目次
はじめに
こんにちは、25卒データエンジニアの井上です! このブログは25卒新人向けに行われた研修紹介のブログ記事です、ぜひ最後まで読んでいってください!
今回のブログで紹介するのは 「検索エンジン」 に関する研修です。 この研修は主に「検索の仕組みに関する講義」と「ハンズオン」という構成でした。 講義パートではバーティカル検索とは何か?どのようにして検索は実現されるのか?どのような評価指標が検索システムにおいて用いられるのか?といった検索に関する業務を行う上での基本的な知識を学び、ハンズオンパートではOpenSearchを使っての検索システムの実装を行いました。
本ブログではバーティカル検索とは何か、全文検索の仕組みについて触れたのち、ハンズオンの内容に触れたいと思います。 本ブログで説明する内容は例示で、実際にプロダクトの検索がこれから説明するように実装されているというわけではありません。
1. バーティカル検索とは?

バーティカル検索とは 検索対象の範囲が限定的な検索 のことです。一般的なWeb検索はインターネット上の情報を検索範囲にするのに対し、バーティカル検索は特定の領域のみを対象にします。 例えば『SUUMO』では物件の検索、『ホットペッパーグルメ』では飲食店の検索といったようにリクルートのサービスではバーティカル検索が主に利用されています。
バーティカル検索ではWeb検索と異なり、ファセット検索(ユーザーが詳細な条件を指定して検索する)が重要であること、領域特有の指標(例えば『ホットペッパーグルメ』ではユーザーレビューなど)を利用したランキングの最適化 が可能であるといった特徴があります。
また、バーティカル検索の精度は事業KPIに直結します。 例えばSUUMOでユーザーの検索意図に合った物件を上位に表示できると、ユーザーが必要な情報にたどり着きやすくなり、サービス体験の向上につながります。 つまり、バーティカル検索の精度改善は事業に直接貢献できる という点が検索システムを作る上での醍醐味です。
2. 全文検索の仕組みについて
まず基本的な全文検索の仕組みについて説明します。全文検索は例えば店舗名の検索に用いられます。 例として「リクルート喫茶店」というお店があったとします。この時「リクルート」という検索ワードに「リクルート喫茶店」は引っかかって欲しいですよね。 このような仕組みは全文検索で実現できます。
