目次
はじめに
こんにちは、Recruit Data Blog 担当の森です。
リクルートのデータ推進室では「Data Meet Up!」と題して、定期的にイベントを開催しています。その第13回目として「リクルート流データ基盤塾 第3弾」を2026年3月24日に実施し、5月14日には再放送を行いました。
データ推進室は事業領域ごとにデータ基盤を構築しており、「各領域で成功パターンやノウハウを作って横展開する」という組織の特徴があります。イベントでは「開発現場におけるAI活用のリアル」をテーマに、3つの事例をピックアップしてご紹介しました。本記事ではイベントの振り返りと動画や資料のリンクを記載しています。ぜひ最後まで、ご一読ください。
1.イベント概要

当日はデータ推進室の鶴谷がモデレータを務め、データエンジニアの3名(上津、勝俣、茅原)が具体的な事例を紹介しました。
当日のタイムライン
19:00〜19:05 オープニング
19:05〜19:20 Claude Actions + Cursor による開発効率化
19:20〜19:35 AIエージェントフレームワークの比較検証
19:35〜19:50 AIエージェントによるプロダクト運用の自動化
- 社内横断プロダクト Crois におけるAIOpsの実践
19:50 ~ 20:00 クロージング
2-1.事例紹介「Claude Actions + Cursor による開発効率化」
はじめに、上津から「Claude Actions + Cursor による開発効率化」というテーマで事例をご紹介しました。現在は要件定義からコードレビューに至るまで、開発のあらゆるフェーズでLLMを利用しており、下記のような効果が出ています。
- 企画担当者からの要望を「堅牢な技術仕様」へと変換
:実装に入る前に、企画要件をClaudeに入力して仕様を作らせることで、検討できていない仕様やエッジケースを出してくれます。 - コーディング支援による「開発力」の底上げ
:LLMのコーディング支援により、1人当たりのアウトプットは劇的に増加。実装フェーズにおいて、エンジニアの役割は「ゼロからコードを書く作業者」から「AIが生成したコードのレビュアー」へと役割をシフトしました。 - 待機時間がほぼゼロの「AIファースト・レビュー」
:AIの一次レビューによるレビュアー負荷の軽減や、レビュイーの心理的安全性の確保ができるようになりました。現在、開発者を除いたコメントの7割近くはAIのレビューです。
