目次
はじめに
はじめまして、ホットペッパービューティーコスメ(以下HPBC)にてフロントエンドエンジニアとして学生アルバイトをしている柏です。
Webサービスで普遍的にもとめられる指標にパフォーマンスがあります。素早く表示されるWebサービスはユーザー体験が良く、コンバージョンや直帰率などにも関係があると言われています。HPBCでは、チーム一丸となってパフォーマンスの改善に継続的に取り組んでいます。
6週間のアルバイト期間で、HPBCのBFF(Backend for Frontend)の性能改善に取り組ませていただき、結果としてレスポンスタイムを200ミリ秒程度短縮することができました。本記事では、その取り組みをテーマに計測を通してパフォーマンスのボトルネックを発見する方法、そして開発の速度を落とさずそれらを解消することについて、ご紹介します。
目次
- HPBCの構成と課題
- Cloud Traceを用いて処理を俯瞰する
- 区間②: APIからBFFまでの遅延
- 仮説1: ページURL
- 仮説2: サーバーリソースの不足
- 仮説3: 検証環境へのベンチマークツールを使った検証
- サンプルコードでの実験
- 対応策の検討
- 区間③: HTML生成の高速化
- V8 Profiler, Performance Measurement APIを使ったNode.jsの処理の調査
- 改善箇所の検討
- SeparateKeyframesの無効化
- StyleLintのルールを追加し、非効率なCSSの記述を禁止する
- styled-components 由来の不要なコメントを削除する
- AutoExtensionImporterの無効化
- 結果
- パフォーマンス改善に取り組むにあたって
- 全体を見渡すところから始めること
- 計測をすること
- 処理の役割とパフォーマンスへの影響を比較すること
- まとめ
HPBCの構成と課題
Web版ホットペッパービューティーコスメでは、Next.jsやReact、styled-components、AMPといった技術を利用しています。クライアントサイドではAMPをフレームワークとして利用することで高いパフォーマンスの維持を狙いつつ、Next.jsを用いてReactで書かれたページをサーバーサイドレンダリング(以下SSR)することでWebフロントエンド開発におけるJavaScriptの資産を活用しています。
ユーザーがページをリクエストしてから実際にページが表示されるまでの流れは、以下のとおりです。
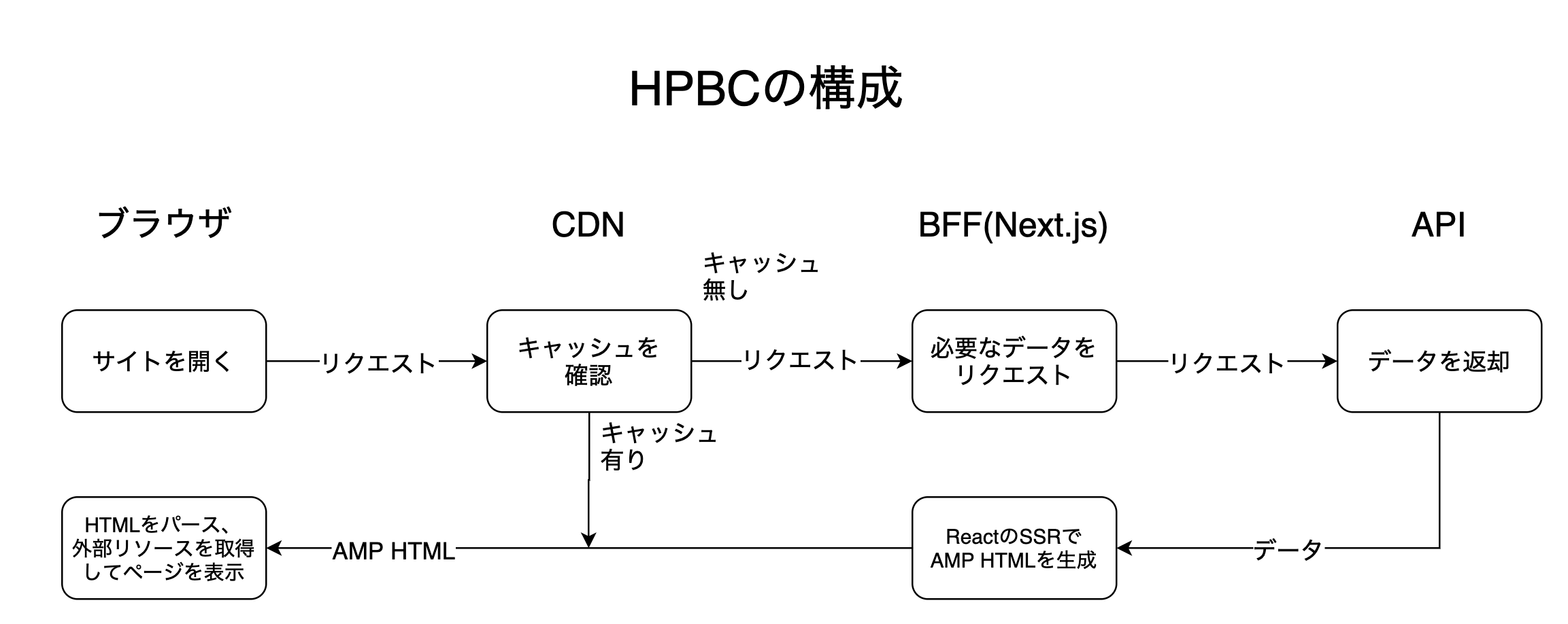
- ブラウザがページをリクエストする
- (キャッシュされていれば) CDNがHTMLを返す
- BFFがページの描画に必要なデータをAPIから取得する
- BFFがAPIから受け取ったデータを用いてAMP HTMLをSSRする
- BFFがHTMLページをブラウザに返却する
- ブラウザがHTMLをパースする
- ブラウザが適切なリソースを取得する
- ブラウザがJavaScriptを実行するなどしてページを表示する
一度アクセスされたことのあるコンテンツはCDNにキャッシュされ、高速にブラウザに届けられます。
この中で、BFFがHTMLを返却してからブラウザがページを表示するまで(6-8)のパフォーマンスに関しては、既に一定の最適化が行われています。AMPのルールに従うことで、使うことのできるCSSやJavaScriptに制限が加わり、ブラウザ上での表示を遅らせる要因は発生しにくくなっています。その上で、Webフォントの削除やPreloadを用いたリソースの事前ロードといった施策で、より高速にページを表示するようになりました。詳しくはこちらの記事もご覧ください。
