目次
はじめに
先日、Kaggle主催のMechanisms of Action (MoA) Prediction(※)に参加しました。チームメンバーは、エムスリー株式会社 堀江氏、そして 当社所属のデータサイエンティストである、羽鳥、阿内、佐々木、小畑の5名です。
本コンペティションは医薬品の作用機序予測がテーマであり、世界中から4,373チームのデータサイエンティストが参加しました。
我々のチームは全チーム中4位の成績を収め、$5,000の賞金と、Kaggle Masterの称号を獲得しました。
※ Kaggleは、世界最大のデータサイエンスコンペティションのプラットフォームで、世界中から15万人以上のデータサイエンティストが技術を競い合います。Kaggle Masterの称号を獲得しているユーザは約1,500人、日本では150人程度です(2020年12月時点)。
コンペティション概要
近年創薬の領域では、病気に関連するタンパク質を特定して、そのタンパク質を調整できるような分子を開発しようとしています。
本コンペでは、作用機序 (MoA: Mechanism of Action) と呼ばれる、薬剤がタンパク質に与える作用を予測することがテーマとなっています。
参加者は、5,000種類以上の薬剤それぞれに対するヒト細胞中の反応のデータ (遺伝子発現、細胞生存能力) などをもとに、薬剤のMoAを予測することを求められました。
薬剤一種類あたりのMoAは複数パターンが存在し得るので、このタスクはマルチラベル分類問題です。
その他の情報は以下の通りです。
- 開催期間
- 2020/9/4 〜 2020/11/30
- 全参加チーム数
- 4,373
- 外部データ
- 無料かつ公開されているデータについては利用可能 (学習済みモデルを含む)
- 目的変数
- 薬剤が206種類のタンパク質それぞれに対してMoAを持つか否か (1あるいは0)
- 特徴量
- 遺伝子発現、細胞生存能力、処置期間、投与量、介入群であるかコントロール群であるか
- 評価指標
- タンパク質ごとの予測結果に関するLogLossの平均
ソリューション概要
我々のソリューションの概要について説明します。
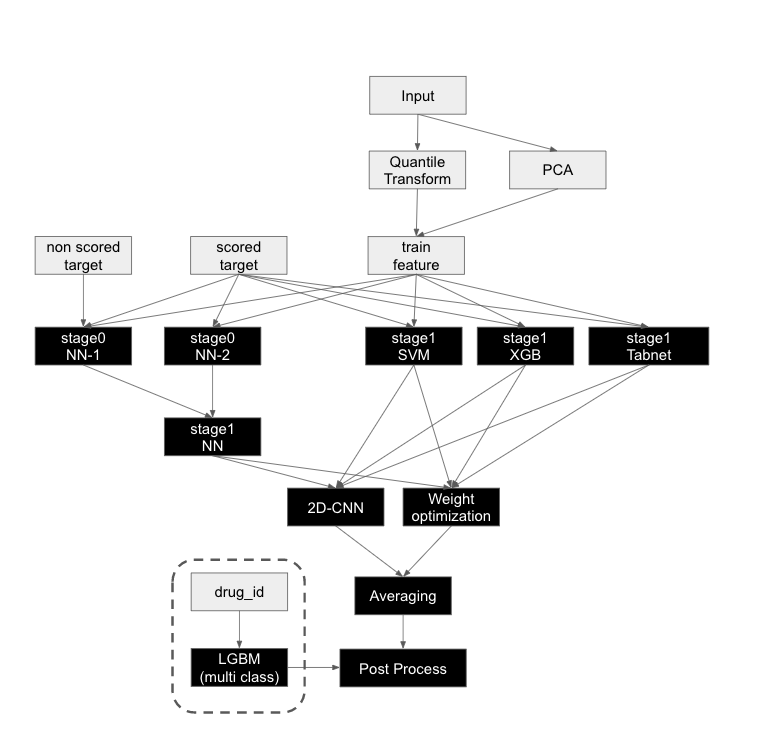
図1. ソリューション概要
基本戦略は、多様性を持った複数のモデルによるアンサンブルです。
kaggle上にも4th place solutionとして解法を公開していますので、合わせてご覧ください。
Cross Validation戦略
Kaggleのコンペティションでは、交差検証(Cross Validation: 以下CV)を適切に行うことで、未公開のprivate test setに対する評価が高い予測モデルを選択することが可能になります。
