目次
はじめに
こんにちは、データ推進室データマネジメント部でアナリティクスエンジニアをしている椎名、平野、町塚です。
私たちの所属しているデータマネジメント部では、メンバー間の情報共有とコミュニケーションの活性化を目的に、定期的にライトニングトーク会(以下「LT会」)を開催しています。
先日開催された第3回のLT会では、先輩方の発表に加え、私たち新卒社員3人も登壇させていただきました!
本記事では、その当日の様子を、新卒の発表内容に焦点を当ててご紹介します。

AE LT会について
AE LT会とは、「Analytics Engineer Lightning Talk会」の略称です。リクルートグループには、HR、住まい、自動車、美容、飲食、まなびといった多岐にわたる事業の最前線で活躍するアナリティクスエンジニア(AE)が数多く在籍しています。しかし、それぞれの現場で生まれる貴重なノウハウや学びは、組織が異なることで共有されにくいという課題もありました。
そこで、組織の垣根を越えて知見を交換し、AE同士の横のつながりを強める場として生まれたのが、このAE LT会です。「ナレッジシェアの促進」と「コミュニティ形成」を大きな目的としています。
この想いから始まったAE LT会も、今回で3度目を迎えます。これまでの会を振り返ると、
- 第1回では、データマート開発のTipsからメタデータ管理まで、AEの業務の幅広さを示す多様なテーマが共有され、大きな反響を呼びました。
- 第2回では、LLMを活用したSQL生成の効率化など、より先進的なトピックが注目を集め、技術的な議論がさらに深まりました。
そして迎えた第3回。回を重ねるごとにコミュニティとしての熱量はますます高まっています。
今回も前回に引き続きハイブリッド形式で開催し、オフライン会場の熱気とオンラインのコメントが融合する、活気あふれる会となりました。
そんな今回のLT会では、今年4月に新卒入社した私たち3名も登壇しました。入社からの約半年、それぞれの部署でどんなテーマで業務に臨み、どのような学びを得たのか発表しました。
LT会の内容について
全体と個人の2パートに分けて発表しました。
全体パート
「実務で必要だったスキル」というテーマで、新卒の“曇りなき眼”だからこそ話せる内容を共有しました。経験豊富な先輩方が忘れがちなフレッシュな視点を呼び戻すことができたのではないかと思います。

AEとして必要な業務知識はビジネス面の理解も含め多岐に渡りますが、今回は技術的な側面に絞って、私たちが「初期装備」として必要だと感じた3つのスキルセットについて発表しました。
-
開発者としての基礎スキル
- Git/GitHub: コードのバージョン管理はもちろん、チームメンバーとの円滑な情報共有の基盤としても重要でした。
- Linux基礎コマンド: 日常の開発において、基本的なコマンド操作はスムーズな業務遂行に欠かせません。
-
データ分析者としてのスキル
- 実践的SQL: 句の実行順序の理解、Window関数やCTEといったテクニックは、複雑なデータ抽出・分析の基礎でした。
- BigQueryの深い知識: BigQuery特有のデータ型への理解や、スロットの概念に基づいたコスト意識は、パフォーマンスと効率を両立させる上で重要でした。
-
データモデリングのためのスキル
- dbt: dbtにおけるStaging/Intermediate/Martといったレイヤー構造や、差分更新を実現するIncremental modelの概念の理解が、マート開発に必要でした。
- データモデリング: 主にスタースキーマについての理解が重要でした。ファクト(事実)テーブルと、それに関連する複数のディメンション(属性)テーブルでデータを構成するという概念に慣れが必要でした。

さらに、これらの内容の中には新人導入研修に含まれないものも多かったため、「AE新卒元年」の私たちがフィードバックすることに価値があると考えました。そこで発表の最後には、来年度の新人が「強い装備」でスムーズにスタートできるよう、必要なスキルの体系化と人事へのフィードバックといった取り組みを進めていることも共有しました。
個人パート
平野パート: 安全安心の料理(Mart層)には素材(Staging層)の産地・生産者情報(Metadata)が大事

AEの管理するアウトプットの一つであるMart層を「料理」とすると、その「料理」が安心安全であるためには、「食材」(Staging層)の品質情報(メタデータ)が不可欠です。今回は、そのStaging層に対するメタデータの拡充を行い、後続・下流への自動伝播の仕組みの改善に取り組みました。
メタデータの充実度と管理体制を明確にし、すでに導入されている自動充填の質を高めることを目的として取り組みました。Mart層から遡って、事業的優先度の高い対象テーブルを特定し、オーナー・メンテナーの明確化、テーブル定義書の作成を行いました。さらに、Cursorを活用して定義書の内容をdbtのYAMLファイルへ効率的に入力する手順を確立し、実装を進めました。
その結果、BigQuery上でテーブルやカラムの詳細情報を一元的に確認できるようになり、データ異常発生時のリードタイム削減に貢献しました。また、データ組織・開発組織におけるメタデータ管理への意識向上という副次的な効果も生み出し、新規テーブル作成時のルール作りへと繋がっています。
町塚パート: 秘伝のタレ(クエリ)をオンプレからクラウドに移し替えよう
現在住まい領域では一部のマート作成バッチ処理をオンプレミス環境にて運用しています。今回の案件では事業運営に不可欠な指標を可視化しているTableauが参照するバッチ処理を対象に、サービスの更新に合わせて実行基盤をクラウドへ移行するものでした。