一方で下記のような課題もあり、様々な対策も実施しています。
- 非機能要件の不在
:機能要件には忠実ですが、暗黙的な非機能要件を満たさないため、プロンプトやcursor rulesに制約を明文化しています。 - AI特有のオーバーエンジニアリング
:AIが複雑すぎるコードを生成するため、人間が「YAGNI原則」を指示しています。 - 「AI可読性」と「人間可読性」の乖離
:人間にはメンテナンスしにくい構造が生まれるため「人間がメンテナンスするコードであること」を前提に、可読性ガイドラインを遵守させています。
今後、自律型AIパイプラインが当たり前になっていく世界において、人間の価値は「設計の正しさを判断する能力」と、AIを使いこなすための「コンテキスト注入能力」の2つに集約されると考えられます。 AIは「どう作るか」を極めてくれるからこそ、私たち人間は「何を作るか」と「なぜ作るか」にフォーカスできるようになる、と上津は語りました。
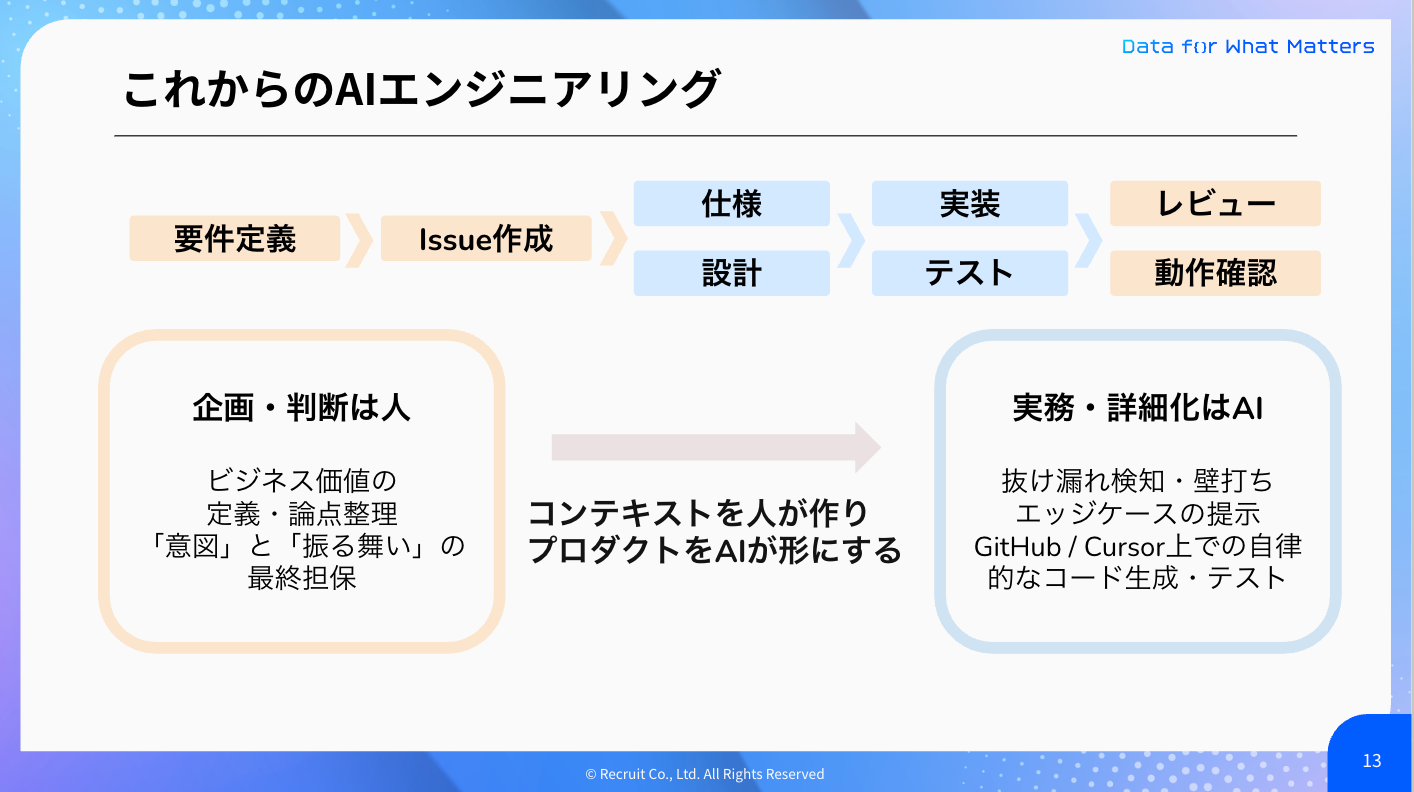
2-2. 事例紹介「AIエージェントフレームワークの比較検証」