全文検索をもっとも簡単に実現する方法としては、逐次型 の検索があります。ここでは全文検索の対象となる文章をDocumentと呼ぶことにします。逐次型の検索は全Documentの文頭から検索キーワード を探すことで、目的のDocumentを検索します。

逐次型の検索はシンプルですが、Document数やDocumentの長さが長い場合には現実的な時間で検索することができなくなります。そのような場合においても現実的な時間で検索することを可能にするためには 転置インデックス という仕組みを使います。 転置インデックスを作る際にはまずDocumentの形態素解析を行います(対象が英語の文章ならば行う必要がないですがここでは対象が日本語の文章だとします)。 形態素解析によってDocumentは適切な箇所で分かち書きされます。例えば「リクルート喫茶店」なら「リクルート」と「喫茶店」という単語(Term)に分割されることが期待されます。 実際にどのように分割するかは利用する形態素解析器によって異なりますが、バーティカル検索の文脈では業界特有の単語で区切るためにユーザー辞書などを用いることがあります。
転置インデックスは各Termに対して、それが登場するDocumentのIDを昇順に並べた配列のことです。 具体例は以下の写真を見てもらえるとわかると思います。
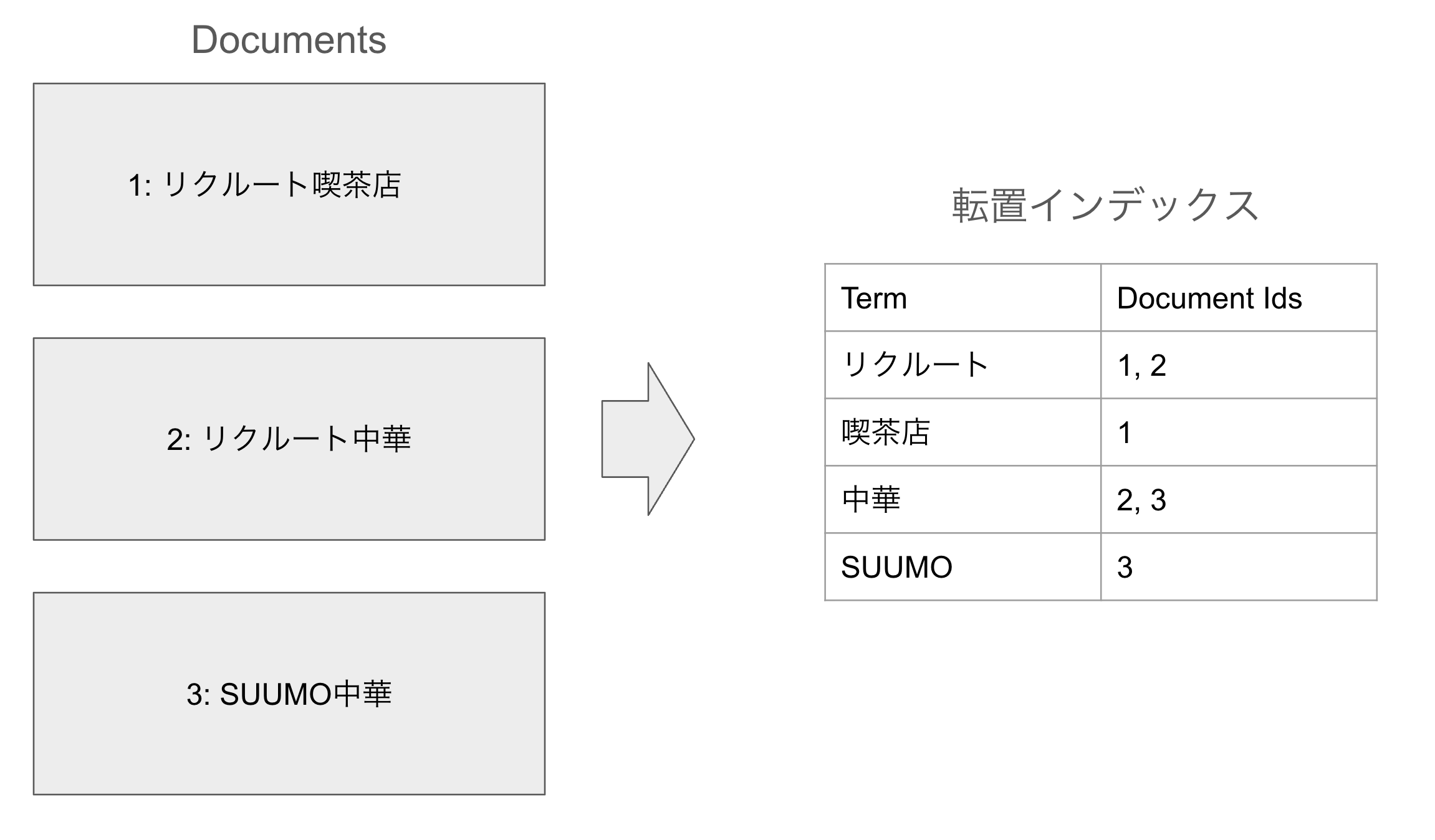
転置インデックスを使うとあるTermが登場するDocumentを高速に検索できます。 例えば初めの例のように「リクルート」と検索したとき、転置インデックスの「リクルート」のTermに対するDocumentのIDを検索結果として返すだけで良いわけです。
さまざまな検索
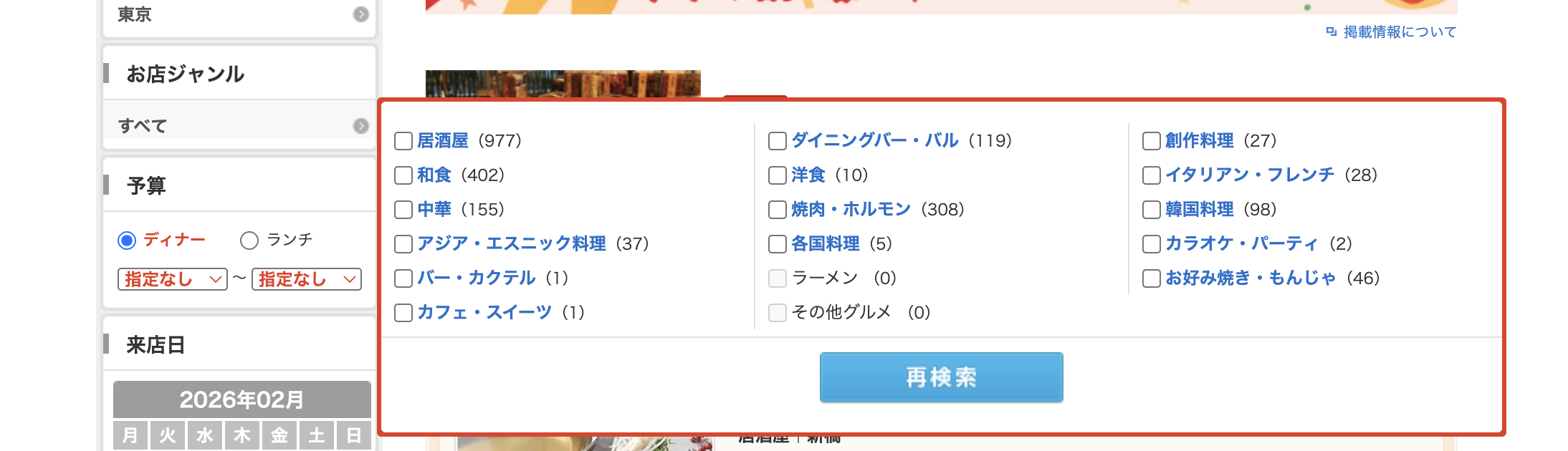
さらにバーティカル検索ではファセット検索も重要です。ファセット検索(Faceted Search) は、データを カテゴリ(ファセット)ごとに分類し、ユーザーが複数のフィルターを組み合わせて絞り込み検索を行える検索手法です。 ファセット検索の対象になるフィールドは例えば業種(中華、居酒屋、イタリアン…)、所在地などです。これらの検索では全文検索とは異なり、特定のカテゴリに分類されるかどうかという条件で検索を行います。 ファセット検索は転置インデックスとは異なり、ファセット検索の対象になるフィールドに対してフィルタリングやグルーピングが可能なカラム志向のデータ構造を持つことで実現されています。
ファセット検索と全文検索を組み合わせると例えば「中華料理で店の名前にリクルートを含むお店」の検索を行えますね。
