目次
こんにちは。
4月から新卒駆け出しインフラエンジニアとして日々奮闘しております河合です。
"モバイル行動ログ収集基盤" を "小さく" 始めたので、以下にインフラ構築からモバイルまでの設計までをまとめたいと思います。今回このログ収集基盤を作るにあたって私自身がこれまで経験したことのない技術・ツールを利用しましたので、それらの導入についてもご紹介いたします。
導入の背景
私は英単語サプリを中心にインフラを担当しています。
英単語サプリとは、聞ける・話せる・覚えてるをコンセプトとした高校受験からTOEICまで対策できる英単語学習のサービスです。

ユーザの分析によく使われるツールの1つにGoogle Analytics(以下、GA)があります。
私が所属しているチームでは、GAにおける緻密な設定をすることで多種多様なユーザの分析を行っています。
しかし、
「あるユーザは、ある単語をどれほど考えて正解 or 間違えたのか」
「あるユーザは、どこでいつ最後に離脱したのか」
「あるユーザは、初回離脱後の二回目に何をしたのか」
といった、モバイルアプリにおけるユーザの個の特性を追うとなると、GAだけでは難しかったりします。
また、このようなユーザの行動ログを取得することでユーザがよく間違える単語の傾向等を判定することに役立てています。
そこで、今回は独自でモバイル行動ログ収集基盤を小さく作るところから始めました。
全体構成
モバイルからインフラまでの構成は以下のようになります。
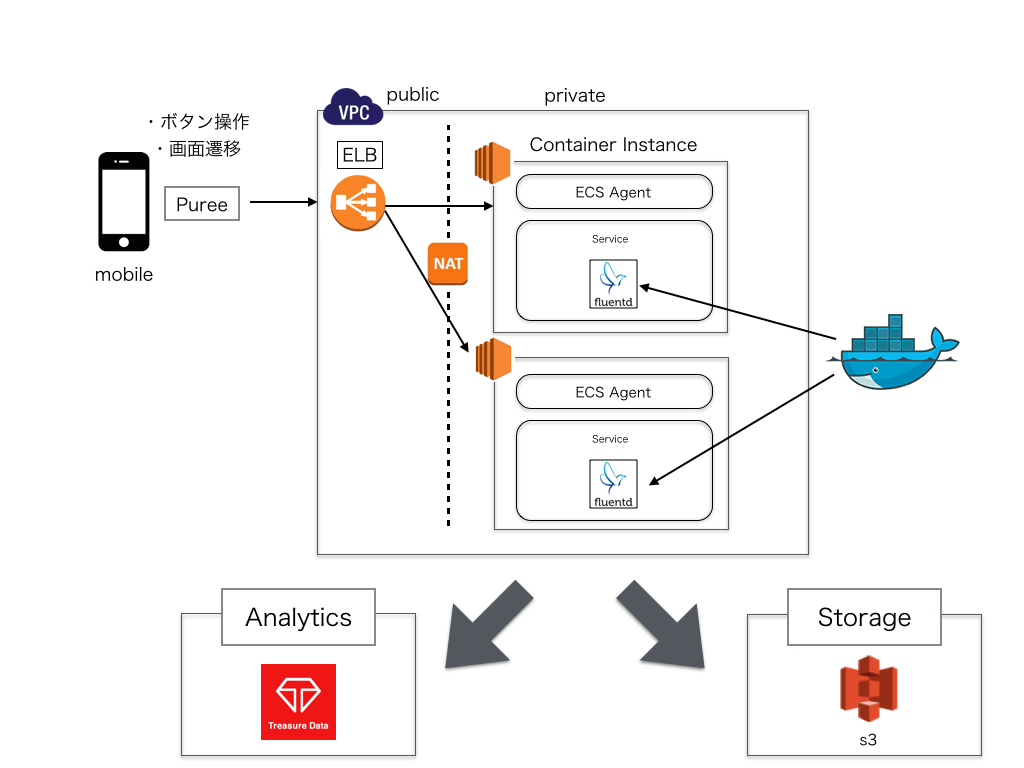
以下にそれぞれ使ったツールとその使い方をご紹介します。
使ったツール・OSS
インフラ
モバイル行動ログ収集基盤は、全てAWSで完結するようにしました。AMIの作成はPackerで行い、VPC・ELB・EC2におけるインフラ構成要素は、全てTerraformでテンプレート化するようにしました。
Packerとは、仮想マシンのイメージ作成を行うためのツールです。Terraformとは、インフラ構成をテンプレートファイルとして記載し、AWS等のクラウド環境に反映するためのオーケストレーションツールです。
Packerを使ってAMIの作成
Packerを使ってAMIを作成するサンプルを以下に示します。
{
"variables": {
"aws_access_key": "YOUR_ACCESS_KEY",
"aws_secret_key": "YOUR_SECRET_KEY",
"instance_type": "インスタンスタイプ",
"source_ami" : "指定したAMI"
},
"builders": [{
"type": "amazon-ebs",
"access_key": "{{user `aws_access_key`}}",
"secret_key": "{{user `aws_secret_key`}}",
"region": "ap-northeast-1",
"source_ami": "{{user `source_ami`}}",
"ssh_username": "ec2-user",
"instance_type": "{{user `instance_type`}}",
"ami_name": "ecs optimized {{timestamp}}",
"security_group_ids": ["セキュリティグループのID"],
"subnet_id": "VPCのサブネットID",
"ami_block_device_mappings": [
{
"device_name": "/dev/xvda",
"volume_size": 100,
"volume_type": "gp2",
"delete_on_termination": true
}
]
}]
}
$ packer validate example.json
$ packer build example.json
たったこれだけで指定したAMIが生成されます!