その一方、ブラウザがページをリクエストしてからBFFがHTMLを返却するまで(1-5)のパフォーマンスに関しては、前段のCDNを活用することに重きを置いてこれまで開発が行われてきました。しかし、機能開発によってCDNでキャッシュしにくいページも追加され、HTMLを高速に生成する必要が出てきました。そこで、CDNより後ろの3-5にかけて調査することとなりました。
Cloud Traceを用いて処理を俯瞰する
前述の通り、ブラウザがページをリクエストしてからHTMLを返却されるまでには、APIやBFFで様々な処理が行われます。パフォーマンス改善のためには、その全体像を俯瞰し、ボトルネックとなっている部分を特定する必要があります。
そこで、パフォーマンス計測の第一歩として利用したのが、Google Cloud Platformの機能として提供されているCloud Traceです。
HPBCでは、Open Censusを用いてNginxやAPI、BFFといったコンポーネントを横断したログを収集しています。トレースを用いることで、ユーザーにページが返却されるまで、どの処理にどれだけの時間がかかっているのか可視化することができます。
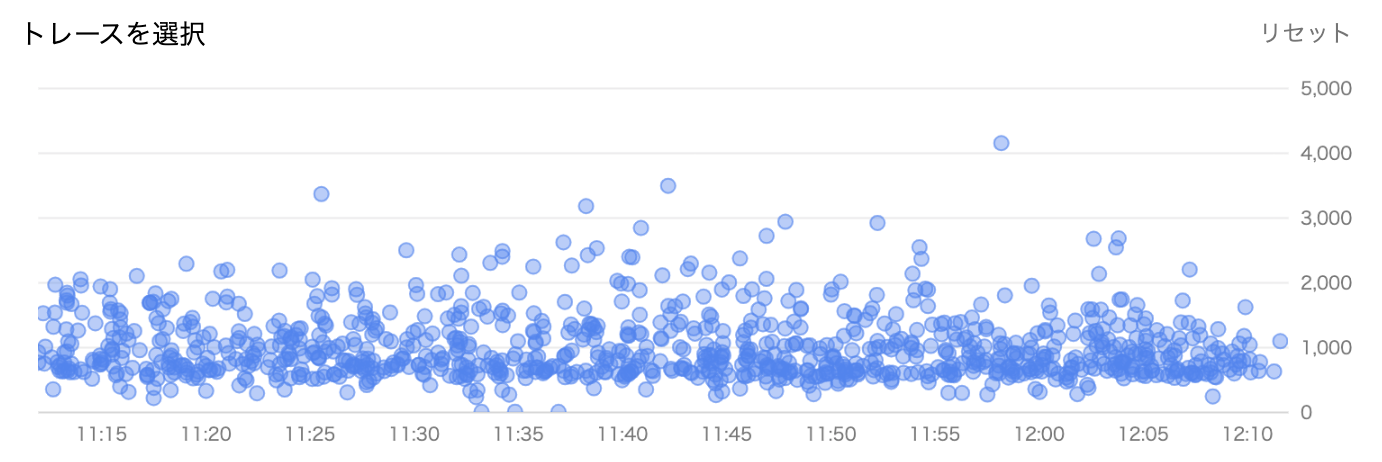
トレースの一覧では、横軸に時間、縦軸に応答時間を取り、BFFの受け取ったリクエストを表示できます。

それぞれのリクエストに対しては、リクエストを受け取ってからHTMLを返却するまでの処理の詳細を見ることができます。例えばこのリクエストでは、BFFがリクエストを受け取った後、BFFがAPIをコールし、APIサーバーがリクエストを受け取った後に応答、BFFがデータを受信して最終的に653ミリ秒でHTMLを返却しています。
Cloud Traceでは、ページのURLやKubernetesのPod、レスポンスの時間などの条件でトレースを絞ることも可能です。そこで、レスポンスに時間のかかっているトレースに絞って調査を行い、どの処理に時間がかかっているのか、ページの種類との関係などについて調べました。
特にレスポンスまでに時間がかかるリクエストに関して、トレースから確認できる範囲で時間のかかっている処理が大きく3箇所あることが分かりました。
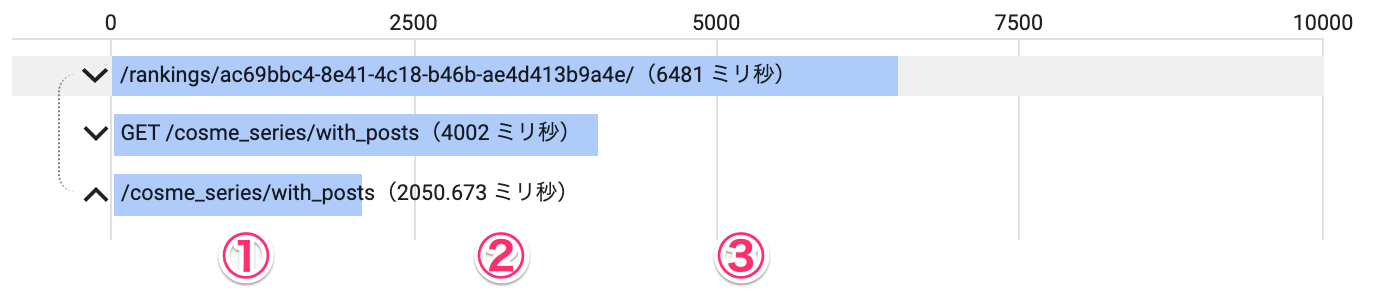
- 区間①は、APIサーバーがリクエストを受け取ってから、レスポンスを返すまでにかかる時間です。DBへのアクセスやデータの変形をしている箇所と考えられます。
- 区間②は、APIサーバーがレスポンスを送信してからBFFがレスポンスを受け取るまでの時間です。
- 区間③は、BFFがAPIサーバーからレスポンスを受け取ってからHTMLをブラウザに返却するまでの時間です。
区間①に関しては、バックエンドチームを中心に継続的に改善が行われています。エンドポイントごとのレスポンスタイムやスロークエリログを監視し、対策を講じています。
そこで、区間②と区間③について、具体的にどのような処理が行われているのか調査し、改善策を考えることとしました。
区間②: APIからBFFまでの遅延
前述の通り、区間②はAPIサーバーがレスポンスを送信してからBFFがレスポンスを受け取るまでの時間です。上記の画像のトレースでは、この区間に2000ミリ秒程度かかっていました。
通信の時間を考慮しても、サーバー間のデータの送信に2000ミリ秒もかかるとは考えにくく、何かしら時間のかかっている処理がありそうです。
仮説を立て、ツールを使って仮説を検証することで、APIコールがBFFで遅延する原因を調査していきました。
仮説1: ページURL
最初に検証した仮説は、特定のページに対するリクエストで発生するというものです。トレースを事象が発生していることを確認しているURLでフィルターし、同じページに対する他のリクエストでも発生しているか調べます。

上の2つのトレースは、同じURLに対するリクエストのものです。左では上から2行目と3行目に差が出ていますが、右では出ていないことが分かります。
