目次
リクルートテクノロジーズの大杉です。
本ブログは、2018年2月から3月に我々の検索チームで一緒に働いてもらったインターン生の山田祥允さんが、今回のインターン中に学んだことをまとめたものです。
彼には、検索改善のための開発とその前にそもそも何を作るべきかの分析を行ってもらいました。そして、なぜ開発側のエンジニアがデータ分析をすべきかについてまとめてもらいました。
—ここから山田さんの記事—
サービスを運用していると、利用者を増やしたいといった要望や速度性能をあげてほしいという要求など様々な改善が求められると思います。
こんな時、闇雲に改善を施すのではなく実際のデータを見て分析を行い、どのような部分を改善すべきなのか決定してから改善していくことが重要です。
例えば、ページの読み込み速度を改善し従来の半分の時間でページを読み込めるようにしたとしても、そのページがほとんど見られていないページであれば大きな改善効果は得られません。また、ユーザがページの読み込み速度よりも検索性能の低さに辟易している場合、読み込み速度を上げるよりも検索性能を改善するべきです。
今回は、こういった観点からサービス改善のためのデータ分析手法について書きたいと思います。
また、僕はこの分析をエンジニアのチームで行ったのですが、企画側の人員や分析専門チームに分析を任せるのではなく、実際に開発に携わるエンジニアがデータ分析をすることが重要だと考えています。
営業→企画→開発と回って来た案件ではどうしても伝達の過程で情報が削ぎ落とされてしまい、本当に課題となっている点の改善に繋がりにくいからです。
実際の開発を行うエンジニアが、データを元にサービスの課題を見つけていくことで、適切な改善が期待できます。
ここでは、僕が今回のインターンで実際に行ったデータ分析を例にデータ分析手法について説明します。
データ分析の流れ
1. 目標設定
まず分析の目標を設定します。
〇〇のクリック数を増やす、△△の閲覧数を増やすなどそのサービスにあった目標を設定する必要があります。
2. データの取得・整形
次に分析に必要なデータを取得します。アクセスログを取って来たり、その情報を使える形に整形したり、などです。
3. 分析手法の選択
そしてどの手法を用いて分析を行うかを決定します。
目標を達成するためには機械学習を使う必要があるのか?単に統計データを収集するだけで良いのか?
機械学習を使うのであればどの手法が適しているか?といった点を考慮します。
4. 分析
用意が揃ったらあとは分析するのみです。
以上が今回行った分析の流れです。
この順序は入れ替えてはいけません。
例えば、目標を決めずに先にデータを取得してしまうと、目標に対して必要なデータが得られないといったことが起こります。
