目次

リクルートテクノロジーズのアドベントカレンダーの 12/25 の分です。
要するにデータが潤沢なデータレイクと、秩序だったデータウェアハウスがほしいという話をします。データマートは分析者も必要に応じて作ればいいので、なくても問題ないです。データレイク、データウェアハウス、データマートについては本記事で解説します。
とはいえ、「データあるから分析してくれ」を最初に取りかかる場合は、秩序だったデータウェアハウスが無いはずなので、データレイクに大量のデータがあれば贅沢は言いません。実はデータがない状態は本記事では想定していません。
本アドベントカレンダーでは似た内容を先に書かれましたが、本ブログでは使う側の視点なのでちょっと違います。とはいえ、目指す姿はだいたい似るはずです。
http://yuzutas0.hatenablog.com/entry/2018/12/08/235900
なんのためにデータ基盤が必要なのか
何らかの意思決定に影響を与える数字の基礎集計の全容が見えなくなったら、データ基盤を作らないとまずいです。
あとは、「データあるから分析してくれ」で分析できた後に必要です。わたしが得意なことは最初のなんとかするところですが、長くなるので本記事のスコープの外に置きます。
データ基盤の目的は、組織内の多くの人間が必要な情報(数字)にアクセスでき、現状の問題や改善策についてデータに基づいた意思決定ができるようになり、サービスやプロジェクトに対して当事者意識をもって取り組めるようにするためです。
そのため、データ基盤はひとつだけで、多くの部署の人間が気楽にアクセスできる方が望ましいです。
部署ごとにデータ基盤が違うと、部署間で共有する数字の整合性が合わないという問題が発生した時、その現象の解決にはつらすぎる作業が必要になります。同じ組織なのに隣の部署の数字が見えてはならない!みたいな場合はデータ基盤をひとつにはできませんが、よほど特別なケースを除き、部署間で数字とデータの共有ができないなんてデータ基盤以外の問題がありそうです(個人の見解)。
また、データ基盤に多くの部署の人間が気楽にアクセスできるようにするため、クレジットカード番号やら社員の給与情報などの、他の人が見てしまってはまずい情報はデータ基盤に絶対に流してはダメです。
データレイクとデータウェアハウスとデータマートについて
本記事で言及するデータレイクやらデータウェアハウスやらデータマートやらは概念なので特定のプロダクトを指すものではありません。製品名にデータウェアハウスとあっても、それをデータレイクのように使用することは普通にあるので、ご注意ください。
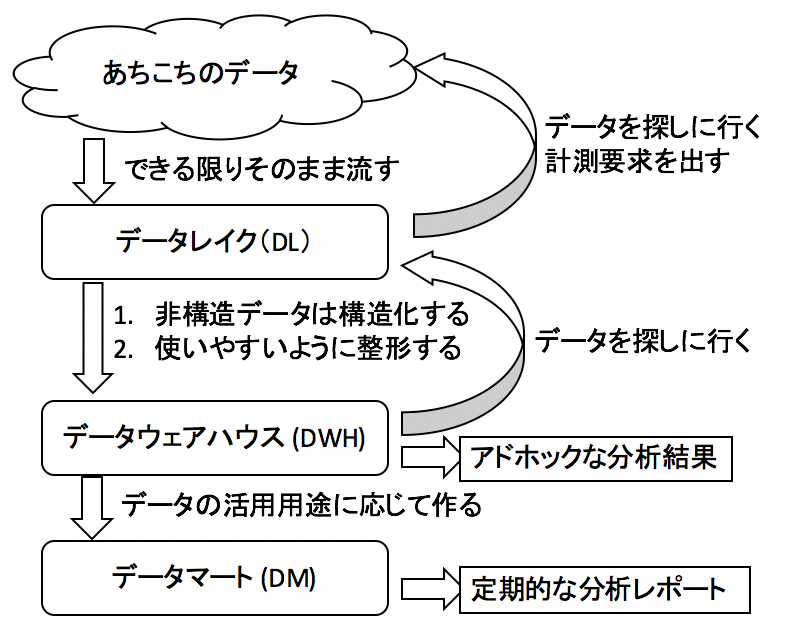
データ基盤のおおまかな流れはこんな感じです。
具体例があったほうがわかりやすいので書きます。今なんとなく寿司が食べたいので、架空のお寿司屋さんを例に適当に考えます。数字とか用途とかは本当に適当ですが、これでなんとなく雰囲気が伝わるんじゃないかなぁと思ってます。
データレイクの状態
伝票が雑に転がってます。
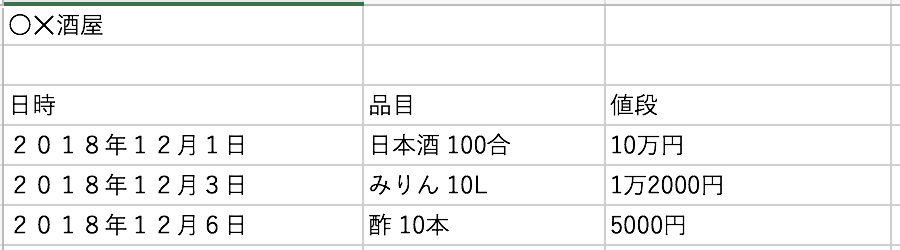

酒屋の日時と魚屋の発行日が同じものを指すのか?酒屋の値段は内税か外税か?酒屋の伝票の方がだいたい文字列など実に嫌な予感がします。ただ、ここには実際の伝票が再現できるくらいの情報をデータベースに入れておきます。データレイクには他にも色んな情報が転がってます。
データウェアハウスの状態

データレイクを漁って、こんな状態にまで持ってきました(とします)。
