目次
はじめに
人材領域でデータ分析を担当している羽鳥です。Kaggleの Vesuvius Challenge - Surface Detection コンペにソロで参加し、1391チーム中12位で金メダルを獲得しました。
このコンペは古代の巻物を仮想的に展開して読み取るという、ロマンあふれるテーマでした。 また、今回自分で書いたコードはコンフィグファイルやドキュメント含め、正真正銘1行も無く、AIエージェントを活用することで開発効率を非常に高めることができました。
本記事ではコンペの解法とそれを支えたClaude Codeのskillsを紹介します。
コンペティションについて
タスク
西暦79年のヴェスヴィオ火山の噴火により、パピリ図書館の蔵書の多くは炭化した灰の塊となりました。約2000年経った今でも、多くの巻物は繊細すぎて物理的に開くことができません。そこで、CTスキャンから巻物内部のパピルスの層(シート)を検出し、仮想的に展開することで中に隠された文字を読み取ろうというプロジェクトが進められています。今回のコンペティションはその第一段階である「シートの表面検出(Surface Detection)」を対象としたものです。
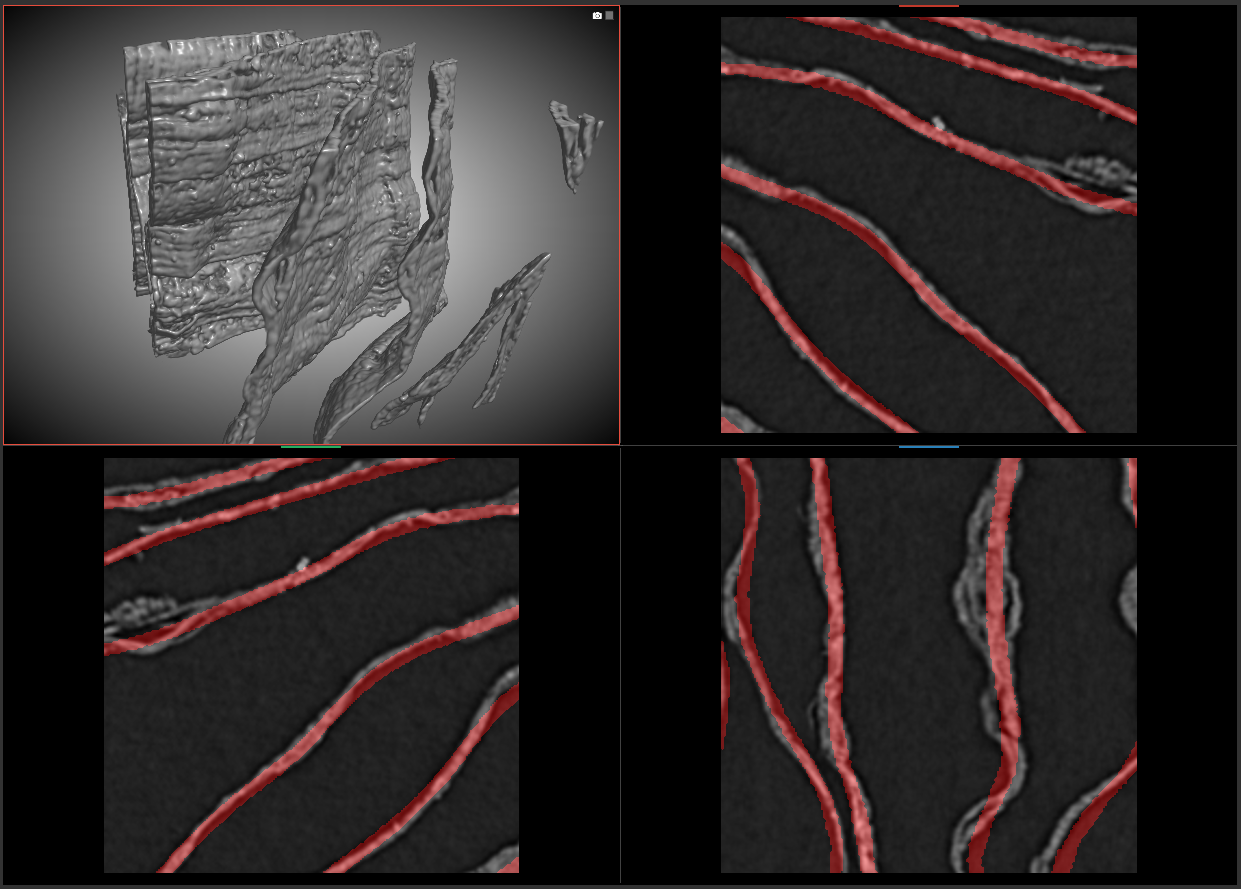
上の画像の左上はCTスキャンボリュームの3Dレンダリングで、パピルス断片の全体像を示しています。残りの3枚はCTスキャン断面の拡大図で、赤く着色された曲線状の部分がパピルスのシート(紙の層)です。このように何層にも密に重なったシートの1枚1枚を正しく識別・分離することがこのコンペの目標です。
データ
- 3DのCTスキャン画像(tif形式)の部分ボリューム
- ラベルマスク:0=背景、1=前景、2=ラベルなし
- ボリュームのサイズは固定ではなく、データごとに異なる
- 学習データ:約27GB、約1615ファイル
評価指標
CTスキャンの3Dボリュームの中には、巻物を構成する複数のシート(パピルスの層)が写っています。これらのシートを1枚1枚正しく分離してセグメンテーションできているかが評価の対象です。
以下の3つの指標の加重平均で評価されます。
Score = 0.30 × TopoScore + 0.35 × SurfaceDice@τ + 0.35 × VOI_score
| 指標 | 重み | 何を測るか |
|---|---|---|