結果として、同じURLに対するリクエストでも事象が発生する場合と発生しない場合があることが分かり、ページの種類が原因ではないことが分かりました。
仮説2: サーバーリソースの不足
次に検証したのが、メモリやCPUといったリソースとの関係です。
KubernetesのPodごとのリソースの状況は、Cloud Monitoringを用いて確認することができます。Aggregatorを活用することで最大・最小・平均などを使ってデータをまとめることもでき、コンピューティングリソースの不足と事象との関連を調べました。
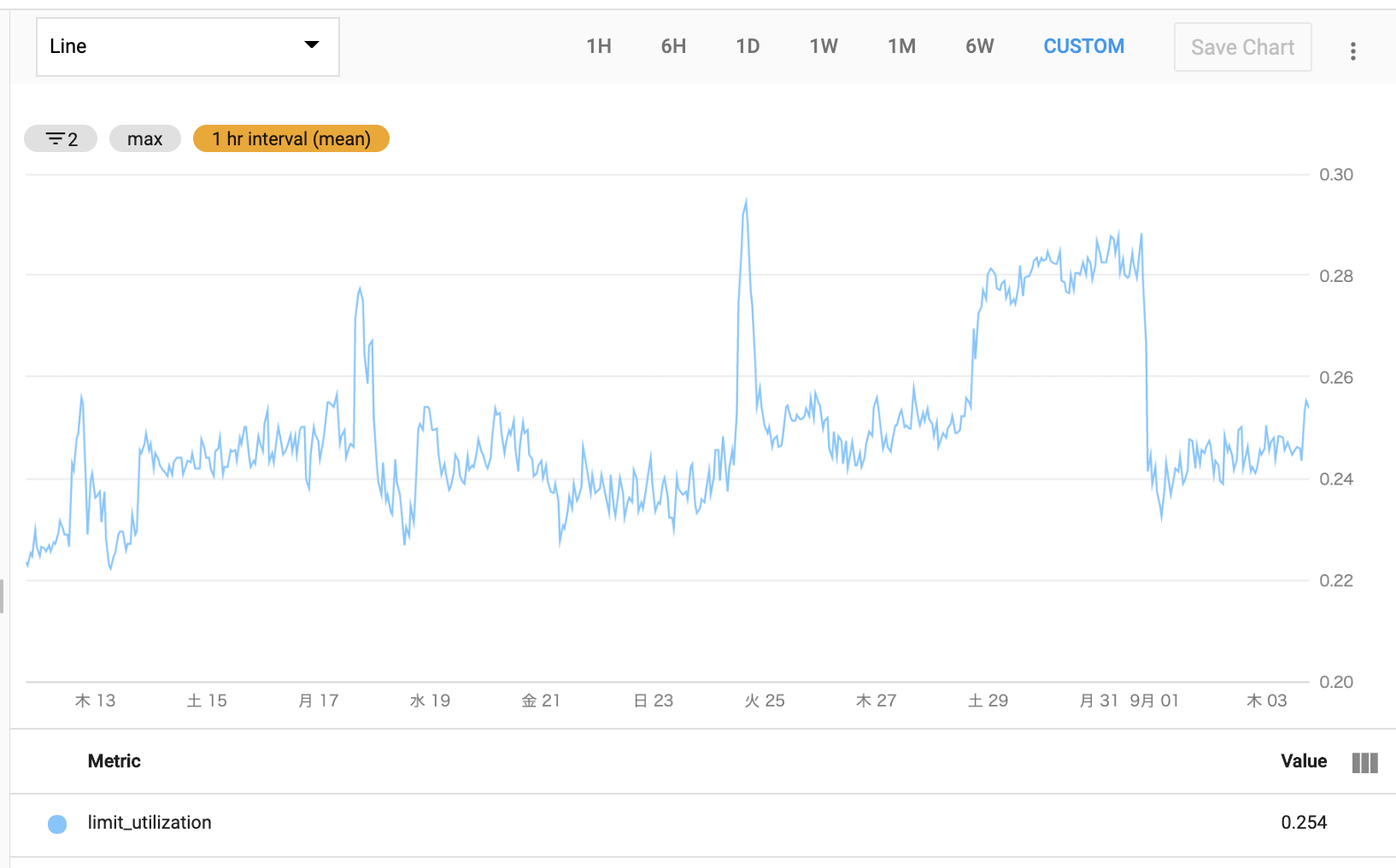
上の画像は、メモリの推移を示したものです。ピークでも30%程度の利用率と余裕がある状態で推移しており、メモリが原因ではないと判断しました。
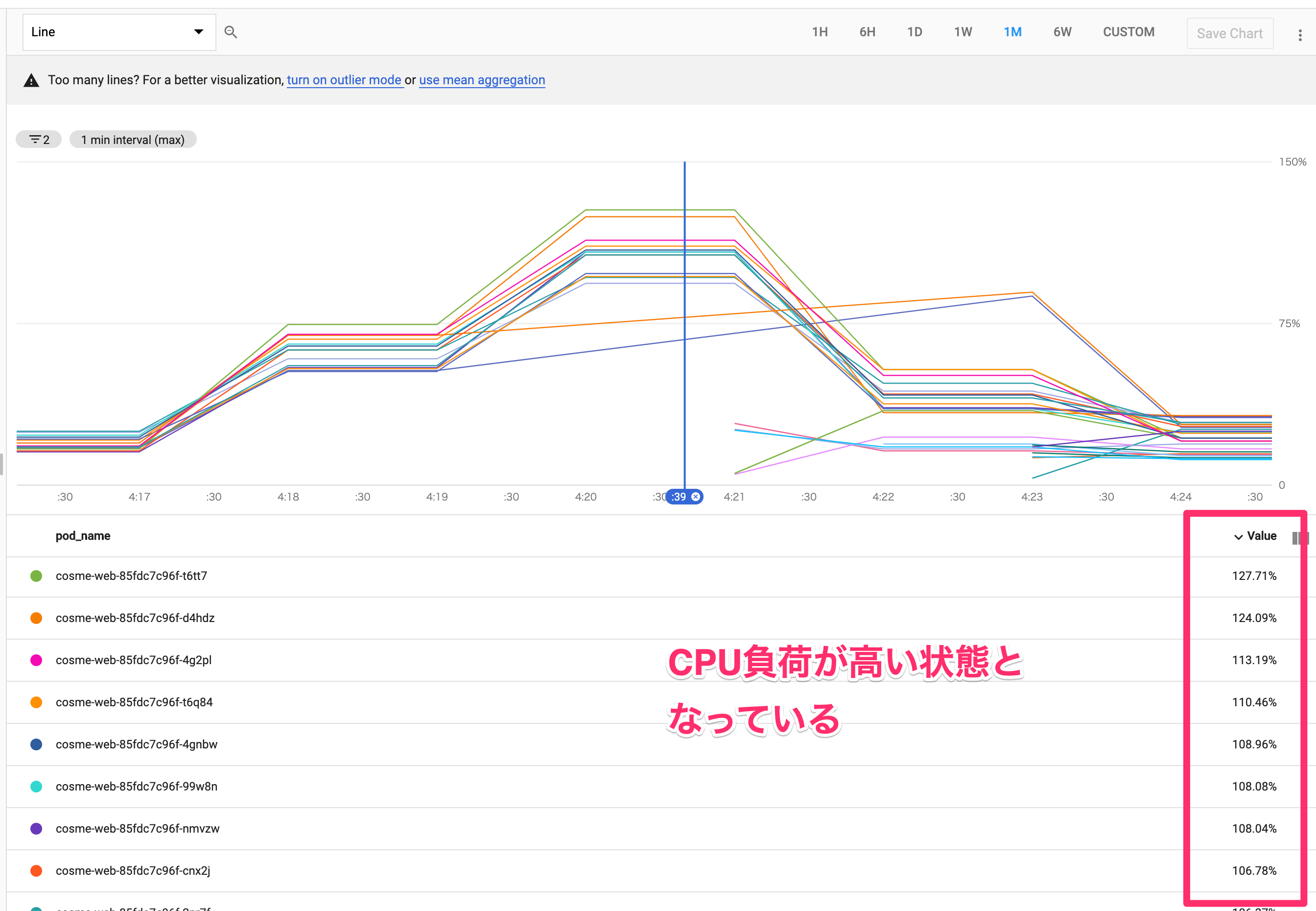
CPUに関しても、一時的に負荷が高まっているタイミングはあるものの、事象がその他のタイミングでも発生していたため、直接の原因ではないと判断しました。
仮説3: 検証環境へのベンチマークツールを使った検証
そこで立てた次の仮説が、短時間に多くのリクエストを受信すると事象が発生するというものです。それを検証するため、本番と同じ構成の検証環境を作成し、ベンチマークツールを用いて大量のリクエストをサーバーに送信しました。その際、同時に送信するリクエストの数を操作し、結果を比べました。
30秒間のテストの結果は、以下のようになりました。
| 同時リクエスト数 | 完了リクエスト数 |
|---|---|
| 1 | 13 |
| 2 | 16 |
| 3 | 15 |
並列度を上げると、それに比例して処理できるリクエスト数も増えるのではないかと予想していました。しかし、同時リクエスト数を増やしても、同じ時間でサーバーが処理できるリクエストの数には変化はありませんでした。
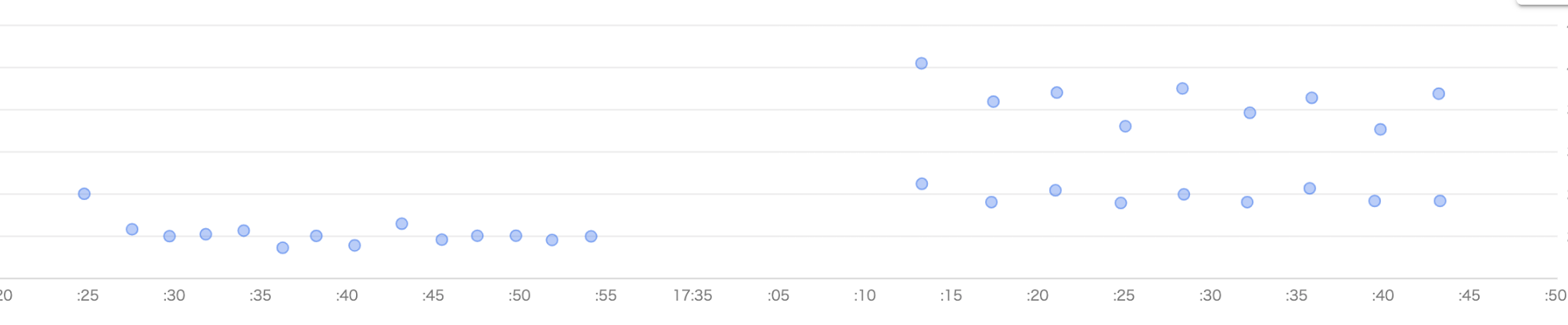
トレースを見ると、同じ時間(横軸)に受け取った2つのリクエストに対して、応答時間が早いものと遅いものに分かれていることが見て取れます。応答時間が遅いグループではAPIサーバーがレスポンスを返却してからBFFで受け取るまでに時間がかかっており、区間②が発生するのは同時に複数のリクエストを受けていることが原因であると考えられます。
サンプルコードでの実験
2つのリクエストを同時に処理する場合、APIサーバーとBFFから見たAPIコールの処理時間に差が出ることを、簡単なコードを使って類似の状況を発生させて確認しました。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
const { performance } = require('perf_hooks');
// APIコール(固定で2000ミリ秒を必要とする)
async function API() {
return new Promise((resolve) => setTimeout(resolve, 2000));
}
// APIレスポンスを使ってHTMLを作成する処理(固定1000ミリ秒)
function GenerateHTML() {
const startTime = performance.now();
while (performance.now() < startTime + 1000);
}
// リクエストを受ける処理
async function request(id) {
console.log(`[${id}] APIコール開始`);
const t1 = performance.now();
await API(); // 2000ミリ秒必要とする
const t2 = performance.now();
console.log(`[${id}] APIコール終了 ${Math.round(t2 - t1)}ms 経過`);
