目次
この記事は Recruit Engineers Advent Calendar 2019 の 18日目の記事です。
リクルートテクノロジーズでインフラエンジニアをやっている宮地(@int_tt)です。
今回は今年起きた障害への対応と、OSSへのコントリビューションまでのお話をしたいと思います。
はじめに
僕の担当しているプロダクトではコンテナ環境で運用しており、CI/CDにはConcourseCIを利用しています。
ある日、サービスのデプロイを行おうとデプロイボタンを押したところ、CI上で動くDockerで以下のようなエラーが出てきました。
|
1 2 3 4 |
Pulling xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/xxxxx:latest (attempt 3 of 3)... Error response from daemon: Get https://xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/v2/: dial tcp: lookup xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com on 172.18.0.3:53: read udp 10.254.0.122:48372->172.18.0.3:53: i/o timeout |
デプロイまでのフローは ボタンクリックすると、 git clone -> docker build -> docker push -> k8sのmanifest書き換え,デプロイ というフローで行われており、 docker build を行う中で、cacheとしてimageをpullするところで落ちていました。
おかしい、サービスはリリースから今まで一度もこんなエラーが出たことがなかったし、直近で構成変更も行っていません。
エラーメッセージからも一時的に通信が不安定だったんだろうと思い、再度リトライしても失敗。
その日はもう夜も遅かったので、一時的にRoute53かVPCのネットワークが不安定だったのだろう(聞いたことはないけど)と思い、また翌日リトライすることにしました。
次の日は成功したが
翌日リトライしてみるとあっさり成功。昨日のエラーは何だったんだろうと思いながらも他にも業務があったので、そのまま忘れることにしました。
そして数日後、またリリースを実施しようとすると以前と同じエラーが発生。もうすぐ日程をズラせないリリースも控えていたので、本格的に調査をすることにしました。
手始めに
まず最初にやるのはエラーの解読。エラーメッセージからDockerでImageをECRからpullする時に、ECRのドメインを名前解決する辺りでtimeoutが出ている模様。
試しに手元のマシンやCIのジョブ上からECRの名前解決を試してみると成功する状態でした。
ここまででわかっている情報は大きく2つです。
エラーが出ない日と出る日がある
原因は特定出来ていないが、少なくともここ1年は出ていなかった。
DNS周りが怪しい
おそらく名前解決の辺り。
CIではGithub Enterpiseにもアクセスしており、そのDNSは名前解決が出来ている。
トラブルシューティングの中で面倒なのが、タイミングによって結果が変わる、出来るケースと出来ないケースが存在すること辺りだと思っており、今回はそのどちらも該当していました。
どの辺りから切り分けていこうかなと思い、まずはdeploy出来る状況に持っていくのを優先しようという形で、 エラーが出ない日と出る日がある これを調査してみることにしました。
今までのログやコマンドの結果を眺めていたところ、DNSの名前解決の結果から気になる点を見つけました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
$dig xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com ; <<>> DiG 9.14.3 <<>> xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 19059 ;; flags: qr rd ra; QUERY: 1, ANSWER: 5, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com. IN A ;; ANSWER SECTION: xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com. 59 IN CNAME proxy-ap-n-ProxyLB-1R9IUKJ5VMG6A-733833415.ap-northeast-1.elb.amazonaws.com. proxy-ap-n-ProxyLB-1R9IUKJ5VMG6A-733833415.ap-northeast-1.elb.amazonaws.com. 22 IN A 18.182.137.86 proxy-ap-n-ProxyLB-1R9IUKJ5VMG6A-733833415.ap-northeast-1.elb.amazonaws.com. 22 IN A 52.68.158.116 proxy-ap-n-ProxyLB-1R9IUKJ5VMG6A-733833415.ap-northeast-1.elb.amazonaws.com. 22 IN A 52.198.187.11 proxy-ap-n-ProxyLB-1R9IUKJ5VMG6A-733833415.ap-northeast-1.elb.amazonaws.com. 22 IN A 18.179.102.55 ;; Query time: 9 msec ;; SERVER: 172.19.0.4#53(172.19.0.4) ;; WHEN: Thu Sep 19 17:26:36 UTC 2019 ;; MSG SIZE rcvd: 580 |
CNAMEで返ってきているドメイン名に注目すると、ECRのエンドポイントがおそらくELBであるというところがわかります。
ELB, ALBを使っている方はご存知だと思いますが、ELBのユニット数はリクエスト量に応じて増減し、増加すると返すAレコードの数も増加します。
うまくいった日と行かなかった日の結果を見比べてみるとうまくいっている日はAレコードが2つ、行かなかった日は4つ以上ありました。
何が起きてるのか
これによって何が引き起こされるのか?と思い、GoやDocker周りで調べてみたところ以下のissueを見つけました。
ここにまさに今回の事象に近しいコメントを書いてくれている方もいらっしゃいます。