配属から数ヶ月の「初期装備」状態で舞い込んできた突然の案件に戸惑いながらも、メンターや先輩方に話を聞き、案件の概要を整理するところからスタートしました。開発を進める中で、古く長いクエリの理解、初めて触れるシェルスクリプトやYAMLファイル、さらに長年活用されてきたゆえに文書化が十分でない部分があり、まさに「秘伝のタレ」ならではの壁が多く立ちはだかりました。過去の経緯はチーム内でも確認が難しい場面がありましたが、とにかくメンバー、ひいてはベンダーの方々までをも巻き込み、質問を投げ続けることで一つずつ課題をクリアしていきました。
その結果、約2ヶ月間でSQLファイルを整理・移行し、ワークフロー開発を完了させることができました。初期装備が十分でない状態からでも、概要の整理、周囲を巻き込んだ開発、そして徹底した質問が、この「秘伝のタレ」をオンプレからクラウドへ移し替える成功の鍵となったと感じています。
一方で、ドキュメント作成やテスト体制の課題も感じたため、将来このシステムを触る方々が困らないようにドキュメント整備なども進めていきたいと考えています。今回の経験を糧に、リリースまで、そして下半期のタスクにも全力で取り組みます!
椎名パート: Microbatchで実現する、速度・コスト・運用性を兼ね備えたモデリング
私がHR領域のAEとして配属後すぐに直面したのは、大規模データに起因する日次マート更新の課題でした。HR領域には数TBにもなる巨大なテーブルが多数存在します。通常のモデリング(Materialization: table)で実装されたマートでは、更新時にBigQueryの6時間制限によるタイムアウトや、他のクエリ実行を妨げるスロット消費が発生していました。

この問題を解決するため、「Microbatch Incremental Model」(以下 Microbatch)を導入しました。Microbatchは、大規模な時系列データを効率的に処理するために設計されたモデルです。日単位などの特定の時間単位で区切って、必要な範囲のデータだけを更新することができます。
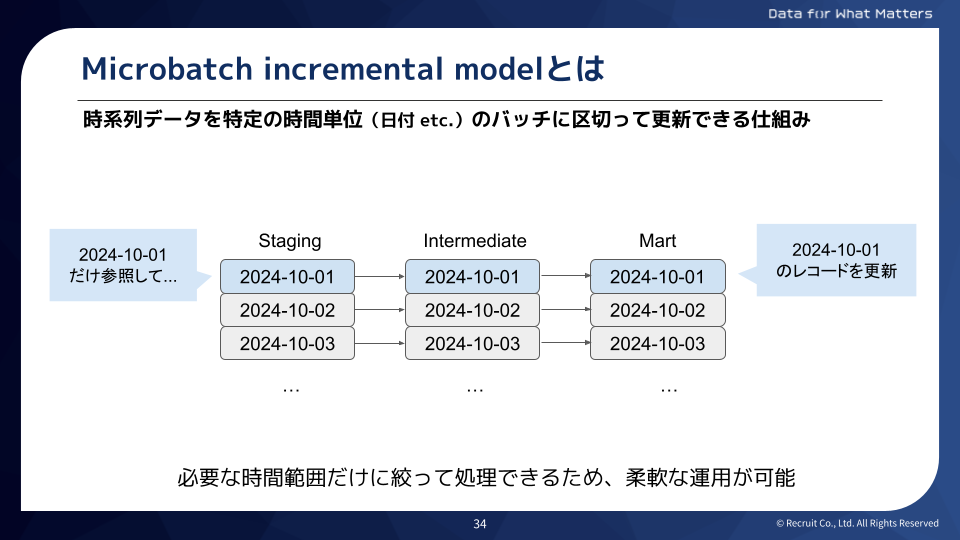
Microbatch導入により、以下のように更新パフォーマンスが劇的に改善し、速度・コスト・運用性を兼ね備えたモデリングが実現できました。
- 速度: 実行時間は240分以上から約2分に短縮。必要な日付範囲のデータのみを処理するため高速化を実現できました。
- コスト: スロット消費量が28,000 スロット分以上から5 スロット分未満に激減。スキャン量も1.5TB超から1GB未満となり、コスト削減に貢献しました。
- 運用性: 特定の時間範囲だけを更新できるため、過去遡及を任意の期間で簡単にできるようになり、柔軟な運用が可能になりました。

最後に
LT会が終わった後も、発表者である私たち新卒3人には、多くの先輩方から温かいフィードバックや質問をいただくことができました。組織の垣根を越えた議論に加わり、新卒として非常に貴重な経験となりました。
正直、発表前は不安でいっぱいでしたが、この経験は私たちに大きな達成感と、AEとしての確かな一歩を踏み出せたという自信を与えてくれました。これからも頑張ります!