console.log(`[${id}] HTML生成開始`);
GenerateHTML(); // 1000ミリ秒必要とする
const t3 = performance.now();
console.log(`[${id}] HTML生成終了 ${Math.round(t3 - t2)}ms 経過`);
}
// 2件のリクエストを1件目の終了を待たずに作成
request(1);
request(2);
このスクリプトを実行すると、以下のように出力されました。
1
2
3
4
5
6
7
8
[1] APIコール開始
[2] APIコール開始
[1] APIコール終了 2004ms 経過
[1] HTML生成開始
[1] HTML生成終了 1000ms 経過
[2] APIコール終了 3005ms 経過
[2] HTML生成開始
[2] HTML生成終了 1000ms 経過
APIコールに必要な時間は固定で2000ミリ秒なのにも関わらず、6行目の項目において、見かけのAPIコールに必要とした時間が約3000ミリ秒になっていることが分かります。
区間③として示したHTMLを生成する処理に時間がかかり、またNode.jsがシングルスレッドで動作することから、あるリクエストに対してHTMLを生成している間はその他のリクエストに対する処理が行われず、APIサーバーから返却されたデータを処理できていないことがわかりました。
対応策の検討
サンプルコードでの実験から、1つのNode.jsプロセスが2つ以上のリクエストを同時に受信するとレスポンスが遅延することが分かります。こちらの解決策としては、
- Node.jsプロセスの数を増やし、全てのリクエストに1プロセスを割り当てる
- 区間③として示したHTMLを生成する処理を短縮する
の2つが考えられます。
リクエストを受けるプロセスの数を増やすことで、区間②を削減することはできます。しかし、インフラのコストは増大し、区間③のHTML生成に時間がかかることに変わりはありません。
全てのリクエストに関係し、根本的な解決を狙えることから、次のステップとして区間③として示したHTMLを生成する処理の調査・改善に取り組みました。
区間③: HTML生成の高速化
区間③は、BFFがAPIサーバーからレスポンスを受け取ってから、ブラウザにHTMLを返却するまでを指します。この区間のパフォーマンス改善にため、まずは時間のかかっている処理を特定するところから始めました。
V8 Profiler, Performance Measurement APIを使ったNode.jsの処理の調査
Node.jsで発生する負荷の高い処理を見つける際には、V8 Profilerが効果的でした。V8 Profilerを用いることで、処理ごとの大まかな実行時間を計測することができます。
まず、 v8-profiler-next というライブラリを用いて、CPU Profileを作成します。計測を開始するタイミングと終了するタイミングで関数をコールし、計測データをファイルとして書き出します。
HPBCでは、Next.jsのCustom Serverを使っており、リクエストを受けてから5秒間計測を行うコードを書きました。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
server.all("*", (req, res) => {
// ページのパスを含む計測のタイトルを生成
const title = `${req.path.replace(/\//g, "_")}-${Date.now()}`;
// 計測をスタート
v8Profiler.startProfiling(title, true);
setTimeout(() => {
// 開始から5秒経過で停止し、書き出し
const profile = v8Profiler.stopProfiling(title);