packerを使えば、このようにJSONで書いた設定ファイルをコマンド実行するだけでAMIを作成することが出来ます。この作成したAMIのIDを毎回調べるのは面倒ですので、生成後にAMIのIDを吐き出したものをファイルに保存することで、AMIのIDを管理するようにすると便利です。
Terraformを利用したインフラ構築のテンプレート化
今回のログ収集基盤では、VPC、ELB、Route53、ECS用インスタンスまで全てTerraformでテンプレート化しました。
例として、Terraformを利用したELBのテンプレートファイルの例(elb.tf)を以下に示します。
resource "aws_elb" "log-aggregate" {
name = "log-aggregate"
subnets = ["${var.pub_region_a}", "${var.pub_region_c}"]
security_groups = ["${var.sg_ssh}", "${var.sg_dev}"]
internal = false
listener {
instance_port = 8888
instance_protocol = "http"
lb_port = 443
lb_protocol = "https"
ssl_certificate_id = "${var.ssl_tracer}"
}
health_check {
healthy_threshold = 2
unhealthy_threshold = 2
timeout = 5
target = "TCP:8888"
interval = 10
}
cross_zone_load_balancing = true
}よく利用する変数等は、別ファイルにして管理しておくのが良いでしょう。
variable "aws_access_key" {}
variable "aws_secret_key" {}
variable "ami" { default = "" }
variable "prod" {
default = {
sg_ssh = "セキュリティグループID_1"
sg_dev = "セキュリティグループID_2"
pub_region_a = "サブネットID_1"
pub_region_c = "サブネットID_2"
priv_region_a = "サブネットID_3"
priv_region_c = "サブネットID_4"
ssl_tracer = "◯◯◯◯◯◯◯"
}
}
provider "aws" {
access_key = "${var.aws_access_key}"
secret_key = "${var.aws_secret_key}"
region = "ap-northeast-1"
}以下のコマンドを実行して反映します。
$ terraform plan # 差分チェック
$ terraform apply # 反映
初めて使ってみた感想としては、planでインフラ構成の差分がチェックすることが可視化されるところはすごくいいなぁと思いました。
ただし、terraform.tfstateファイルのチーム間で正しく管理し、現状と本番との差分がない最新の状態をきちんと保持する仕組みを考える必要がありそうです。
fluentd経由でログ収集ができるコンテナの作成
ログ収集を行うみんな大好きfluentdのDockerコンテナを作成し、それらを全てAmazon EC2 Container Service(ECS)で動かすようにしました。
fluentd経由でログ収集ができるコンテナを作成するのに必要なファイルは、以下の2つです。
├── Dockerfile
└── config
└── td-agent.conf
fluentdがログを受け、TreasureaDataとS3にログを投げるDockerfileは以下のようになります。
FROM ubuntu
MAINTAINER kohey
RUN apt-get update && apt-get install -y --force-yes libssl0.9.8 curl