当時、CIのジョブ上で実行されていたDockerのversionは以下の通り。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
$ docker version Client: Version: 17.03.2-ce API version: 1.27 Go version: go1.7.5 Git commit: f5ec1e2 Built: Tue Jun 27 03:35:14 2017 OS/Arch: linux/amd64 Server: Version: 17.03.2-ce API version: 1.27 (minimum version 1.12) Go version: go1.7.5 Git commit: f5ec1e2 Built: Tue Jun 27 03:35:14 2017 OS/Arch: linux/amd64 Experimental: false |
古いですね。buildされたGoのversionもissueに書かれている問題のversionと合致します。これで原因が「Concourse内部で使われているDockerがbuildされた時のGoの標準ライブラリのバグ」というところまで突き止められました。
ただ、これを解決するにはDockerのupdateをする以外に方法がありません。Concourseのジョブで使われているDockerのversionを上げるにはConcourseのversionを上げるか、 resource-type を書き換える必要があります。
前者は検証も含めるとすぐには出来ないので、後者をやるしかないかなーと思いながら、またログを眺めていたところ、もう一つ気になる点を見つけました。
以下は手元のマシンとCIのジョブ上からDNSの名前解決を行った結果です。
手元のマシン
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
dig xxxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com ; <<>> DiG 9.10.3-P4-Ubuntu <<>> xxxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 59708 ;; flags: qr rd ra; QUERY: 1, ANSWER: 5, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;xxxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com. IN A ;; ANSWER SECTION: xxxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com. 30 IN CNAME proxy-ap-n-ProxyLB-1R9IUKJ5VMG6A-733833415.ap-northeast-1.elb.amazonaws.com. proxy-ap-n-ProxyLB-1R9IUKJ5VMG6A-733833415.ap-northeast-1.elb.amazonaws.com. 9 IN A 52.198.187.11 proxy-ap-n-ProxyLB-1R9IUKJ5VMG6A-733833415.ap-northeast-1.elb.amazonaws.com. 9 IN A 18.179.102.55 proxy-ap-n-ProxyLB-1R9IUKJ5VMG6A-733833415.ap-northeast-1.elb.amazonaws.com. 9 IN A 52.68.158.116 proxy-ap-n-ProxyLB-1R9IUKJ5VMG6A-733833415.ap-northeast-1.elb.amazonaws.com. 9 IN A 52.197.24.241 ;; Query time: 0 msec ;; SERVER: 10.1.144.2#53(10.1.144.2) ;; WHEN: Wed Sep 11 07:41:39 UTC 2019 ;; MSG SIZE rcvd: 218 |
CIのジョブ上(再掲)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
$dig xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com ; <<>> DiG 9.14.3 <<>> xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 19059 ;; flags: qr rd ra; QUERY: 1, ANSWER: 5, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com. IN A ;; ANSWER SECTION: xxxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com. 59 IN CNAME proxy-ap-n-ProxyLB-1R9IUKJ5VMG6A-733833415.ap-northeast-1.elb.amazonaws.com. proxy-ap-n-ProxyLB-1R9IUKJ5VMG6A-733833415.ap-northeast-1.elb.amazonaws.com. 22 IN A 18.182.137.86 proxy-ap-n-ProxyLB-1R9IUKJ5VMG6A-733833415.ap-northeast-1.elb.amazonaws.com. 22 IN A 52.68.158.116 proxy-ap-n-ProxyLB-1R9IUKJ5VMG6A-733833415.ap-northeast-1.elb.amazonaws.com. 22 IN A 52.198.187.11 proxy-ap-n-ProxyLB-1R9IUKJ5VMG6A-733833415.ap-northeast-1.elb.amazonaws.com. 22 IN A 18.179.102.55 ;; Query time: 9 msec ;; SERVER: 172.19.0.4#53(172.19.0.4) ;; WHEN: Thu Sep 19 17:26:36 UTC 2019 ;; MSG SIZE rcvd: 580 |
MSG SIZE が違うのが分かるかと思います。
手元から引いた時は 218 のに対し、 CIのジョブ上からは MSG SIZE が 580 byteになっていました。
解決(?)