profile.export(function (error: any, result: any) {
fs.writeFileSync(`${title}.cpuprofile`, result);
profile.delete();
});
}, 5 * 1000);
// リクエストをNext.jsに渡す
return handle(req, res);
});
書き出された .cpuprofile ファイルは、Chrome Dev Toolsを使って可視化できます。chrome://inspect を開き、Open dedicated DevTools for Node を選択、開いたDevToolsの Profile タブから Load をクリックし、.cpuprofile を読み込みます。
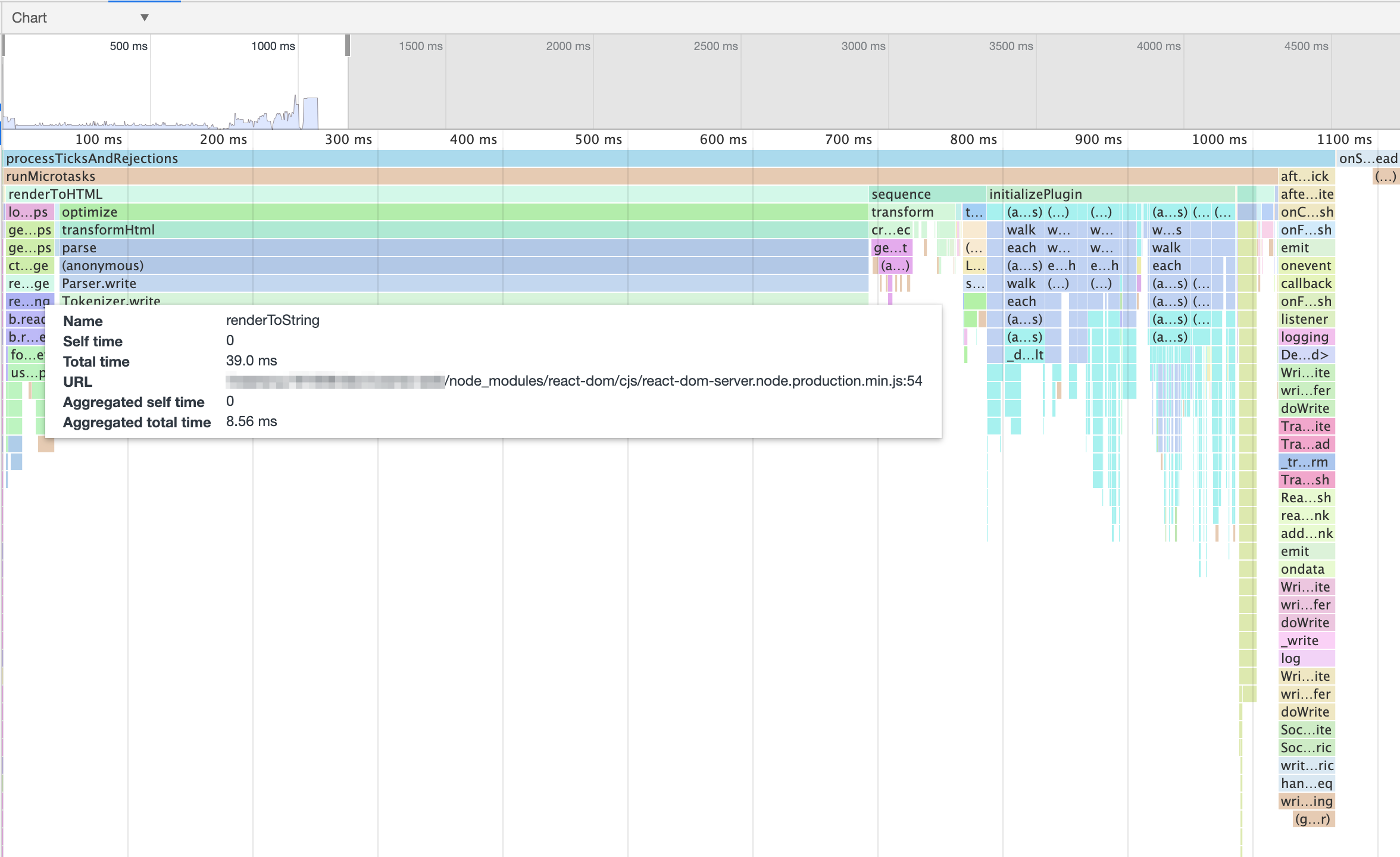
例えばこの画像からは、ReactをSSRする renderToString 関数の実行が40ミリ秒程度で終わっている事が分かります。
このグラフから重そうな処理を特定した上で、ライブラリのソースコードを読みながら実際に行われている処理の内容を解析しました。
APIレスポンスを用いてHTMLを生成する処理は、大きく「ReactのSSRによるHTMLの生成」「AMP Optimizerを使ったHTMLの最適化」の2つに分けられます。
前述の通り、ReactのSSRは40ms程度で終わっており、その後に続くAMP Optimizerの処理がレスポンスまでの時間の大部分を占めていることが確認できたため、AMP Optimizerにフォーカスして調査を進めました。
1
2
3
4
5
6
7
8
9
10
const { performance } = require('perf_hooks');
const performanceLog = [];
const t1 = performance.now();
Transformer_A();
const t2 = performance.now();
performanceLog.push({name: "Transformer_A", time: t2 - t1});
Transformer_B();
const t3 = performance.now();
performanceLog.push({name: "Transformer_B", time: t3 - t2});
console.table(performanceLog);
AMP Optimizerは、受け取ったHTMLをパースした後、複数の"Transformer"と呼ばれる関数をHTMLツリーに対して順々に適用することで、最終的に最適化されたHTMLを生成します。上記のコードのように、それぞれのTransformerの実行の前後で記録を取ることで、それぞれの処理にどの程度の時間がかかっているか調べました。
| 処理名 | 処理時間(ミリ秒) |
|---|---|
| Parse HTML | 28.451 |
| Markdown | 0.006 |
| AutoExtensionImporter | 52.185 |
| OptimizeImages | 0.006 |
| ServerSideRendering | 4.343 |
| AmpBoilerplateTransformer | 0.011 |
| ReorderHeadTransformer | 0.665 |
| RewriteAmpUrls | 0.104 |
| GoogleFontsPreconnect | 0.029 |
| PruneDuplicateResourceHints | 0.057 |
| SeparateKeyframes | 164.524 |
| AddTransformedFlag | 0.015 |
| MinifyHtml | 2.877 |
