255),
prefecture varchar(255),
city varchar(255),
street varchar(255)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;データを入れるテーブルを作ります。
ダウンロードしたデータはshift_jisなので、utf8に変換してロードします
nkf -w KEN_ALL_ROME.CSV > zipcode_list.csv
mysqlimport --local --compress --user=ichikawa --password --host=ichi-cluster-1.cluster-c0h4arn1ki4b.us-east-1-beta.rds.amazonaws.com --fields-terminated-by=',' --fields-enclosed-by='"' --lines-terminated-by='rn' -d first_aurora ./zipcode_list.csv
Enter password:
first_aurora.zipcode_list: Records: 123699 Deleted: 0 Skipped: 0 Warnings: 0mysql> select * from zipcode_list where zipcode in ('1006640','4600008');
+---------+-----------------+-----------------------+-----------------------------------------------------+------------+--------------------+-------------------------------------+
| zipcode | prefecture_kana | city_kana | street_kana | prefecture | city | street |
+---------+-----------------+-----------------------+-----------------------------------------------------+------------+--------------------+-------------------------------------+
| 1006640 | 東京都 | 千代田区 | 丸の内 グラントウキョウ サウスタ | TOKYO TO | CHIYODA KU | MARUNOCHI GURANTOKYO SAUSUTAWA(40-K |
| 4600008 | 愛知県 | 名古屋市 中区 | 栄 | AICHI KEN | NAGOYA SHI NAKA KU | SAKAE |
+---------+-----------------+-----------------------+-----------------------------------------------------+------------+--------------------+-------------------------------------+
2 rows in set (0.09 sec)ここまで、特に困ること無くデータの取り込みと検索が出来ました。
試しにreaderとなっている方のインスタンスに繋いでinsertを試してみました。
mysql> insert into zipcode_list values(9999999, "だみー", "まち", "ちょうめ", "dummy", "machi", "cyome");
ERROR 1290 (HY000): The MySQL server is running with the --read-only option so it cannot execute this statementま〜、当然ですが、書き込みできないとのエラーが出ました。
Failoverを試す
インスタンスアクションの所に、気になるメニューが有りました。
Failoverって、何してくれるんでしょう?そんなわけで、Failoverしてみました。
コンソールでwriterの方に繋いでましたが、Failoverをきっかけにコネクションが切れました。
先ほどまでwriterだったインスタンスもRoleがreaderに変わってます。

数分してからマネージメントコンソールを見ると、エンドポイントの名前が入れ替わってます。
入れ替わったのはいいですが、さっきreaderの方に設定されていたホスト名と違うホスト名になってしまいました。。
もし、読み込みだけをreaderのホストをみるようにしていたら、ホスト名が変わるのはつらいですね。
とは言え、Multi-AZを有効にしていただけで、Read Replicaを作っていたわけではないので、そもそもreaderの方を読み取り用のエンドポイントとして使うのが間違えているのだろうか。
正式リリース版になれば、正しい使い方も分かるでしょう。
気になってたコマンドでfailoverを試せるのもやってみました。
mysql> ALTER SYSTEM CRASH INSTANCE;
ERROR 2013 (HY000): Lost connection to MySQL server during queryちゃんとfailoverしました。
更に、マネージメントコンソールからReplicaインスタンスだけを残して他を削除していった所、Replicaインスタンス昇格して1台だけで普通に使える状態となっていました。

感想
普通に使うならなんに違和感もなく使えました。
まだプレビュー版なのでfailover周りが今後どうなるのかが気になるところです。
けど、データ容量を気にしなくていいとか、MySQLよりも速いといった部分には期待をせざるにいられないので、正式版が出てくるのが楽しみですね。