そのほかにも前方一致検索やFuzzy検索には専用のデータ構造が用いられるなど、さまざまな検索を高速に実現するために多様なデータ構造が利用されることが特徴です。
3. ハンズオン
研修ではハンズオンパートがあり、OpenSearchというオープンソースの検索エンジンを用いて実際に検索システムを実装してみるハンズオンを行いました。
「店舗の予約検索システム」、「店舗の検索後のリランキングを行って精度改善」、「検索補完のサジェスト」の3つのハンズオンを行いました。 この3つのハンズオンのうち僕が面白いと感じた2つのハンズオンについて軽く紹介します。 なお、研修としてハンズオンを実施したのみで事業実装はされていません。
店舗の予約検索システム
店舗の空き時間や業種、店舗名などの条件で検索を行う簡易的なAPIを実装しました。OpenSearchがインデックスの作成などをよしなにやってくれるため、データを適切に入れてあげると検索ができるという体験ができました。初めはそもそもOpenSearch全然触ったことない!からのスタートで、どうやってデータを入れるんだ?とかどうやったら検索できるんだ?を調べるところから始まりました。
ローカルでOpenSearchを立てて、データの投入から自分でやるスタイルだったのですが、1件ずつインサートしているとデータを入れるだけで 30分 も必要で、限られた研修の時間で実装するのは大変でした。これは Bulk API を使って早くインサートできるようにするなどの工夫が必要でした。
オプショナルな課題として、データ量がおよそ10倍に増えたときもレイテンシを維持するというものがありました。 僕はパフォーマンスチューニングが好きなのですが、大量のデータでもレイテンシを維持する ためのOpenSearchでのクエリの書き方 やレプリカ数などに触れることは面白い経験でした。
OpenSearchでは Profile API を使うことでプロファイルを行うことができ、これを見ながらチューニングを行いました。
ランキングに寄与しなくて良い条件を must から filter に移す(参考: Boolean query )ことでかなり検索が高速になりました。 これはこのブログの前半で説明したファセット検索がfilter、全文検索がmustにはおおよそ対応しており、filterを適切に使うことでキャッシュが使えたり、不要な計算を減らせたりすることで、速く検索が行えるようになっていました。 OpenSearchを使うにあたっても検索の中身を理解することは大事だなと感じました。