| AmpScriptCsp | 0.459 |
ここでは、AMP Optimizer全体に約250ミリ秒かかっており、その中でもAMPのCSSを最適化する SeparateKeyframes とscriptタグを追加する AutoExtensionImporter が合わせて216ミリ秒と8割以上の時間を占めていることが分かりました。
改善箇所の検討
ここまでの調査で、区間③の中においてAMP Optimizerの処理が大部分を占めている事が分かりました。
AMP Optimizerは、高速なAMPページを生成するには事実上必要不可欠であり、完全に無効化することはできません。しかし、実行時間の大部分を占めていた2つのTransformerに関しては必ずしも必要ではなく、最適化された後のコードを事前に書いておくことで無効化できると考えました。
しかし、手動でプログラムが行っていた処理を行うことは、開発者の体験を毀損したり、開発の速度を遅くしてしまう可能性があります。そこで、開発者に負担をかけず、生成されるWebページにも大きな変更を発生させず2つの重い処理を削除する方法について検討・実装を行いました。
SeparateKeyframesの無効化
SeparateKeyframesは、受け取ったHTMLに対して以下の処理を行っています。
- CSS内の @keyframes 宣言を探し、
<style amp-keyframes></style>内に移動する - cssnano を用いてCSSのサイズを小さくする
HPBCではstyled-componentsを用いてCSSを記述しており、コンポーネントをSSRする段階でstyled-componentsによって改行やコメントの削除といった一般的なminifyは行われています。その上で、cssnanoはCSSの宣言の意味を解析し、サイズのさらなる削減を行っていました。
例えば、
margin: 10px 20px 10px 20pxはmargin: 10px 20px; にcolor: black;はcolor: #000に
に変換されます。
この処理を省くため、以下の対応を行いました。
StyleLintのルールを追加し、非効率なCSSの記述を禁止する
SeparateKeyframesによって修正されるCSSを書いた際、StyleLintによって警告が出るようにしました。
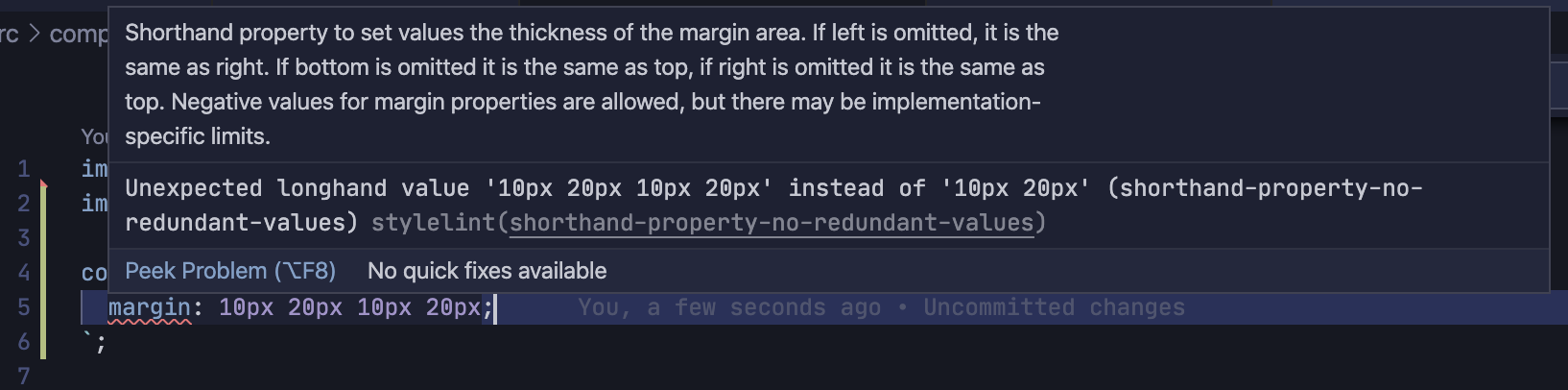
例えば、shorthand-property-no-redundant-values を有効化することで、不必要な値の繰り返しはエラーとして扱われるようになりました。
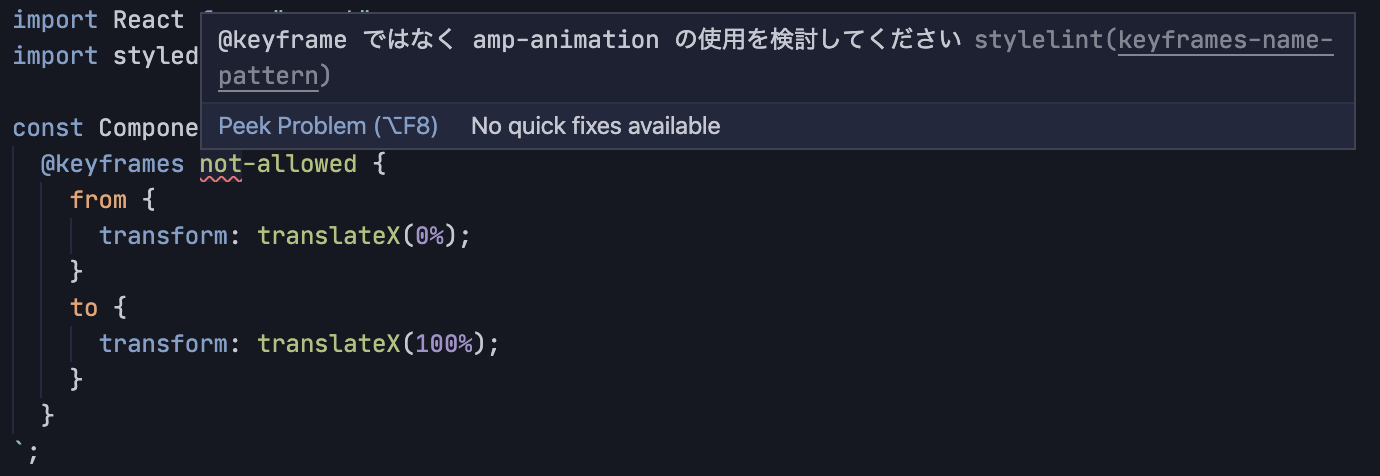
他にも、keyframes-name-pattern と1文字以上の文字列にはマッチしない正規表現 $^ を組み合わせて keyframes宣言をエラーとし、エラーメッセージとして amp-animation の利用を促したりするなどして、SeparateKeyframesを使わずとも最適なCSSを書くことを開発者に促すようにしました。
styled-components 由来の不要なコメントを削除する
HPBCでは、styled-components を使ってCSSを書いています。styled-components をSSRすると、Rehydrateを効率的に行うための区切り文字が追加されます。HPBCではクライアントサイドでReactを使っておらず、Rehydrateも必要ないため、CSSを書き出す際にこのコメントと改行を削除するコードを追加しました。
AutoExtensionImporterの無効化
Web Componentsとして配布されているAMPのコンポーネントは、特定のscriptタグを読み込むことで利用可能になります。AutoExtensionImporterは、HTMLを走査して使われているAMPコンポーネントを判断し、必要なscriptタグを自動でheadタグに入れてくれます。
