目次
こんにちは!アプリケーションソリューショングループ(以下、ASG)の吉井です。本記事は Recruit Engineers Advent Calendar 2020「15 日目」の記事です。
Stories as Test
ASG では、Storybook / reg-suit を用いたビジュアルリグレッションテストを推進しています。Component テストを兼ねた .stories ファイルのコミットは、私たちにとって今やフロントエンド開発に欠かせない工数です。そんな Storybook ですが「全ての実装者にとって無理なく取り組めるか?」というと、ハードルはまだ高いように思います。
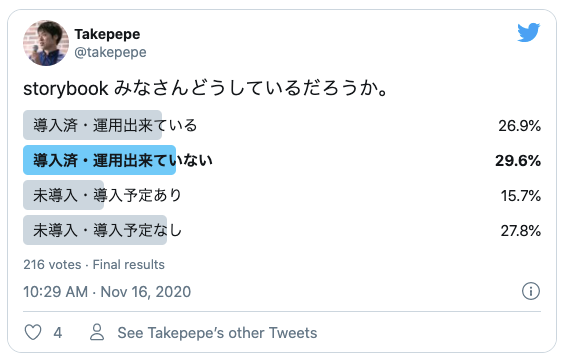
Storybook の運用実体について開発現場でどの程度普及しているのか気になったので、個人的に簡単なアンケートをとりました。結果「導入済・運用出来ている」という回答者は 26.9% 程度でした。まだまだ「一般的」というには道のりがあります。
この結果について理由は様々だと思いますが「価値化できていない・工数に見合わない」等の意見を聞いたことがあります。テストと同じように全員が Storybook をコミットするためには、誰もが当たり前に実施できるよう、ハードルを下げる必要があると感じています。
文化を支える自動化ツール
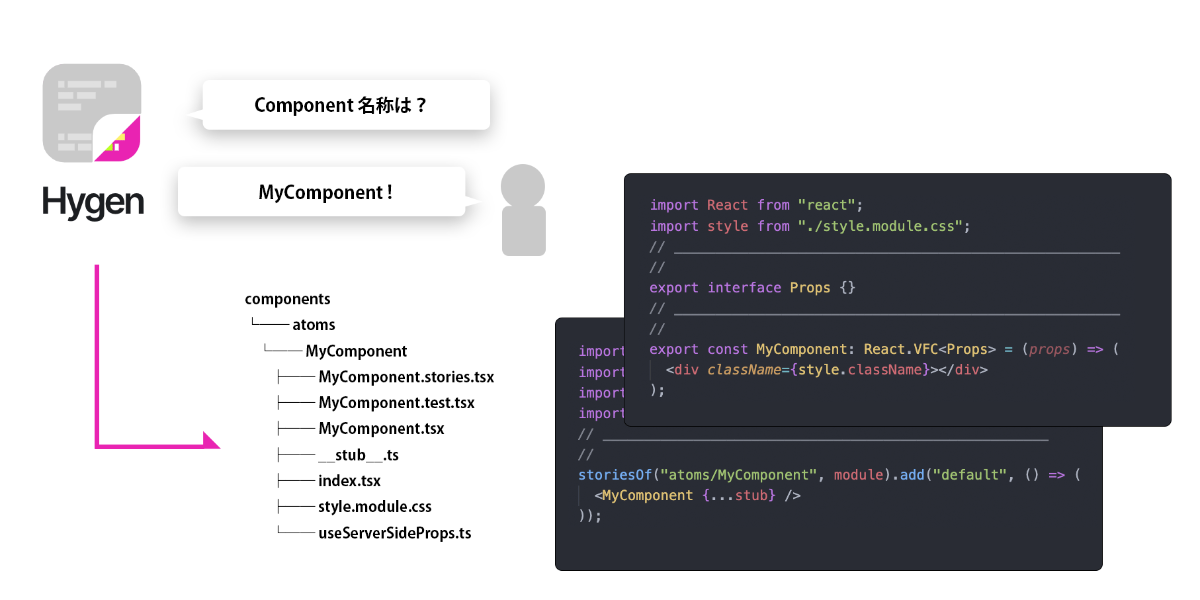
文化を定着させる手段として、フルスタックフレームワークにはテスト Scaffold Generator が備わっていることがあります。CLI 経由で項目を入力すると、実装だけではなくテストの足場ファイルなども一式作成されるツールです。この自動化恩恵により、ワークフローに自然とテストを書く慣習が促されます。Component 実装でも同様に、.stories の Scaffold Generator があると便利です。
hygen はこのような任意の Scaffold Generate ニーズに応えるツールです。生成時の命名ひとつで任意のファイル群ができるので、実装速度が向上します(詳細についてはこちらにも寄稿しているのでご参考まで)。私は入社後アサインされた案件に hygen を採用し、Component 実装に取り組んできました。hygen の下支えもあり、短期間で作りあげた 300 近くの Component で 100%の Storybook カバレッジを達成することが出来ました。
Component 実装は Props 型定義を軸にまわるので、型定義を更新すれば次に着手すべき場所へとコンパイルエラーによって誘導されます。そのため、.storiesファイル実装を失念するということが起こりません(このような恩恵を受けることができる静的型付けは素晴らしいです)。ツールによって敷かれるレール・作業効率向上というのは、文化醸成のために必要なピースと言えるでしょう。
さらなる自動化の探究
hygen 導入により Component 実装の一連は定型化され、本質的考察に時間を多く割くことができるようになりました。概ね以下の流れに沿います。
- 1. 型定義の考察 | どのような値で成り立つ Component なのか?