これで名前解決をする先のDNSキャッシュサーバーを変えればいけるのではという仮説のもと、CIのworker上の resolv.conf の nameserver を変更したところうまく行くようになりました。
めでたしめでたし。
ではないですね。
そもそもの話
上記の方法はあくまで暫定対応なので、「なぜ手元からDNSを引いたときとCIのジョブ上から引いたときでは MSG SIZE が違うんだ?」 というところを深ぼっていきました。
手始めに、DNSを引いた時のパケットをキャプチャし比較してみます。
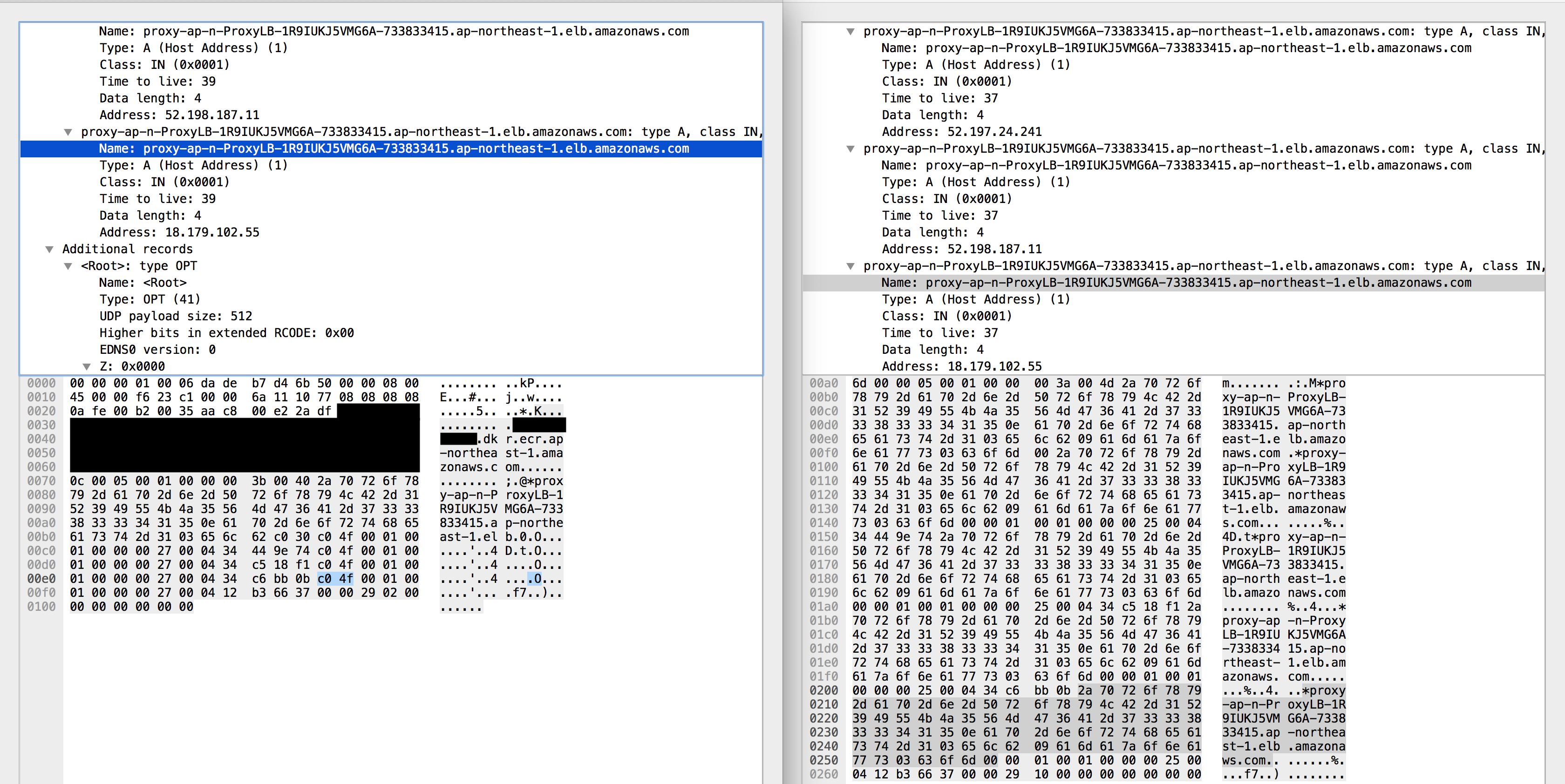
一目瞭然ですね。明らかにサイズが違います。
DNSに圧縮の機能なんか存在していたかなーと思い、slackに投稿したところ、数分で弊社の執行役員である竹迫さん(!)から返事が返ってきました。
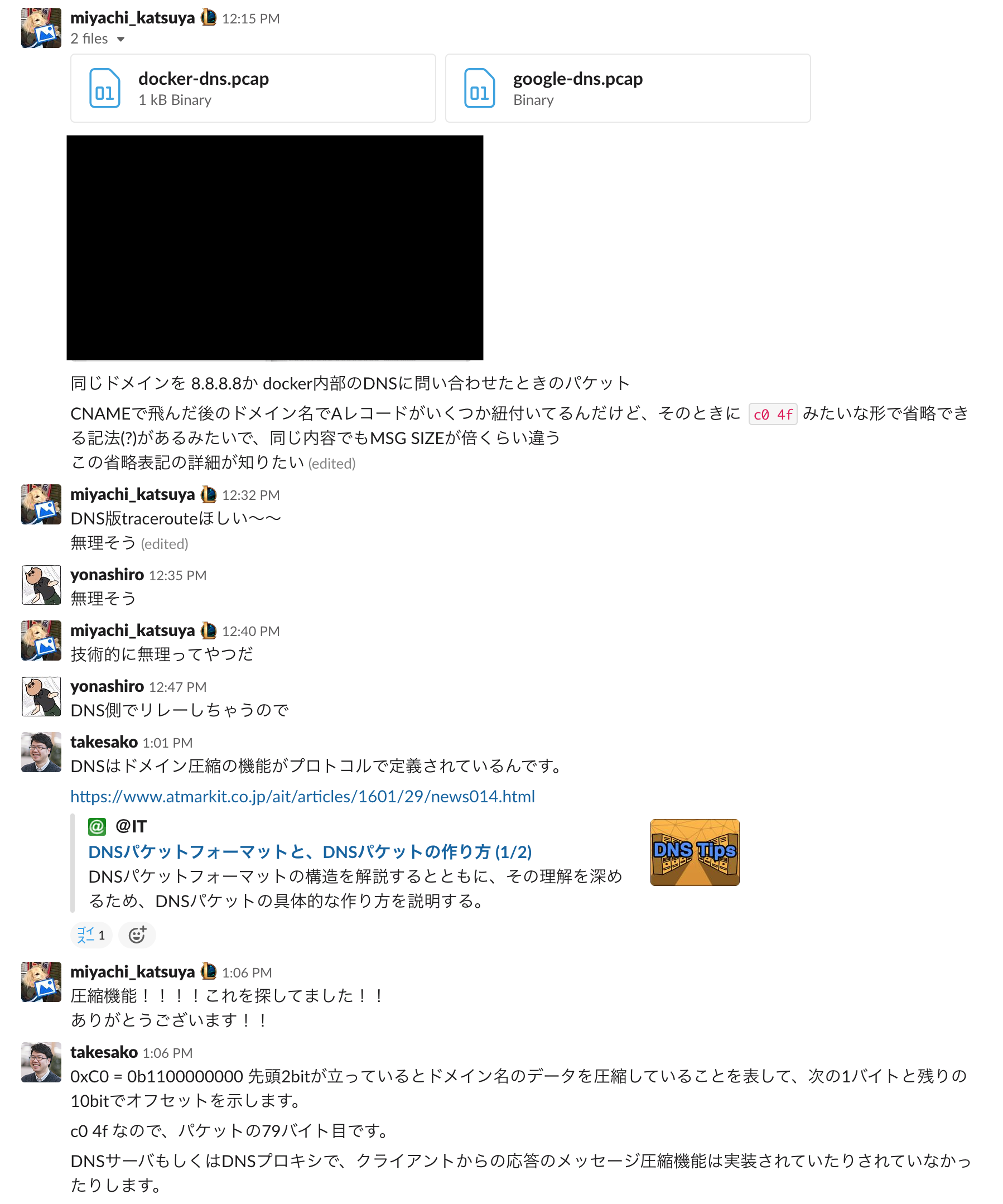
そんな機能が!
