目次
こんにちは、データ基盤チームの平本です。
我々、データ基盤チームのミッションは2つあります。
- リクルートライフスタイル各サービスの分析担当者に対して、そのサービス、もしくは複数のサービスにまたがったユーザの行動を分析できる環境を提供する
- 各サービスのデータを使ったOne to One、Cross-use施策のバッチを開発・運用し、各サービスに価値を提供する
今回は第1回目ということで、我々が構築・運用しているビッグデータ環境の全体像について紹介します。
基盤の全体像
我々の基盤は、リクルートライフスタイル全サービスのデータを収集しています。
収集したデータを基に、分析に使うマートやレコメンドに使うデータを作成しており、レコメンドのデータをサービス側のDBへエクスポートしたり、レコメンド結果を返却するAPIを用意したりすることで、各サービス側の画面にレコメンドを表示できるようになっています。
これらのデータの流れを300本ほどのバッチで構築しています。
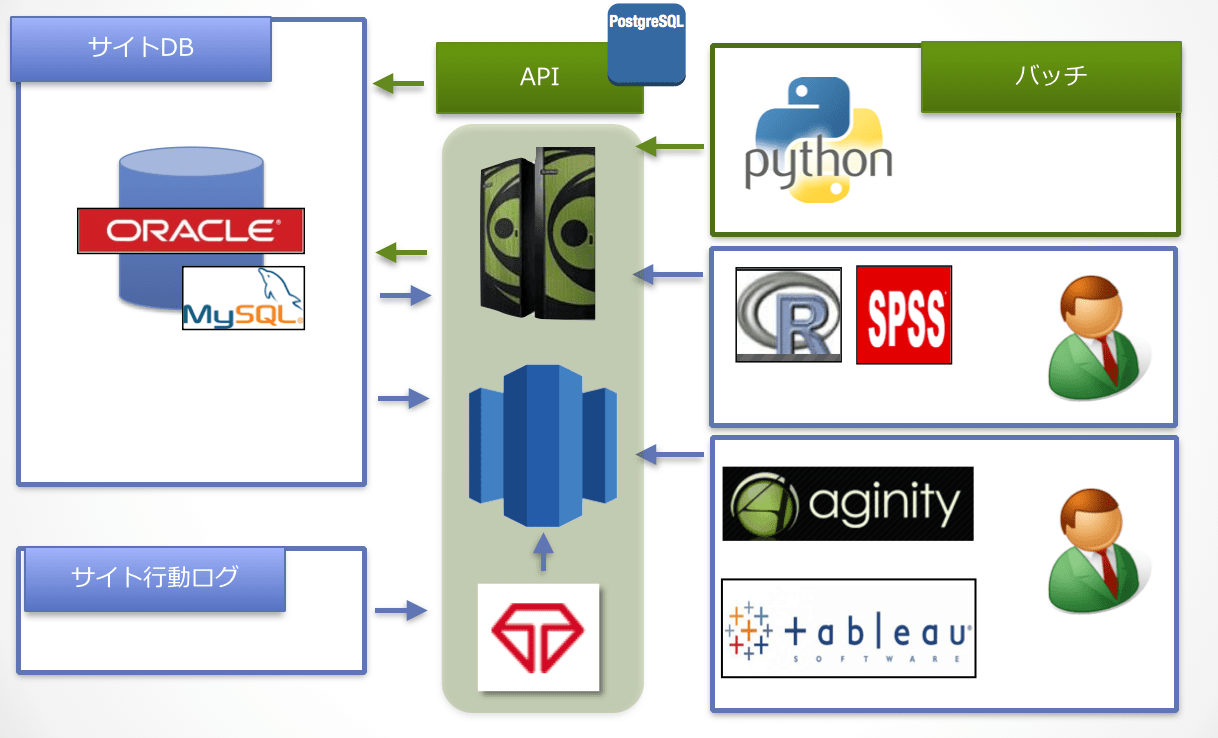
TreasureData
各サービスの行動ログを取込み、1次集計して保存している基盤です。Prestoを多用して、できる限り高速に集計処理を実施しています。
ETL(Extract Transform Load)
独自に実装しており、サービス側のDBのデータをRedshift/Netezzaへ並列インポートできるようになっています。
Redshift/Netezza
サービス側のDBのデータから、マートやレコメンドデータを作成しています。マートを作るにあたって、行動ログが必要な場合は、TreasureDataからインポートしてデータ結合しています。
RedshiftとNetezzaの役割は分かれており、NetezzaはSPSSを使いたい人向け(相性が良いので)に提供しています。Redshiftが登場する前にNetezzaを購入して運用していたので、このような使い分けとなっています。
Redshiftは、簡単にスケールアップとスケールアウトができることから、多くの分析者に使ってもらっています。300人ほどの分析者が、Redshiftへクエリを投げています。
バッチ
データのリレーやDWHで実行する処理が書かれています。バッチはすべてPythonで書かれた独自フレームワークを使って実装しています。
バッチのスケジューリングには、JP1を使用しています。
ビッグデータ用バッチフレームワーク
リクルートライフスタイルでは毎年新しいサービスが誕生します。それに伴い、バッチがどんどん増えていきます。そんな中、以下のようなことが問題となりました。
- 連携しているサービスが多いので、サービス側のシステム変更により、基盤側のバッチを修正する回数が多い