| SurfaceDice@τ (τ=2.0) | 0.35 | 予測した各シートの表面が、正解の表面からどれだけ近いか(τ=2.0ボクセル以内なら正解とみなす) |
| VOI_score | 0.35 | シートごとの領域分割が正しいか。本来1枚のシートを2枚に分割してしまったり、逆に隣接する2枚のシートを1枚に統合してしまっていないかを評価 |
| TopoScore | 0.30 | 各シートの形状の構造(トポロジー)が保存されているか。穴の数や連結の仕方が正解と一致しているかを評価 |
巻物のシートは非常に薄く密に重なっているため、隣接するシート同士がくっついてしまったり、あるいはシートに穴が開くといった構造的なエラーが起きやすくなります。単純なボクセル単位のDiceスコアではこうしたシート間の構造的なエラーを検出できないため、シートごとの分離精度や形状の正しさも評価するこのような指標が採用されています。
見ての通り複雑な評価指標でした。それだけでなく評価そのものにもかなり時間がかかるため、学習の評価はpseudo Diceなどの別指標で行い、コンペ指標での評価は最後に行うという参加者が多かったように思います。
解法の概要
nnUNetをほぼデフォルト設定で使用した3Dセグメンテーションがベースです。詳細は Kaggle Discussion に記載していますので、ここではパイプラインの全体像とスコア推移を中心に紹介します。
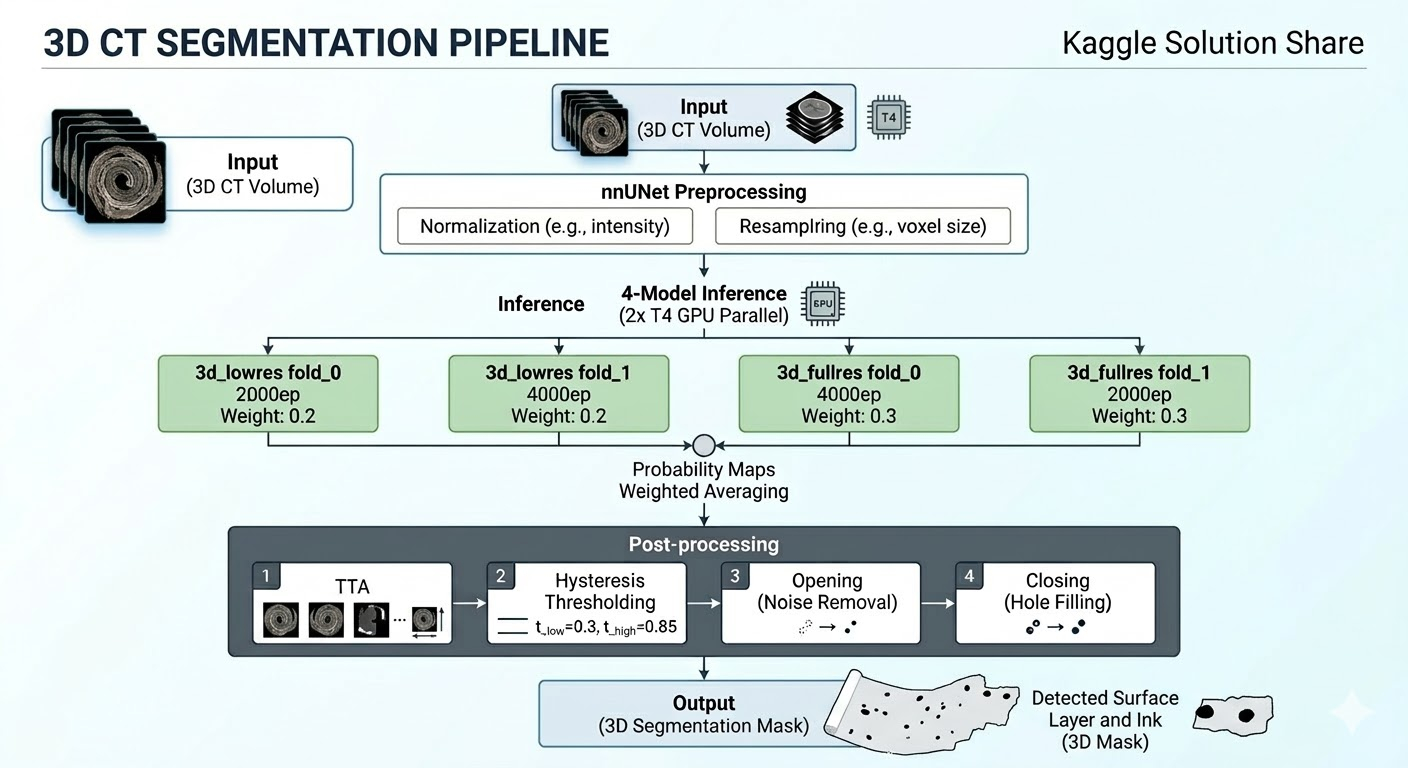
3D CTボリュームをnnUNetで前処理した後、lowres(低解像度)2モデルとfullres(高解像度)2モデルの計4モデルで推論し、確率マップを加重平均します。その後、TTA(推論時にデータを反転・回転させて複数回予測し平均を取る手法)・ヒステリシス閾値処理(高低2段階の閾値で判定し、ノイズを抑えつつ連続した領域を検出する手法)・Opening/Closing(微小なノイズ除去や穴埋めを行う形態学的処理)の後処理を経て、最終的な3Dセグメンテーションマスクを出力するパイプラインです。
ポイントは以下の2点です。これらについては後ほど説明します。
- lowres + fullresのアンサンブル:異なるスペーシング(1.56 mm / 1.0 mm)で異なるスケールをカバー
- 超long epoch training:最大4000エポックまで学習を延長
スコア推移
以下がざっくりとしたやったことに対してのスコア推移です。publicは多少増減あるものの、privateでは概ね一貫して改善していたようでした。
