目次

はじめに
このエントリは全5回を予定する19卒新人ブログリレーの第2回目です。
初めまして、リクルートテクノロジーズ新卒2年目の譚 匡桓(タン キョウカン)です。
現在は主に、タウンワークのAndroidアプリの開発を担当しています。
この度、趣味でオンデバイス機械学習アプリを作った事例について紹介します。
背景
大学で自然言語処理の研修をした時、AWSで高いスペックのGPUのサーバーを借りて、24時間モデルをトレーニングしました。最近はそういったサーバーがなくても機械学習のタスクをさばける、オンデバイス機械学習フレームワーク「CoreML」というものがあるという話を聞き、早速それで画像処理アプリを作ってみました。
実装した機能について
画像処理という言葉はよく耳にしますが、今回実装したのは物体検出(Object Detection)機能です。簡単に言いますと、ある画像が何を表しているのかをプログラムで検知することです。イメージとしては、下の図のように、「猫じゃなく犬です」という判断をプログラムにしてもらいます。

実際の画像処理アルゴリズムも展開したいところなのですが、数式ばかりになるので今回は割愛します。
オンデバイス機械学習
一般的に、従来の機械学習アプリケーション(例:機械翻訳、画像処理)を動作させるときは、クラウド技術を用いて高いスペックのGPUを持つサーバー群とデータサーバーを用意する必要があるとされます。こうした環境は優秀な性能を誇る一方、コスト観点でいうと誰でも手を出せるものではありません。もしこうしたクラウド技術なしで、スマートフォンあるいはタブレットだけで機械学習タスクを処理することができれば、少なくとも下記のようなメリットを享受できます。
・データへのアクセスが容易になる
・サーバーとの通信時間がなくなり、リアルタイムのパフォーマンスが向上する
ここ数年、携帯端末の計算能力が凄まじいスピードで向上しています。そのおかげで、オンデバイス機械学習が本当の意味で実現可能になりました。GoogleはML Kitというモバイル機械学習SDKをパブリッシュし、AppleもiOS/macOS専用の機械学習のフレームワークCore MLと、機械学習モデルを作成するフレームワークCreate MLを公開しました。
Core ML
Core MLの意図として、機械学習知識がないアプリケーションエンジニアでも機械学習アプリを作れるように設計されています。関連機能の構成は、以下のようになっています。