また、分析手法を先に決めてしまうというのは有りがちで、流行りのディープラーニングを使って〇〇したい!というふんわりとした要望はよく聞きますが、その要望に対してディープラーニングが最適でない場合、時間をかけて分析を行った結果、本当にやりたかったこととは異なるものができてしまいます。
各分析手法には向き不向きがあるので、目標に合わせて向いている手法を選択する必要があります。
ここからは、この流れに沿って今回僕が実際に行った実サービスのデータ分析について見ていきます。
目標設定
今回のインターンでの配属先は検索機能担当のチームでしたので、目標としては『ユーザの求めるアイテムを上位に表示する検索』としました。
特に、おすすめ順表示機能とキーワード検索機能にフォーカスしました。
おすすめ順表示機能とは、検索における絞り込み条件での結果を表示する際に価格順・新着順などと並び、機械学習を用いたおすすめ順で表示させる機能です。
データの取得・整形
『ユーザの求めるアイテムを上位に表示する検索』を達成するためには、
– アイテムそのもののデータ
– ユーザの動向に対するデータ
の二つが必要です。
アイテムそのもののデータとして実際に用いているDB内のマスタデータを、そしてユーザの動向に対するデータとしてユーザのアクセスログ、ユーザが検索したキーワードのログをそれぞれBigQuery上で分析しました。
分析手法の選択
今回は機械学習を用いた分析・統計量を用いた分析の両方を用いました。
機械学習を用いたのは、おすすめ順表示機能を改善する際にどういった特徴量が使えるかを調べるためです。ユーザが最も敏感に反応する「価格」に注目し、価格に影響するのはどのような条件であるのかを機械学習を用いて判別しました。
例えば食品であれば季節、銘柄、鮮度といった条件で価格が影響しますし、住宅であれば立地や設備、広さなど多様な条件が影響してきます。
その中で、どの条件がどの程度価格に影響してくるかの分析を行うために、特徴量ごとの重要度が評価できる手法としてランダムフォレスト、線形回帰を選択しました。
次に、ユーザの動向を分析する部分で統計量を用いた分析手法を選択しました。
例えばある人は性能の低い安価なアイテムを多く見ていたり、またある人は多少値段が高くてもこだわりの条件を満たしているアイテムを多く見ているといった情報があります。ここから、各ユーザがどういった条件を重要視しているかを分析できます。
こういったユーザの動向を調べるには、複雑な機械学習モデルを作成するよりも、単純に各ユーザについての統計量を見た方が早いと考え、統計量を用いた分析を選択しました。
分析
まず、機械学習を用いた分析では、アイテムのもつ各条件を特徴量として価格推定のモデルを作成しました。
作成したモデルでは、精度を高めることよりもどの特徴量が重要となるのかを知ることを重視し、それぞれの特徴量と価格との相関をみることで、実際にその特徴量が重要であることを裏付けたりもしました。