注文日時と納品日時は、データレイク内に発注表をみつけたので、その情報と伝票情報をくっつけました。データベースの日付型に変換もかけました(ノーモア日付文字列)。
名称は単位に関する箇所を気合の正規表現と独自辞書で取り除きました。
種別は、実際に材料の仕入れの分析の粒度にあわせて、やはり正規表現と独自辞書で付与しました。
量と量(単位)は、仕入量を定量的に分析しやすくるため分離しました。量(単位)は利用可能単位ホワイトリストで管理されています。日本酒はメニューではミリリットル単位で表記してあったため、ミリリットルのほうが分析しやすかったためミリリットルにしました。データの内容は分析目的から決めます。
価格は税抜きで統一、こちらも整数型で統一です。
データウェアハウスは分析用途によって作るものが変わるので、絶対の正解はないのですが、さきほどのデータレイクに注文表が転がってる状態よりかはだいぶ使いやすくなったはずです。
データマート
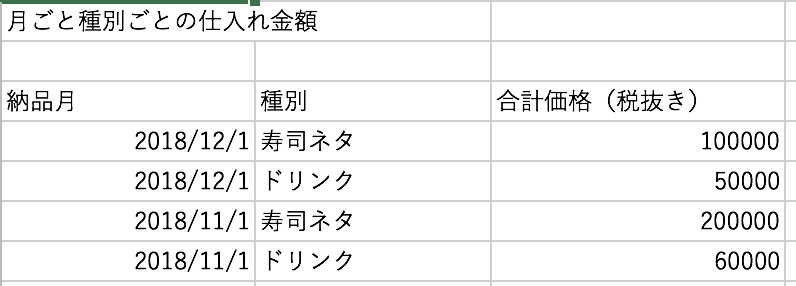
月間の仕入れの金額を定常モニタリングするため、上のデータウェアハウスのテーブルを月単位種別ごとに集計したものを作りました。他にも、お客さんの注文履歴がわかるレジデータをもとに作ったデータウェアハウスを組み合わせた実質原価比率がぱっとわかるテーブルもデータマートに作れるなど夢が広がります。
というお話でした。
これはフィクションですが、データ基盤はだいたいこんな感じになるはずです。
データレイクとデータウェアハウスとデータマートをそれぞれもう少し解説
データレイク
データレイクとは、AWSのドキュメントでは
データレイクは、規模にかかわらず、すべての構造化データと非構造化データを保存できる一元化されたリポジトリです。データをそのままの形で保存できるため、データを構造化しておく必要がありません。また、ダッシュボードや可視化、ビッグデータ処理、リアルタイム分析、機械学習など、さまざまなタイプの分析を実行し、的確な意思決定に役立てることができます。
と書かれてます。(引用元:https://aws.amazon.com/jp/big-data/datalakes-and-analytics/what-is-a-data-lake/)
この中で特に重要な点は
1. 一元管理
2. そのまま
の2点です。
なぜこの2点が重要なのかを示すため、具体的に残念な例を挙げてみます。
- データが一元管理できてないから、集客施策のデータを取得するのにアカウント申請が必要で、アクセスログを集計するために本番サーバーでの作業許可が必要など、いちいち面倒くさい。
- データ集計時に数字ずれがおきた!データレイクに流された時点で加工されているため、そのデータレイクへの加工に問題があるのか、もともとのログがおかしいのか、これらの問題の切り分けができず。そのために本番サーバーの数字とデータレイクの整合性の検証が必要となり、本番サーバーでの作業許可が (ry
ということで、データレイクへはとりあえずデータ流しとけっていう思想です(流したらまずいデータを除き)。ストレージも昔よりも価格が下がってますし。
とはいえ、無秩序に流し込むとデータ沼と揶揄されるカオス状態になります。レイク(湖)を正常に保つために、日々のこまめな掃除と定期的な大掃除が必要そうですが、私は生来掃除が苦手なので、その辺は良くわからないです。データが無いよりは沼のほうがありがたいです。どっちかというと、データレイク自体の秩序よりも、次に解説するデータウェアハウスへ流し込むところの秩序のほうが重要だと考えてます。