(引用元:https://developer.apple.com/jp/documentation/coreml/)
AccelerateとBNNSが高速かつ低消費電力な計算を実現するライブラリで、Metal Performance Shadersが高パフォーマンスの画像処理ライブラリです。これらはCoreMLの基盤となっています。現在CoreMLがサポートしているのは、画像を分析するVision、テキストを処理するNatural Language、音声情報をテキストに変換するSpeech、何の音かを特定するSoundAnalysisです。加えて、最近公開されたTuri Create機械学習ライブラリも、より豊富なファンクションを提供しています。
今回は主に、Visionを使いました。
実装方法
まずは下記サイトより、学習済みのモデルを用意しましょう。
https://developer.apple.com/jp/machine-learning/models/
ここにOCR(Optical Character Recognition、光学文字認識)、オブジェクト検出、深度推定、画像セグメンテーションなど、いろいろなモデルが用意されています。
今回自分が使ったのはYOLOv3という物体検出モデルです。
これを使って、ある画像に対して下記の処理を行います。
①人の有無、いる場合表情の取得
②テキストの有無
③オブジェクトの検知
①と②は、appleのVisionフレームワークで解決できます。③は今回のYOLOv3に任せます。
そしてCoreMLのタスクの実行にはRequestとHandleが要りますので、まずはそれぞれのRequestとHandleを以下のように作ります。
①顔検出および表情判断:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
//顔検出Request lazy var faceDetectionRequest = VNDetectFaceRectanglesRequest(completionHandler: self.handleDetectedFaces) //顔検出Handle fileprivate func handleDetectedFaces(request: VNRequest?, error: Error?) { if let nsError = error as NSError? { return } DispatchQueue.main.async { guard let results = request?.results as? [VNFaceObservation] else { return } //後続処理 } } |
②テキスト検出:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
//テキスト検出Request lazy var textDetectionRequest: VNDetectTextRectanglesRequest = { let textDetectRequest = VNDetectTextRectanglesRequest(completionHandler: self.handleDetectedText) // 文字ごとのRectを出力フラグ textDetectRequest.reportCharacterBoxes = false return textDetectRequest }() //テキスト検出Handle fileprivate func handleDetectedText(request: VNRequest?, error: Error?) { DispatchQueue.main.async { guard let results = request?.results as? [VNTextObservation] else { return } //後続処理 } } |
③オブジェクト検出:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
//オブジェクト検出 lazy var classificationRequest: VNCoreMLRequest = { do { let model = try VNCoreMLModel(for: YOLOv3().model) let request = VNCoreMLRequest(model: model, completionHandler: { [weak self] request, error in self?.processClassifications(for: request, error: error) }) request.imageCropAndScaleOption = .centerCrop return request } catch { fatalError("Failed to load Vision ML model: \(error)") } }() // 実装 func processClassifications(for request: VNRequest, error: Error?) { DispatchQueue.main.async { guard let results = request.results else { return } for observation in results where observation is VNRecognizedObjectObservation { guard let objectObservation = observation as? VNRecognizedObjectObservation else { continue } // 後続処理 } } |
コードは数行しかありませんが、ここでは意識しなければいけないことが2つあります。
1つは、モデルによって入力ファイルの型が異なっていることです。
画像の場合、CVPixelBufferかUIImageかそれともCIImageかは、事前に確認した方がよいでしょう。用意したモデルをクリックし、「Prediction」を見ると、入力するファイルの型を確認することができます。
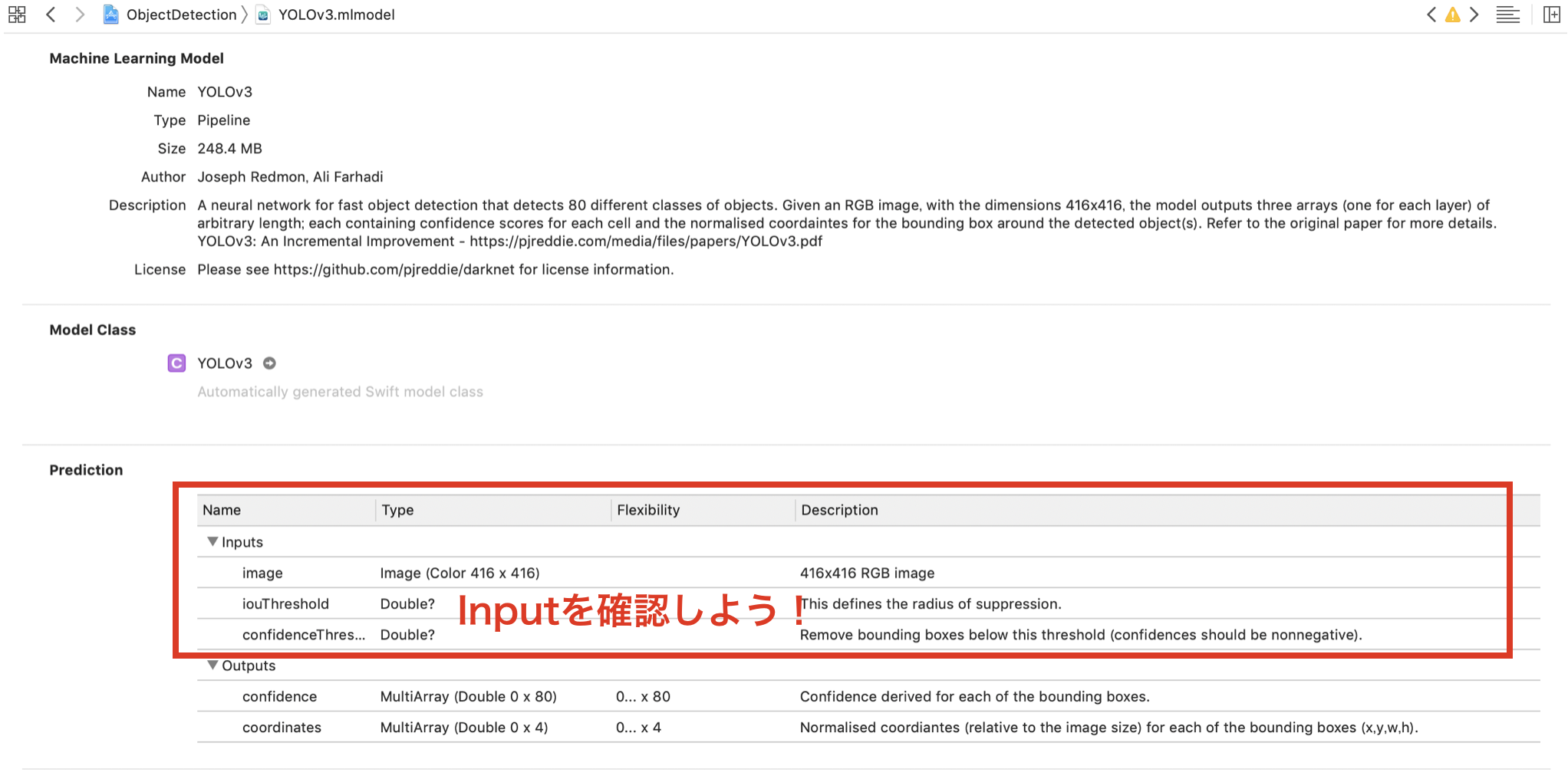
2つ目は、識別などは時間がかかるので、非同期処理をするべきということです。(例:DispatchQueue.main.async)
最後に
これにより、与えられた画像の「顔検出」「文字検出」「オブジェクト検出」ができるようになります。こういった機能を使えば、面白いアプリが作れそうですね!
皆さんも、Core MLで簡単なオンデバイス機械学習アプリを作ってみませんか?