続いて勝俣からは、不動産マッチングプラットフォーム『SUUMO』の「従業員向け業務支援ツール」開発における、AIエージェントフレームワーク(※)の比較検証の事例を共有しました。
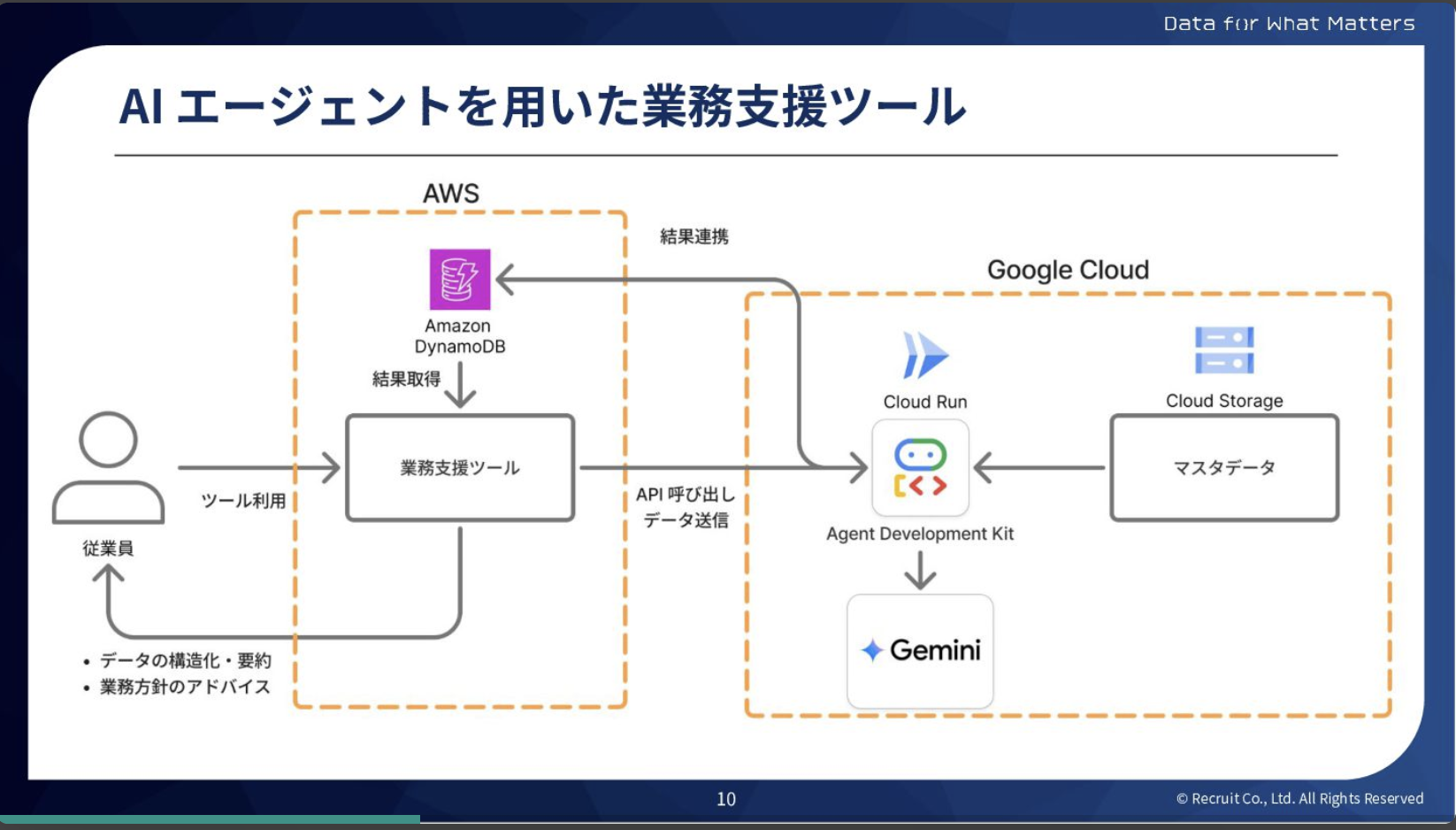
このAIエージェントを用いた業務支援ツールは、デリバリー最優先で作られたため、下記のような課題がありました。
- 不要なマルチクラウド
:ツールの稼働場所がAWSであるのに対し、エージェントはGoogle Cloudで稼働しているため、運用コストが嵩む不要なマルチクラウド状態になってしまいます。 - Agentフレームワークの調査不足
:Agent Development Kitの標準仕様に従わずに利用しています。
そこで各エージェントフレームワークの比較を行ったのが、本事例です。比較観点は主に「機能性」「可用性」「保守性」の3点。今回は下記4つに絞って、比較結果をご紹介しました。
- Strands Agents
- LangGraph
- Agent Development Kit
- OpenAI Agents SDK

※詳細は、ぜひ本記事の最後に記載しているリンク先の動画や資料をご覧ください