| ステージ | 変更内容 | Public | Private |
|---|---|---|---|
| ベースライン | 1000ep, 1モデル, argmax | 0.530 | 0.552 |
| +後処理 | ヒステリシス | 0.549 | 0.570 |
| +2-fold | fold_0+1 アンサンブル | 0.565 | 0.590 |
| +opening_closing | 後処理改善 | 0.565 | 0.593 |
| +2000ep | エポック数増加 | 0.568 | 0.593 |
| +fullres | fullres 2モデルのみ | 0.575 | 0.598 |
| +4モデル | lowres+fullres アンサンブル | 0.582 | 0.606 |
| +重み調整 | fullres 60%, lowres 40% | 0.583 | 0.605 |
| +TTA | 8方向ミラーリング | 0.584 | 0.607 |
| +4000ep | 最終提出 | 0.578 | 0.613 |
差別化ポイント:なぜこのアプローチが効いたのか
今回の解法で他の参加者との差別化に繋がったと考えているのは、fullres + lowresのアンサンブルと超long epoch trainingの2点です。
fullres + lowresのアンサンブル
上位チームの解法を見る限り、fullresとlowresを混ぜてアンサンブルしている人はほとんどいなかったようです。 私は以下の設定でfullres・lowresのモデルを学習し、アンサンブルを行いました。
| 3d_lowres | 3d_fullres | |
|---|---|---|
| パッチサイズ | 128³ | 128³ |
| 画像サイズ | 205³ | 320³ |
| スペーシング | 1.56 mm | 1.0 mm |
| 実効視野 | ~200³ mm³ | ~128³ mm³ |
ここでパッチサイズは実際にネットワークに入力される3Dクロップのサイズで、2D画像が大きいときに切り取りを行うクロッピングに相当するものです。
fullresとlowresで画像サイズを事前に変えているため、同じ大きさのパッチサイズであってもモデルが実際に見る領域としては「fullresは細部を狭く・lowresはざっくり広く」といった感じになります。