HPBCでは、これまでページごとに手動でscriptタグを記述していましたが、ページに使われるコンポーネントの依存関係を全て把握する必要があり、いくつかのページでscriptタグの記載漏れが発生していました。
そこで、下記AMPコンポーネントをラップしたReactコンポーネントを作成し、そこにNext.jsの機能を使ってscriptタグを書くことで、コンポーネントを利用する全てのページで自動的にscriptタグが記載されるようにしました。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import Head from "next/head";
import React, { Fragment } from "react";
import Key from "../../../constants/Key";
type Props = {
children?: React.ReactNode;
className?: string;
} & JSX.AmpVideo;
// amp-video をラップしたコンポーネント
const AmpVideo: React.FC<Props> = ({ children, className, ...rest }) => {
return (
<Fragment>
<Head>
<script
key={Key.AmpVideo}
async
custom-element="amp-video"
src="https://cdn.ampproject.org/v0/amp-video-0.1.js"
></script>
</Head>
<amp-video className={className} {...rest}>
{children}
</amp-video>
</Fragment>
);
};
export default AmpVideo;
ポイントはscriptタグに key 属性を追加することです。そうすることで、ページ内で複数回このコンポーネントが使われても、実際にheadの中に追加されるscriptタグは1つになります。
こうしたラッパーを用いることで、開発時の体験と生成されるHTMLを変えることなく、AutoExtensionImporterを無効化することができました。
結果
区間③から2つの処理を無効化する変更がリリースされたため、実際にどの程度レスポンスタイムが改善されたか調査しました。
まず、特定の種類のページのレスポンスタイムに関して、Cloud Traceでレポートを作成しました。
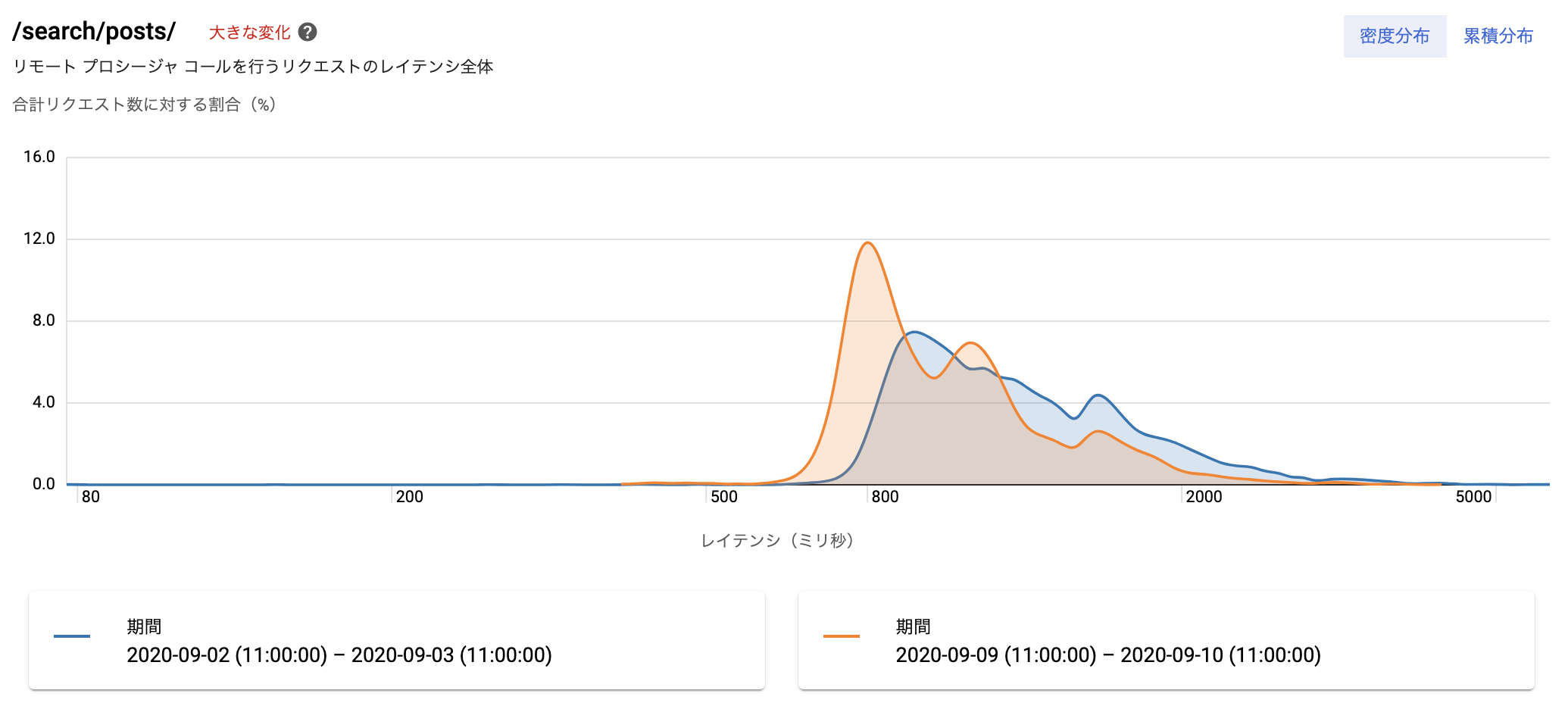
リリース前(青のグラフ)に比べて、リリース後(オレンジのグラフ)はレスポンスが全体的に早くなり、グラフが全体的に左にズレたことが分かります。
Cloud Traceのレポートは特定のページに絞った概算であるため、Big Queryを用いて、BFFが受け取ったリクエスト全てをサンプルとした正確なレスポンスタイムも集計しました。
| パーセンタイル | リリース前(ms) | リリース後(ms) | 変化 |
|---|---|---|---|
| 25% | 717.113 | 496.901 | -31% |
| 50% | 970.638 | 736.812 | -24% |
| 75% | 1318.037 | 1033.041 | -22% |
| 90% | 1767.238 | 1369.275 | -23% |
| 95% | 2129.373 | 1645.225 | -23% |
| 99% | 3184.724 | 2606.936 | -18% |
結果としては、リリース後に200ミリ秒ほどレスポンスが早くなっている事が分かりました。