- 既存のバッチは、ソースが冗長になってしまっている箇所が多く、ソース修正箇所が多い
そこで、これらの問題を解決できる独自のフレームワークを作り、適用していこうということになりました。
ビッグデータの処理を高い抽象度で表現すると、「ハコからハコへのデータのリレー」と「ハコの中で集計」になります。
我々が開発しているフレームワークは、この特徴を使った設計になっています。
具体的には、開発者がバッチを実装するには、下記のファイルだけを用意すればOKです。
- データのリレーをどうしたいかYAMLに記述
- データをどう集計したいかをSQLで記述
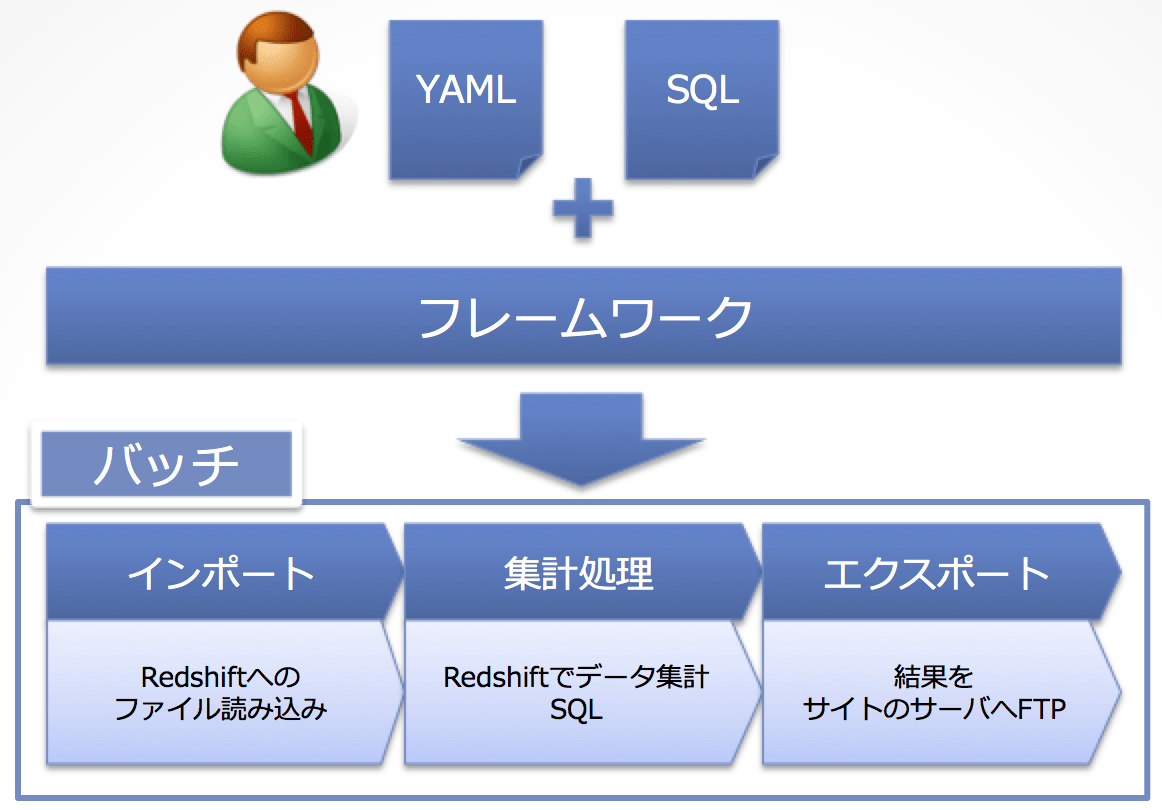
RedshiftやNetezzaへのデータロード、集計結果をサイトへ連携するためのFTPで渡す処理などは、フレームワークが内包しているライブラリ側にすべて実装されています。
よって、開発者はYAMLにデータリレーのフローを書いて、やりたい集計処理をSQLファイルに書くだけで、図に示したようなRedshiftへのデータロード・集計・サービス側へ結果提供するバッチを実装できます。
以下は、NetezzaへデータをロードするYAMLのサンプルです。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
type: loading
sub_module:
-
name: LocalToNetezza
mode:
param:
netezza_component_key: M_NETEZZA_COMPONENT.ID=DATAMART_BATCH
local_storage_component_key: M_LOCAL_STORAGE_COMPONENT.ID=1
source_file: /home/hogehoge/fugafuga.csv
target_table: TABLE_NAME
null_value: ''
max_errors: 100
date_delim: '/'
time_delim: ':'
quote_value: DOUBLE
skip_rows: 0
trunc_string: True
remove_local_source: True
データファイルと、このYAMLだけあれば、Netezzaへデータをロードするバッチが作成できます。 実際のロード処理のロジックは、すべてライブラリ側に実装してあるので、何かバグがあったり、機能追加が必要な場合でも、ライブラリ側を修正するだけでOKです。
まとめ
今回は第1回目ということで、データ基盤チームが開発している基盤の概要を紹介しました。
今後は、より深いフレームワークの話や、Redshiftなどの運用に関して共有していきます。