データウェアハウス
やはり、AWSのドキュメントから引用すると
データウェアハウスは、トランザクションシステムと基幹業務アプリケーションから取得したリレーショナルデータを分析するために最適化されたデータベースです。データ構造とスキーマの事前定義は、SQL クエリが高速になるように最適化されます。業務レポート作成や分析などには、通常、SQL クエリの結果が使用されるためです。データにはクリーニング、エンリッチメント、変換が実施され、信頼できる “単一の情報源” となるようにします。
難しい文章がでてきました。
私の考えるデータウェアハウスの存在意義は
- 利用のための学習コストを下げる
- データから知識発見の過程でのストレスを下げる
の2点です。これがあることで、組織内でデータ分析する文化が成熟し、専門のデータサイエンティストがいれば、その人の専門性が活きてきます。データサイエンティストとして専門的な仕事を求めるのなら、この状態を作ってからにしてほしいものですが、世の中を見回すと必ずしもそうじゃないようです。
データウェアハウスの存在意義① 利用のための学習コストを下げる
大きく以下の3つは満たしておきたいです。
1. どこになんの情報があるかわかる→データ沼を泳がなくて済む
2. 広く知られてる手法が使える→すでに普及してるSQLだと嬉しい
3. データソース特有のドメイン知識を意識しなくて良い
これを満たしてないと、データ基盤利用の学習コストがあがるのは自明ですね。
“どこになんの情報があるかわかる” ためには、データウェアハウスのドキュメント(どこになにがあるか)や、データレイクからデータウェアハウスへの変換ルール(その情報がどこから来たか)が整理整頓されている必要があります。
“広く知られてる手法が使える” はとても重要です。RDBから情報をとってくるSQLのSELECT文は、それ自体のわかりやすさというよりも、すでに広く使われているという点で優れてます。またSQLの種類によっては、結構表現力が高いので、データレイクからデータウェアハウスへの変換ルールの多くをSQLだけでなんとかすることも場合によっては可能です。ただ、このSQLで正規表現地獄の処理とか入ってると可読性やら保守性やらが低いものができあがるので、SQL資材管理はちゃんと考えておかないと、データレイクからデータウェアハウスへのSQL管理の部分にもうひとつ沼ができてしまいます。
“データソース特有のドメイン知識を意識しなくて良い” のドメイン知識は、寿司屋の酒屋の伝票の値段が税込みか否かといったその情報源特有の知識と、画像や音声や自然言語のような非構造データの扱いのような知識の2種類に大雑把にわかれます。前者はその知識をちゃんとわかりやすくドキュメント整理すること、後者はドキュメント以外に非構造データを構造データに変換する処理(たぶん機械学習モデル)の管理が重要です。
まとめると、データウェアハウス作りには整理整頓系のスキルが非常に強く求められます。このスキルは一般にいわれるデータサイエンティストのスキルとは違いますね。
ただ、データウェアハウスを中身をどうするか?という話は、どういう分析をしたいかによって決まるので(寿司屋の例だと種別カラムとか)、データレイクからデータ分析することはデータウェアハウスを作る前に必要です。
知識の獲得のために誰かがデータ沼に突撃し(サイエンスの仕事)、そこで苦労して泳ぎきった経験をもとに、みんなが使いやすいものをちゃんと作るという流れが正道だと(まことに遺憾ながら)感じてます。