この結果、従来の手法では用いていなかった特徴量が、新たにおすすめ順に使えそうであることがわかりました。
次に、統計量を用いた分析では、以下のようにユーザの動向を調べました。
– 各ユーザが閲覧したアイテム同士の相関を取り、各ユーザがどのような条件を重要視しているかを分析
あるユーザについて、見ているアイテムに相関の高い条件があれば、その条件を含むアイテムをおすすめすることができます。
今回の分析では、どのような条件が共通して見られているのかが分かりました。
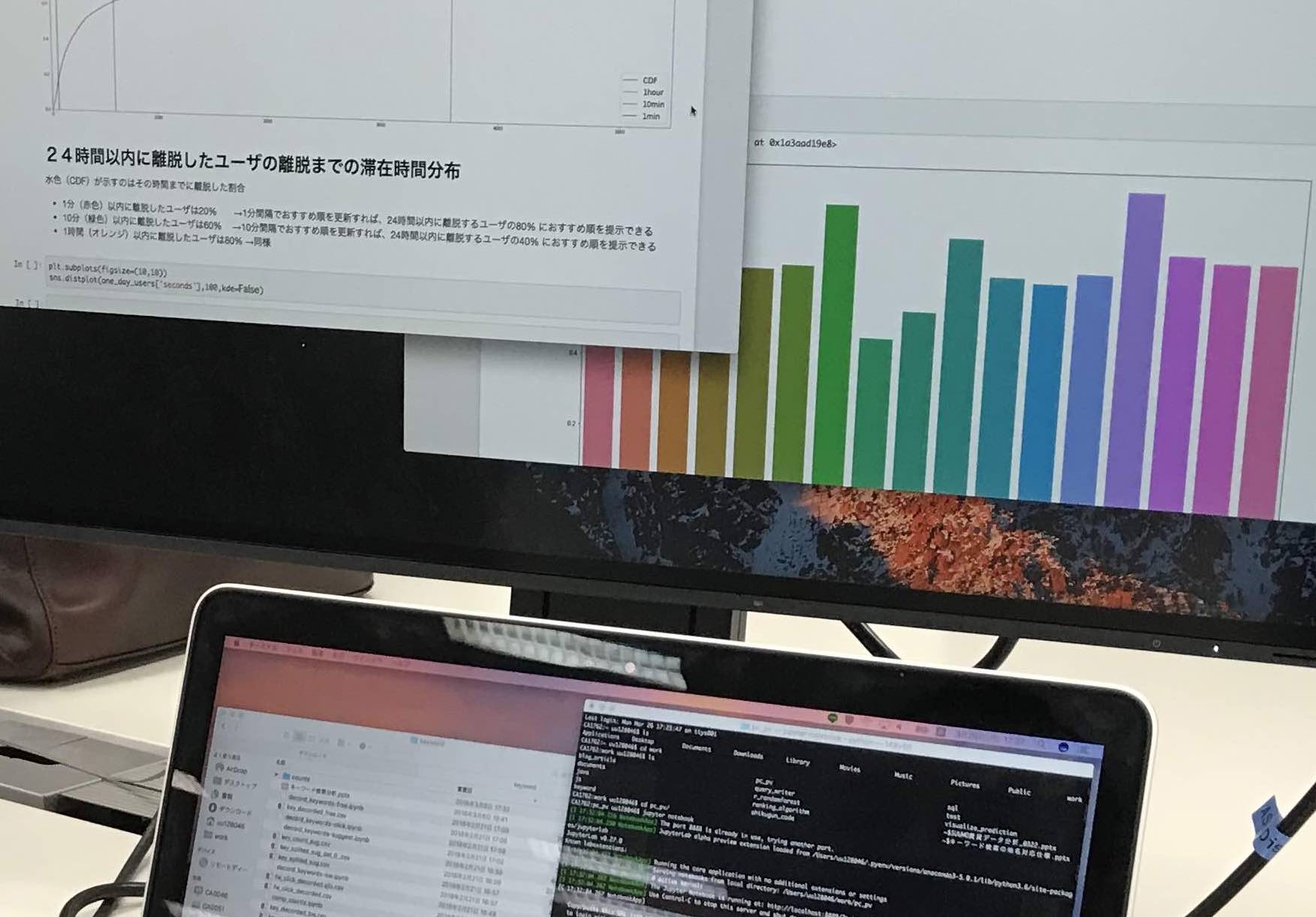
– 各ユーザがアイテムを探し始めてから探し終える(あるいは諦める)までの時間分布を可視化
ユーザがどの程度の時間アイテムを探しているか分かれば、ユーザがアイテムを探している間におすすめするためにどの程度の頻度でおすすめ順のアルゴリズムを更新すれば良いかがわかります。
今回の分析では、特に24時間以内に離脱したユーザについて、どのくらいの時間で離脱しているのかを可視化しました。

縦軸を時間、横軸をその時間までにアクションした割合にすると全容がつかみやすいです
– ユーザがどのようなフリーワードで検索しているかを分類
フリーワードがアイテムの条件を示す場合や、価格に関する条件を示す場合、あるいはアイテム名そのものの検索など、どのような検索ワードが多く存在するかを見れば、改善すべき点が見えてきます。
多く検索されている条件についての検索性能をあげれば、より多くのサービス利用者に対し成果を上げることができます。
今回の分析では、多く検索されているにも関わらず、十分な検索結果が得られていない条件を発見し、改善することができました。
これらの分析を通して、サービスの改善すべき点だけでなく、開発に当たって注意すべき点も発見することができました。
例えば、ユーザがどのくらいの時間で離脱するのかを調べることで、どのくらいの周期で処理を行えば離脱する前にユーザに合わせた結果を提示できるかが分かり、設計上の見通しがよくなりました。
さらに、機械学習を用いたアルゴリズムの予測精度は、時間的に性能が変化しないことが分かったため、無闇にアルゴリズムを更新する必要がなくなり、開発がよりシャープになりました。
このような、開発に直結した分析ができることが、エンジニアがデータ分析を行うメリットとなります。
まとめ
僕が実際に行った分析を例に、データ分析手法について見てきました。
ここで一番大切なのは目標設定の部分で、そこがブレてしまうと分析の内容がまとまりのないものとなってしまいます。
逆に最初に目標をしっかりと定めれば、必要なデータ、分析手法が自ずと決まってくるので、スムーズに分析が進むはずです。
僕が今回学んだこのデータ分析手法が、少しでも参考になれば嬉しいです。