RUN curl -L http://toolbelt.treasuredata.com/sh/install-ubuntu-trusty-td-agent2.sh | sh && mkdir -p /var/log/td-agent
ENV GEM_HOME /opt/td-agent/embedded/lib/ruby/gems/2.1.0/
ENV GEM_PATH /opt/td-agent/embedded/lib/ruby/gems/2.1.0/
ENV PATH /opt/td-agent/embedded/bin/:$PATH
ADD ./config/td-agent.conf /etc/td-agent/td-agent.conf
CMD ["td-agent"]ログデータをs3とtreasuredataにfluentdが投げるconfigファイルは以下のようにしました。
<source>
type http
port 8888
</source>
<match log.**>
type copy
<store>
type s3
aws_key_id "#{ENV['AWS_ACCESS_KEY_ID']}"
aws_sec_key "#{ENV['AWS_SECRET_ACCESS_KEY']}"
s3_bucket YOUR_BUCKET_NAME
s3_object_key_format %{path}%{time_slice}.%{file_extension}
path log/
buffer_path /var/log/td-agent/s3
time_slice_format %Y%m%d-%H
flush_interval 3600s
</store>
<store>
type tdlog
apikey "#{ENV['TD_KEY']}"
auto_create_table
buffer_type file
buffer_path /var/log/td-agent/buffer/td
use_ssl true
flush_interval 60s
</store>
</match>このDockerイメージをビルドしたものを、プライベートDocker Registryにpushします。
EC2 Container Service(ECS)内で、先ほど作成したDockerイメージを利用するようにして起動させました。
ECSの詳細はこのエントリでは割愛しますが、作成したDockerイメージを下図のように指定し(task-definitionの設定)、その後、コンテナを立ち上げることが可能です(create-service or run-task)。
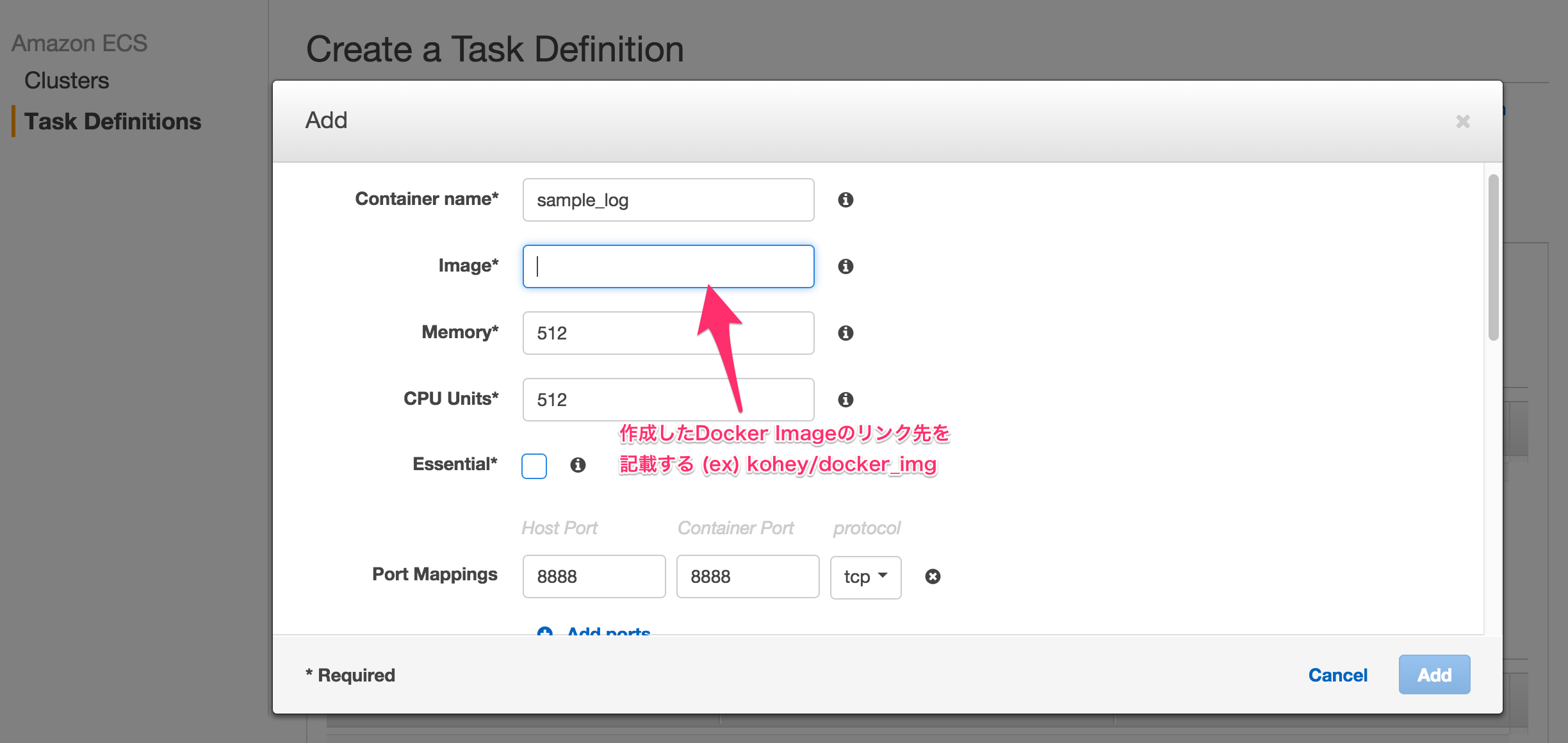
ECSを使った感想としては、まだまだ不十分な部分(特にコンテナのデプロイ周り)はある・ECSの専用の用語を覚えなければならないといったことはありつつも、ELBと連携が容易なところから、AWSで全て管理できるのはいいなぁと思います。Productionで動かす事例等、今後も配信できればなと思います。
モバイル行動ログの取得について
モバイル行動ログを取得する方法は様々あると思います。行動ログを取得するにあたって、悩んだことが一つありましてそれは「ボタンタップの度に毎回ログ収集サーバにリクエスト送るのもなぁ。結構タップするアプリだったらずっと送信しているなぁ。」
ということです。と同時に、
「fluentdっぽく、ある程度バッファーを貯めて一定のログ数に達するとflushするような仕組みがモバイルにもあればなぁ」
ということを思いました。
そこでCOOKPAD社のPureeというログ収集ライブラリを利用することにしました。
Pureeの導入等の詳細はCOOKPAD社のブログを見れば大変わかり易いのですが、私は以下のように作成しました。
Logger.swift |
Pureeを用いたLoggerの設定全般 |
|---|---|
ActivityFilter.swift |
ログを整形するためのファイル |
LogServerOutput.swift |
ログを収集サーバに投げる処理を書いたファイル |