目的なきデータウェアハウスは意味がわからないです。と、強調しましたが、別に高度な統計学や機械学習を使わずとも、当たり前の集計を行って、その集計結果を元に意思決定が行われているのなら、その集計を助ける目的でのデータウェアハウス作りは自然です。
データウェアハウスの存在意義② データから知識発見の過程でのストレスを下げる
- 計算リソースをあまり気にしなくて良い
- 自分用データ基盤を作っても良い
このへんはあったらいいな、という意味でおまけみたいに思われるかもですが、非常に重要です。分析者にフレンドリーなミドルウェアや環境にしましょう。
データマート
あまりデータマートという呼び方に個人的にはしっくりきてないのですが、データウェアハウスで分析した結果を、その用途に対してギリギリまで近づけた加工をした状態です。レコメンド機能などのエンドユーザーに直結する機械学習の学習済みモデルもここと同じ立ち位置の概念だと思ってます。データを活用する側が作ります。データ活用の欲求がある組織がデータウェアハウスから自組織用のデータマートを各々で作る、でいいと思ってます。ここの管理を中央集権的にやろうとするとスピードが犠牲になるでしょうし。
なにかが足りないアンチパターン集
ここでは、データレイク・データウェアハウス・データマートのどれかひとつが欠けた場合になにが辛いかを書きます。
本記事で言いたいことはここです。
データレイクがない場合
データレイクなしで直接データウェアハウスにデータを投入している状態です。保存するさいになんらかの使いやすくなるための不可逆な加工がデータに加えられています。この場合の辛いことはぱっと思いつくだけで
- (Webなら)ログ取得のためのコード量が増えて、開発速度が低下する
- 加工の処理があちこちに散らばりやすくなるので、加工コードの修正コストが非常に高くなる
- 加工前のデータが残ってないので、新しい加工方法にした場合は新しく取得されるデータしか使えない
- 変なデータがあったときに、加工方法が悪いのか元のデータが変なのかの原因の切り分けが困難
と、かなり辛いです。特に分析だけでなく開発のスピードが落ちる点も厳しいものがあります。データレイクがない例、ありそうな話です。
データウェアハウスがない場合
辛いです。データ沼を泳がないとデータ分析ができない状態だと、広くデータ分析する文化が根付きづらいです。珍しい現象ではなさそうです。ただ最初はこんな状態からスタートするものなので最初に分析する人は頑張って泳ぎましょう。
データマートがない場合
分析結果をなにかに利用しようとすると、自然と各人がデータマートを作るはずなので、あまりこのパターンはないです。理想を言えば、全員がデータウェアハウスでSQLを叩ける世界が一番良いので、社内向けにはデータマートを一生懸命作るよりも、使いやすいデータウェアハウスを作るほうが重要だと個人的には考えてます。すでに他の仕事で忙しい人でも、データウェアハウスが使えるようになるように、データウェアハウスの学習コストは頑張って下げましょう。
どんな人がデータ基盤作りにむいてるか
データレイク・データウェアハウス・データマートが必要になるタイミングで変わってくるイメージです。職種で語ると、人によって捉え方がブレるかも知れないので、ふんわり目に書きます。
終わりに
私はデータ沼を泳ぐのは得意なのですが、整理整頓が大の苦手なので、データウェアハウスの作り方の各論はあまり詳しくないです。が、どうなっていたらデータ分析する側としてありがたいかはわかります。
今後、データ基盤を作る人や、今作ってるor使ってるけど何かが辛い人への参考になれば幸いです。