リリース以前のレスポンスタイムの推移も確認しましたが、100ミリ秒を超えるような変化は見られず、今回の施策によってレスポンスタイムが改善されたといえます。
パフォーマンス改善に取り組むにあたって
今回、初めて稼働しているシステムのパフォーマンス改善に取り組ませていただきました。その中で、パフォーマンス改善に取り組む際に大切だと思ったことをまとめてみます。
全体を見渡すところから始めること
今回、コードを読むような具体的な調査の前に、ユーザーがページをリクエストしてからページが表示されるまでの流れを考えるところから始め、バックエンドにフォーカスした後もトレースを用いて異なるコンポーネントを俯瞰的に眺めました。BFFやAPIといった特定のコンポーネントに始めからフォーカスするのではなく、ユーザーに関係する全ての場所を調べることで、大きくパフォーマンスを損ねている場所にたどり着くことができると感じました。
計測をすること
「推測するな、計測せよ」という言葉はあまりにも有名ですが、今回の取り組みを通してその重要性を改めて理解しました。取り組みの中では、イメージしたパフォーマンスのボトルネックと実際の原因が全く違うことも多く、計測してから手を動かすことで効率よく最適化を行うことができました。
トレースを調査し、BFFでのHTML生成に時間がかかっていると分かったとき、私は「ReactのSSRに時間がかかっているはずだ。どのようにすれば高速化できるだろうか。」と考えました。しかし、Node.jsの処理を計測すると、実はReactのSSRにはほとんど時間がかかっておらず、本当の原因はAMP Optimizerであることが分かりました。このとき、計測を怠ってReactのSSRの高速化に取り組んでいたら、高い難易度に対して少ない成果しか得られていませんでした。
AMP Optimizerに関しても、計測することでTransformerごとの実行時間を出力し、具体的な処理を調べるTransformerを絞り込むことができました。
怠慢せず、手を動かす前に計測し、実行する施策によってパフォーマンスにどれだけの影響があるか調べることは必須だと感じました。
処理の役割とパフォーマンスへの影響を比較すること
計測して遅い処理を特定した後には、処理の役割とパフォーマンスへの影響を比較することが大切だと感じました。
今回手を加えなかった時間のかかる処理として、AMP OptimizerのHTMLのパースがあります。AMP Optimizerは文字列として受け取ったHTMLをパースし、Transformerに渡します。そのパースにも時間がかかっているのですが、その処理を省くにはAMP Optimizer全体を省く必要があります。前述の通り、AMP Optimizerは高速に表示できるAMPページを作るために便利な機能を多く持っており、それを全て無効化するためには、開発に大きな工数を割くことになります。
一方、今回無効化した2つのTransformerは、処理にかかっている時間に対して役割が少なく、ツールやコードを少し追加するだけで開発フローや生成されるデータに大きな変化を加えずに無効化することができました。
時間のかかる処理を手当り次第に削減しようとするのではなく、役割を調べた上でそれに対するパフォーマンスへの影響を評価することが重要です。
まとめ
学生アルバイトとして、ホットペッパービューティーコスメのパフォーマンス改善に取り組みました。実際に取り組むにあたっては、トレースの見方や問題の切り分け方に関して、チームの皆さんに相談に乗ってもらい、様々なアドバイスがもらえました。本当にありがとうございました。
今回取り組んだのはパフォーマンス改善でしたが、「全体を俯瞰する」「計測をする」「役割と影響を考える」といったそこから得た学びは、エンジニアリングにおける問題解決全般に当てはまることだと思っています。
今回の学びを忘れずに、これからも技術的な課題にチャレンジしていきたいです。