検索補完のサジェスト
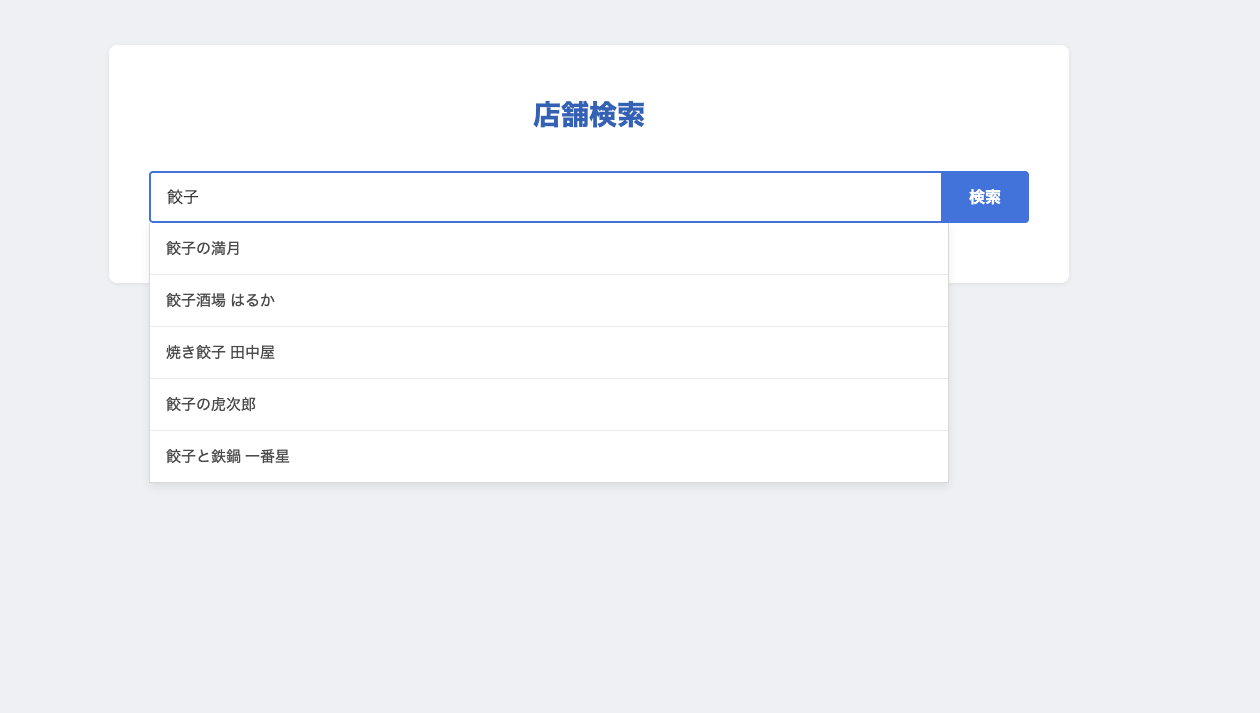
こちらのハンズオンでは店舗名やジャンル名から店舗候補のサジェストを行う機能を実装しました。 イメージとしては以下の画像のようなものです。
これは実はOpenSearchの Completion suggester という機能を使うと簡単に実装できます。内部的にはFinite-state Transducer(FST)というデータ構造を利用して検索が行われています。 こちらは自分でドキュメントを調べて実装をしました。OpenSearchはドキュメントが充実しており、サジェストは Autocomplete functionality のCompletion suggesterを設定することで実現できるとわかりました。
このようなかたちで completion を設定して、
PUT stores
{
"mappings": {
"properties": {
"store_name": {
"type": "completion"
}
}
}
}
このように検索するだけで、サジェストするAPIが実装できます。
GET stores/_search
{
"suggest": {
"autocomplete": {
"prefix": "餃子",
"completion": {
"field": "store_name"
}
}
}
}
このようにしてサジェストAPIを作って、それを呼び出すフロントエンドを書いて検索結果が上の画像のように表示されるのを見て、OpenSearchを使うと複雑なデータ構造を必要とする検索も手軽に実装でき、OpenSearchの凄さを実感できました。
おわりに
今回の研修では検索システムの概要とハンズオンを実際に行いました。
講義パートでは検索システムを実現するためのデータ構造や評価指標について学び、 ハンズオンにおいては、実際に検索システムを作ってみることで検索に関する理解をより深められました。 ちなみにこの研修はハンズオンがかなり大変な研修でしたが、同期でSlack上や現地で助けあったり、生成AIをうまく活用して理解したりしながら進めていくことができました。
研修を通じて、検索システムにおいてレイテンシを保ちながら検索精度を向上させるという速度と精度の両側面の面白さがあることを体感することができ、とても勉強になりました。
このブログを最後まで読んでいただきありがとうございました!