わかりやすい例だと、時系列予測コンペでは学習用データの中で時系列に複数パターンでデータ分割して交差検証を行うことで、信頼できる評価指標を計算することが可能になります。
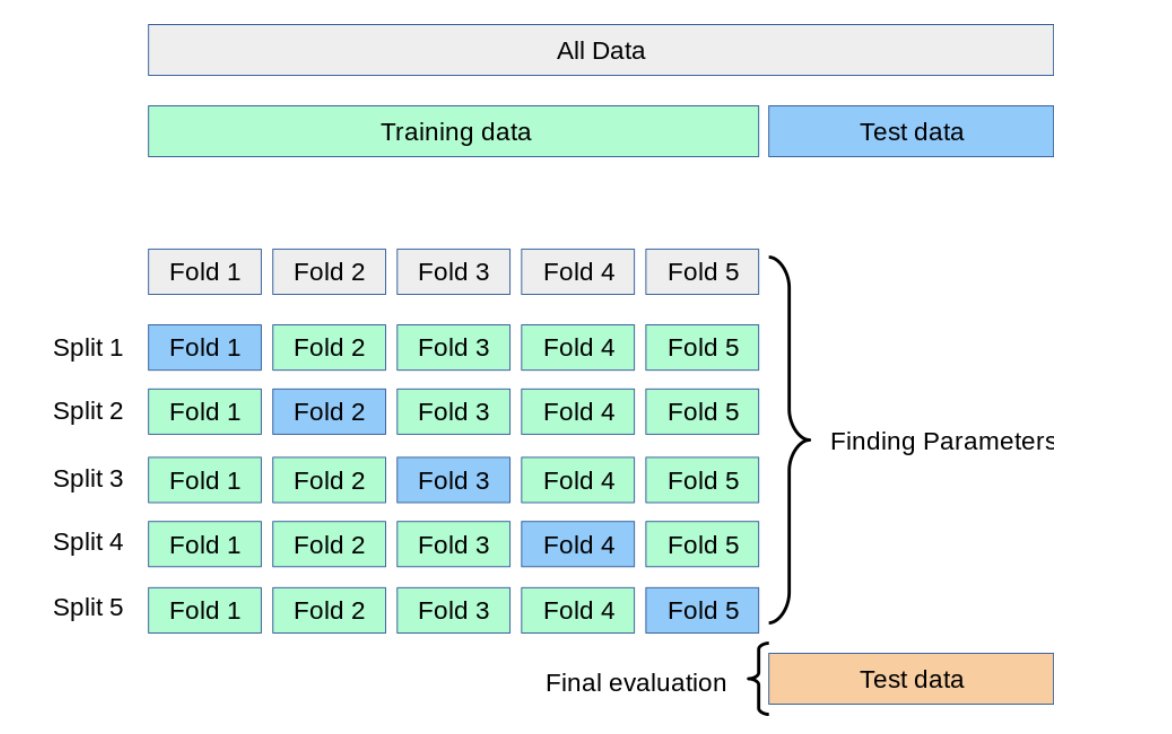
図2. Cross Validationについて(scikit-learn 公式より引用)
今回のコンペティションでは、交差検証の方法として、KaggleのDiscussionで公開されていたChris Deotteさんの手法を使用しています。
この手法では、学習データに存在しない薬剤がテストデータに存在している状況を再現するようにデータを分割しています。
コンペ中盤で薬剤のid(drug_id)が公開されたのですが、最高で1866件学習データに入っている薬剤もあれば、6件しか存在していない薬剤もあります。そのため、学習データに登場する回数が少ない薬剤については全て同じfoldに含めるようにMultiLabelStratifiedKFoldを実装しています。
このCV戦略を拝借することで、最終スコアが最も高いsubmissionを選択することができました。
Feature Engineering
通常のコンペティションでは、変数の意味合いやデータ構造から特徴量加工アイディアを出していくことも多いのですが、今回は各変数が匿名化され、既にスケーリングされていたため、実験ベースで特徴量を作っていきました。
今回実施した特徴量加工のうち有効だったものは、
- PCA特徴
- 差分特徴(変数同士の差分)
の2つで、各変数の統計量(min, max, avg, std, …)などはCV改善に繋がりませんでした。
以下はTabNetの特徴量重要度を可視化したもので、PCA特徴、差分特徴の重要度が高いことが見てとれます。
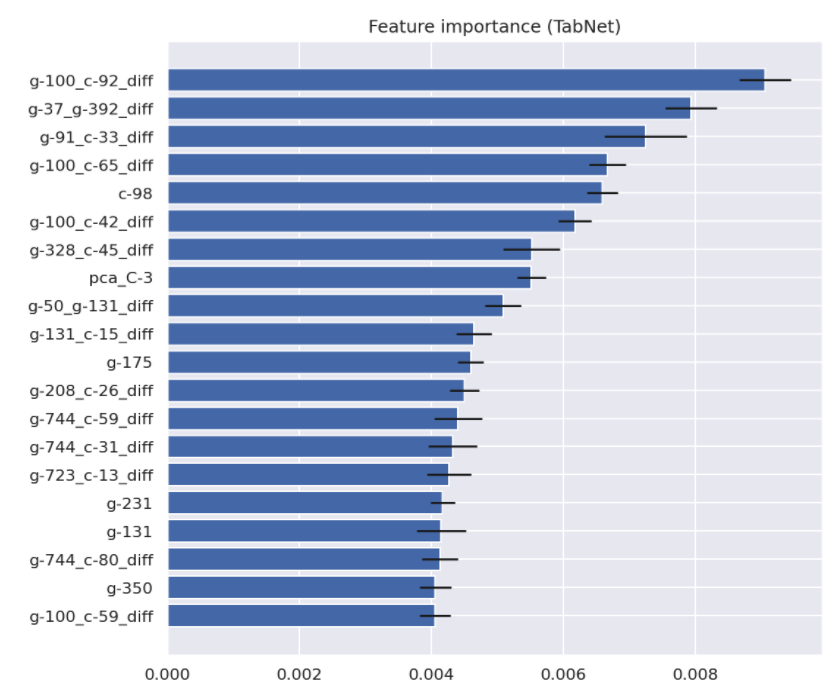
図3. 特徴量重要度
PCA特徴については、提供された全変数でPCA特徴を算出してもCVは改善せず、c系変数(c-1, …, c-100)をPCAを用いて60次元に圧縮したものを変数として利用することでCVが改善しました。
また、差分特徴に関しては、全組み合わせが379,756通りも存在したため、分散が一定以上の変数に関してのみ利用することで現実的に計算可能な特徴量計算を実施し、CV改善に繋がりました。
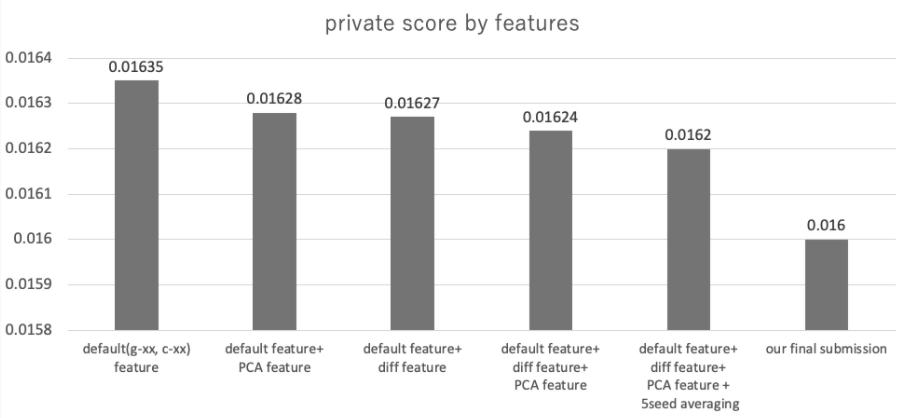
図4. スコアの推移
以上の特徴量を導入することでCVは改善したものの、今回は変数が匿名化されていることもあり、そこまで手の込んだ特徴量加工を実施することはできませんでした。