最終的に「Strands Agents」を採用し、基盤もAWSに統一しました。その結果、データやLLMについてはGoogle Cloudへの依存もありますが、運用コストは軽減されました。またAmazon Bedrock の利用が必須ではないため、LLM は従来通りGemini を使い続けることができます。
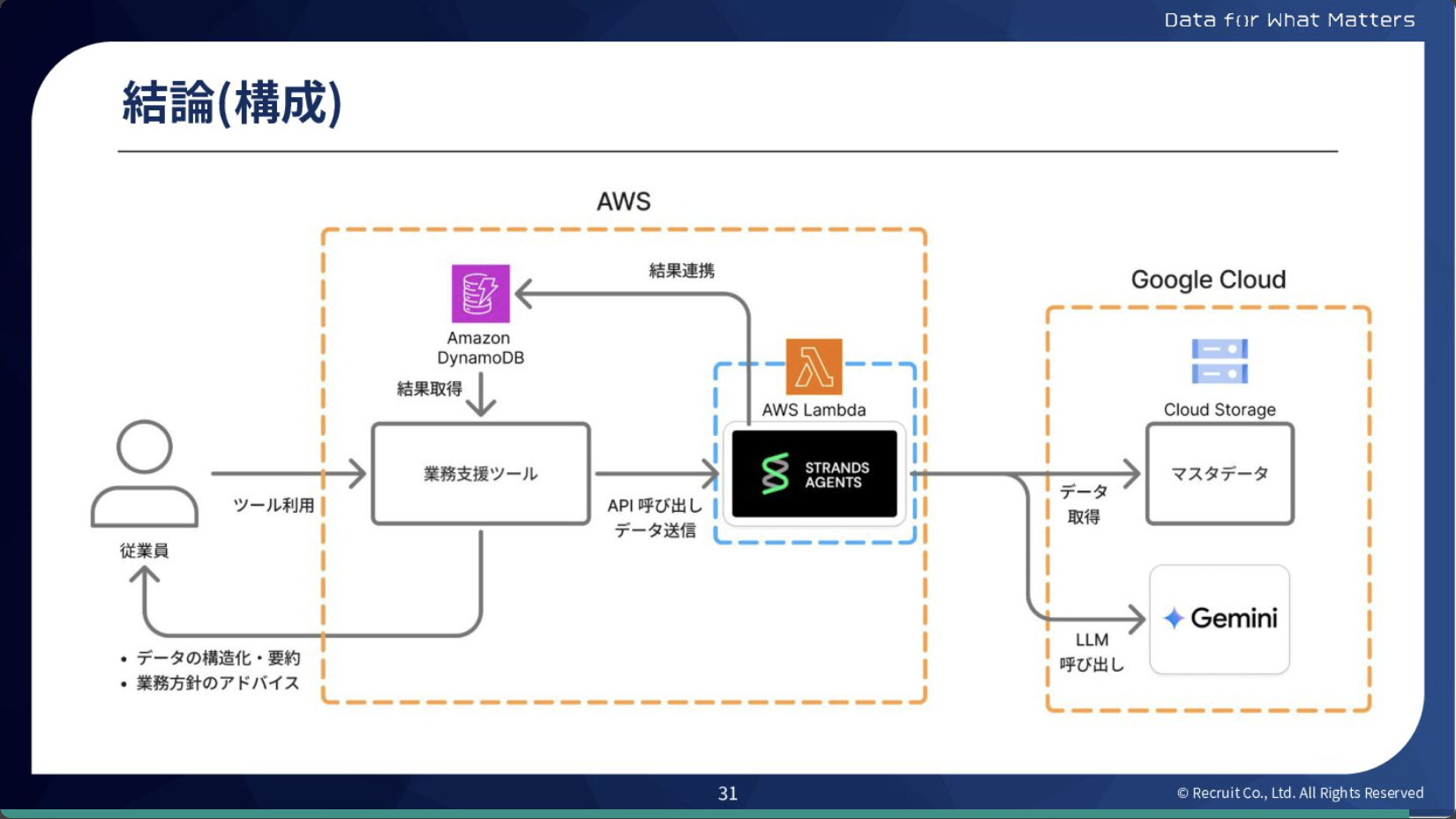
昨今のエージェントフレームワークは、主要なものだと基本的にメジャーな機能(※)が備わっているため、カスタマイズ性や思想に差異が出ることが多い傾向があります。 出力には大きな差異が出づらいため、「ケースやチームに合わせて柔軟に選択することが重要」だと勝俣は話しました。
2-3.事例紹介「AIエージェントによるプロダクト運用の自動化」
最後に、茅原より「AIエージェントによるプロダクト運用の自動化- 社内横断プロダクトCrois におけるAIOpsの実践」というテーマで事例をご紹介しました。
※詳細は
こちら
の記事でもご紹介しています。あわせてぜひご覧ください。