上位チームのソリューションではパッチサイズを変えることでこの辺りの多様性を確保するソリューションが多かったようですが、私の採用した方法だと実際にモデルに入力するパッチサイズが固定のため、GPUメモリの消費量が抑えられるというメリットがあります。
アンサンブルの重みはvalidationに対するCVスコアをベースにざっくりと探索し、fullres 60%、lowres 40%に設定しました。 実際にスコア推移の表を見ると、fullres単体(Private 0.598)よりも4モデルアンサンブル(Private 0.606)で大きく改善しており、このあたりの判断は正しかったと言えそうです。
超long epoch training
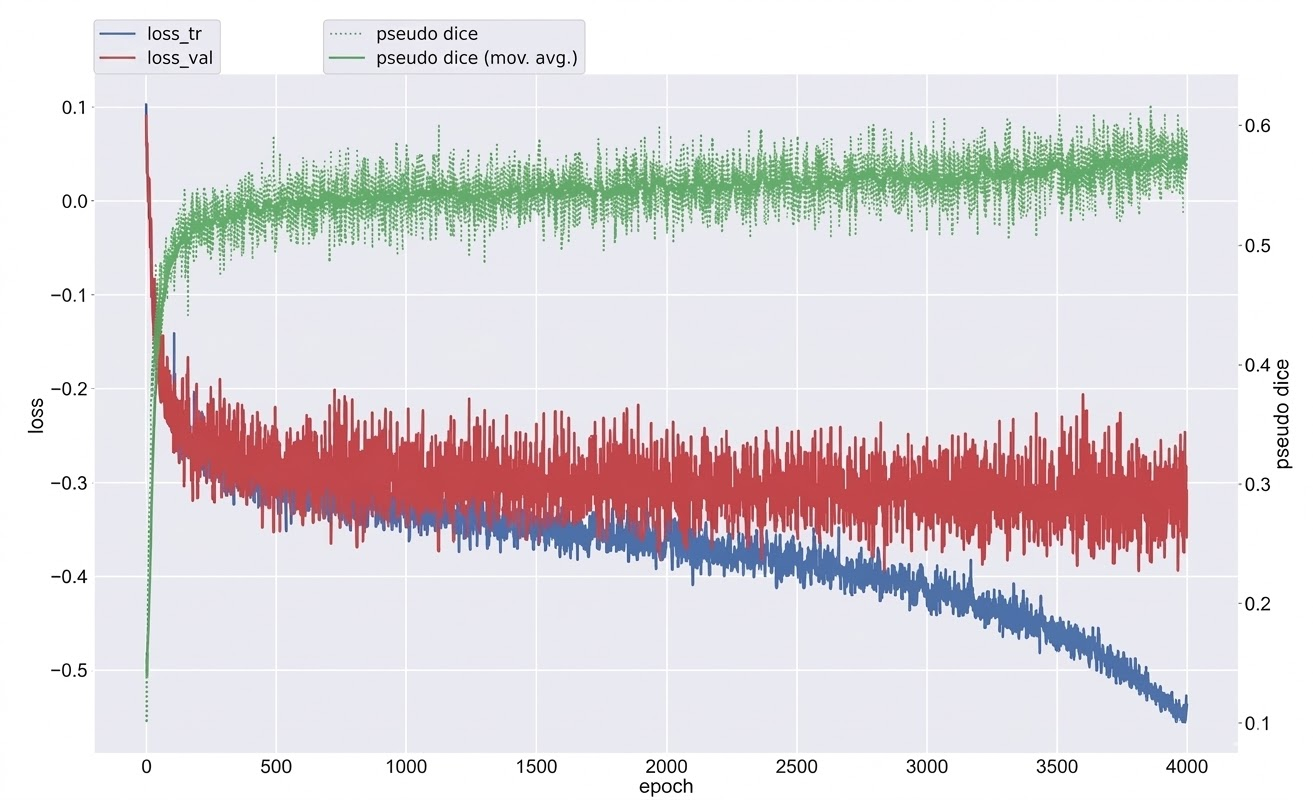
nnUNetのデフォルトは1000エポックですが、最終的に一部のモデルは4000エポックまで学習を延長しました。 1000エポック時点でtrain lossとvalidation lossの乖離が小さく、まだモデルの学習に余裕がありそうだと感じたのがきっかけです。 また、過去のコンペから「同じvalidation lossであれば、train lossがより低い過学習傾向のモデルの方がアンサンブル時に効きやすい」という経験則がありました。
実際に1000エポック、2000エポック、4000エポックの学習ログを見てみると、エポックが大きくなればなるほどvalidation dice scoreは同程度ですがtrain lossは小さくなっているようでした。
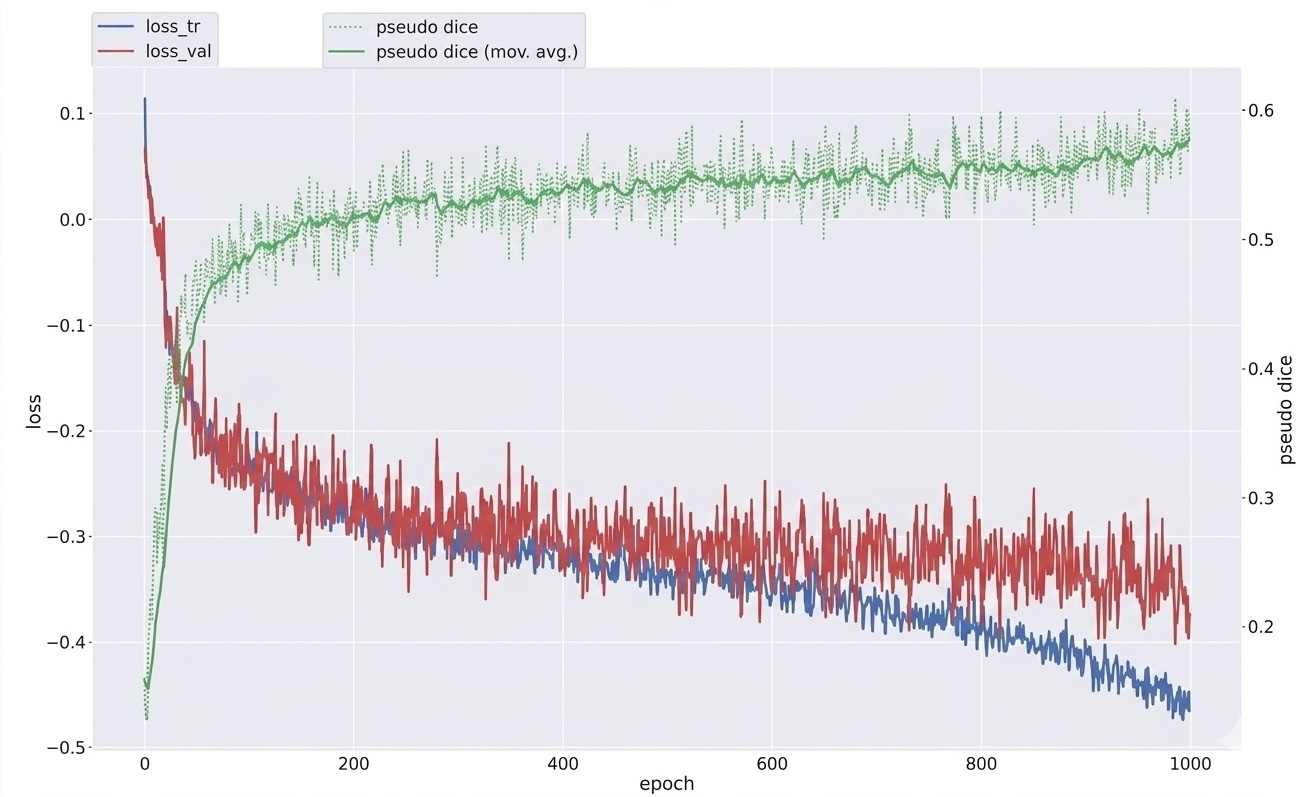
|
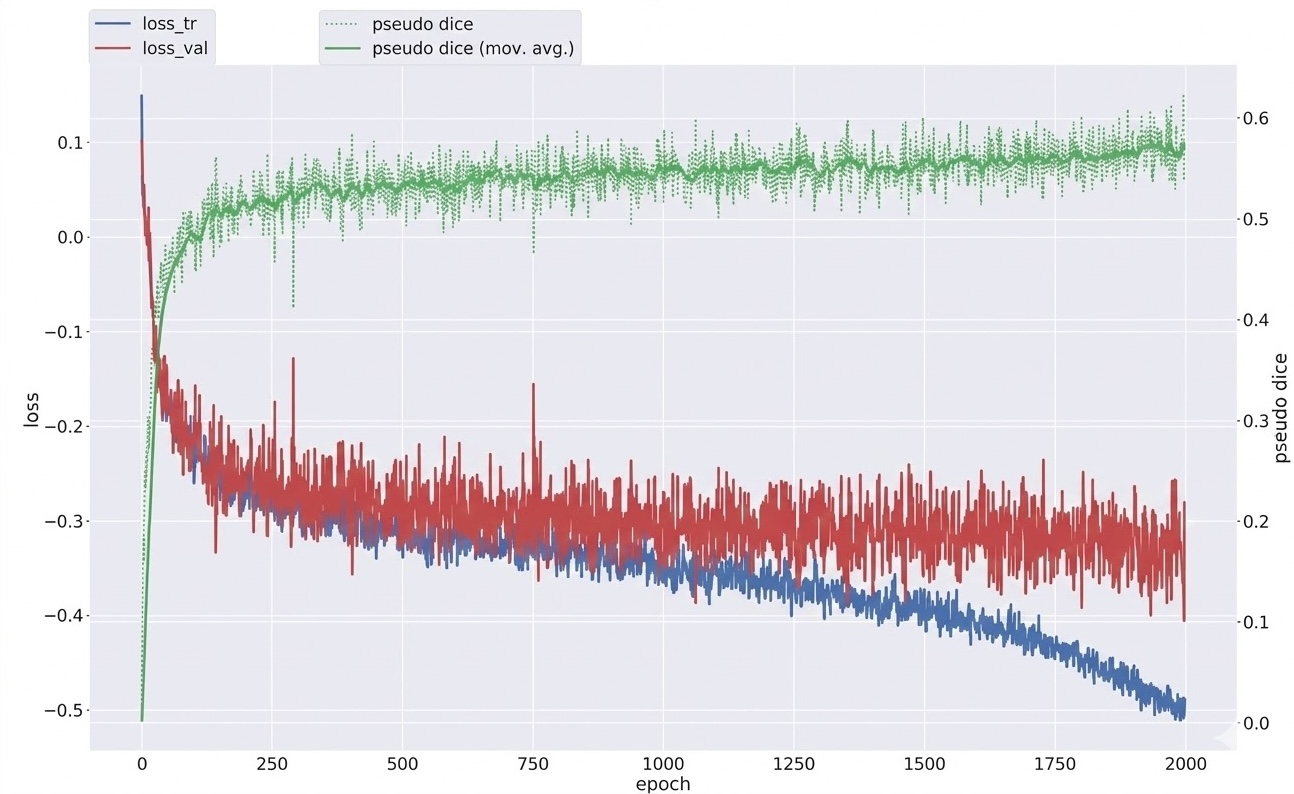
|
|
上記の図から分かる通り、4000エポック時点ではtrain lossとvalidation lossの乖離は出始めていたものの、validation loss自体はまだ下がり続けていました。時間が許せば8000エポックまで伸ばし、さらにfold_0〜fold_4まで全foldで学習できていれば、もう一段スコアを伸ばせていたのではないかと思います。
実際、上位チームもlong epoch trainingの有効性を示しています。 1位チーム はベースモデルを4000エポック学習させており、 3位チーム に至ってはlowres 8000エポック + cascade 8000エポックという構成で最高スコアを達成しています。このコンペでは、長く学習させることがスコア改善に直結していたと言えそうです。