テーブルデータのコンペティションでは、鍵となる特徴量を見つけることが勝利につながることも多いのですが、結果的に今回は、モデリングやアンサンブルが勝利に最も大切な要素となるコンペティションだったと考えています。
アンサンブル
Neural Network Stacking
- なぜやったか
- 今回のタスクでは、予測対象のtarget(206変数)とは別に、予測対象ではないnonscored target(402変数)が与えられていました。このnonscored targetについても、target同様にtrainデータにしか与えられていないため、予測に用いることは困難です。しかし、kaggleではこのような一見活用が難しいデータが勝利へのキーとなることが多いため、stackingというテクニックで活用することにしました。
- 何をやったか
- targetを予測するNN(Neural Network)と、target + nonscored targetを予測するNNの2つを用意。
- 2つのNNを用いてout of foldから出力された予測値をconcatしたデータを入力とするNNで、再びtargetを予測します。
- 結果
-
- stage0-NN1 : 0.016779
- stage1-NN :0.016736
- stackingにより、targetを予測するNN単体よりも強力なモデルを構築できました。
-
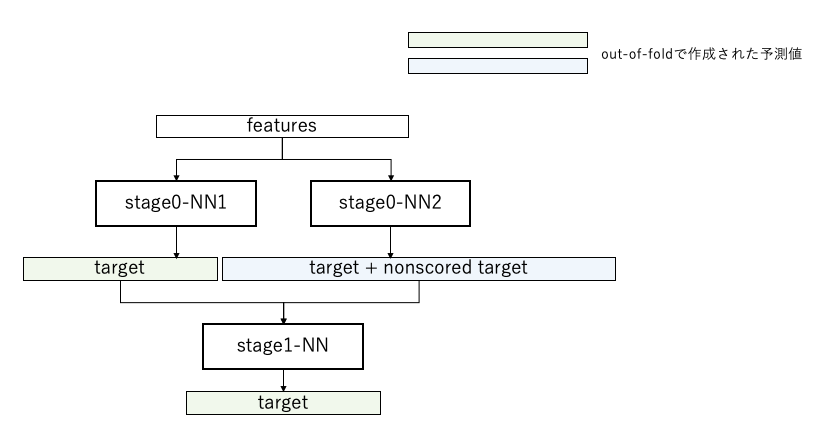
図5. Neural Network Stackingのイメージ図
Blending Weight Optimization
- なぜやったか
- stackingするモデルのチューニングが不要で手軽であり、シンプルな手法のため過学習しにくいと判断しました。また、同じメンバーで参加していたOSIC Pulmonary Fibrosis Progressionでもこの手法が有効でした。
- 何をやったか
- out of foldで作成したtrain dataに対する予測値を用いて、モデルごとにweightを決定しました。具体的にはsig_id(全レコードでユニークなID)ごとのkfoldで、Scipy minimize function (‘Nelder-Mead’)でlossが最小になるweightを探索しています。このとき、過学習を避けるためにfold数と切り方を変えながら何度か探索して、平均を取った上で最終的なweightを決定しています。この実装はTReNDS 2nd place solutionを参考にしました。
- 結果