- 2. Component の実装 | どのように値を DOM にマッピングするのか?
- 3. Stub データの作成 | どのような値が与えられると想定しているのか?
.storiesファイルを Storybook で確認するためには、Props または Provider の値を模した Stub データを用意する必要があります。hygen で生成される.storiesファイルには型注釈付与されてはいるものの、初めはただの空ファイルです。
作業を重ねるうちに「この Stub データ作成も自動化できれば、もっと作業効率は向上するかも?」という考えが頭をよぎりました。
型定義から Stub データを自動生成
このアイディアを実現するために時間はかかりませんでした。faclip というツールは「クリップボードにコピーした型定義文字列」から Stub データが作成できます。あらかじめ npm i -g faclipしている状態で、次のような型定義をクリップボードにコピーします(※ Area も含めてコピー)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
interface Area { name: string; label: string; } interface Props { firstName: string; lastName: string; user: string; emailAddress: string; phoneNumber: number; area: Area[]; } |
つぎに、faclip コマンドを叩くと、クリップボードの中身が Stub データに変換されているというツールです。Propsという名称の型定義をエントリポイントに、型定義が変換されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
export const stub: Props = { firstName: "Anya", lastName: "Bartoletti", user: "Fuga assumenda eius et autem voluptatem. Non laudantium ex laborum autem.", emailAddress: "Roger_Hermiston72@yahoo.com", phoneNumber: 47027, area: [ { name: "Toy Pagac", label: "nostrum assumenda qui" }, { name: "Howard Koch", label: "Necessitatibus non nihil dignissimos ab et harum quibusdam.", }, ], }; |
faclip 自体は Google の OSS intermock にクリップボードの文字列内容を渡しているだけの簡易なものです。intermock は渡された型定義文字列を TypeScript Compiler API で解析し、Stub データを作成するライブラリです。intermock が解析した型定義内訳を内部依存している faker.js に与え、faker.js のレスポンスを Stub データとして返します。
Props 型定義を軸にまわる Component 実装ですから、Stub データの SRC は既にそこにあります。これなら.storiesファイル作成は、完全自動化も夢ではないのでは?と夢が膨らみますね。
これはまだアイディアです
hygen は Node.js 製のツールですので、intermock などと統合することも簡単です。Props 型定義を一つ用意してしまえば全自動化可能、という上記アイディアは実際に実現可能でした。しかし、まだまだ精査が必要です。
「どんな値が与えられると想定しているのか?」という考察をスキップしてしまう事自体、最良な工程とは言えないからです。与えられた足場は足場でしかなく、実装者が振る舞いと意図をテストに落とし込むことは、完全自動化できるほど単純なものではありません。これはテストも Storybook も共通に言えることです。
しかしながら、型定義内訳を解析し二次活用できるという利点は、作業効率向上に活用できる余地がありそうです。昨今のフロントエンド開発において、型・lint・format が文化として定着したのは、優れたツールがハードルを下げた背景があるはずです。より良い DX をもたらしてくれる自動化ツールは、これからの文化醸成を支えうるものではないでしょうか。