Claude Codeのskillsを活用した開発効率化
今回のコンペでは、 Claude Code のskills機能を積極的に活用しました。skillsとは、よく行う操作を定型化してClaude Codeに覚えさせる仕組みです。コンペ中に繰り返し発生するタスクをskillとして定義しておくことで、毎回ゼロから指示する必要がなくなり、開発サイクルが大幅に速くなりました。
例えば、submitした後の時間測定ひとつ取っても、docker環境を使ってくれなかったり、指定のフォーマットでログを保存してくれなかったりと、都度指示すると細かいところで齟齬が生じがちです。skillとして手順を定義しておけば、こうした「暗黙の前提」を毎回正確に再現してくれるので非常に助かりました。
以下、今回作成したいくつかのskillを紹介します。
submit後の時間測定skill
Kaggleのコードコンペでは、notebookをsubmitした後に採点が完了するまで数時間かかることがあります。その間にスコアや実行時間を手動で確認しに行くのは面倒ですし、結果を記録し忘れることもあります。
そのためにスクリプトを作って実行時間を計測するということ自体はよく行われていると思いますが(参考: currypurinさんの有名なコード )、AIエージェントにお願いすると前述のように意外と細かいところで意図せぬ挙動をしがちです。このskillはそれを助けるためのものになっています。
このskillは /submit exp002_fold0 のように実験名を指定して呼び出すと、採点完了を自動で監視し、実行時間とLBスコアをログファイルに記録してくれます。
---
name: submit
description: Monitor Kaggle submission until scoring completes. Usage: /submit exp002_fold0
---
# Monitor Submission
Kaggle提出の採点完了を監視し、実行時間とLBスコアをログに記録する。
## 引数
- `name`: 実験名 (例: `exp002_fold0`)
## 手順
1. **監視スクリプトを起動**
source .venv/bin/activate && nohup python logs/monitor_submission.py <name> >> logs/submission_<name>.log 2>&1 &