- 以下の表1の通り、cvとweightは完全には相関しないことがわかりました。例えばcv scoreが一番低かったSVMは、blendの重みとしてはかなり重要です。一方でcv scoreはSVMよりも高かったXGboostは重みとしてはかなり小さくなっています。
表1. CV scoreとblending weight
| model | cv score | blend weight |
|---|---|---|
| stage1-Tabnet | 0.016846 | 0.228 |
| stage1-SVM | 0.017554 | 0.160 |
| stage1-NN | 0.016736 | 0.598 |
| stage1-xgb | 0.017366 | 0.0123 |
2D-CNN Stacking
- なぜやったか
- blending weight optimizationではターゲット全体に対して全て同じ重みを適用していますが、本来であれば最適な重みはターゲット、モデルごとに異なるはずです。本手法であればモデル間、ターゲット間の関係性を表現できると考えました。
- このようなことをしようとする際に、一番恐ろしいのは過学習です。一般的にMulti Layer Perceptronよりはパラメータ数が少なく、過学習しにくいCNNと組み合わせることで、適切にモデル間、target間の関係性が捉えられると思いました。また、blendingと全く異なる性質のモデルなので、両者をアンサンブルすればさらに伸びそうだと思いました。この辺りのアイデアはiMet 7th place solutionを参考にしています。
- なにをやったか
- model x targetのベクトルを1channelの画像のように扱い、[3×1]のfilterを適用するようなCNNモデルを実装しました。モデル間の関係性をfilterが表現してくれることを狙っています。
- 結果
- 2D-CNN stacking : 0.01670
- blending weight optimization : 0.016518
- 30%と70%でblend : 0.01647
このように、weight optimizationの限界からさらにcvを向上させることができました。
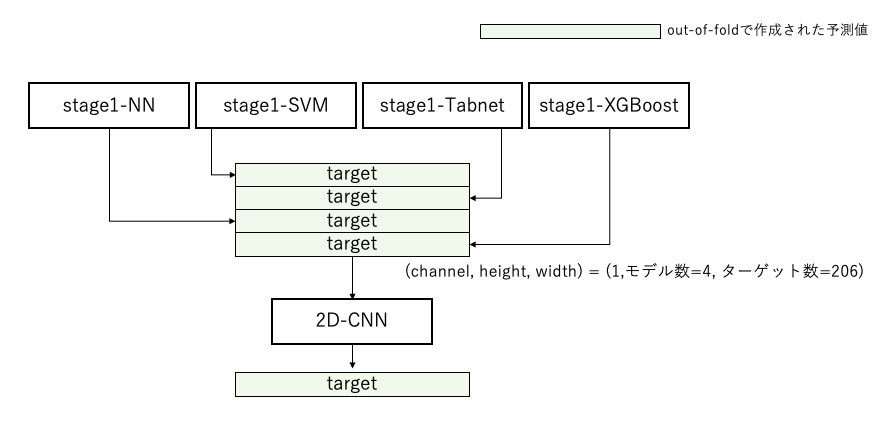
図6. 2D-CNN stackingのイメージ図
終わりに
私たちが所属するリクルート データ推進室では、Kaggleで得た知識を業務に活かして今回のようなテーブルデータを扱ったり、リクルートのプロダクトのデータを使用したレコメンドや検索のアルゴリズムを開発するなど、様々な分野で予測・分析を行っています。
機械学習コンペが大好きな皆さん、ぜひ一緒に働きましょう!
そして次回は優勝したいですね。
・新卒採用ページ
・中途採用ページ