「Crois」とは、リクルート社内において、ワークフローエンジン・ジョブスケジューラ機能を提供する内製の横断プロダクトです。様々な事業領域から、機械学習/推論パイプライン/ETLジョブの実行基盤として利用されており、利用量も増加してきました。
このプロダクトの運用業務には「Slack上での利用者からの問い合わせやアラート対応」があり、クラウドインフラやソースコードを見に行かないと分からないことが多いため、運用側の負荷が増大しているという課題がありました。
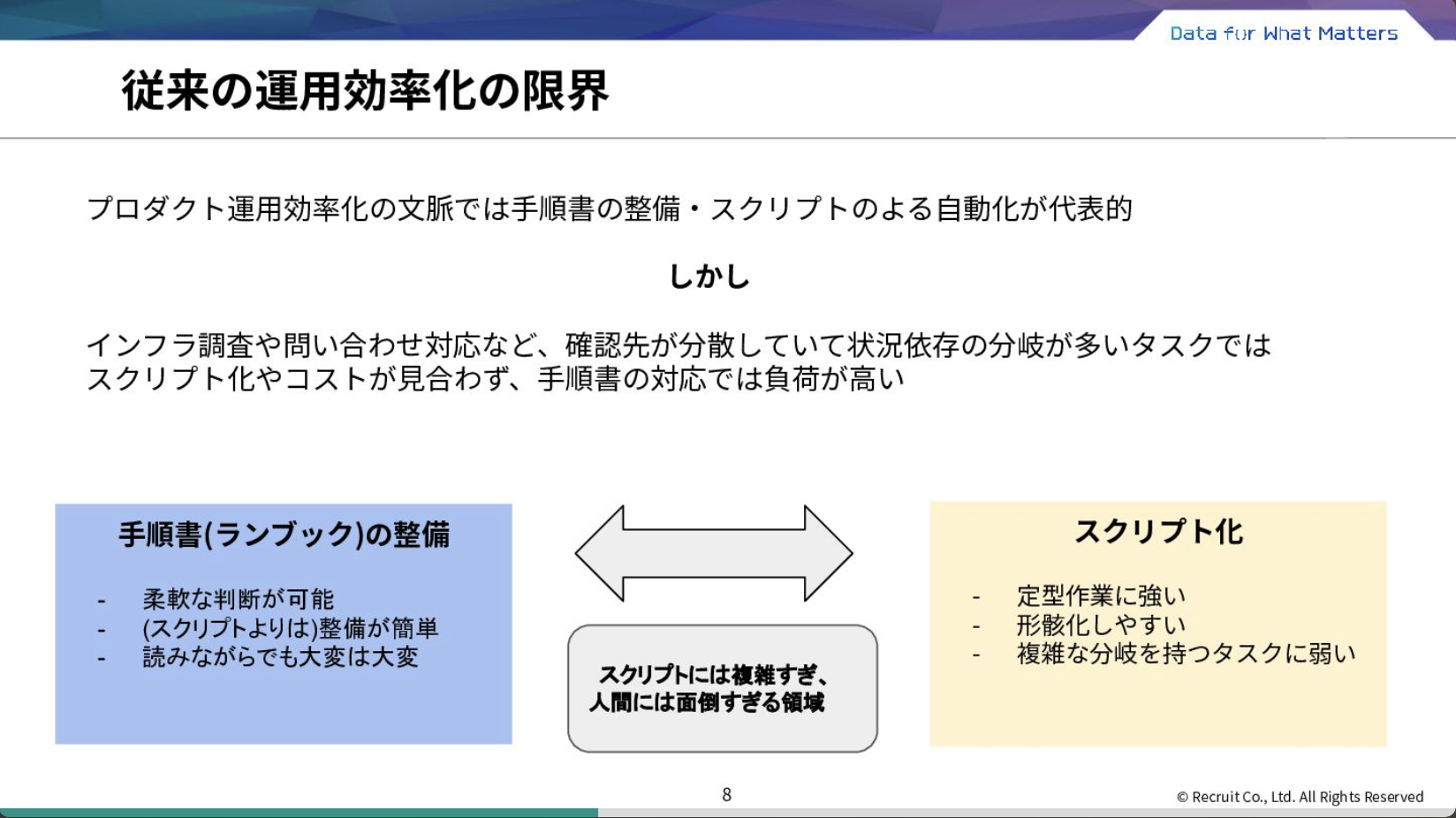
そこで、開発業務における「仕様書からコードを生成する」スキームを、運用業務における「手順書からオペレーションを生成する」プロセスに転用するという取り組みを行いました。こちらが実際に作ったCrois用の運用エージェント、通称クロサイの概観です。
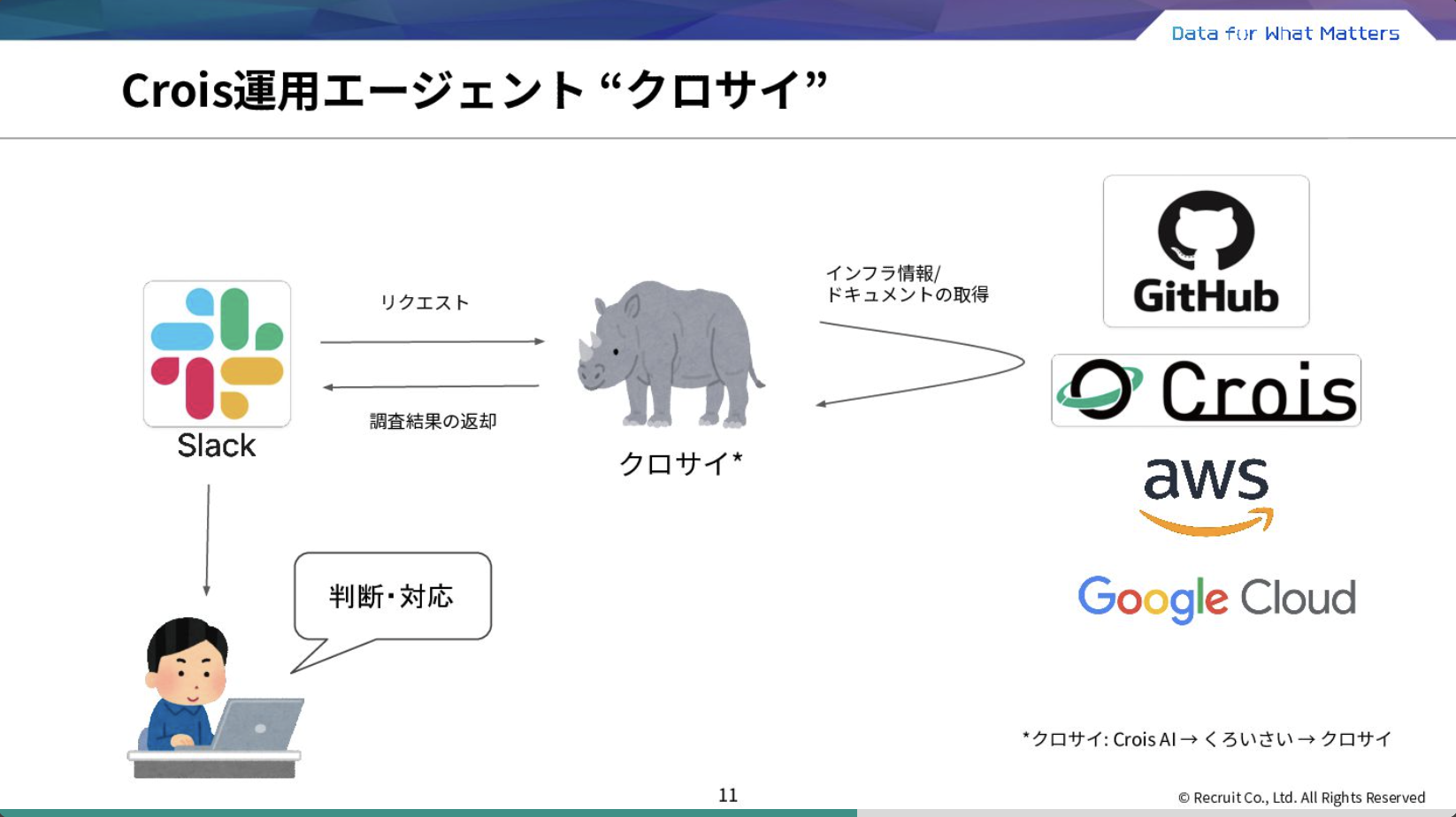
実際の対応例としては下記のようなものがあります。
- アラート対応
:クロサイがSlack上に発報されたアラートに反応し、関連するランブックを読み込み、手順に従ってAWS/GCPのログやリソースの状態を調査します。 - インフラ調査