2. **ユーザーへ報告**
- 監視開始したことを報告
- `tail -f logs/submission_<name>.log` で結果を確認できることを伝える
## 出力
- ログファイル: `logs/submission_<name>.log`
- 採点完了時: `[<name>] run-time: X min, LB: Y.YY`
skillの中身自体はシンプルですが、ポイントは「仮想環境で監視スクリプトを起動する」「リモートで起動しているClaude Codeが落ちてもいいようにnohupで実行する」「指定のフォーマットでログを残す」といった手順が固定されている点です。skillなしで毎回指示すると、仮想環境のactivateを忘れたり、ログのファイル名がバラバラになったりしがちですが、skillとして定義しておけばそうした細かいミスがなくなります。
コードレビュー用skill
コードを変更するたびに /review と打つだけで、コンペ固有の観点を踏まえたレビューを受けられるskillです。レビュー観点にはKaggleのコードコンペ特有の制約(9時間の推論時間制限、GPUメモリ16GB)や、今回のコンペ固有のnnUNet設定・後処理の整合性チェックなどを盛り込んでいます。
---
name: review
description: コードレビューを実行し、問題点や改善提案を提示する
---
# コードレビュースキル
あなたはコードレビューの専門家です。以下の観点でコードをレビューしてください。
## レビュー対象の決定
引数が指定された場合:
- ファイルパスの場合: そのファイルをレビュー
- ディレクトリの場合: そのディレクトリ内の変更をレビュー
- `HEAD~N` や `branch..branch` の形式: git diffでその範囲をレビュー
- `staged` または `--staged`: ステージングされた変更をレビュー
引数が指定されない場合:
- `git diff --staged` でステージングされた変更を確認
- ステージングがなければ `git diff` で未ステージの変更を確認
- どちらもなければユーザーに確認
## レビュー観点
### 推論効率(Kaggle環境制約)
- **時間制限**: 推論が9時間以内に完了するか.より効率的な処理は無いか