LoggerManager.swift |
ログのセッション管理等を行うファイル |
例えば、ボタンを押した後のログを取りたい時に、
@IBAction func btnPush(sender:UIButton) {
let logger = Logger.sharedInstance.logger
let answerLog = [
"action": "traning",
"type": result.type.getString(),
"word": result.word.en,
"left_time": leftTime,
"result": type.hashValue
]
logger.postLog(answerLog, tag: "action.log")
}
を仕込むだけでモバイル内にログを貯め、設定したログ数が貯まればログ収集サーバに投げることが実現できました。また、全てのログに対して共通で追加したいログ(タイムスタンプ・デバイス名・uuid等々)は、全てActivityFilterで追加するようにしました。
class ETGActivityFilter: PURFilter {
override func configure(settings: [NSObject : AnyObject]!) {
super.configure(settings)
}
override func logsWithObject(object: AnyObject!, tag: String!, captured: String!) -> [AnyObject]! {
let currentDate = self.logger.currentDate()
var dic = object as! Dictionary<String, AnyObject>
// 以下、ログにおける追加要素
dic["uuid"] = (UUIDを取得する処理)
dic["device"] = "ios"
return [PURLog(tag: tag, date: currentDate, userInfo: dic)]
}
}
また、fluentdでいうところのログのタグの設定が出来るというのも凄くいいなぁと思いました ( 7行目 ) 。
class SampleLogger {
let logger:PURLogger
private init() {
let pattern = "action.**"
let configuration = PURLoggerConfiguration.defaultConfiguration()
configuration.filterSettings = [
PURFilterSetting(filter: ETGActivityFilter.self, tagPattern: pattern)
]
configuration.outputSettings = [
PUROutputSetting(output: ETGLogServerOutput.self, tagPattern: pattern, settings:[PURBufferedOutputSettingsLogLimitKey: 10,
PURBufferedOutputSettingsFlushIntervalKey: 30])
]
logger = PURLogger(configuration: configuration)
}
static let sharedInstance = ETGLogger();
}まとめ
なぜ、タイトルに "小さく" と書いたのかというと、まだこの基盤だとログを収集するという点だけしか満たしておらず、可視化やTreasureDataを利用した分析であったり、「ログを収集して何をするのか」の部分は満たしていないので、"ちいさく作る" と書きました。
ただし、TerraformやPackerでインフラ構成をテンプレート化し、Dockerでコンテナ化を行ったために、他のプロジェクトへログ収集基盤を導入コストを比較的少なく行えそうな気がしたため、これらの技術選定はすごく良かったと思います。