RFCにも
4.1.4. Message compression の章に書かれていました。
つまり、どこかのタイミングでこの圧縮を展開しているヤツがいる。ということで次にヤツを探しに行きました。
ヤツ探し
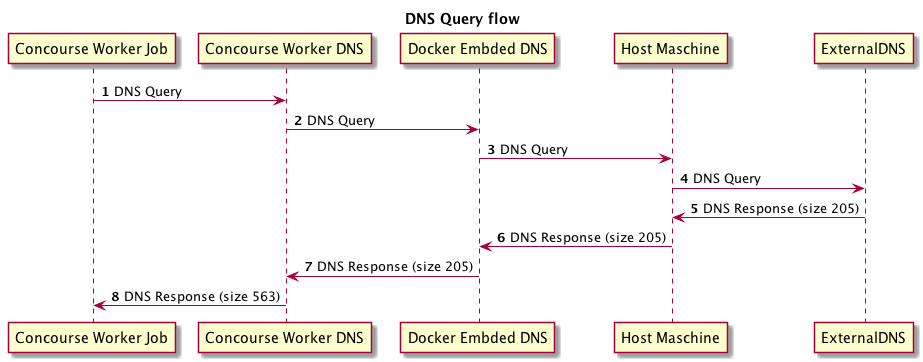
CIはEC2上にdocker-composeで立ち上げるというシンプルな構成です。この構成の中でヤツがどこにいるかを調査していきます。
各ネットワークでパケットキャプチャを行い、どこでDNSの圧縮を展開しているやつが居るのかを調べました。
調査の結果、DNSの流れは以下のようなフローになっていて、各レイヤーのDNSのメッセージサイズは以下のようになっていました。
ここで初めてConcourseのWorkerにDNS Proxyが居ることに気づき、DNS Proxyがレスポンスを返す時にメッセージ圧縮がされていなかったことを突き止めました。
issueとPRを投げる
ここまで来たら、あとはissue立ててPRを投げるだけです。
「ここがこうバグってるから直したよ!」というのをバグの説明をissueに、あとはそのISSUEに紐付けてPRを投げます。
今回の場合、ライブラリ側の責務では?と言われる可能性もあったので、どう説明しようか悩んだんですが、Dockerのlibnetworkも近い実装をしていたおかげで伝えやすかったです。
これにて終了!
まとめ
今回起きた問題をまとめると、
ECRのドメインがの返すDNSレスポンスサイズが不定期に変動することと、Concourseの内部DNS Proxyがレスポンスを圧縮せずに転送していたことによって、当時のGoが抱えるバグを踏んでしまったということになります。
終わりに
いちエンジニアとして色々なOSSをプロダクションで使わせてもらっている中で、起きた障害の原因を最後まで特定し、最終的にOSSに還元するところまでやりきれたのはとても大きな自信になりました。
ここまで淡々と書いていきましたが、実際に障害が起きてからPRを上げるまでは1ヶ月以上かかりました(もちろんこれ以外の業務もあるので)。
特にどのDNSサーバでメッセージ圧縮が展開されているかの特定には時間がかかり、最初はDockerの内部DNSがやっているんじゃないかと推測し、libnetworkの実装を読んだり、dockerやdnsのライブラリにpatch当ててvagrantで再現環境を作って実行してみたりしていました(この辺はGoやコンテナはすごくやりやすい)。また、concourseやDockerが生成するiptablesの解析をやってみたりと色々苦労しました。
結果としてこの辺りは的外れだったのですが、これらの調査の過程で得た知識が役に立って、Concourseの実装を読んだ時にこれだ!とすぐに気がつくことが出来ました。
普段はyamlかHCLばっかり書いていて、クラウド全盛期の時代では日常的には気にしない事が多いですが、低レイヤーの知識を活用してトラブルシューティングしていくのはとても楽しかったです。
これからもOSSを使う側としてだけではなく、バグ修正や機能追加などを継続的に還元できるように活動していきたいです。