- **メモリ制限**: GPU 16GB / RAM制限内か。メモリ効率は最高か。メモリリークはないか。
- **バッチサイズ**: OOMを避けつつ効率的か。
### コードの堅牢性
- **エラーハンドリング**: 推論中の例外で全体が落ちないか
- **型の不整合**: numpy/torch、float32/float64
- **境界条件**: 空データ、エッジケース
### Vesuvius固有
- **nnUNet設定**: Trainer, Plans, Configの整合性
- **後処理**: hysteresis, opening/closing の適切な適用
- **評価指標**: TopoScore, SurfaceDice, VOI_scoreの計算
- **3Dボリューム処理**: パッチ分割・統合の正確性
- **step_size/overlap**: 推論時のオーバーラップ設定
### 提出パイプライン
- **Kaggle Notebook互換**: オフライン実行可能か
- **データセットパス**: `/kaggle/input/` のパス構造
- **出力形式**: submission.csvのフォーマット
- **依存関係**: 必要なパッケージがすべて含まれているか
## 出力フォーマット
## レビューサマリー
[全体的な評価と主要な懸念点]
## リーク警告(該当する場合)
[データリークの可能性がある箇所を最優先で報告]
## 問題点
### [Critical/High/Medium/Low] ファイル名:行番号
[問題の説明]
[修正案]
重要度の目安:
- Critical: リーク、結果が無効になる問題、推論が動かない
- High: スコアに大きく影響、OOMリスク
- Medium: スコアに軽微な影響、保守性の問題
- Low: スタイル、可読性
## CV/LBへの影響
[変更がCVスコアやLBスコアに与える影響の予測]
## 改善提案
- [任意だが推奨される改善点]
## Good Points
- [良い点があれば記載]
## 注意事項
- 建設的なフィードバックを心がける
- 修正案は具体的なコードで示す
- 重要度に応じて優先順位をつける
- このプロジェクトのCLAUDE.mdの規約に従う