:未整備のランブックや手がかりの少ない問い合わせに対しても、ソースコードやクラウドリソースを参照して自律的に調査を進めます。
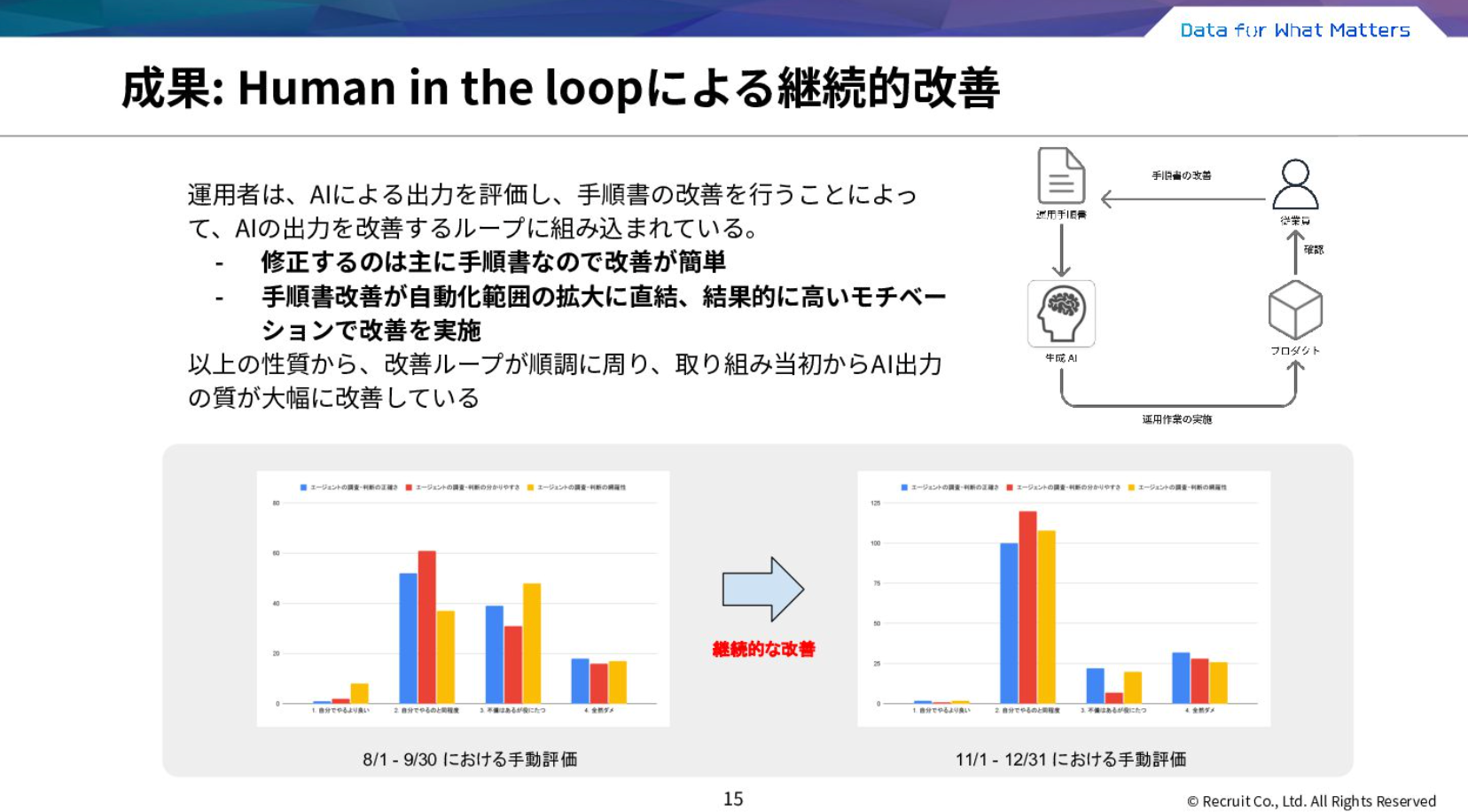
その結果、運用負荷の軽減とHuman in the loopによる継続的改善を実現できました。
- 運用負荷の軽減
:複数リソースを行き来する調査はAIが代行してくれるため、調査タスクの負担を軽減できます。また、全体の7割以上のアラートにおいて、人手による評価と同等以上の精度を達成しました。 - Human in the loopによる継続的改善
:運用者が「AIによる出力を評価し、自然言語の手順書を改善することでAIの出力を改善する」というループに組み込まれています。手順書の改善が自動化範囲の拡大に直結するため、改善ループが順調にまわり、取り組み当初と比較してAI出力の質が大幅に改善しています。
この事例における学びは「CroisのSRE文化とAIの親和性」が挙げられます。Croisには「toolでアクセスできる詳細情報(整備されたログ、メトリクス、アラート等のシステム監視)」と「集約されたガイドライン(地道に蓄積してきたランブック)」が既に存在していたため、AIが即戦力として機能したと言えます。
おわりに
最後には視聴者の方との質疑応答があり、非エンジニア向けにConfluence上でAIと壁打ちができる仕組みを構築している話も紹介されました。今後も、開発効率化から運用自動化まで「AI活用に関する試行錯誤」が最大のテーマになると考えられます。本イベントの内容が、少しでも参考になりましたら幸いです。
もう一度見たい&見逃してしまった方はぜひ、下記URLから録画や資料をご覧ください。
▼ 録画
https://youtu.be/SLowOCak2KE?si=GT_oWjVO6lFWQXiZ
▼ 資料
https://speakerdeck.com/recruitengineers/datesuishin-event-20260324-uetsu
https://speakerdeck.com/recruitengineers/datesuishin-event-20260324-katsumata
https://speakerdeck.com/recruitengineers/datesuishin-event-20260324-chihara