特にコードコンペでは、推論パイプラインのちょっとしたミス(パスの間違い、メモリリーク等)がsubmit後に数時間待ってから発覚するということが起こりがちです。事前にレビューで潰しておけるのは大きな時間の節約になりました。 またこのskillでは明らかなバグだけでなく、学習や推論の効率性にも踏み込んでレビューしてくれるため、パフォーマンス向上に大きく寄与しました。
Kaggleディスカッション整形skill / notebookダウンロードskill
今回のコンペには後半から参加したため、すでにdiscussionやpublic notebookが充実している状態でした。こうした先行情報をいかに効率よくキャッチアップするかが、コンペ序盤の方向性を決める上で非常に重要でした。
そこで、以下の2つのskillを作成しました。
-
ディスカッション整形skill:ブラウザの開発者ツールからコピーしたKaggleディスカッションのHTMLを、メタ情報(著者、投票数、日付)を保持したまま整形されたテキストファイルに変換し、
docs/discussions/に保存するskillです。ハイパーリンクやコードブロックの情報も残るので、後から検索・参照しやすくなります。 - notebookダウンロードskill:Kaggle APIを使って投票数の多いnotebookを一括でダウンロードし、未取得のものだけを差分更新するskillです。
これらのskillで重要なdiscussionやnotebookをローカルに蓄積しておくことで、Claude Codeのコンテキストに含めて「このdiscussionの手法を自分の実装に取り入れるにはどうすればいい?」といった質問ができるようになります。コンペの方向性を決める初期のリサーチフェーズで特に威力を発揮しました。
おわりに
非常に強力なnnUNetのデフォルト設定をベースに、lowres/fullresのアンサンブルとlong epoch trainingによって、12位・金メダルを獲得することができました。
また、Claude Codeのskillsを活用することで、コンペ中の反復的なタスクを効率化し、高い生産性を維持できました。 もはやAIエージェントを効率的に活用することは今後のKaggleにおいても非常に重要な要素になっていく可能性を強く感じました。
冒頭にも書きましたが、今回は古代の巻物を読み取るという、ロマンあふれる大変興味深いテーマでした。また、学習データも大きすぎず小さすぎず、ローカルのCVスコアが比較的素直にLBに反映される素晴らしいコンペだったと思います。今後もこのような面白いコンペに積極的に参加していきたいと思います。